洪水频率分布的尾指数估计
2012-09-26欧阳资生
欧阳资生,甘 柳
0 引言
在各种水利规划设计中,都需要进行水文频率分析工作,以保证达到工程要求的设计值。而在洪水频率分析中,无非是讨论像洪水或超出某一警戒水平的水位或流量的分布情况。在极值统计中,像洪水等这类事件发生频率很低,但是一经发生就容易造成较大损失的事件叫极值事件。事实上,在洪灾风险管理中,如何发现这些极值事件的发生概率和某个极值分位数点对风险管理者是相当重要的。我们知道,从极值理论的角度来看,这些极值事件的概率和极值分位数被一种称为极值分布的尾指数所控制。对于正态分布,它的尾部呈指数函数衰减,其尾指数为零。当尾指数大于零时,分布尾部呈幂函数衰减,我们称其为厚尾分布。厚尾模型在诸如金融、保险、水利等很多场合都是一个应用非常广泛的分布模型。厚尾分布中,尾指数越大,其尾部越厚。因此尾指数可作为衡量洪水分布规律的重要指标。
假设X1,X2,⋅⋅⋅,Xn是一列正的,独立同分布的随机变量序列,具有共同的分布函数F(x):
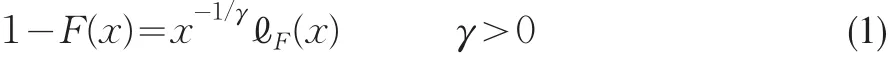
则分布函数F(x)被称为厚尾的。模型(1)的F(x)也称为Pareto型分布。ℓF是无穷远处的缓变函数,满足对所有的η>0:

这里,γ称为极值指数,而如果令α=1/γ,则α称为尾指数。尾指数或极值指数的估计目前仍然是极值统计的一个热点问题。如Danielsson(2001)利用自助法研究了尾指数的估计问题。Beirlant et al.(2008)提出了一种修正的偏差减少方法对尾指数和极值分位数进行估计。Beran and Schell(2010)在小样本情况下构造了一个稳健的M估计方法对尾指数进行了估计。Brito and Freitas(2010)研究了相依数据尾指数估计的相合性问题。但总的说来,对尾指数或极值指数的的估计,不外乎是Pickands估计、Hill估计和矩估计三种估计及其拓展估计方法。在这三种估计中,Hill估计和矩估计实际应用中相对较多,而Pickands估计实用性并不强,基本不用。
如果设:

为 n个观测值 X1,X2,⋅⋅⋅,Xn的顺序统计量,Hill估计定义为:

Hill估计虽然在理论上具有很好的大样本性质,但是在实际应用中,并不好操作,我们可以从图1就可很容易理解。

图1 极值指数的Hill估计图
图1 是我们利用学生-t4分布对Hill估计结果作的一个随机模拟,我们作了200次随机模拟,每次模拟的样本量是500,我们给出了模拟的200次估计的1/4分位数,中位数和3/4分位数,在学生-t4分布中,极值指数的真值γ=0.25,但是极值指数的真值到底取多少,我们从图1中很难做出判断。换句话说,我们不知道门限值取多大时才能对样本进行有效分割。事实上,如何选取合适的门限值是估计极值指数或尾指数的基础,也是我们进行洪水频率分析的必要程序。
本文中,我们将基于指数回归模型,给出矩估计的门限值和样本点分割的选取原理和方法,然后利用MC方法进行模拟说明门限值选取的合理性,最后利用所构建的模型对湖南省四个水文观测站的水文数据进行实证分析。
1 尾指数估计的统计建模
通过前面的模拟,我们看到Hill估计并不好操作,门限值选择不当将导致极值指数估计的较大偏差。事实上,极值指数三种估计方法中,矩估计相对来说较为稳健,实际应用中也相对较多。因此,本文我们采用矩估计来估计极值指数和尾指数。
矩估计由Dekkers、Einmahl&de Hall(1989)提出,其定义为:对 k∈{3,⋅⋅⋅,(n-1)}

