基于多水平模型的西南民族地区农户非农劳动行为研究
——以云南省红河哈尼族彝族自治州为例
2012-10-18王娟
王 娟
(北海职业学院,广西 北海 536000)
基于多水平模型的西南民族地区农户非农劳动行为研究
——以云南省红河哈尼族彝族自治州为例
王 娟
(北海职业学院,广西 北海 536000)
文章基于农户模型理论,结合西南民族地区农户特征,寻找影响农户非农劳动行为的因素;基于农户数据具有层级结构的特点,从多水平模型统计分析方法入手,通过对数据的组间异质性和随机性问题的有效处理,以云南省红河哈尼族彝族自治州为例,结合实证得出了最终模型,并与普通最小二乘估计进行比较。
多水平模型;西南民族;非农劳动
中国是个拥有9亿农民的农业大国,解决农民问题的核心是增收,农民增收的有效途径是扩大非农就业。相比沿海内地经济发展水平较高地区,由于其居住环境、社会发展程度不同,西南民族地区的农村问题研究更有其特殊性和复杂性,本文基于农户模型理论,结合西南民族地区农户特征,寻找影响农户非农劳动行为的因素;基于农户数据具有层级结构的特点,从多水平模型统计分析方法入手,通过对数据的组间异质性和随机性问题的有效处理,寻找农户层级数据的微观水平和宏观水平影响效应,从而深入分析对于西南民族地区农户行为决策过程中更合理的农户经济解释,为西南民族地区农业问题的开展提供借鉴与思考。
1 模型的设计与解释
在研究农户问题时,许多学者采用多元线性回归模型的统计方法,如张林秀,霍艾米(2000)采用最小二乘估计(OLS)方法研究经济波动中的农户劳动力供给行为;Ahn, Singh,and Squire(1981)用加入误差项的计量模型估计农户多产出的利润函数;程名望,史清华(2006)用基于线性回归的Logit模型论证了城镇的拉力是农村劳动力转移的根本动因。考虑到农户数据具有层级结构的特点,层级结构数据存在组内同质性问题,即同层(组)的个体存在相似性,其残差项不相互独立,导致传统多元线性回归模型的同方差和独立性假设不成立,其估计参数标准误也会产生偏倚,由此产生统计检验的第一类错误,而错误地拒绝统计学显著性检验的真假设。
多水平模型自上个世纪80年代发展起来到现在,已是目前国际统计学研究中的一个重要领域,但国内外对于多水平模型在经济领域的运用尚处于刚刚起步阶段。在农户行为问题的研究中,目前还没有运用多水平模型统计方法分析的例子。多水平模型统计分析方法能将因变量中的变异分解为组内变异(within-group variance)和组间变异(between-group variance),因此,适合于处理层级数据结构。
2.1 多水平模型的形式
以一个两水平模型为例介绍多水平模型,在一个两水平模型中包括两个水平1解释变量和一个水平2解释变量,模型设定如下:
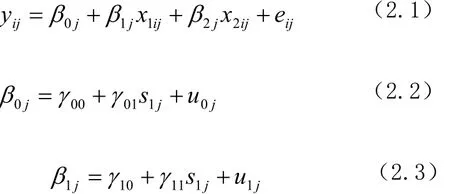
