基于Gnutella的P2P搜索改进算法的研究
2012-09-15吴俊丰王春枝
吴俊丰,王春枝
(湖北工业大学计算机学院,湖北 武汉430068)
1 Gnutella协议
1.1 Gnutella网络协议体系
在以Gnutella网络为代表的分布式非结构化对等网络模型中,所有的客户端也是一个服务器,同样反之亦然,因此他们被称为对等机(servent).他们通过相互的连接遍历整个网络.Gnutella协议定义了这些网络中的对等机的通信方式.这些协议工作在位于TCP/IP层上的应用层.该协议包括对等机间通信描述符集(服务原语集)和相应的通信规则集.一台新的对等机通过与当前处于Gnutella网络中的任何一台活动对等机建立一个连接,从而加入Gnutella网络[1].
1.2 传统Gnutella协议的查询机制
传统的Gnutella网络采用flooding即洪泛式的查询机制.在Gnutella网络中存在4种信令消息,包括 PING,PONG,QUERY,QUERYHIT,PUSH消息.各个消息的说明见表1.

表1 Gnutella网络中各种信息的说明
在Gnutella网络中,当一个节点需要查询数据文件时,会采用泛洪式的查找查询方式,即该节点先把查询消息(Query)发送到自己的邻居节点,邻居节点首先查找自己的数据列表,如果发现要查询的数据,就返回一条确认消息(QueryHit),否则就把这条信息转发给自己的直接邻居.在转发过程中,节点会检查并修改Query消息头的TTL字段,如果发现消息的TTL为0,则直接丢弃该消息.当首先发起查询的节点收到QueryHit消息后,就可直接与回复QueryHit消息的主机建立连接,下载所需的文件.对于在NAT或防火墙后的主机,可以采用“推送”的方式来下载数据文件,即查询节点发送Push请求回复QueryHit消息的主机处,受到Push请求的主机需要主动建立到查询节点的连接并将所需数据“推送”给查询节点.
上述查询机制是有问题的.泛洪查询将查询信息以广播方式对直接邻居节点进行转发,当网络规模不大或是查询范围比较小时,这种泛洪的查询方式有高度的容错性和查准率.然而,随着网络规模的扩大,查询信息的转发将是海量的.假设目前有个比较规则的网络,网络中的每个节点平均有n个节点,查询信息每进行一次转发需要转发n条信息,随着查询范围的扩大(TTL值的增加),查询消息将以指数级增长,冗余信息量也会急剧增加[2].这些冗余信息会使得网络流量急剧增加,网络负担加重,甚至会造成网络拥塞.如何管理网络连接,使用高效的资源定位算法,减少转发的冗余查询信息的数量,提高资源搜索的效率,并提高Gnutella网络的扩展性,对Gnutella网络的发展极其重要.
2 基于资源推荐策略的路由算法与改进
2.1 现有的基于资源推荐策略的路由算法
现有的资源推荐策略在返回查询消息时缓存查询信息来为后续的查询作出指导[3-5].这些缓存的查询信息包括通过本节点成功到达具有请求资源的目标节点的次数:从本节点到达具有请求资源的节点的最少跳数[6-8].为了实现以上的2个功能,前人通过使用本地资源索引表(LIT)和本地路由索引表(RIT)来对节点的信息进行管理.
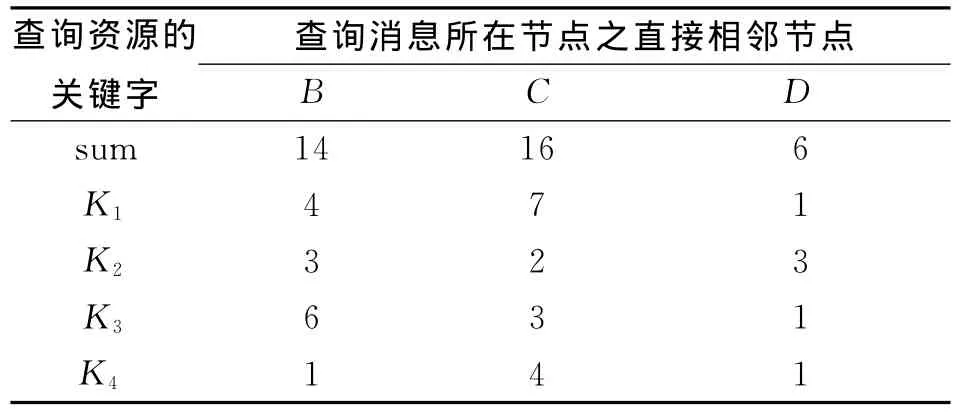
表2 节点A的本地路由索引表(RIT)
表2中,行所表示的是查询信息的关键字:列表示的是本节点A的邻居节点.Ki为节点A在过去一段时间内所查询的信息的关键字.其中(Ki,B)表示关键字为Ki的查询信息通过B节点转发查询成功的次数为mi.例如,(K1,B)为4表示关键字为K1的查询信息通过B节点转发查询成功的次数为4次.“通过B节点转发查询成功”包含有2层含义:一是在B节点自身的本地资源索引表里找到;二是B节点也是查询的中间节点,查询信息通过B节点后将按照同样的原理进行转发.这个方法虽然能够指导查询消息向更加有效的邻居节点进行转发,但当查询的TTL值低于到达具有请求资源的最近节点的TTL值时,查询消息将不会到达资源节点.
