计算机等级考试中的关联规则挖掘
2012-09-21曾旭
曾 旭
(遵义医学院医学信息工程系,贵州遵义 563003)
数据挖掘是从大量数据中发现有趣模式,其中数据可以存放在数据库、数据仓库或其他信息库中。这是一个年轻的跨学科领域,源于诸如数据库系统、数据仓库、统计学、机器学习、数据可视化、信息检索和高性能计算。其他有贡献的领域包括神经网络、模式识别、空间数据分析、图像数据库、信号处理和许多应用领域,如商务、经济学和生物信息学[1]。
数据挖掘的类型很多,如总结规则挖掘、关联规则挖掘、分类规则挖掘、聚类规则挖掘、预测分析、趋势分析和偏差分析等。其中关联规则挖掘时近几年研究较多应用最为广泛的应用[2]。
1 基本术语
关联规则的概念是由Agrawal等[3]提出的,是数据之间一种简单实用的规则,是指数据对象之间的相互依赖关系[4]。关联规则挖掘是从数据中挖掘出满足一定条件的依赖性关系。关联规则挖掘的主要对象是事务数据,是形如“X⇒Y,支持度=s%,置信度=c%”的规则。
1.1 置信度
全体事务集D中支持物品集X的事务中,有c%的事物同时也支持物品Y,则 c%称为关联规则X⇒Y的置信度,置信度表示规则的强度,用confidence(X⇒Y),其中,最小置信度用min-conf表示。

1.2 支持度
全体事务集D中有s%的事务同时支持物品集X和Y,则称s%为关联规则X⇒Y的支持度,支持度表示规则的频度,用support(X⇒Y)表示,其中最小支持度用min-sup表示。support(X⇒Y)=P(X∪Y)
1.3 频繁项集
物品集X的支持度support(X)不小于最小支持度min-sup,则称 X为频繁项集。支持度和置信度均大于给定的阈值的规则称为强规则,数据挖掘主要是关于强规则的挖掘。通常的关联规则可以用如下数学模型描述:I={i1,i2,…,in}为数据项集,D为全体事务集合,每个事务 T有一个唯一标识Tid,对数据项集X⊆I,Y⊆I,称X包含于Y,当且仅当X⊆Y。关联规则形式:(X⇒Y,support(X⇒Y)=s%,confidence(X⇒Y)=c%),这里X⊆I,Y⊆I且X∩Y=Φ,X称为规则的条件,Y称为规则的结果。关联规则挖掘的一般步骤:
(1)找出事务数据库中所有频繁项集
(2)用频繁项集产生强关联规则,即:对于每个频繁项集X,如Y⊆X,Y≠Φ,且confidence(Y⇒(X-Y)≥min-conf),构成关联规则 Y⇒(X-Y)。
这两步中,第二步最容易,挖掘关联规则的总体性能由第一步决定。下面介绍经典的频繁项集算法Apriori算法。
Apriori算法使用一种称作逐层搜索的迭代方法,k-项集用于探索(k+1)-项集。首先,找出候选1-项集C1,由 C1生成频繁1-项集L1;利用频繁1-项集L1生成候选2-项集 C2,由 C2生成频繁2-项集L2;如此下去,直到不能找到频繁k-项集。找每个 Lk需扫描一次数据库。
2 关联规则对评分结果的分析
将上述关联规则的挖掘算法应用于遵义医学院计算机等级考试评分系统中,根据该校现有的考试数据可以获得一些关联规则。现以2010级临床专业全体440名学生的考试数据为例,采用Apriori算法进行选择题、Windows操作题、打字题、Word操作题、Excel操作题和网络操作题共6个属性间的关联规则的挖掘。具体数据整理成表1,共包含440条相关记录。由于篇幅关系,文中只列出原表的基本结构和表中的部分数据,如表1所示。