i=1,2,…,N(样本总量) ;j=1,2,…,J(水平2单位数)式中,yij为第j个水平 2单位(或第j组)中的第i个个体的水平1被解释变量;式(2.1)表示yij变异的水平1方程。水平1截距 0j表示水平1截距跨水平2单位的变化,是随机回归系数 0j,对应的有水平2方程(2.2),在这里,0j就变成了因变量,它表示的是,水平1被解释变量yij的总体平均值并非如一般线性回归模型所描述的是一个固定系数,而是随着水平2的不同而不同,它的变异由(2.2)方程中的水平2解释变量s1j来解释。x1ij对yij的效应跨水平2单位变化,同样 1j也是随机回归系数,它的变异由(2.3)水平2方程中的水平2解释变量s1j来解释。水平1解释变量x2ij并不跨水平2单位变化,其对应的回归斜率β2j也是固定的。从模型的形式看,包含了两个随机回归系数 0j和 1j,以及一个固定回归系数 2j。
将式(2.2)和(2.3)代入式(2.1),可以得到组合模型(2.4):
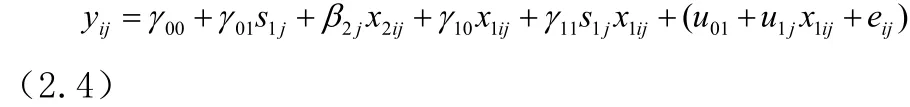
式(2.4)可以看成有两部分组成:即固定效应成分和随机效应成分,分别对应
(00+01s1j+2jx2ij+10x1ij+11s1jx1ij)和。水平2误差项ju0和ju1只是在各组间有变化,在组内(第j组)并没有变化,也即各组内观察值互不独立。该模型看上去,与一个带有交互作用的普通线性回归模型有些相似,但是其残差部分要复杂得多。该模型的残差包括两个水平2误差项ju0和ju1,一个水平1误差项ije以及水平1解释变量ijx1,称之为复合残差结构,它取决于ju0、ju1和ijx1的值,并且ijjxu11被看作是组群与水平 1变量ijx1之间的交互作用。因此,复合残差没有一个恒定的方差,也正是由于这个特征会导致异方差性,从而不符合普通最小二乘法的条件假设,而需要用特殊的方法来估计多水平模型的参数。
通常用于多水平模型参数估计的方法有两种:一种是迭代广义最小二乘估计,即 IGLS,Iterative Generalized Least Squares(Goldstein, 1985);另一种是限制的迭代广义最小二乘,即 RIGIS,Restricted Iterative Generalized Least Squares(Goldstein,1986)。本文采用SAS PROC MIXED进行模型拟合在计算机软件中的实现,其提供了可供选择参数估计方法:ML、REML等。在多水平模型中,对模型的检验运用的最为广泛的是似然比检验,常用似然比检验来对比两个模型拟合的好坏,通过其差值大小的显著性来检验模型的改进效果。-2LL值越小,表明模型改进得越好。此外,还可采用信息标准统计量:AIC、BIC和AICC进行模型比较。AIC、BIC和AICC的值越接近于0,则模型拟合数据越好。
2 西南民族地区农户非农劳动时间的影响因素分析
2.1 数据的预处理与变量的选取
本文研究数据来源于 2008年云南省红河哈尼族彝族自治州统计局农村住户调查数据,包含13个市县、136个乡镇、295个村,3000户农村家庭,涉及3700多个普查指标。很显然,该数据具备明显的层级特点,农户嵌套于村,村嵌套于乡镇,乡镇又嵌套于市县,是一个三水平层级结构数据,适合于采用多水平模型估计与分析。考虑合适的组群个数,本文采用“村—农户”对数据进行分层处理,以不同的村码区分。水平2的乡镇经济变量来源于《2009年红河州领导干部经济工作手册》。
