相似度算法下中文问答系统的设计与实现
2012-10-16刘震肖文显
刘震,肖文显
(河南科技学院,河南新乡453003)
中文问答系统是信息检索技术的一个重要分支,采用全新的检索理论,对现有的基于关键字技术的信息检索的不足之处进行了有效的补充,是新一代信息检索的研究方向[1].
国外在问答系统的研究与应用方面发展较为迅速,这是因为基于英文的句法分析和词法分析都比较成熟,基于英文的语料库和测试语料库也非常多,而且大部分都开源[2],所以国外的问答系统的发展比较领先.相对而言,国内在自动问答系统方面的研究存在着很大的差距.本文在深入研究了大量国内外问答系统的基础上,结合中文信息处理所具有的特点,提出了一个基于语句相似度计算的中文问答系统模型,在些基础上,构建了基于常见问题集的中文问答系统.
1 中文问答系统的理论基础
在中文问答系统中,用户提出问题后,需要从数据库的问题库中查找与用户问题最相似的问句.常规的做法是计算用户问题和候选问题库中同类问句之间的相似度,当相似度超过某个指定的阀值时,相似度最大的就是用户要找的句子;如果用户问题和所有候选问题库中的同类问句之间的相似度都小于阀值,则需要从语料库或网络中检索和摘取相应的答案[3].因此,语句相似度的定义及计算对于中文问答系统来说非常关键.
1.1 知网的结构
知网中有两个主要概念:“概念”和“义原”,分别介绍如下[4]:
(1)概念:描述词汇语义用的,是由词表示的概念标识符.
(2)义原:描述概念中用到的最基本的、不能再分割的最小意义单位.
1.2 中文问答系统的分类
1.2.1 领域分类 中文问答系统按照主题内容所涉及的领域可分为专业领域的问答系统和面向开放领域的问答系统.
1.2.2 特性分类 中文问答系统依据问题类型的特性,参考TREC会议评测的标准,可以将问答系统分为:a.事实性问题问答系统;b.罗列性问题问答系统;c.定义性问答系统[5].
1.3 中文信息处理的特点
中文问答系统相对于西文自动问答系统有以下几个方面的特点[6]:
(1)中文词语之间连续书写,中文分词是中文信息处理的基础,中文问答系统要分析问句和答案,首先要对句子进行分词处理;
(2)中文没有像英语一样的形态变化;
(3)中文句子的语法十分灵活,句子的类型没有办法枚举,句子各成分之间的关系比较复杂,很难发现句子的规律;
(4)缺乏必要的语料库的支持.
1.4 问句特征向量的提取
问句特征向量的提取,是指在中文分词和词性标注的基础上,去掉连词、介词、拟声词等虚词,以及对于区分意义不大的高频词(比如“这一”)和低频词之后形成的关键词序列[7].
2 中文问答系统的模型
2.1 中文问答系统的框架
中文问答系统是信息检索的高级形式,其目的是希望用户使用更为贴切自然语言的方式进行提问,得到的也是一个比较接近自然语言的答案.中文问答系统就是在对用自然语言表达的问句作一定的分析处理,在理解其语义内容的基础上,根据一定的算法或采取一定的策略进行检索,最后把答案从网页或文档中提取出来,呈现给用户.

图1 中文问答系统的整体框架Fig.1 Overall frame-chart of Chinese Q&A system
由图1可知,基于语句相似度的中文问答系统由3部分组成,分别是问句预处理、语句相似度计算和答案抽取.
(1)问句预处理模块主要包括:中文分词和词性标注、问句类型分析、关键词提取和关键词扩展.
(2)语句相似度计算模块主要包括词语相似度计算、词形相似度计算、词序相似度计算、结构相似度计算、句长相似度计算、语义相似度计算和语句相似度计算.
(3)答案抽取模块主要包括相似度排序、强制性关键词筛选、答案输出和用户结果显示.
2.2 问句预处理
中文分词是中文信息处理的基础,由于汉语是分词连写的,要对问句进行理解,还要对分词之后的词语进行词性标注.问句类别确定的目的是确定答案的语义类别以及对问句采用何种策略.在确定问句类别和要搜索的答案类别之后,才可以运用一些特殊的策略和技术去分析问句和进行问句相似度的计算,最终生成问题的答案.经过分词和词性标注之后,进行信息检索的输入部分就是问句的关键词,它直接影响到后面的检索结果.
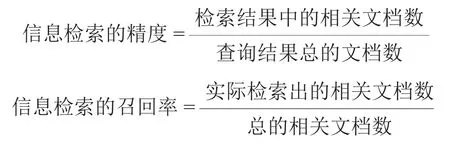
中文问答系统评价的标准是使用该系统进行信息检索的精度和召回率,定义如下:
2.3 多特征加权的语句相似度计算
(1)词语相似度以知网作为系统的语义知识库,主要包括词语相似度计算、义原相似度计算、虚词概念相似度计算和实词概念相似度计算.
(2)词形相似度反映两个句子中词语在形态上的相似程度,以两个句子中所含有相同词的个数来衡量.
