网络蠕虫的检测技术研究与系统设计
2012-10-17杨庆涛
杨庆涛
重庆医科大学现代教育技术中心 重庆 400016
0 引言
本文分析了现有的针对网络蠕虫特征的检测方法,涉及到对已知和未知蠕虫的检测。在蠕虫的特征提取技术方面,分析了现有的特征提取方法,同时引入了生物信息学中采用的序列连配算法来进行特征的提取工作,对算法的性能进行分析比较,提出了对算法的改进方法,在对网络蠕虫的检测技术和特征提取的理论分析的基础上,提出了基于上述思想的网络蠕虫检测模型,该模型给出了蠕虫检测的具体实现方法。
1 传统的蠕虫特征检测方法
在对蠕虫病毒进行检测和防御的过程中,都需要对其特点进行研究和发现,而特征码无疑最能反映蠕虫和其他计算机病毒的特点。所谓的特征码可用来对蠕虫和其它的变体进行身份识别,能够反映其攻击特征,在计算机中的组织表现就是一组或者多组的二进制的连续的序列。
所谓的特征提取算法,它的方法就是首先收集可疑的数据包,然后对这些可疑的数据包加以分析比较,从而能够提取出具有一定代表性,能够反映蠕虫传播特点,攻击特点的特征,并最终为蠕虫的检测技术所使用。目前常用特征提取技术包括最大公共子串(Longest Common Subsequence,LCS)提取、基于 Rabin fingerprints算法的对数据流的内容进行有效的划分,采用Expectation Maxmization等。其中最有代表性的是最长公共子序列LCS。采用该方法的时候时间复杂度较高,同时若支持进行聚类分析,则平摊复杂度将更高;若不支持聚类的分析,其混合通信(包括非蠕虫通信、若干蠕虫种类、若干蠕虫变体)将严重影响到特征的提取过程;正是基于这样的考虑我们提出了下面的特征提取的改进方法。
2 改进的序列算法研究
2.1 算法的性能分析
Needleman 算法的思想是基于动态规划的思想,通过使用该算法,我们能够对两个序列进行相似度的比较,同时通过量化的方式,能够计算出它们之间的相似度比值。对这个比值进行比较分析,就得到了一个基于全局的联配结果。
该算法具有两个主要步骤:(1) 计算所给定的两个序列整个的相似分值,并得到一个相似度矩阵;(2) 根据相似度矩阵,按照动态规划的方法回溯寻找最优的联配。我们将通过如下的方式对两个序列的相似度进行计算:
对于序列x和y,序列联配的相似度计算函数定义为:

在上面的定义中,我们引入了分值的概念,以分值的大小来表示序列的相似度。m表示的是两个序列匹配时的得分,而不匹配时的得分用n表示,如果出现空位的话,其分值为δ,由此我们可以计算出相似度比值。
在实际的应用中,若需要对两个序列xi和yi进行序列联配,那么在联配的过程中可以表示为三个序列,分别是x′, y′和s。其中x′, y′分别表示有x,y通过插入一定的空格所产生,s则是联配的结果。s 中包含x′和y′对齐后相同的字母以及通配符“?”和“*”显然s体现了x和y的相似关系,为了对序列的结果进行分析,我们将结果S中被“*”和“?”分开的部分称为片段,而只含有一个字符的片段称为序列碎片。现考虑如下的两个序列xi和yj,xi= NMZTCJPGKYXV和yj=AKYXTNOZUCDP。图1中我们在序列xi的末端插入空位符,在yj的前端插入空位符,由此得到下面两种结果,如图2所示。