在模型建立之前,对部分变量进行了预处理。数据中年龄为分类变量,采用组中值处理方法将其处理为连续变量,运用加权平均法求出平均年龄以便作年龄的总中心化处理;数据中农户经营土地面积为连续变量,但其密集在平均水平以下,为了利于估计,尝试将该变量分类虚拟化看其对农户劳动行为的影响。
基于农户模型的理论框架,农户家庭的劳动行为决策与生产和消费决策联系在一起。结合研究数据与西南民族地区农户的行为,考虑其特殊性,本文从以下三个方面着手选取变量:
(1)经济因素。由农户模型可以清晰地了解农户在进行劳动时间决策时是通过效用函数分析的,在农户家庭效用最大化的条件下,考虑生产决策与消费决策。本文研究的对象是我国西南少数民族贫困地区的农户劳动行为,劳动市场的不完善性以及少数民族文化的特定性使得农户模型的假定过于苛刻,生产决策和消费决策不具有可分性,生产决策影响消费决策的同时,消费决策反过来也影响生产决策。也正是基于此,在本文对农户非农劳动时间的影响因素分析时,在不考虑农户的消费偏好的前提下,将可支配收入这一影响农户消费决策的变量引入模型之中,以测定其对生产决策的反作用。同时,由于劳动力市场的不完善,使得农业劳动工资无法观测,因此,本文采用农业生产函数估计农业劳动的影子工资以代替市场劳动工资,进而估算出农户的影子收入,在此基础上考虑影子收入对农户非农劳动时间配置的影响。
(2)场景因素。地理因素在很多农户问题的研究中也被称作是环境因素,不论其如何界定,代表农户家庭所处的自然环境、交通条件、所处地区的基本情况的这些协变量,本文为与后面统计分析模型一致,全部定义为场景因素或场景变量。从经验研究看,这些变量对农户家庭的行为决策具有一定的影响,而且存在同一范围内的相似性。在场景因素的选择中,本文与前人研究的区别在于考虑了所处地区的乡镇经济发展状况对农户个体行为的影响,从乡镇的工业总产值、乡镇企业营业收入等变量入手试图来寻找更具代表性的场景变量以分析非农劳动时间的影响因素。
(3)家庭特征因素。农户行为决策来自于家庭,作用于家庭,而每个家庭的特征又不尽相同,比如家庭的结构、劳动力人数、男劳动力人数、家庭经营的土地面积、受教育程度、年龄等等造成了农户劳动供给行为决策时的个体差异。有学者还曾就某一家庭特征变量进行专门的分析,比如教育。此外,考虑到西南民族地区农业生产占绝大部分,农业生产风险较其他地区更大,其对农户收入有直接的影响,而人均经营土地面积和上一年农业生产固定资产原值从一定程度上可以反应农户家庭抵御风险的能力。本文将把这些家庭特征变量作为个体变量纳入模型进行探索性测量。
3.2 两水平模型估计
(1)正态分布检验。为了分析影响云南红河地区农户劳动时间配置问题,本文选取非农劳动时间为因变量,考虑到多水平模型对因变量正态分布的前提要求,对该变量取自然对数,检验其正态性,得到如下正态Q-Q图1,从分布的斜率来看,呈近似正态分布,符合多水平模型估计对因变量的正态性要求。

图1 非农劳动时间取自然对数的正态Q-Q图
