基于支持向量机的图像深度提取方法
2012-10-18牛连丁赵志杰金雪松孙华东王海涛
牛连丁,赵志杰,金雪松,孙华东,王海涛
(哈尔滨商业大学计算机与信息工程学院,150028)
随着三维立体视频的广泛应用,三维视频领域存在的市场需求旺盛与片源严重匮乏的矛盾日益凸显.2010年以来三维显示设备的迅速普及,使得市场对3D片源需求急剧增加.一方面,人们不断追求立体视频所带来的强烈的视觉冲击及逼真的临场感;另一方面,利用立体视频采集设备来制作3D片源存在成本高、周期长、技术难度大等问题,导致立体片源严重不足.为了解决这一矛盾,相关研究人员提出了利用二维视频提取深度的方法,将现有的二维视频转换为三维视频.充分利用已有的二维视频资源,既节约了制作成本,又可以满足市场需求.
三维视频在工业仿真、建筑设计、军事模拟、医疗卫生、教育、机器制造、斟察测量、影视娱乐和广告传媒等领域具有广泛的应用前景.因此,2D-3D视频转换技术的研究,必将促进这些领域内相关的技术的发展,具有较高的应用价值.
1 图像的深度提取方法
目前,大多数2D-3D视频转换技术的研究都是围绕德国HHI(Heinrich Hertz Institute)提出的基于深度的三维图像生成方式DIBR(Depth-Image-based Rendering)[1]进行的.生成过程如图1所示,DIBR是利用深度与目标物体三维坐标的几何关系,由深度图计算出物体的三维信息.基于该理论,深度提取成为2D-3D视频转换的关键问题,是2D-3D视频转换技术研究中的一个重要方向.
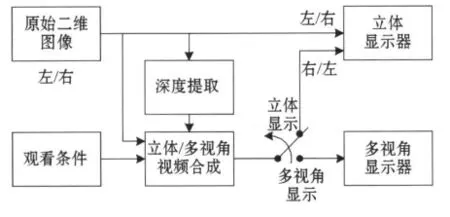
图1 基于DIBR的3D图像生成系统结构框图
在基于深度的2D-3D视频转换方法中,通过采用不同的线索,如:运动视差(motion)、散焦(defocus)、线条透视(linear perspective)、大气散射(atmosphere scattering)、图像纹理(patterned texture)、遮挡(occlusion)等,获得图像的深度信息,取得了一定的研究成果.但每一个线索都有其特定的适用范围,仅靠单一的线索提取深度信息很容易受到具体场景的限制.例如,Cheng等提出的基于宏块的双边滤波的二维视频到三维视频转换算法[2],以及Feng X等提出的通过采用光流法获得运动矢量场来确定深度信息的技术[3].这两种方案都是基于运动视差线索提取深度,认为运动越快的物体越接近观察者,这种算法在摄像机运动、场景静止时能获得较为理想的效果.否则无法得到满意的估计结果.Zhou等提出了基于DFD(depth from defocus)通过高斯梯度方法建立边缘模糊度模型[4],该方法在边缘处理效果以及场景深度计算准确度方面有所提高.但对于模糊对比不大的图像效果不理想.研究人员为了弥补这一不足,提出了以一条线索为主,以其他线索作为补充的深度提取方法.如Y.FENG等人提出一种基于模糊度估计与光流法相结合进行深度估计的算法[5].但是,由于多线索之间结合的方式是未知的,会出现因依据某个线索判断得到错误的结果而影响到最终结果的准确性.例如在模糊估计时,大面积天空背景会被误判为清晰的前景,对最终深度图的效果有一定的影响.
2 基于支持向量机的深度提取方法
人眼可以从二维视频甚至静态图片中获取深度信息.因此,在观看电影或照片时,观查者可以轻易地区分景物之间深度层次的关系,这是人类大脑能够从图象中获取不同的线索,并将这些线索结合在一起来判断深度信息.但是这种多线索结合的方式并不明确.如果深度提取算法也具有这种多线索学习能力,将会具有更强的适应性.而SVM可以通过对小样本学习近似地获得存在但并不明确的模型.因此,本文提出了基于支持向量机的图像深度提取算法.该算法利用支持向量机训练学习获得多条线索结合方式,从而建立图像深度信息的模型.利用该模型将图像中提取的纹理变化、纹理梯度以及雾度等线索结合起来进行深度预测,从而提高深度提取的准确性.
2.1 支持向量机
支持向量机(Support Vector Machine,简称SVM)是由Vapnik等人在统计学习理论的基础上提出的一种新的机器学习方法.它要求寻找一个最优超平面H作为分类面.从而保证结构化风险最小.如图1所示,设两类训练集为{xi,yi},i=1,…,n,x∈Rd,d为特征向量的维数,训练集共n个样本,其中xi是第i个样本,yi∈{-1,+1}是第i个样本的类别标签.
为保证结构化风险最小,分类面H:wTx+b=0(其中:w是超平面的法向量,b是超平面的常数项.)必须满足以下两个条件:
1)分类面对所有样本都能正确分类,即:yi
2)正例和反例之间的隔离边缘最远.即下式最大.