表1 计算机等级考试原始数据
2.1 数据预处理
为了更好的进行关联规则分析,需对数据进行概化,概化过程遵循的原则是:将得分率低于0.6的题概化不合格,否则概化为合格。具体处理方法如下:
选择题概化规则:分段概化为 A0(小于12分),A1(12-20分)。
Windows操作题概化规则:分段概化为B0(小于6分),B1(6-10分)。
打字题概化规则:分段概化为C0(小于9分),C1(9-15分)。
Word操作题概化规则:分段概化为D0(小于15分),D1(15-25分)。
Excel操作题概化规则:分段概化为E0(小于12分),E1(12-20分)。
网络操作题概化规则:分段概化为F0(小于6分),F1(6-10分)。
由关联规则的概念,Apriori算法的规则和概化后的结果,可得出项目集合为:
{A0 、A1 、B0 、B1 、C0 、C1 、D0 、D1 、E0 、E1 、F0 、F1}

表2 计算机等级考试概化后数据
2.2 关联规则挖掘过程
现对表2用Apriori算法找出所有频繁项集,设min-sup=30%,可得候选1-项集C1,如表3所示。

表3 候选1-项集 C1
由候选1-项集C1可得频繁1-项集L1,如表4所示。

表4 频繁1-项集 L1
由频繁1-项集L1可得候选2-项集C2,如表5所示。
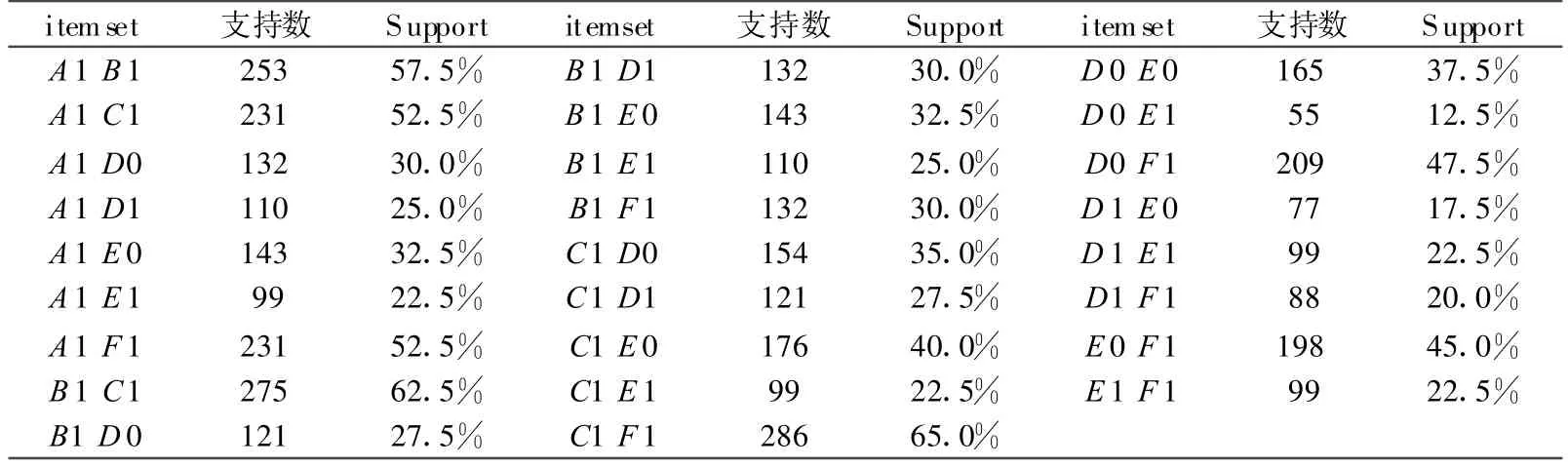
表5 候选2-项集 C2
由候选2-项集C2可得频繁2-项集L2,如表6所示。
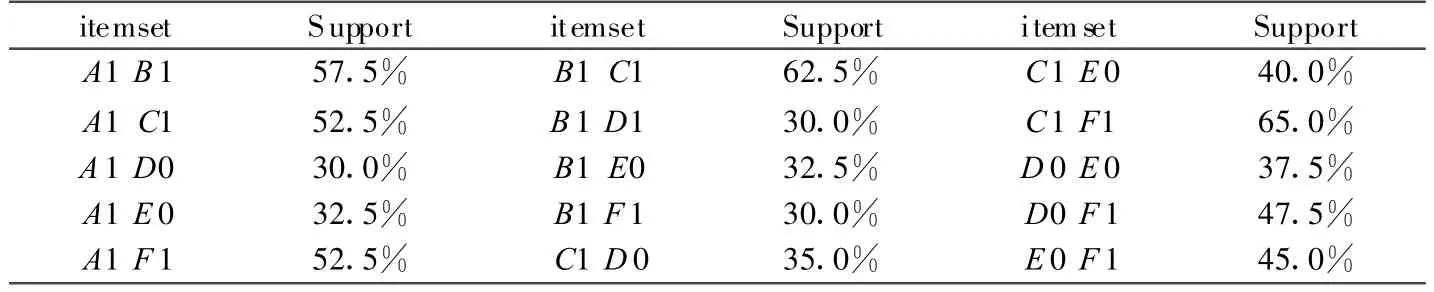
表6 频繁2-项集 L2
由频繁2-项集L2可得候选3-项集C3,如表7所示。
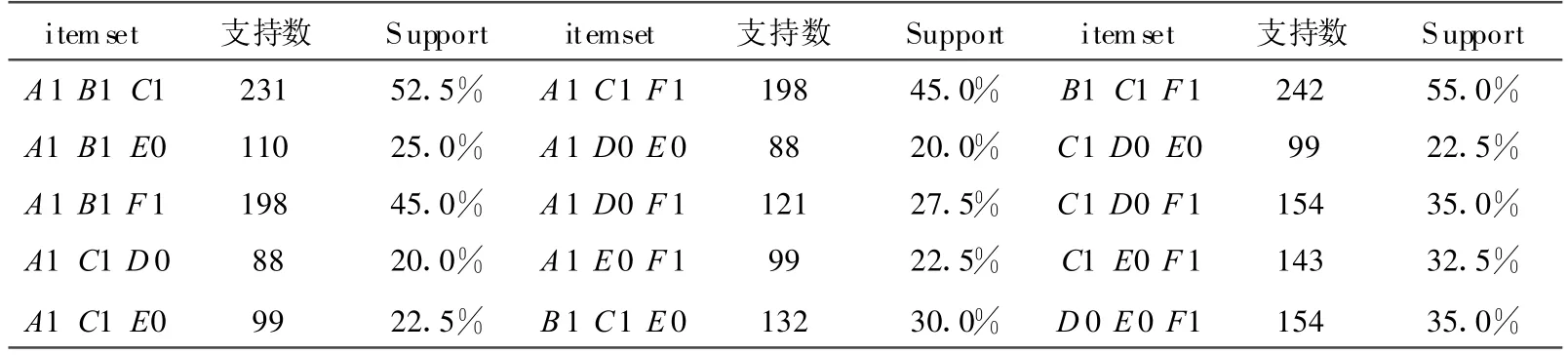
表7 候选3-项集 C3
由候选3-项集C3可得频繁3-项集L3,如表8所示。

