RFID混合碰撞算法研究
2012-10-17汪国强
汪国强,赵 璐,郑 东
(黑龙江大学 电子工程学院,哈尔滨 150080)
0 引 言
RFID是Radio Frequency Identification的缩写,中文译名射频识别技术,其技术最大的特点就是通过无线射频信号自动对目标进行无接触识别[1]。RFID系统由阅读器 (Reader)、电子标签(Tag)、应用系统3个部分组成。阅读器在自己的工作范围内,不断地通过天线发送特殊的射频信号,当标签进入工作区域内,标签会有感应电流产生,这个感应电流驱动电子标签,使其获得一定的能量,将自身携带的序列号信息由天线发送出去,阅读器接收到这个信息后,对信息进行一定的处理(解调、解码),再把处理后的信息发送到应用系统中,应用系统会发出下一步工作的指令。
RFID系统工作时经常会有这样一种情况出现,多个电子标签存在于阅读器的工作范围内,多个使用者共同使用一个无线信道,必然会发生信道争抢、信息干扰等问题,最终导致电子标签无法被阅读器识别,这种情况称之为发生了冲突或者出现了碰撞 (Collision)。在RFID系统中碰撞问题可以分为两大类:阅读器碰撞、标签碰撞。从软件的角度采用一定的策略或方法来避免冲突现象的发生的过程称为防冲突,或者防碰撞。由于碰撞产生的相关问题制约着RFID技术的推广与应用,尤其是当RFID技术广泛应用于工业生产、销售、货运等需要准确实现多目标识别的领域时,由于碰撞造成数据的错误传输,信息读取无法正常进行,最终导致产品识别的失败,以及产品信息的丢失,造成的后果会更严重。因此,解决碰撞问题的技术也就成为RFID系统中的一项至关重要的技术,由此可知对于碰撞问题的深入研究是非常有必要的。
RFID系统中的标签碰撞问题属于多目标识别问题,即 “多路存取”问题。“多路存取”本身就是无线电技术中长期面临的难题。因此,可以通过解决多路存取问题的方法来解决标签的碰撞问题。一般来说总共分4类,即空分多址 (SDMA)法、频分多址 (FDMA)法、码分多址 (CDMA)法、时分多址 (TDMA)法[2]。从RFID的通信形式、系统的构造以及成本问题上来看,TDMA法是最适合的。随着研究的不断深入,时分多址法又可以分为两种不同的算法。不确定性算法、确定性算法[3]。不确定性算法主要是ALOHA类算法,包括纯ALOHA算法、时隙ALOHA算法、帧时隙ALOHA算法等;确定性算法主要是二进制算法,包括二进制搜索算法、动态二进制树搜索算法等。
现在如何提高RFID系统的工作效率成为该技术发展的一个核心话题,为此本文对帧时隙ALOHA算法和二进制搜索算法进行了详细研究,采用标签数量预测判定与分组结合的方式,对其进行改进,形成了一种有效的标签碰撞算法,并对其进行了仿真分析。
1 FSA算法
FSA (Framed Slotted Aloha)算法称为帧时隙ALOHA算法[4],也可以称为固定帧时隙ALOHA算法,这种算法是在纯ALOHA算法的基础上进行改进的一种算法,这种算法把N个时隙绑定成一组形成一帧,其大小在电子标签识别过程中是固定的,并且帧中每个时隙的长度都能保证标签、阅读器之间完成正常的通信过程,然后在一帧内任意选择一个时隙进行标签数据的发送。这种算法适合用于传输标签数量相对较大的场合。
帧时隙ALOHA算法的过程:当电子标签进入阅读器的工作范围时,阅读器把帧内时隙数N发送给标签,标签本身产生一个随机数m (m≤N),并根据自己的随机数选择时隙,当时隙数与m值相等,并且只有一个标签响应,则通信成功,多个标签响应就会发生碰撞,没有响应就是空闲状态;当时隙数与m值不相等时,标签就继续等待。因此,在整个的通信过程中阅读器会接收到标签的3种应答:成功时隙、空时隙、碰撞时隙。假设在标签发送信息的过程中一切的干扰都忽略不计,信息帧的长度为FL,那么,当阅读M个标签时帧内成功时隙数 (S)、空闲时隙数 (B)、碰撞时隙数(C)分别为:
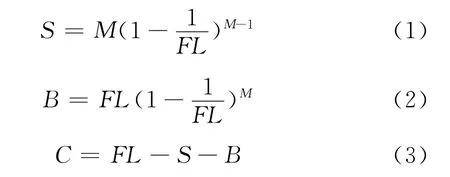
假设系统的固定帧的长度FL=64,利用matlab进行对该算法的正确率 (S/FL)、空闲率 (B/FL)、冲突率 (C/FL)进行仿真,如图1 (a)所示,随着标签数量的不断增加,冲突率也随着增加,当标签的数量在64左右时,系统的识别率最高,正确率最高,约为36.8%;图1(b)中横坐标代表标签的数量,纵坐标代表系统的识别率,3条曲线中FL分别为32、128、256,由图中可以看出当标签数量接近帧长度时系统的正确率最高约为36.8%,并且随着标签的数量的增加,正确率有一定的衰减,这样的结果与图1(a)中结果是一致的。因此,得到结论,固定帧时隙算法当标签数量和帧长度相等时效率最高约为36.8%。
