数据挖掘综述
2012-10-10汪明
汪明
(中国矿业大学 管理学院,江苏 徐州 221116)
0 引言
在当今信息爆炸的时代,人类正面临着“被信息所淹没,但却饥渴于知识”[1]的困境。随着计算机硬件技术的快速发展、企业信息化水平的不断提高和数据库技术的日臻完善,人类积累的数据量正以指数方式增长[2]。面对海量的、杂乱无序的数据,人们迫切需要一种将传统的数据分析方法与处理海量数据的复杂算法有机结合的技术。数据挖掘技术就是在这样的背景下产生的。它可以从大量的数据中去伪存真,提取有用的信息,并将其转换成知识。
数据挖掘技术可以用来支持商业智能应用和决策分析,例如顾客细分、交叉销售、欺诈检测、顾客流失分析、商品销量预测等等,目前广泛应用于银行、金融、医疗、工业、零售和电信等行业。数据挖掘技术的发展对于各行各业来说,都具有重要的现实意义。
1 数据挖掘概述
数据挖掘是在大型数据存储中,自动地发现有用信息的过程。在国外,数据挖掘技术已经广泛应用于金融、零售业、电信、保险、医疗服务、体育和政府管理等领域。国内对数据挖掘的研究起步稍晚,近年来对数据挖掘的研究发展较快,所涉及的领域集中在学习算法的研究、数据挖掘的应用和相关数据挖掘理论的研究。然而,目前关于数据挖掘的论文虽多,但与企业结合较少。可以说,目前国内的数据挖掘应用仍停留在初级阶段,行业企业大规模的运用数据挖掘技术尚需时日。
将数据挖掘技术应用于实际项目中,一般都遵循“跨行业数据挖掘标准流程”(如图1所示)。该流程是数据挖掘业界通用推行的标准之一,它强调将数据挖掘用来解决商业实际问题,而不是将数据挖掘限定在研究领域。它是一个不断迭代的过程。
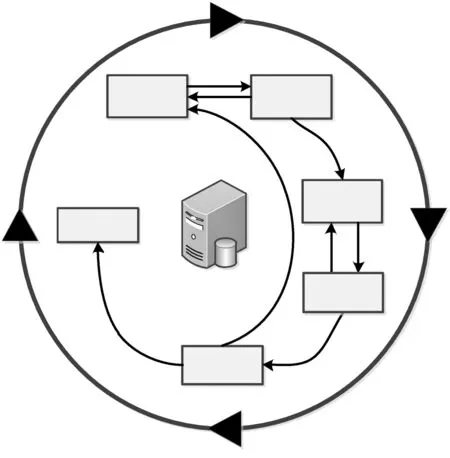
图1 跨行业数据挖掘标准流程(CRISP-DM)
2 数据挖掘方法
数据挖掘从一个新的视角将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能等领域有机结合起来,它能组合各个领域的优点,从而能从数据中挖掘到其他传统方法不能发现的有用知识。这里从数据挖掘任务这一视角来阐述数据挖掘的方法。
2.1 预测建模方法
预测建模分为两大类:分类和回归。回归模型一般分为线性回归和非线性回归,很多非线性模型都可以经过适当的变换转化为线性回归模型[4]。分类模型可以作为解释性的工具,用于区分不同类中的个体,同时也可以用来预测记录的类别。常用的分类技术有:
(1)决策树方法
决策树方法是一种归纳学习算法[3]。在构造的树中,每个叶结点都赋予一个类标识。非叶结点包含属性的测试条件,用于区分具有不同特征的记录。主要的决策树算法有 :ID3、C4.5、CART 和CHAID。
(2)基于规则的分类方法
基于规则的分类方法是使用一组“如果…那么…”规则来对记录进行分类的技术。顺序覆盖算法通常被用来从数据集中直接提取分类规则。另一种更广泛使用的直接规则提取算法叫RIPPER算法。该算法特别适合类分布失衡的数据集,它对噪声数据有很好的容忍度。
(3)支持向量机
支持向量机已成为一种热门的分类技术,它能很好地处理高维数据集,避免维灾难。它可以将分类模型表示为凸优化问题,从而可以利用已知的有效算法发现目标函数的全局最优点,而其他分类算法一般都采用贪心学习的策略来搜索,往往只能发现局部最优解。
(4)神经网络
神经网络是一种模仿动物神经网络行为特征,进行分布式并行处理的算法。反向传播算法是神经网络中采用最多的方法。神经网络的优点是:分类的准确度高,并行分布处理能力强,对噪声数据有较强的鲁棒性和容错能力等。但该方法比较耗时,不适于处理大数据量的数据集。
(5)贝叶斯分类方法
在很多实际应用中,类别属性和其他属性之间的关系是不确定的。贝叶斯分类方法是一种对数据集中属性集和类别变量概率关系建模的方法。贝叶斯分类方法主要有:朴素贝叶斯分类方法和贝叶斯网络方法。