图1 联配的结果

图2 联配的结果
在实验中考虑如果序列匹配则m=2,不匹配则n=-2,每出现一个空位符δ=-1,即空位罚分。根据公式1我们将得到如下结果:
联配a的相似度分值S( x, y)=2×4+(-1)×3+(-2)×10=-15 (2)
联配b的相似度分值S( x, y)=2×3 +(-1)×2+(-2)×14=-24 (3)
联配的结果中,联配a的相似度值明显优于联配b的结果。但是,这并不是我们期望的结果,因为没有考虑到序列碎片的问题,序列碎片是由于我们在匹配的过程中不当的添加空位字符造成的。可以看出在联配a中产生了4个序列碎片,而联配b中没有序列碎片。从实际的应用可以判断,联配b明显优于联配a,原因在于:
① 连续的序列片段更能体现数据的语义信息
在两个序列匹配的结果中,序列b中含有连续的字母片段“KYX”,这显然更能反映序列的语义信息。
② 序列碎片容易导致误报的产生
另一个重要的原因在于,序列碎片容易导致误报的产生,若将联配的结果表示成*N*Z*C*P*,将该特征与随机产生的字符长度为1000的字符串比较,将会有38.7%的概率被匹配到。而联配b所表示的特征信息*TWO*只有0.00059%的概率被匹配到。这是因为序列碎片成为了无用的干扰信息,其所产生的攻击特征也很不准确。
2.2 算法的改进方法
由以上分析可知,将 Needleman-Wunsch算法移植到蠕虫病毒特征提取的实际应用中时,由于采用的匹配方式不同,使用该算法所产生的全局最优也很容易易产生序列碎片的情况,也就是采用了匹配结果中匹配字符数较长,相似度比值较高的字符串作为联配的结果,这显然会产生不太理想的情况。为了能够提供序列的匹配精度,使得匹配的结果更为准确,本文提出了一种激励相邻匹配的的全局联配算法。
与 Needleman-Wunsch算法一样,本算法也是采用动态规划的思想,在其的空间和时间的复杂度上都是O(nm)(本处用n和m来分别表示两个序列的长度)。为了使序列匹配上能够使局部较长字符串的到补偿,本文通过加入补偿函数来增加对于局部最优的需求,采用该方法使保留的字符串最优。通过该方式得到的相似度函数如下:

该算法的具体描述为:设具有X和Y的两个序列xi和yj,两个序列之间的相似度为S(x,y)。通过评价x序列中前i个位置和y序列前j位置之间的匹配值,我们可以递归的得到联配的结果F(x,y)。如果x和y的长度分别为m和n,则其期望距离为。在相似度矩阵中引入的第1行1列单元的距离为0(相当于两个空序列进行联配),在单元(i,j)内,使到达该单元距离增加的三种可能事件为:
① 从单元(i-1,j)向单元(i,j)进行垂直移动,相当于在序列X中插入了一个空位使得相似序列得以延伸。
② 从单元(i-1,j-1)向单元(i,j)的对角线进行移动,相当于增加了碱基xi和yj使的相似序列延伸。
③ 从单元(i,j-1)向单元(i,j)的水平移动,相当于在 Y 序列中插入了一个空位使相似序列得到延伸。引入补偿函数ins(S)时,就需要考虑到各种其它的因素进行设置。
因此,单元(i,j)的相似度S (xi,yj)可看成三个相邻单元的相似度值加上相应权重后的最大者,即
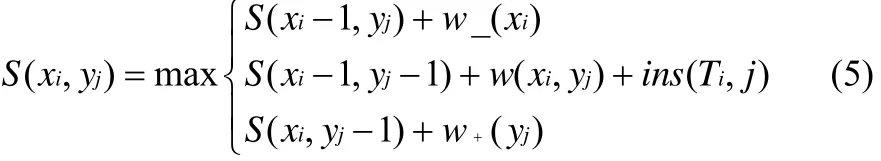
该式的初始条件为:
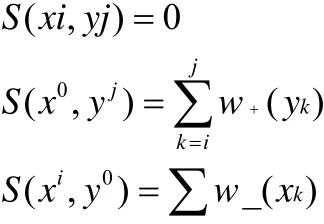
在上面的公式中,对参数进行如下设置:
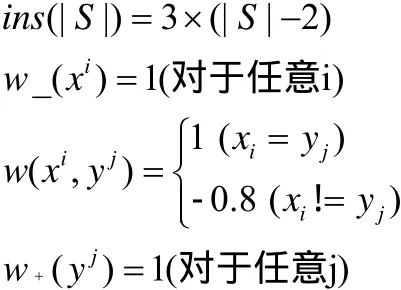
针对联配方式a,由于在其中碎片的存在其值为:

而针对联配方式b我们将得到如下的相似度值:

通过比较可知,补偿函数的引入,能够得到最优的联配结果。
3 蠕虫检测模型设计
为了对特征提取算法进行验证,我们设计了一个蠕虫检测模型。本系统由功能划分明显的几个模块构成,各个模块之间相互协作,能够实现对网络中数据的捕获,到异常的发现和报警,同时能够对数据包中相应的数据特征提取。系统总体结构如图3所示。