2 二进制搜索算法
二进制搜索算法中,阅读器针对于比特前缀进行查询,当标签的序列号与查询前缀一致时,标签才可以对阅读器进行响应,发送其自身的序列号;当阅读器工作范围内,当且仅当有一个标签响应时,标签就可以成功的被识别出来;当标签的数量>1时,阅读器会自动给查询前缀补一个0,进行下一轮的查询,这样,前缀不断地被增加,直到所有的标签被识别出来,见图2。
通过每一轮减少冲突位的方法是二进制搜索算法的核心,那么二进制搜索算法的关键就是如何发现冲突位,曼切斯特码可以有效地解决这个问题。曼切斯特码的特点就是通过电平的跳变来表示1和0,在传输过程中 “无变化”是不被允许的。因此,选用曼切斯特码来发现冲突位。另外要实现二进制搜索算法,还需要增加一系列的命令:
REQUEST:阅读器发送序列号 (发送请求)。
SELECT:阅读器发送给标签早已经制定好的一个序列号。
READDATA:被选中的标签进行数据的发送,把自身携带的信息传给阅读器。
UNSELECT:这一轮被选中的标签被取消资格,进入 “休息”状态。
二进制搜索算法实现过程:①发送REQUEST命令,要求所有的标签应答,判断碰撞发生位,通过碰撞的情况得到下一次的REQUEST(与第一次发送是不同的);②发送重新制定的REQUEST命令,进行第二次判断碰撞发生位,再一次地修改REQUEST命令,这样不断重复下去,直到阅读器工作的作用范围内只有一个标签响应,这样就完成了一个标签的识别,不断重复以上的步骤,直到阅读器工作范围内所有标签都被识别出来为止。这种二进制搜索算法从N个标签中识别单个标签平均的次数为log2N+1,且每一次标签响应阅读器的命令时所传输的序列号都是完整的,但是这种算法的时延相对来说有些长。
图3是二进制搜索算法的matlab仿真图,由图3可见,标签的数量过大时,系统的工作效率不稳定,标签的数量越大系统的工作效率就越低。
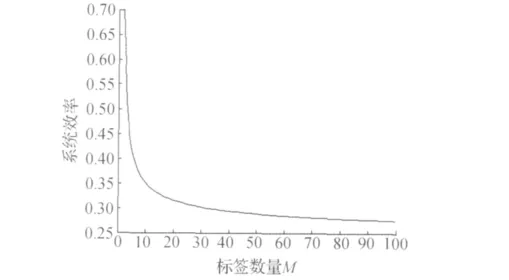
图3 二进制搜索算法仿真图Fig.3 Simulation result of binary search algorithm
3 混合算法
为了更好地解决碰撞问题,所以把帧时隙ALOHA算法和二进制算法进行一定融合与改进,最终改进的的碰撞算法过程分为两个部分:标签数量确定、标签识别。因此,合适的标签数量预测方法与合适的分组方法是决定混合算法效率的关键。
3.1 标签预测方法选择
由于RFID系统工作时,阅读器范围内的标签数量都是未知的,所以要先对工作范围内的标签进行数量的预测,一般有以下几种预测方案:
1)最小预测 (low bound)[5]:当只有一个标签响应阅读器时,不会发生碰撞,但是当标签响应的数量>1时,亦即,当存在>2个标签时就有碰撞问题,因此,基于这种思想估算标签的数量至少为T=2×Sk。
2)Schout预测[6]:通过计算得到一个时隙内,标签的碰撞率约为0.418,那么得到发生碰撞标签的数量为1/0.418=2.392 2,因此,待识别标签数量T=2.392 2×Sk。
3)Vogt预测[7]:VogtⅡ是一种基于概率统计的估算方法,其思想就是通过理论与实际的成功时隙数值、空闲时隙数值以及冲突时隙数值进行对比,得到最小误差的方法来预测标签的数量,通过这种方法预测到的标签数量值,比原来的预测方法得到的结果更加精确。
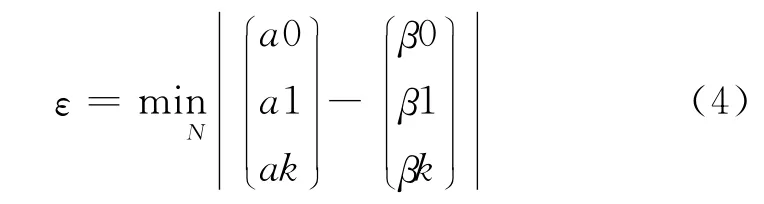
式中a0、a1、ak分别为通过预测得到的实际冲突时隙、成功时隙、空闲时隙的数值。在标签数N取值范围内内找到ε值,这个ε值所对应的N 值就是这种算法预测到的标签数。
经过上面对3种标签数量预测方法的分析,可以发现VogtⅡ算法是采用统计规律进行误差模最小估计方法进行标签数量的预测,结果更加准确。因此,采用VogtⅡ算法来进行标签数量的预测。
3.2 算法描述
在帧时隙算法中可看到标签的比特位数设定为8。因此,帧时隙算法中可设定的最大时隙数为256,以此来界定分组的阈值。通过Vogt方法进行标签数量的预测,当预测到的标签个数<256时,可通过预测到的标签数设置最佳初始帧,并采用FSA算法进行识别,当识别过程中有碰撞产生时,就会进行第二轮的识别;采用二进制搜索算法进行识别,可以有效避免碰撞和提高识别效率。当预测到的标签个数>256时,采取一定的分组策略对其进行平均分组识别,分成的组数为n=即取上正数,且每一组的数量为256。通过实际预测到的标签数,就可得到分成的组数,并且给各个组编号s[1]~s[n],在每一组内部采用二进制搜索算法进行识别,一组识别完成后进入下一组识别,直到所有组的标签都完成识别。