在传统的路由索引机制中,还存在一个查询准确率的问题.查询消息每经过一个节点都会参考一次该节点的RIT,通过比对决定优先向哪个直接的邻居节点转发查询消息.事实上,通过该节点转发查询成功的次数多并不一定代表最短的查询路径一定通过该节点.最糟糕的情况就是通过查询成功次数最多的节点转发所得到的查询结果都是路径最长、所需跳数最多的.

表3 路由缓存表
如表3所示,通过B节点查询成功的次数最多,为4次,但通过B节点查询成功的路径最少也要4跳才能找到具有请求资源的节点G,而通过D节点查询成功次数最少,但是通过D节点却能最快找到最短路径的具有请求资源的节点H.而且,每经过这样1次对邻居节点的参考选择,就可能有一些可靠的查询路径被轻视.查询信息进行路由选择的次数越多,有效的查询消息被忽略的可能就越大,选择查询所忽略的有效信息的百分比
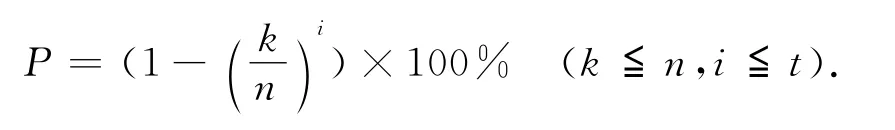
公式中,n为节点的平均度数,k为在某一节点参考RIT进行节点选择的次数,i为查询转发的次数,t为查询消息的生命周期值,每通过一次RIT查询,就需要在n个节点里选择一个节点,整个查询就像是在一个完全k叉树里进行搜索.在最糟糕的情况下,可能要广度优先遍历整个完全n叉树,那样会有很大的查询延迟.最多的查询次数

2.2 改进后的基于路由索引机制算法
为了论述改进的路由索引机制算法,先引述相似查询的概念:两个查询消息所查询的资源具有给定的相似度的查询就是相似查询[9].笔者在总结原有路由索引机制算法和自身分析研究的基础上,所做的改进工作主要包括两个方面.
1)在现有的基于缓存的节点推荐路由策略的基础上加以改进.在表2中的通过邻居节点成功查询到关键字的次数对相似查询确实具有一定的指导作用,但是,由于没有记录通过该邻居节点到达资源节点的最少跳数,这样,查询信息有可能不能够到达具有请求信息的资源节点.为了记录从该节点到达请求资源所在节点的最少跳数,本文引入了Hops项.当查询信息的TTL值小于Hops时,该算法自动将此TTL值修改为与Hops等同的值然后进行查询,保证了查询信息能够到达推荐的资源节点.
2)为了减少查询信息的数量,本文引入了查询路由表(RPT)来记录资源查询过程中返回的路由信息.当查询节点发出了Query消息后,如果被查询节点里有所请求的资源,该节点将会沿查询信息Query的路由原路返回一个QueryHit消息.这时,途经的这些节点将会记录下这些QueryHit中的返回资源的路径和其他信息.并对某类相似查询的路由进行排名,存储其中跳数较少的路由(本文推荐是前3条跳数最少的路由),以指导后续的相似或重复查询,加快重复查询的效率,减少冗余查询信息,从而减少网络流量,缓解网络负担.改进的路由见表4.