(2)村内同质性的统计检验。对数据的结构进行初步分析知道本文研究数据具有明显的分级结构,考虑样本分布及群组单位个数适应多水平模型分析的要求,选用“农户—村”这一两级数据进行分层处理,首先,通过这一结构数据的组内相关系数计算,可以发现该数据是否具有层级结构。本文中关于多水平模型分析的软件实现均在SAS9 .2版本下运行。首先,建立关于非农劳动时间2L的空模型(Empty Model),写作:
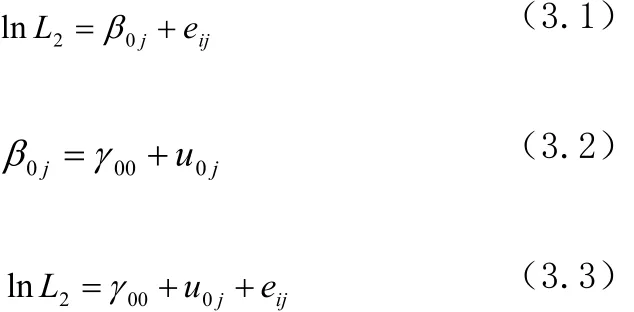
该模型中水平1(公式3.1)和水平2(公式3.2)中均没有解释变量,模型(3.1)中,0j和eij分别代表第j个村庄的非农平均时间和围绕该平均值的农户个体的变异。模型(3.2)中,γ00表示总截距,代表非农时间的总平均值;u0j代表组均值之间的变异,即第j个村庄的非农平均时间与非农总平均时间的差异。模型(3.3)是模型(3.1)和(3.2)的组合模型,该数据以“村”作为组水平单位,其空模型运用REML估计法,即限制性最大似然法(restricted maximum likelihood),经过2次迭代即成功收敛,表明空模型拟合良好。模型的拟合统计量 - 2LL= 6598.5,具体运行结果如表1:

表1 空模型—估计结果
组内相关系数ICC的显著性检验相当于组间方差为“零”的假设检验,通过上表,和的P值都很小,均表现出统计显著,由此可以推断ICC是统计显著的。另一方面,可以计算组内相关系数:

组内相关系数也可以解释为组间方差与总方差的比。计算结果ICC=0.527,在因变量中约有52.7%的总变异是由个体样本不同引起的,表明数据中存在较大程度的组内同质性,或者说组群效应,也就是说同一个村庄的农户在非农劳动时间的分配问题上存在着相似性,同时也意味着存在组间异质性,即不同村的农户存着差异。
(3)最终模型
根据多水平模型的建模步骤,依次建立水平2解释变量主效应的随机截距模型、随机截距模型、水平1解释变量的随机斜率检验,直至得到最终模型的估计结果,如表2:
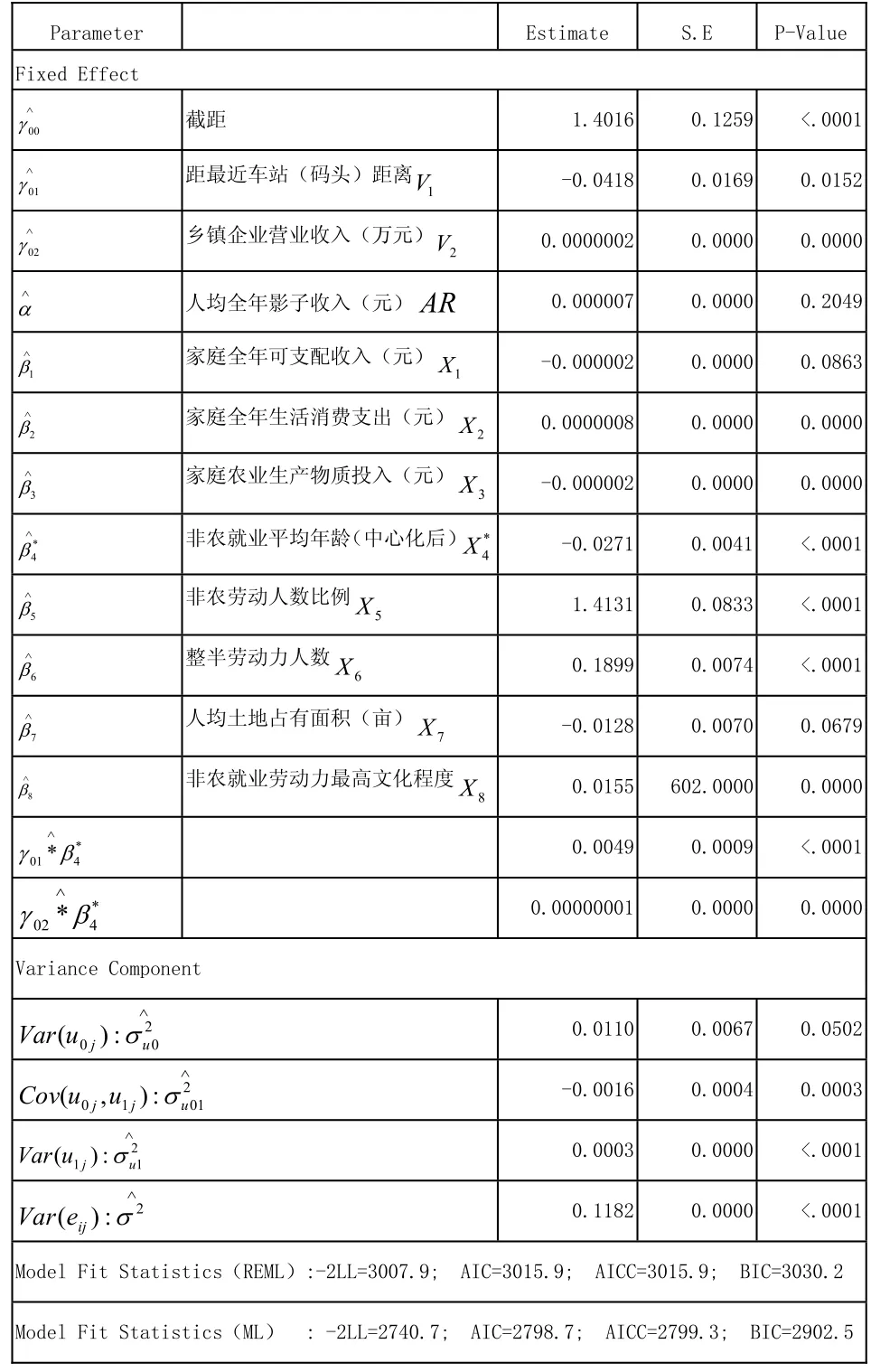
表2 最终模型—估计结果(REML)
很显然,从模型拟合统计量来看,-2LL由第四步的模型3186.3降低到3007.9,又一次得到了改善,其差值为178.4,(9)=16.919<178.4,统计显著。通过观察各自变量的P值,在5%的显著性水平下,都通过显著性检验。各残差项估计值也都有不同程度的减少,总的来说,模型拟合效果较优。最后,根据估计结果,可以写出关于农户非农劳动时间的最终模型(3.5):
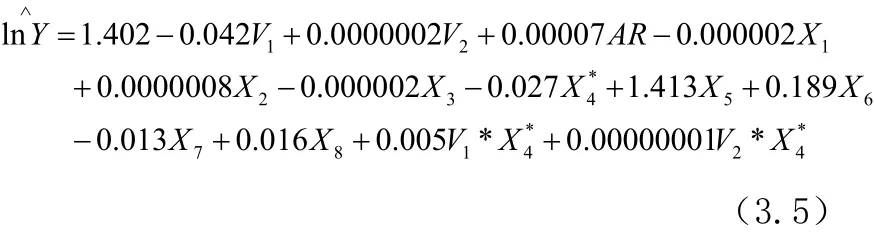
(4)与OLS估计的比较
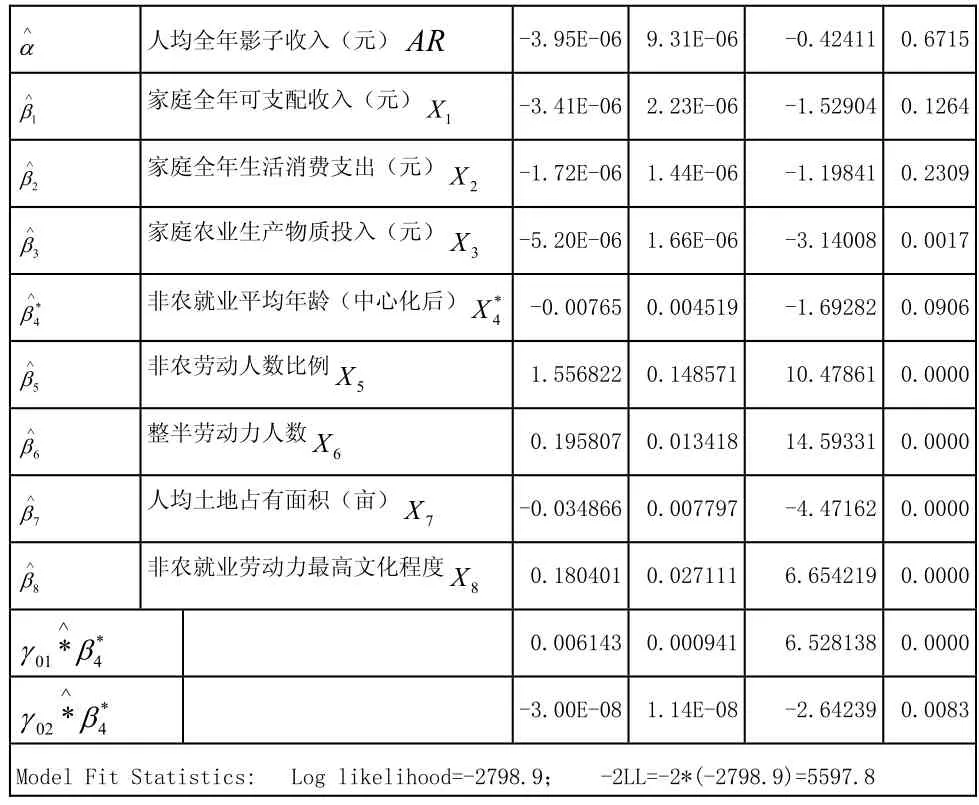
为了从不同侧面了解多水平模型估计方法的优劣性,本文还采用大多数学者在研究农户问题时常用的一般线性回归模型的OLS,即普通最小二乘(ordinary least squares)估计方法,结果如下:

表3 OLS回归结果