3.3 仿真结果分析
图4是混合算法与二进制搜索算法、FSA算法的软件仿真结果比较,由图4可见,采用改进算法的系统效率由原来最高0.368提高到最高为0.52,而且当标签数量很大时,系统的效率下降相对很慢,从图中得出结论,这种混合的改进算法的效率比二进制搜索算法、FSA算法的效率有了很大的提高,所以采用这种改进的算法更好。
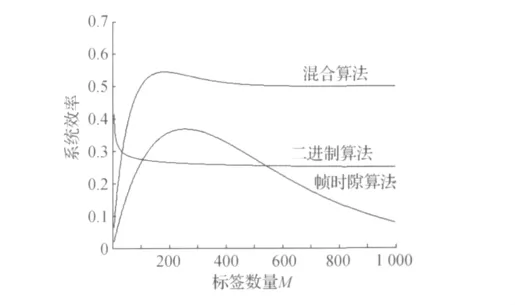
图4 混合算法与传统算法仿真对比Fig.4 Comparison efficiency of improved algorithm and traditional algorithm
4 结 论
混合碰撞算法是在FSA算法与二进制搜索算法基础上提出的,主要是针对于大规模标签进行识别的一种改进型算法。这种算法很好地改善了系统的工作效率问题,即使当阅读器范围内有很大数量的标签时,也能很好地解决碰撞问题。
在RFID系统通信过程中,碰撞问题是需要解决的重要问题,同时碰撞也是影响一个系统稳定性的因素,针对这种情况本文在传统算法的基础上,采用了一种混合的方式来解决系统的碰撞问题,通过仿真证明,这种算法比传统的FSA算法有了明显优势,使系统的性能达到很高,从而更有效的解决了RFID系统中标签的碰撞问题。
[1]Ponnusamy Kumar,A.Krishnan throughput analysis of the IEEE 802.11distributed coordination function considering erroneous channel and capture effects[J].International Journal of Automation and Computing,2011,8 (2):236-243.
[2]Finkenzeller K.RFID handbook,fundamentals and applications in contactless smart cards and identification[K].John Wiley and Sons Ltd,2003.
[3]Tang Z,He Y.Research of multi-access and anti-collision protocols in RFID systems [A].IEEE International Workshop on Anti–Counterfeiting,Security,I-dentification [C].Xiamen,China 2007:377-380.
[4]L.Burdet RFID multiple access methods[R].Technical Report ETH Zurich,2004.
[5]Christian Floerkemeier,Mathias Wille.Comparison of transmission schemes for framed ALOHA based RFID[C]//Application and the Internet Workshops,2006.SAINT Workshops 2006.
[6]Qiaoling Tong,Xuecheng Zou,Dongsheng Liu,et al.Modeling the anti-collision process of RFID system by Markov Chain [A].Wireless Communications,Networking and Mobile Computing [C].WiCom 2007.
[7]Yanfei Li,Hongjun Wang,Hua Li.A RFID algorithm based on cyclic redundancy check[A].Proceedings of the 3rd International Conference on Anti-Counterfeiting,Security,and Identification in Communication[C].IEEE Press Piscataway,NJ,USA,2009.