朴素贝叶斯方法假设在估计类条件概率时,属性之间是条件独立的,它对孤立的噪声数据和无关属性具有很好的分类效果。但是现实中,很多情况下独立分布的属性关系是不成立的。贝叶斯网络不要求类的属性是条件独立的,很适合处理不完整的数据集,但是构建合理的网络可能很繁琐。
(6)组合分类方法
组合分类方法由训练集构建多个基分类器,然后通过对每个基分类器的预测进行投票来进行分类的方法,从而提高分类的准确度。实践表明,组合方法往往比单个分类器的效果好。
比较常用的组合方法有:bagging方法、boosting方法和随机森林方法。AdaBoost算法就是一种常用的boosting方法实现。随机森林方法是一种专门为决策树分类器设计的组合方法,它组合了多种决策树的预测。研究表明,随机森林方法在准确度方面可以和AdaBoost相媲美,另外,其运行速度比AdaBoost快。
(7)最近邻分类方法
最近邻分类方法记住整个训练集数据,当测试记录的属性与某个训练集记录完全匹配时才进行分类。在实际应用中,往往找出与测试集的属性相对接近的所有训练集记录即可,这些记录被称为最近邻。记录r的k-最近邻是指与r距离最近的k个数据记录。合理选取k的值很重要,其值太大,最近邻分类器可能会误分测试集记录;其值太小,最近邻分类器易受训练集中噪声的影响而产生过拟合的问题。
2.2 关联分析方法
关联分析方法可以发现隐藏在大型数据集中有意义的联系。这种联系可以用关联规则来表示。在使用关联规则时,需要考虑两个问题:一是从大数据集中发现模式可能效率很低;二是所发现的某些关联可能是毫无意义的。支持度这一度量可以删除那些毫无意义的关联规则,置信度可以度量规则的可能性大小。关联分析的算法主要有:Apriori算法、DHP算法、DIC算法和 FP-增长算法等。
2.3 聚类分析方法
聚类分析是将数据划分成具有意义的组。聚类算法的选择应由数据类型、聚类目的和应用决定。主要的聚类方法有:
(1)划分方法
给定一个有N条记录的数据集,以及要生成簇的数目K。划分方法首先给出一个初始的分组方法,然后通过反复迭代的方式改变分组,使得每一次改进之后的分组方案都比前一次好。该方法常用的算法有:K-Means算法、K-MEDOIDS算法和CLARANS算法等。
(2)层次方法
层次方法是对给定的数据对象集合进行层次分解,层次方法可以分为凝聚和分裂[5]。该方法在合并、分裂的时候要检测大量的记录和簇,因而伸缩性比较差。比较常见的方法有四种:BIRCH、CURE、ROCK 和 Chameleon[5]。
(3)基于密度的方法
基于密度的方法与其他方法的一个本质区别是:它不是基于距离作为相似性度量的,而是基于密度的。这样就能克服基于距离的算法只能发现类球状聚类的缺点。最具代表性的是DBSCAN算法、OPTICS算法和DENCLUE算法[5]。
(4)基于网格的方法
这种方法首先将数据空间划分成有限个单元的网格结构,所有的处理都是以单个的单元为对象。这么处理的一个明显优点就是处理速度很快,通常这是与目标数据集中记录的个数无关的,它只与把数据空间划分的单元数量有关。代表算法有:STING 算法、CLIQUE 算法、WAVE-CLUSTER算法[5]。
(5)基于模型的方法
基于模型的方法给每一个聚类假定一个模型,然后寻找数据对给定模型的最佳拟合。这样的一个模型可能是数据点在空间中的密度分布函数或者其它。通常有两种方案:统计的方案和神经网络的方案。
2.4 异常检测方法
异常检测,也称偏差检测。异常检测的目标就是发现与其它大部分数据点不同的数据点。不平凡的事物往往都具有异乎寻常的重要性。异常检测的方法主要有:
(1)基于邻近度的技术
很多异常检测都是基于邻近度这一度量,通过比较不同对象之间的距离,就可以判断异常对象。异常对象往往是远离其他大部分对象的对象。
(2)基于模型的方法