图3 系统总体模块结构
该系统由数据捕获,协议分析和异常检测等几个模块构成,尽管本系统只是用于实验性的工作,但考虑到蠕虫发展的现状和以后改进的需要,还是提供了一点的扩展功能。
① 数据包捕获模块。该模块的主要功能是通过在以太网中使用winPcap实现对数据包的捕获功能,为后面进行数据分析提供依据。
② 协议分析模块。协议分析模块是通过数据传输的特点,完成数据包的逆向分析,获取数据包每层的数据信息。
③ 基于贝叶斯的检测模块。通过协议分析模块的实现,我们获取了每层数据包的信息,通过对数据包头信息的分析,我们结合数据的异常检测算法,能够及时的发现潜在的数据威胁并进行有效的报警。
④ 特征提取模块。在数据的异常检测部分,我们完成了对异常数据的检测,但是我们设计系统的目标是为了发现蠕虫的传播和攻击特点,而特征码真是对其特点的最好体现,通过特征信息的提取,为以后的数据检测分析提供了有效的方法。
⑤ 数据库的实现。在数据库的设计方面我们将采用开源软件Mysql来实现。
4 系统测试
为了得到理想的测试效果,本测试利用了赛门铁克蠕虫模拟器的simulatr的蠕虫模拟功能,在地址为192.168.0.199及222的两台机器上启动蠕虫模拟器,通过加载Blaster Worm和MyDoom Worm两个蠕虫程序。系统将会自动模拟这两种蠕虫的传播方式进行传播,其效果如图4所示。

图4 蠕虫模拟程序
在系统检测服务器运行蠕虫检测程序,该程序首先会进行初始化操作,完成系统网卡的选择,然后进入系统等待状态,其进入等待后的状态如图5所示。

图5 系统运行界面
在完成了数据包的捕获后,系统将会根据设置的参数完成对数据的分析工作,上面的图示中显示了系统分析的结果。系统根据捕获数据包的情况,完成了对数据的分析工作,在上图中展示了异常数据的信息,包括其发生的时间,源地址信息,目的地址,所采用的端口及协议信息等。采用同样的方式,我们会看到系统根据异常检测的结果提取的数据的特征信息。其最终的结果如图6所示。

图6 提取的特征信息
Step1:为了对基于序列联配的特征提取进行比较,本文选择了ATPhttpd和BIND-TSIG这两种漏洞来进行攻击测试。ATPhttpd是一款高性能的小型WEB服务程序,远程攻击者可以利用此来进行缓冲区溢出攻击。BIND是一个实现域名服务协议的服务器软件,在TSIG(传输签名)的实现上存在一个缓冲区溢出漏洞,可能允许远程攻击者在BIND服务器上执行任意代码。
Step2:采用了两个不含攻击的数据集 DRAPA96和DRAPA97来进行攻击测试,并采用ADMmutate对数据进行了变形处理,使得对漏洞的攻击能产生多个攻击的样本;

在试验中,本文分别采用了LCS算法,Needleman算法及其改进的激励算法进行了特征的提取工作,表1即为特征提取的结果对比。

表1 提取的攻击特征对比图
从上表中不难看出,当采用改进的 Neeleman算法时,所提取的特征比LCS算法和Needleman算法更为准确。准确性从提取的特征的数量和特征的片段都有所反应。如在 BIND攻击的时候,采用 Neeleman算法所提取的特征少了联系后面 x00 x00 xFA的特征x00。同时,在改进算法的ATPhttpd攻击中,其提取的特征BF ?????????? r n有多个问号,也就是说有多个可变的字符,这也更能反映变形或隐藏攻击的情况。
5 结论
本文通过分析现有蠕虫特征提取方法,引入了生物信息中特征的提取方法,同时针对算法中的不足提出了相应的改进方法。在此基础上设计了网络蠕虫的特征值提取模型。通过测试证明,该模型对已知及未知病毒蠕虫特征的提取都具有一定的参考价值。
[1]Hofmeyr,Forrest S.Architecture for an artificial Immune system[J].Evolutionary Computation.2011.
[2]Vigna G,Kemmerer R A.NetSTAT:a network-based Intrusion Detection System[J].Computer Security.2010.
[3]R.Lo,P.Kerchen and R.Crawford.Towards a testbed for malicious code detection[J].Computer Communication.2010.
[4]AntonChuvakin,GCIA GCIH.Honeynets:High Value Security Data[J].Network Security.2009.
[5]郑辉.Internet 蠕虫研究[D].南开大学.2003.
[6]郑军,胡铭曾,云晓春,郑仲.基于数据流方法的大规模网络异常发现[J].通信学报.2006.