∧α 人均全年影子收入(元)AR -3.95E-06 9.31E-06 -0.42411 0.6715∧1β家庭全年可支配收入(元) 1X -3.41E-06 2.23E-06 -1.52904 0.1264∧2β家庭全年生活消费支出(元) 2X -1.72E-06 1.44E-06 -1.19841 0.2309∧3β家庭农业生产物质投入(元)3 X -5.20E-06 1.66E-06 -3.14008 0.0017∧*4β非农就业平均年龄(中心化后) *4 X -0.00765 0.004519 -1.69282 0.0906∧5β非农劳动人数比例5 X 1.556822 0.148571 10.47861 0.0000∧6β整半劳动力人数6 X 0.195807 0.013418 14.59331 0.0000∧7β人均土地占有面积(亩)7 X -0.034866 0.007797 -4.47162 0.0000∧8β非农就业劳动力最高文化程度8 X 0.180401 0.027111 6.654219 0.0000∧ *4 01*β γ 0.006143 0.000941 6.528138 0.0000∧ *4 02*β γ -3.00E-08 1.14E-08 -2.64239 0.0083 Model Fit Statistics: Log likelihood=-2798.9; -2LL=-2*(-2798.9)=5597.8
从表3中可以看出OLS估计结果认为非农劳动时间与农户所在调查村的两个变量1V、2V不相关,统计检验都不显著,而多水平模型却能通过将数据进行分层处理,找出组群与个体之间的关系;不仅如此,多水平模型在处理交互效应时也比一般线性模型要更优,即使OLS估计结果得出两个变量的交互效应显著,但是解释起来却缺乏理论依据。甚至有时候,在验证某些经济理论的时候,显得力不从心,比如根据农户模型理论的推断,容易知道,农户在决定家庭提供非农劳动时间的多少时,会考虑到家庭的影子收入,但在OLS估计结果中,人均影子收入这一变量却并不显著,因此无法验证这一经济理论。从模型的整体性检验来看,多水平模型的最终模型的拟合统计量结果明显比OLS的模型拟合更优,因为多水平模型的最终模型拟合值-2LL=3007.9,远远小于 OLS的模型拟合值-2LL=5597.8,相差2589.8。
3.3 模型的解释及经济意义
本文由于把场景因素处理为层级结构数据中的组水平变量,不仅考虑了环境因素对农户个体的影响因素,还通过(1)“距最近车站(码头)的距离”这一分类变量衡量调查村的交通便利条件,得出结论,与最近车站(码头)的距离越近,对非农劳动时间的投入也越多,交通基础设施的便利,会带来出行频率的增多,与外界的联系越多,市场对等信息的获得越高,将有利于农户从事非农劳动;(2)通过“乡镇企业营业收入”来反映调查村的乡镇经济发展状况,表明了乡镇经济发展水平越高,为非农就业提供了更多的机会,形成了乡镇拉力,吸引农户就近选择农业劳动以外的其他劳动形式。同时还考虑了跨层的交互效应,也因此能更精确地体现调查村的环境变量是如何调节农户个体的非农劳动时间决策的。估计结果表明,非农就业的劳动者年龄与平均年龄的差异与非农劳动时间投入的关系随着其家庭交通便利条件的不同而有所不同。在西南少数民族地区,70%的农户居住在山区,地势的恶劣条件使得交通便利对他们来说就是能否出行,出行的复杂程度已经是次要的,对于年轻或年长的劳动者,他们不是家庭的主要农业劳动参与者,他们主要从事非农劳动的方式就是长期外出打工,打工时间一般也在6个月以上,而非农闲时的补充劳动方式。