表8 频繁3-项集 L3
由频繁3-项集L3可得候选4-项集C4,如表9所示。
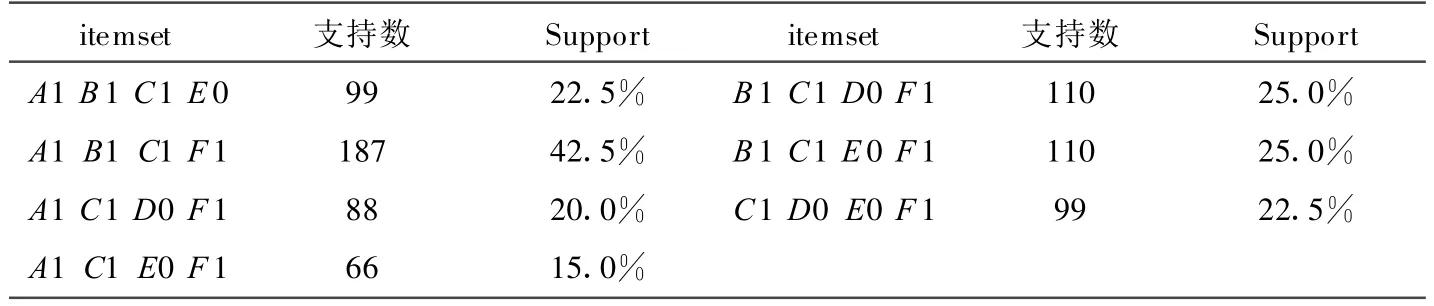
表9 候选4-项集 C4
由候选4-项集C4可得频繁4-项集L4,如表10所示。
2.3 关联规则挖掘结果分析
从众多频繁项集中,可以发现比较有代表性的两项:支持度为42.5%的A1 B1 C1 F1以及支持度为37.5%的D0 E0,这两项频繁项集的置信度如下:
(A1 B1 C1)⇒F1,confidence=187/231=81.0%
(A1 B1 F1)⇒C1,confidence=187/198=94.4%
(A1 C1 F1)⇒B1,confidence=187/198=94.4%
(B1 C1 F1)⇒A1,confidence=187/242=77.3%
(D0)⇒E0,confidence=165/264=62.5%
(E0)⇒D0,confidence=165/286=57.7%
在设置最小置信度min-conf=30%,最小支持度min-sup=60%的前提下,以上7条规则中前6条形成强规则。即:选择题、Windows操作题、打字题、网络操作题的合格情况是相互关联的,考生在对这4种题型的把握过程中能够相互促进和提高。另外,Word操作题和Excel操作题的不合格情况是存在关联的,考生若对Word操作题存在欠缺,那么同时也会对Excel操作题存在欠缺。

表10 频繁4-项集 L4
3 结束语
对考生的计算机等级考试中各类题型的得分情况进行关联规则挖掘后所得到的结果能够帮助考生在学习过程中更注重题型之间的相关性并明确自己可能存在缺欠,便于查漏补缺。与此同时,教师也可在后继教学过程中重点把握各类题型的相关性,帮助学生重点把握丢分环节并顺利通过考试以提升过级率。此结论对考生和教师来说均具有一定的指导性。
[1] RICHARD J ROIGER,MICHAEL W GEATZ.数据挖掘教程[M].北京:清华大学出版社,2003.
[2] JIAWEI HAN,MICHELINE KAMBER.范明,孟小峰等译.数据挖掘:概念与技术[M].北京:机械工业出版社,2001.
[3] 张瑶,陈高云.数据挖掘技术在试卷分析中的应用[J].西南民族大学学报,2008,34(4):839-842.
[4] 陈辉,向伟忠.关联规则挖掘在教师教学评价系统中的应用[J].南华大学学报,2005,19(1):104-108.
[5] 接励,王虹.高校人事管理信息心中的关联规则挖掘[J].天津师范大学学报,2004,24(2):64-66.
[6] 胡可云,田凤占.数据挖掘理论与应用[M].北京:清华大学出版社,2008.
[7] 周贤善,杜友福.高置信度关联规则的挖掘[J].计算机工程与应用,2010,46(24):151-154.
[8] 张云涛,于治楼.关联规则中频繁项集高效挖掘的研究[J].计算机工程与应用,2011,47(3):139-141.
[9] 马青霞,李广水.频繁模式挖掘进展及典型应用[J].计算机工程与应用,2011,47(15):138-143.