所以寻找最优超平面即正反例间隔最大化问题,最终归结为一个约束优化问题,即:

使用Lagrange乘子法建立Lagrange函数:

求解出对偶问题的最优解,设用a*i表示最优的Lagrange乘子,则此时原问题的最优解为:

则最优判别函数为:
该判别函数是用来解决二分类问题的.对于工程中出现的多分类问题,一般采用将多分类问题归结为多个两类问题分别处理,通过组合多个二分类支持向量机(binary support vectormachine,BSVM)实现多类分类.目前常用的方法有:一对多、一对一、导向无环图、二叉树等.本文采用一对一的方式实现多类分类,这种方式是在任意两类样本之间训练一个SVM,对于K类样本需要构造K(K-1)/2个SVM.预测时,对于一个样本用所有的SVM进行分类,累计各类别的预测得分,选择得分最高者所对应的类别为测试数据的类别.即通过投票的决策方式,由二分类支持向量机解决了多分类问题.
2.2 基于支持向量机的深度提取
基于支持向量机的图像深度提取方法的结构如图2所示,系统处理分为数据准备和SVM学习两阶段完成.在数据准备阶段,通过处理深度图获得分类标签,在原始图像中提取深度特征构成特征向量.在SVM学习阶段,首先需要确定核函数及其参数;然后根据数据准备阶段获得的分类标签以及特征向量训练SVM建立分类模型;最后,使用该模型以及特征向量,由SVM对未知深度的图像进行预测,最终获得其深度图.
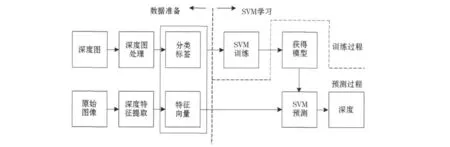
图2 基于支持向量机的图像深度提取方法的结构框图
3 算法实现
3.1 分类标签获取
本文深度预测是以宏块为单位进行的,通过预测每个宏块的深度来获取一帧图像的深度图.所以将深度图以及原始的二维图像分成固定尺寸N×N的宏块.则对于任意一个宏块patch(i),以其块内像素深度的均值作为该宏块的深度另外,人眼在观察二维图像时,会将景物按深度不同分成不同的深度层,在本设计中为了方便处理,将宏块的深度量化到l个层中处理.相应的层号作为该宏块在SVM多类分类器中的分类标签经过综合考虑主观感受和处理复杂度,本文将宏块尺寸选为、层数选为16.
3.2 特征向量的获取
二维图像在制作过程中已经丢失了大量的深度信息,要恢复其深度信息则需要根据残留在图像中不同的线索提取深度特征,这对推断深度来说是一个非常重要的前提.本研究的深度特征提取借鉴文献[6]中绝对深度特征的提取方法.
观看二维图像的直观经验表明,利用一个单独宏块很难预测其自身的深度信息,必须参考场景中与其直接相邻的景物或更大范围内的景物才能够判断出其深度.例如,对于一个孤立的蓝色宏块,我们无法判断出它是远处的天空,还是近处蓝色物体的一部分.这就要求在深度判断过程中,要充分考虑深度特征的全局特性.因此,在原始图像中建立多尺度空间一阶邻域系统,如图3所示.这样可以将与中心宏块直接相邻的宏块以及离它较远的宏块(在更大的尺度中)的特征引入深度判断.另外,由于在图像中的景物(如楼房、树木、人等)大多数是垂直的,将宏块所在的列分成相等的4部分,形成可以捕捉该宏块的垂直属性的4个列宏块.这样,对于一个小宏块来说,就获得19个与其有空间约束关系的宏块来表示其特征(5patchs/scale×3scales+4columnpatchs=19patchs).