根据农户模型推出劳动供给与收入、生活消费、生产物质投入有关,估计结果也证实了这一推导,非农劳动时间与人均收入、生活费用呈显著正相关,和生产物质的投入呈显著负相关。表明,较高的生活水平需求与较高的人均收入对非农劳动时间的拉力较强。此外,农户的消费产品中,除了生活消费还有对闲暇时间的消费,由于其价格的不可观测性,可以通过影子工资反映的影子收入作为判定闲暇的优劣性质。当收入增加时,对劳动供给也随之增加,那么闲暇就随之减少,这时闲暇就是劣等品;反之,当收入增加时,对劳动供给随之减少,那么闲暇就随之增加,此时闲暇即为正常物品。但由于本文的因变量只是劳动供给中的非农劳动,因此,只能部分地解释闲暇的优劣程度,不能完全说明闲暇对西南少数民族地区来说是劣等品。从农业生产投入来说,生产物质投入越多,意味着对农业生产时间的需求越多,而农户生产受时间的约束,对非农劳动时间投入相对就越少。这一点也是与农户模型理论是相吻合的。
为了解释农户生产决策影响消费决策的同时,消费决策是否也反过来影响生产决策,我们对可支配收入进行观察其估计结果发现,可支配收入与非农劳动时间有显著负相关,也就是说,可支配收入越多,农户对非农劳动时间的投入就会越少。对农户来说,从事农业生产是主要的,如果在农业生产可以创造较多的可支配收入以满足其消费的条件下,那么对非农劳动的投入也就会减少。另一方面,从统计的角度来说,其显著性的影响验证了西南少数民族地区的农村处于不完善的商品市场条件下,农户的生产与消费决策是联系在一起,相互影响的。
对于农户劳动行为的研究必定会讨论人力资本变量,本文通过家庭劳动力结构状况以及教育程度来分析农户人力资本对非农劳动时间的影响。从风险的角度来说,农业生产是一个条件限制性较高的活动,不仅受经济活动的影响,还与诸如阳光、雨水、土壤等不可控的自然因素关系密切,尤其在西南民族贫困地区,各种风险所带来的收入波动对低收入的西南少数民族地区的农户更是一大冲击,信贷市场与保险市场往往不存在或不完善,非农劳动可以从另一个方面抵御农业生产的风险,劳动力人数以及参与非农劳动的人数作为基本的人力资本是一个不可或缺的条件。本文还尝试把“上一年生产性固定资产原值”看作是农户家庭的原始积累,反映农户家庭的风险抵御能力。但估计结果为正相关,且模型的拟合值增大,拟合效果没有改进,其经济意义也不能从风险抵御能力上合理解释,因此没有纳入模型。
[1] 张林秀,霍艾米,等.经济波动中农户劳动力供给行为研究[J].农业经济问题,2000(5).
[2] 程名望,史清华,徐剑侠.中国农村劳动力转移动因与障碍的一种解释[J].经济研究,2006(4).
[3] De Leeuw, J.& I.G..G. Kreft. Random Coeffcient models for multilevel analysis. Journal of Educational Statistics.Vol.11:57-85.
[4] Wallace E. Huffman. Farm and Off-farm work Decisions:The Role of Human Capital. The Review of Economics and Statistics,Vol.62,No.1(Feb.,1980)pp:14-23.
Non-farm labor action research of the southwest region farmers Based on the multi - level model——Take honghe hani nationality yi nationality autonomous prefecture in Yunnan province for example
In this paper, based on the farmer model theory, combined with the household characteristics of the southwest national area, looking for influence factors of non-agricultural Labour behavior; based on characteristics of hierarchical structure in the household data, starting from statistical analysis method of multilevel models, Through effective handling between groups heterogeneity of data and random question, Take honghe hani nationality yi nationality autonomous prefecture in Yunnan province for example, combined with the positive,obtained final model and compared with the ordinary least squares estimates, the empirical results show that multi-level model better is suitable for the research of the economic problems of farmers, were new ideas were put forward from methodology.
multi-level model; southwest nationality; non-farm labor
TP273
A
1008-1151(2012)06-0302-04
2012-04-11
王娟(1975-),女,湖北武汉人,北海职业学院经济学硕士,研究方向为应用统计。