(3)词序相似度就是句子A和B的词序相似度.
(4)结构相似度汉语句子结构相似度主要反映两个句子在结构上的相似性,该方法的主要思想是:根据两个汉语句子分词和词性标注之后,所得到的词类序列,结合不同词类的权重,进行词类序列匹配,得到最优的匹配结果.
(5)句长相似度反映两个句子在长度形态上的相似程度.
(6)语义相似度是设两个句子S1和S2,S1包含的词为w11、w12、…、w1m,S2包含的词为w21、w22、…、w2n,则词语 w1i(1≤i≤m)和 w2j(1≤j≤n)之间的相似度表示为 Sim5(w1i,w2j).
(7)语句相似度反映两个句子之间的相似程度.通常表示为0~1之间的一个数值,0表示不相似,1表示完全相似,数值越大表示两个句子越相似.
2.4 答案抽取
系统的关键在于问题句子和数据库中标准问句之间相似度的计算,显示用户结果的时候,需要根据相似度进行排序,另外,系统也需要设置一个阀值threshold,只有语句相似度大于threshold的时候,才输出检索结果.通过强制性关键词表对检索的结果进行过滤,去掉和用户检索结果无关的结果,以用户较为熟悉的论坛风格输出用户检索的结果.为了满足不同用户的浏览习惯,用户可以自己订制检索结果的显示风格,包括:每页显示的记录的条数、页面的CSS风格等.
3 中文问答系统的实现
3.1 数据结构的设计
利用语句相似度计算来实现的中文问答系统,与一些知识库的相关信息都有非常紧密的联系,需要一个数据库来存放,从便于操作和方便的角度出发,我们采用Access 2003作为后台数据库管理系统.3.1.1问题库的分析与表示 对于构建一个基于常见问题集的中文问答系统,首先需要一个常见问题库作为系统的基础支撑,考虑到常见问题可能存在一问多答的现象,所以设计了表1和表2来存储常见问题及其答案.

表1 Questions的存储结构Tab.1 Storage structure of Questions

表2 Answers的存储结构Tab.2 Storage structure of answers Answers
从表1和表2可以看出,两个表之间是通过问题编号这个字段进行关联的,字段Question_Id在表Questions中作为主键,在表Answers中作为外键.
3.1.2 知网的分析与表示 知网是用知识描述语言描述的,给出了义原关系的树状结构表示.中文问答系统采用Java语言实现,为了提高系统的运行效率,需要在程序运行的开始,读入所有的词典内容到内存中.
3.2 问答系统的实现
基于常见问题集(FAQ)的中文问答系统是在已经存在的问题数据库中找到与用户所提问句相匹配的问题,再在答案库中找出与该问题相对应的答案返回给用户.系统分为建立候选问题集、计算语句相似度、FAQ库的更新3个过程来处理.
3.2.1 候选问题集的建立 为了提高检索效率,减小查找的范围和语句相似度计算等这样复杂的处理过程的效率,我们建立了一个候选问题库,使得像计算相度这样繁琐的过程能够在一个相对较小的范围内进行,有利于提高检索的效率.系统选出FAQ库的20%的问句作为候选问题集.针对目标问句中包含的某个词语,想尽快地统计出常见问题库中究竟有多少个问句包含有这个词,我们使用下面的数据结构来实现.
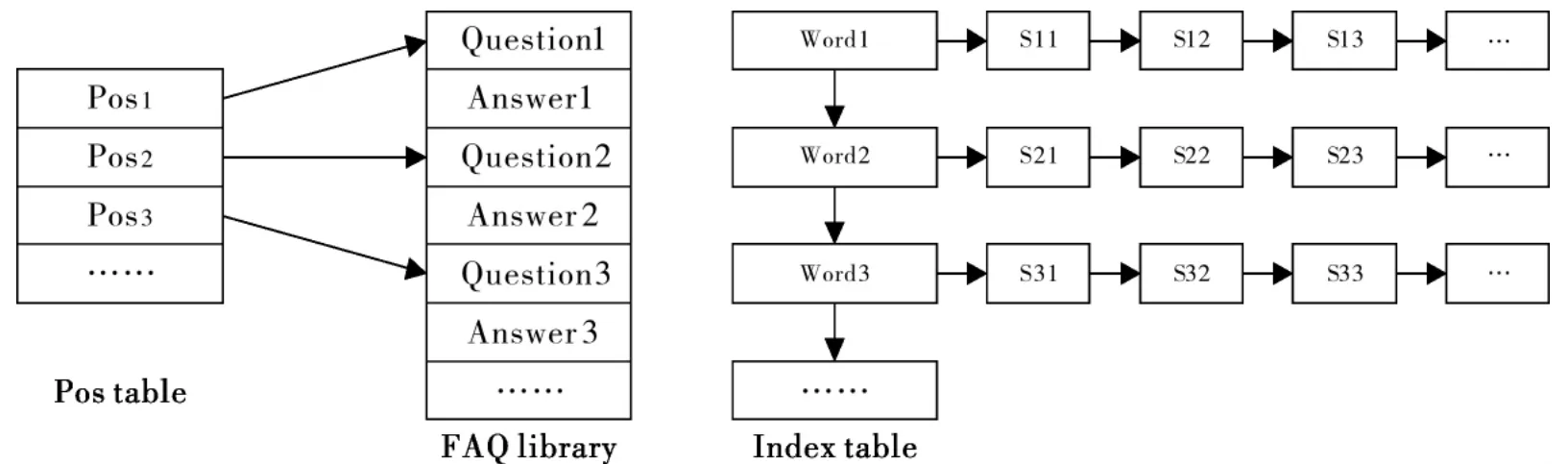
图2 常见问题集的中文问答系统的数据结构Fig.2 Data structures of Chinese question answering system in FAQ
在图2中的FAQ库中记录了所有的Question-Answer对,Pos表则记录了FAQ库中的每个Question在文件中的具体物理位置,反映到关系数据库中记录每个问句的ID号即可,Index表中的Word1,Word2,……是FAQ库中的所有问句包含的词语经过排序后形成的链表.每个Wordi指向一个S链表,这个S链表中的每个节点记录的是FAQ库中含有Wordi的一个问句的句子ID号.