尽管矩估计较Hill估计稳健,在理论上也具有更好的大样本性质,但是在实际应用中,也同样存在门限值选取的问题。我们可以从图2就很容易发现,虽然相对Hill估计而言,矩估计要稳健得多,但是门限值的选取问题仍然是一个需要解决的问题。

图2 极值指数的矩估计图
图2 是我们利用学生-t1分布对矩估计结果作的一个随机模拟,我们同样作了200次随机模拟,每次模拟的样本量大小为500,我们给出了模拟的500次估计的中位数。在学生-t1分布中,极值指数的真值为γ=1。虽然比起Hill估计而言要稳健得多,但是,极值指数的真值到底取多少,我们从图2中也不好判断。换句话说,我们不知道门限值取多少时,才能对样本实现最优分割。
和其他估计一样,在用矩估计对尾指数进行估计时,首先是确定门限值,找出超出门限值以上的观察数据;也就是对所观察到的样本值的顺序统计量进行有效分割,得到用于估计的观察数据,然后才能进行估计。但需要指出的是,门限值的选取问题却一直是困扰极值工作者的一个难题。门限值越大,可以分析的数据越少,这时,被分析的数据比较接近分布的极端,分析的偏差减少,但由于数据过少,估计的方差增加;反之,门限值过小,被分析的数据增加,分析的方差减少,但偏差却增加了。对这个问题的研究,统计工作者提出了许多方案。如Dupuis(1998)建议从参数的稳健性出发来确定门限值;Guillou(2001)、Matthys&Beirlant(2003),Beirlant et al.(1996,2004),欧阳资生(2008)等建议使用最小化均方误差或渐近二阶矩来获得门限值;Gomes et al.(2008)建议使二阶参数估计的偏差达到最小从而通过一个启发式适应过程得到门限选择方法;Vandewalle et al.(2008)通过使PDC估计(partial density component estimation)的积分均方误差达到最小来获得门限值,对样本进行分割。
采用SPSS 19.0软件对数据进行分析处理,计量资料以(均数±标准差)表示,采用t检验;计数资料以(n,%)表示,采用χ2检验,以P<0.05表示差异具有统计学意义。
下面:我们将基于指数回归模型,在渐近最小均方误差的准则下,给出矩估计的门限值和样本点分割的选取原理和方法,并提出极值指数和尾指数估计的算法。
对于随机变量序列X1,X2,⋅⋅⋅,Xn的分布函数F(x),如前所述,我们假设F(x)是Pareto型的,其原因主要是基于Pareto型在极值分布中的地位和作用。我们知道,这种分布在金融、保险、水利中都被广泛应用。例如,在巨灾统计数据中,有一个广为人知的事实,即巨灾统计数据是厚尾的,因此,可以直接假设巨灾统计数据分布服从Pareto分布。
对于模型(1)中的缓变函数,有一个被广泛接受的假设:
假设ℜλ:存在一个实常数ρ<0和一个正的比率函数b(x),满足当x→∞时,b(x)→0,且使得对所有的η≥1,

其中 kρ(η)= ∫1ηvρ-1d v=(ηρ-1)/ρ ,若 ρ=0 ,则 kρ(η)=log(η)。需要说明的是,假设ℜλ条件并不苛刻,一般的缓变函数均能满足这个条件。
在假设ℜλ下,我们按照Beirlant et al.(2004),欧阳资生(2008)的指数回归模型方法来选取k,从而进一步确定参数 γ̂k,b̂n,k,ρ̂k。为此,建立如下指数回归模型:

这里,f1,f2,⋅⋅⋅,fk是一列独立的,服从标准指数分布的随机变量。在式(6)中,利用最大似然估计,得到参数γ,bn,k,ρ的估计值:

类似于Beirlant et al.(2004),欧阳资生(2008),我们可得在指数回归模型中,极值指数用矩估计作为估计量时的AMSE为:

因此,样本的最优分割k̂optn为:
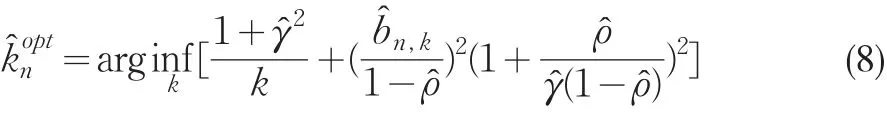
因此,根据以上原理,我们可得基于指数回归模型的样本分割方法,进而得到尾指数的矩估计的算法,算法如下:
(1)对指数回归模型式(6),利用极大似然估计,对k∈{3,⋅⋅⋅,(n-1)}计算参数 γ ,bn,k,ρ 的估计值{(γ̂k,b̂n,k,ρ̂k),k∈{3,⋅⋅⋅,(n-1)}
(2)对 k∈{3,⋅⋅⋅,(n-1)}计算 AMSE(γ̂Mk)
(3)利用
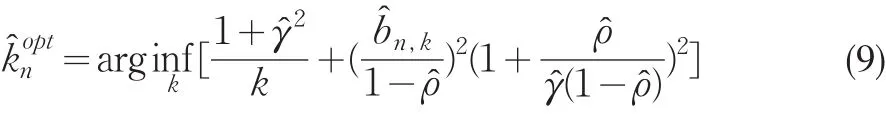
获得 k̂optn
(4)根据矩估计式(4)和步骤3的最优k̂optn,可得极值指数的最优估计和尾指数估计α̂。
2 随机模拟
现在,为验证我们的模型,我们对下列极值分布进行蒙特卡洛模拟:
(1)Burr(1,1,1)分布。 Burr(θ,τ,λ)分布的分布函数满足:

(2)Burr(1,0.5,2)分布
(3)Frechet(1)分布.Fre ch et(γ)分布的分布函数满足:

(4)Frechet(2)分布
(5)学生-t4分布

表1 极值指数估计及其误差估计模拟结果表
在蒙特卡洛模拟时,我们对每一种分布作了500次模拟,每次模拟的样本量均为1000。表1分别给出了500次模拟中相应的最优k值、γ的估计值的平均及其标准差、AMSE的平均。从表1可以看出,在矩估计中,借助于指数回归模型获得门限值、样本点分割方法和极值指数估计值,其结果是令人非常满意的。
3 湖南省洪水频率分析的实证分析
3.1 数据描述
作为模型的一个应用,我们对洞庭湖周边的桃源、津市、沙头、石龟山等四个站点的水文数据中的水流量进行实证分析。数据跨度为1998年元月1日至2010年4月1日共4316个日数据。为对数据的基本情况有一直观了解,我们在表2中列出了相应的统计量。同时,也绘画了其相应的时间序列图(图3)。从表2可以发现,这四个站点的数据均呈现明显的厚尾现象,同时,从图3也可看出其波动明显。
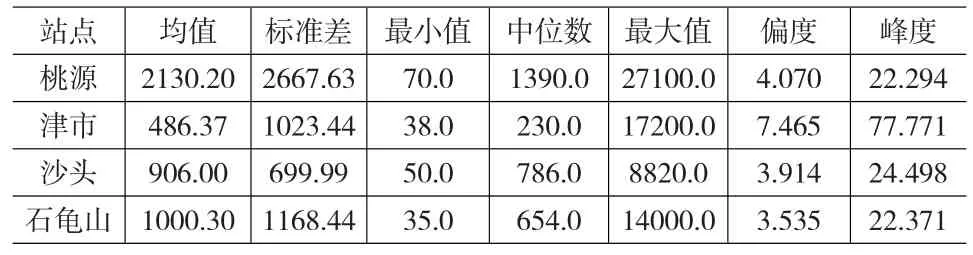
表2 洞庭湖周边的四个水文观测站水流量基本统计特征