很多异常检测方法是通过建立一个数据模型,然后用数据去拟合模型,异常点往往是那些同模型不能很好地进行拟合的点。由于异常对象和正常对象可以看成是两个类别,这样也可以用分类技术进行异常检测。
(3)基于密度的技术
对象的密度可以通过计算进行估计,低密度区域的对象相对远离近邻对象,可以将其视为异常对象。更严格来讲,仅当一个对象的局部密度明显地小于它的大部分近邻对象局部密度时,才将其视为异常对象。
3 数据挖掘应用
数据挖掘是面向实际应用的技术,现在已经广泛应用于金融、银行、农业、制造业、零售业、电信、医疗卫生、教育和生物科学等领域。
在信息技术方面,文献[6]将数据挖掘技术应用到搜索引擎领域,从而产生智能搜索引擎,将会给用户提供一个高效、准确的Web检索工具。
在医疗卫生方面,文献[7]探讨了各种数据挖掘方法在生物医学研究领域中的应用,可以用分类方法对疾病进行诊断,用神经网络、支持向量机等数据挖掘方法对某些疾病进行预测,研究表明,预测效果良好。文献[8]在研究MRI乳腺非肿块样强化病灶对乳腺癌的诊断时,发现决策树模型的灵敏度、特异性和准确率等性能均优于传统统计学中的logistic回归模型。
在零售业方面,文献[9]利用SPSSClementine数据挖掘工具,对超市顾客进行分析研究,并提出衡量超市客户忠诚度的忠诚度系数指标,建立忠诚度—盈利性顾客细分模型,运用k-均值算法对超市顾客进行聚类分析,帮助超市准确识别不同类型的顾客群,尤其是忠诚的高盈利顾客。再利用序列分析模型分析顾客类别变化路径,及早发现潜在价值顾客,实现超市利润的有效提升。
在农业建设方面,文献[10]将数据挖掘技术应用于农村建设中,为我国农村信息化建设提供了解决方案,有效解决了农村信息服务“最初一公里”信息采集难和“最后一公里”信息进村入户难的问题,研究表明,这种思路具有很好的推广应用价值。
在电信方面,文献[11]采用数据挖掘技术分析电信客户以往的行为特征来洞察客户的潜在需求,从而有针对性地进行套餐的设计和定价,在风险可控的范围内最大限度地提高客户对套餐的接受度,为客户提供最需要的产品及产品组合,吸引新的客户入网,减少老客户的流失,同时实现电信企业的业务量和收入提升。
在教育方面,文献[12]在分析了当前远程教育网站的不足之处后,将数据挖掘技术应用于远程教育系统中,通过分析大量在线用户信息,提出个性化的教育服务,进而提高远程教学质量。
在金融方面,文献[13]提出了基于数据挖掘的商业银行客户信用风险评级体系,在此基础上,构建了基于BP神经网络的评级模型和基于多种数据挖掘技术的分类结果细化可视化模块,结果表明,数据挖掘技术可以很好地应用于风险评估中。
4 数据挖掘发展趋势
目前数据挖掘技术的研究已成为国内外研究的热点,最近几年在国内发展迅速,今后该领域发展的趋势可能主要表现在以下几方面:
(1)随着互联网技术的发展,网络上的资源越来越多,如何通过数据挖掘技术对互联网上的资源进行挖掘,并从中发现有用的信息,将成为一个热点问题。Web数据挖掘目前的研究虽然比较多,但是还有很多不足,需要进一步研究完善。
(2)数据挖掘算法的改进和数据挖掘可视化。数据挖掘算法一般要处理海量的数据,如何在算法效率和算法准确度之间寻找平衡点,是一个值得研究的课题。另外,数据挖掘结果的友好可视化展现也是一个重要的研究课题。
(3)多媒体数据挖掘。多媒体包含视频、音频、图像等,这些数据的结构往往比较复杂,传统的数据挖掘算法处理多媒体数据效果比较差。为了挖掘多媒体资源,需要设计和开发更好的数据挖掘算法。
(4)数据挖掘和隐私保护。数据挖掘的个人隐私与信息安全问题备受人们关注。误用和滥用数据挖掘可能导致用户数据特别是敏感信息的泄露,越来越多的人对此表示担忧,如何在不暴露用户隐私的前提下进行数据挖掘,将成为非常值得关注的研究课题[14]。