3.2.2 语句相似度的计算 所用的方法是计算候选问题集合中的每个问句和目标问句之间的相似度,然后对计算出来的各种相似度的结果进行加权计算,对应的相似度最大的问句就是我们要找的句子.
3.3 实验结果及分析
信息检索系统总是假定存在一个文档集与用户的查询是相关的,而基于常见问题集的中文问答系统则假定常见问题集中存在一个正确的“答案”.
3.3.1 测试集和评测标准 实验采用的测试集是从某大学校长信箱的“问题-答案”对中经过人工收集整理来的,从而形成常见问题库,共有304个问句.
为了评价基于语句相似度的中文问答系统的性能,构造了两组测试集.第一组是从常见问题库随机抽取了问句124条;第二组是直接从FAQ库中人工选择有代表性的问句60条.评测时为了便于程序自动统计和人工核对,采用类似TREC的S@n(Success at n)方法,即正确答案在前n个结果中的比例.
对错判的评价主要考虑匹配到问句是否为正确答案,系统返回认为正确而实际错误,则认为是发生错误;对于系统没有发现正确的匹配问句不在考察范围内,取S@1.
3.3.2 实验结果及分析 实验采用传统的VSM(向量空间模型)和基于语句相似度计算的问句匹配方法进行测试,评测结果如表3所示.

表3 测试结果Tab.3 Test results
由表3可知,按照两组数据的比较,第一组数据(从常见问题库随机抽取的问句)的S@1值偏低,经仔细分析,发现错误的原因是:一些问题比较随意,包含有用的信息过少,比如:“不公平”这样的问句包含的信息比较随意;另一些问题没有答案,比如:“校长是哪个专业毕业的?”.第二组数据(从候选问题库中选取的问句)的S@1值比较理想,但还是有近30%的问题答案出错.经仔细分析发现,错误的原因一方面是由于问句的类别识别不正确,另一方面是由于问句或答案中含有否定词语,从而导致问句匹配不正确.按照两种相似度方法比较,两组测试集在相似度计算方法有很大的差别:VSM方法主要是从语句表面进行分析,统计词频等信息;而本文基于语句相似度的问句匹配方法,利用了语义知识库,是对语句的深层分析,提高了问句匹配的精度,对于传统的VSM方法有一定的提高和改进.
4 小结
计算机能否实现智能化,最直接的体现就是能否回答人类自然语言的问题.本文通过深入研究中文句子相似度的计算方法,对几种相似度算法进行分析、比较,提出了一个多特征加权的语句相似度算法,并将这种算法应用到中文问答系统,提出了一个中文问答系统模型,实现了简单的中文问答系统.经过实验证明,其问句匹配的准确率明显提高.如果能进一步优化计算效率,将语句的感情色彩考虑进去,那么得到的答案将会达到最优,这些有待于以后加以研究.
[1]张亮,黄河燕,胡春玲.中文问答系统模型研究[J].情报学报,2006,25(2):197-201.
[2]王宇,战学刚,蔡建山.基于网络的中文问答系统的研究[J].计算机工程与应用,2006(7):162-165.
[3]张亮,冯冲,陈肇雄,等.基于语句相似度计算的FAQ自动回复系统设计与实现[J].小型微型计算机系统,2006,27(4):720-723.
[4]周法国,杨炳儒.句子相似度计算新方法及在问答系统中的应用[J].计算机工程与应用,2008,44(1):165-167.
[5]王荣波,池哲儒.基于词类串的汉语句子结构相似度计算方法[J].中文信息学报,2004,19(1):21-29.
[6]吕学强,任飞亮,黄志丹,等.句子相似模型和最相似句子查找算法[J].东北大学学报:自然科学版,2003,24(6):531-534.
[7]江敏,肖诗斌,王弘蔚,等.一种改进的基于《知网》的词语语义相似度计算[J].中文信息学报,2008,22(5):84-89.