图3 (1998.1.1-2010.4.1)洞庭湖周边四个水文观测站水流量时间序列图
3.2 尾指数的估计
根据前文的极值指数估计模型和计算方法,我们首先可以得到样本的最优分割方法从而得到超出门限值的样本个数,然后得到极值指数的估计值,最后利用α̂=1/γ̂即可得湖南省四个水文观测站点的水流量分布的尾指数估计。
在图4中,我们给出了k=1,2,...,4310时极值指数的估计图,其中虚线代表了最优的k值。而表3分别给出了这四个站点在最优的k值下的极值指数和尾指数最优估计值,从表3可以看出,桃源站的尾指数是最大的,津市的尾指数是最小的。
两点说明:(1)从前文对学生-t1分布的极值指数的随机模拟图2可看出,即使是估计时相对稳健的矩估计也不好直接判断尾指数的真值,这点在图4中也得到了印证。从图4中,如果没有一定的准则,我们是无法获知在何时对样本实施分割,也就无法得到各个站点水流量数据的尾指数的真值了。但是,如果我们借助于指数回归模型,采用使矩的AMSE达到最小作为评价标准,我们就可以很好地解决一个问题。(2)正如Beirlant et al.(1996,2004)在借助指数回归模型对尾指数进行Hill估计时作的评述,指数回归模型相对来说,较为稳健。同时,由于有效的利用了极大似然估计,因此计算的速度也较快,这也是我们在进行矩估计时,借助指数回归模型进行建模的主要原因。

图4 洞庭湖周边的桃源等四个水文站点水流量数据的极值指数估计图
4 结论
以上四个水文观测站点都是位于洞庭湖地区周边站点,由前面的分析结果可以发现,四水系流域的水位变化情况均为厚尾分布,都可以通过极值分布加以较好地拟合。当然,流经不同站点的水流量是不一样的,且不同规模洪水流量的变化幅度亦有所区别,因此在实施防洪措施时应实事求是,依据不同的情况有区别的对待,这样才能既做到全面有效防洪减灾又能尽可能的降低不必要投入,减少浪费。
[1]Beirlant,J.,Figueiredo,F.,Gomes,M.I.,Vandewalle,B.Improved Re⁃duced-bias Tail Index and Quantile Estimators[J].J.Statist.Plann.and Inference,2008,138.
[2]Beirlant,J.,Goegebeur,Y.,Segers,J.,Teugels,J.Statistics of Ex⁃tremes.Theory and Applications[M].NewYork:Wiley,2004.
[3]Beirlant,J.,Vynckier,P.,Teugels,J.L.Tail Index Estimation,Pareto Quantile Plots,and Regression Diagnostics[J].J.Amer.Statist.Assoc,1996,91.
[4]Beran,J.,Schell,D.On Robust Tail Index Estimation.Computational Statisticsand Data Analysis,doi:10.1016/j.csda[J].2010.
[5]Brito,M.,Freitas,A.C.Consistent Erstimation of the Tail Index for De⁃pendent Data[J].Statistics and Probability Letters,2010,(80).
[6]Danielsson,J.Using a Bootstrap Method to Choose the Sample Fraction in Tail Index Estimation[J].Journal of Multivariate Analysis,2001,76.
[7]Dekkers,A.,de Haans,L.A Moment Estimator for the Index of an Ex⁃treme-value Distribution[J].Ann Statist,1989,17(4).
[8]Dupuis,D.J.Exceedances over High Thresholds:a Guide to Thresh⁃old Selection[J].Extremes,1998,3(1).
[9]Gomes,M.I.,Henriques Rodrigues,L,Vandewalle,B.,Viseu,C.A Heu⁃ristic Adaptive Choice of the Threshold for Bias-corrected Hill Esti⁃mators[J].J.Statist.Comput.And Simulation,2008,78(2).
[10]Guillou,A.,Hall,P.A Diagnostic for Selecting the Threshold in Ex⁃treme Analysis[J].J.R.Statist.Soc.Ser B,2001,63.
[11]Matthys,G.,Beirlant,J.Estimating the Extreme Value Index and High Quantiles with Exponential Regression Models[J].Statistica Si⁃nica,2003,13.
[12]Vandewalle,B.,Beirlant,J.,Christmann,A.,Hubert,M.A Robust Estimator for the Tail Index of Pareto-type Distributions[J].Compu⁃tational Statistics&Data Analysis,2007,51.
[13]欧阳资生.厚尾分布的极值分位数估计与极值风险测度研究[J].数理统计与管理,2008,27.