(5)数据挖掘技术与其他系统的集成。数据挖掘应该是一个完整的过程,不单单是一个算法,为了将数据挖掘技术更好地应用于现实生活中,需要研究如何将数据挖掘与其他系统有机地集成,从而最大化地发挥数据挖掘的优势。
(6)空间和时序数据挖掘。空间数据库与关系数据库不同,空间数据库具有丰富的数据类型,带有拓扑、距离信息,空间数据有很强的局部相关性等特点。挖掘空间数据库需要特殊的数据挖掘方法。另外,有一类数据集的数据之间存在着时间上的关系,这类数据被称为时序数据。在对时列数据进行挖掘的过程中,必须考虑数据集数据间存在时间上的关系[15],如何高效地处理空间和时序数据,仍有大量问题需要解决。
(7)流数据挖掘。由于数据流实时、连续、有序、快速到达的特点以及在线分析的应用需求,对流数据挖掘算法提出了很多挑战。目前也有一些流数据挖掘方法,这些方法主要包括概要数据结构、滑动窗口技术、多窗口技术、衰减因子和近似技术等[16]。
(8)适合中小企业使用的数据挖掘系统。目前国外著名的数据挖掘软件有:SAS Enterprise Miner、SPSS Clementine(现被IBM收购并改名为IBM SPSS Modeler)和 RapidMiner(开源)等。除开源软件外,数据挖掘软件一般价格昂贵,中小企业往往望而却步。针对我国中小企业的特点,开发一套适合我国国情的数据挖掘软件具有重要的现实意义。
总之,数据挖掘目前已成为一个热点研究课题。研究数据挖掘具有重要的现实意义。需要注意的是,数据挖掘技术仅仅是一个数据分析工具和方法,得到的结果不是完全正确的,需要结合具体的专业知识和社会大环境等因素分析,才能正确地利用数据挖掘技术来辅助制定决策。
[1]Na isbitt J.Megatrends:Ten new directions transforming our lives[M].New York: Warner Books,1982:16-17.
[2]王光宏,蒋平.数据挖掘综述[J].同济大学学报,2004,32(4) :246-251.
[3]张君枫.数据挖掘算法综述[J].电脑学习,2010(4):120-121.
[4]孟晓东,袁道华,等.基于回归模型的数据挖掘研究[J].计算机与现代化,2010(1):26-27.
[5]刘克准,廖志芳.数据挖掘中聚类算法综述[J].福建电脑,2008(8):5-6.
[6]杨占华,杨燕.数据挖掘在智能搜索引擎中的应用[J].微计算机信息,2006,22(4-3):244-246.
[7]龚著琳,陈瑛,等.数据挖掘在生物医学数据分析中的应用[J].上海交通大学学报(医学版),2010,30(11):1420-1423.
[8]谭红娜,苏懿,等.数据挖掘技术判定MRI乳腺非肿块样强化病灶的初步研究[J].中华放射学杂志,2009,43(5):455-459.
[9]肖生苓,牟娌娜,等.基于数据挖掘技术的超市顾客群研究[J].资源开发与市场,2011,27(08):683-685.
[10]张伟,欧吉顺,等.利用数据挖掘技术建设农业智能综合信息服务平台[J].农业网络信息,2011(8):34-36.
[11]潘宇曦,叶宇航,等.基于数据挖掘的电信行业精确化套餐设计方法研究[J].情报杂志,2011(30):123-125.
[12]王岚,王萍.数据挖掘在远程教育系统中个性化教育的应用研究[J].计算机工程与科学,2008,3(10):93-95.
[13]蔡皎洁,张玉峰.基于数据挖掘银行客户信用风险评级体系研究[J].情报杂志,2010,29(2):47-50.
[14]钱萍,吴蒙.同态加密隐私保护数据挖掘方法综述[J].计算机应用研究,2011,28(5):1614-1617.
[15]贾澎涛,何华灿,等.时间序列数据挖掘综述[J].计算机应用研究,2007,24(11):15-17.
[16]孙玉芬,卢炎生.流数据挖掘综述[J].计算机科学,2007,34(1) :1-5.