图3 多尺度一阶临域系统
在图象中,不同深度的景物表现出的纹理变化、纹理梯度、雾度等特征也不同.因此,本研究利用给定的一组滤波器滤波(如图4所示),根据这三个线索来获得图像的深度特征.其中,前9个模板是由Laws提出的一组3*3 Laws模板,可以用来检测图像中局部均值、边缘、斑点等纹理变化信息;后6个5*5模板是定向侦测器,可以提取图像中纹理梯度信息.对于YUV测试序列,大多数纹理变化及纹理梯度信息都存在于Y通道中、而大气散射则在U、V通道的低频部分比较明显,所以采用滤波器作用于图像的Y通道求得纹理变化和纹理梯度;利用第一个Laws模板作用于图像的U、V两个通道求得雾度.将上述17个滤波器Fn(x,y)(其中:n=1,…,17)与图像I(x,y)卷积,并求其绝对能量和以及平方能量和,即

对于每个中心宏块i就获得了由646维数据特征向量.

图4 Laws模板与方向侦测器
3.3 SVM学习及实验结果
在SVM处理阶段,首先要确定SVM所采用的核函数、参数、以及数据预处理的方式.目前对于SVM的核函数、参数选择都没有统一的标准,使用过程中一般都需要通过经验或者实验对比确定.另外,避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难.通常将数据缩放到[-1,1]或者是[0,1]之间.实验中借助交互检验实验对比的方法进行核函数、参数以及数据缩放方式进行选择选择.
为了验证算法的有效性,利用本文基于SVM的多线索深度提取算法分别对测试序列balloons、newspaper、lovebird中的第50帧进行了深度图生成实验.实验中,采用Matlab完成数据准备工作,采用Libsvm软件包进行训练和预测.实验结果如图5中所示,由左到右依次为原始图像、真实深度图、量化后的深度图以及预测出的深度图.实验中的准确率分别为82.55%、85.799 2%、94.059 2%.实验结果表明,本文所提算法在这几种情况下均能获得较好的效果.
4 结语
本文提出的基于SVM的多线索深度提取算法,利用SVM学习训练样本中多线索的结合规则,将纹理变化、纹理梯度、雾度等线索结合在一起判断深度信息,从而提高了深度提取的准确性.本文通过实验验证了该方案的可行性.与单线索深度提取算法相比,该算法在不同场景中都能得到较好的深度图.由于SVM可以通过增加特征向量的维数来增加使用更多的线索,所以对二维图像中深度线索提取的研究以及如何选择更加有效的深度特征作为SVM的特征矩阵是接下来的研究中的重点.

图5 实验结果对比
[1]CHRISTOPH F.A 3D-TV Approach Using Depth-Image-Based Rendering(DIBR)[C]//Visualization,Imaging,and Image Processing(VIIP),Benalmadena,Spain.2003,482--487.
[2]CHAOCHUNG C,CHENGTE L,POSUN H.A Block-based 2D-to-3D Conversion System with Bilateral Filte[C]//International Conference on Consumer Electronics,Las Vegas,NV,USA.2009:1-4.
[3]FENG X,GUIHUA E,XUDONG X,et al.2D-to-3D Conversion Based on Motion and Color Mergence[C]//3DTV Conference:The True Vision-Capture,Transmission and Display of 3D Video,Istanbul,Turkey,2008:205–208.
[4]SHAOJIE Z,TERENCES.Defocusmap estimation from a single image[J].Pattern Recognition,2011(5):1852–1858.
[5]YUE F,JAYASEELAN J,JIANG J.Cue based disparity estmation for possible2D to3D video conversion[C]//Visual Information Engineering.IET International Conference,Bangalore,India.2006:384-388
[6]ASHUOTSH S,JAMIE S,ANDREW Y N.Depth estimation usingmonocular and stereo cues[C]//International Joint Conference on Artificial Intelligence(IJCAI),Hyderabad,India.2007:2197-2203.