表4 资源推荐路由表
表4中,B,C,D为查询消息所在节点A的直接邻居节点,P1,P2,P3为通过邻居节点返回路由信息中跳数最少的3条路由.查询信息到达邻居节点就将按推荐的路径进行.以对邻居节点B路线上的查询为例,依次首先令Hops=2(即P1的跳数),逐个调整Hops值(对应的是P2,P3的跳数),依次按照推荐路由进行查询.若指定资源的RPT表为空或通过所有推荐路由查询均失败,则继续进行迭代洪泛查询,查询的结果填充RPT表.以便为后续的相似查询做出指导.本文选择对既定资源存储最短三条路由信息有两个目的,一是综合考虑了查询的查准率,如果保留的路由信息过少,那么沿推荐路由查询可能因P2P网络中的节点随时退出网络或是出现其他异常而失败:第2个原因是尽量减轻本地缓存的负担,过多的路由信息对查询的指导效率的提高意义不大,他们会使得节点缓存所占的存储空间增大,存储他们需要占用本节点的硬件资源.
本算法中的RPT将传统算法的RIT吸纳在其中,如果节点本身包含所查询的资源,则从该节点到达请求资源所在节点的最小跳数为0,到达请求资源所在节点的路由就是节点本身.
2.3 改进后算法描述
推荐路由查询全局步骤描述如下:
1)从源节点开始进行Ki记录的探寻,若有Ki信息推荐路由,则沿推荐路由查询,否则,进行迭代洪泛查询.
2)在迭代洪泛查询的过程中,若查询到请求资源,则查询结束:如果查不成功,但是有Ki记录返回,则停止迭代洪泛查询,从开始沿推荐路由查询.
3)若在进行第1次迭代查询后,既没有查询到请求资源也没有Ki的缓存路由信息返回,则进行下一次迭代查询,查询的处理转向(2).
推荐路由查询局部过程的伪代码说明如下:
Main()#主函数,输入和输出
{Routing_select();#资源路由信息的查询
Input Query(Ki,TTL)#client C
Output Queryhit(Ki.IP,Ki_Info);}#sever S
查询算法的输入是 Query(Ki,TTL),Ki为查询资源的关键字,TTL为查询信息所余生命周期值,输入节点是查询的源节点或是转发节点;算法的输出是 Queryhit(Ki_IP,Ki_Info),Ki_IP是查询信息的IP地址,Ki_Info是查询所得资源的特征信息,输出信息的节点是资源节点.
Routing_Select()
{if(Match_Ki()==True)
{if hop=0Queryhit();#请求资源位于本节点,返回 Queryhit
else if(TTL<hop)TTL=hop;
Routing_Pi():#路由的获取
else Routing_Pi():
}}
每当查询信息Query到达一个节点时,首先将自身与RPT表中的关键字Ki匹配,若存在Ki的记录项,则进一步查看到达资源节点的跳数.若到达Ki资源的hop=0,则说明资源存在于本节点;若Query消息不能到达资源节点,则将通往该资源节点的最短路径的hop值赋予查询信息的TTL,使Query能到达该资源节点.需要说明的是,查询信息将依次沿所有推荐路由查询,不同路由中,TTL将会被赋予相应的hop值
Routing_Pi() #从路由缓存记录里获得路由信息
{for(i=1,i<n,i++)Pi;#沿所有推荐路由发送查询消息
if(Pi=S_IP)QueryHit();#查询成功,返回 Queryhit()
else Delete Ki_RPT(); #沿推荐路由查询失败,清空Ki的路由缓存记录
Iterative_Flooding();} #继续进行迭代泛洪查询
使用Ki记录的路由Pi,若查询消息到达资源节点,结束;若通过缓存路由都没能到达资源节点,则删除Ki记录,并使用泛洪查询.
Upadte_RPT();#更新路由缓存信息
{if(Match_Ki()==False)Create_Ki();#创建 Ki的路由缓存
else Ki_RPT();}#填充 Ki的路由信息
当节点第1次参与查询或通过所有缓存推荐的路由查询失败时,RPT表中关于查询资源的记录均为空值,这时将会继续采用迭代洪泛的方法进行查询,并记录查询关键字为Ki.当节点收到Ki消息的Queryhit信息而节点缓存里又没有Ki的缓存路由时,则创建Ki的记录项;若有Ki的记录项而路由信息为空时则更新路由信息,用来指导后续相似查询.
3 算法性能分析
为了分析改进算法的性能,以下将在3个方面对改进算法和现有算法进行比较.
首先比较在最短路径时的命中率.由于传统的资源推荐策略只记录通过该节点查询某一资源成功的次数和所需的最小跳数.而现有的基于缓存的路由指导机制通过存记录的先前的成功查询指定资源的路径,所以在最短路径的命中率方面效率明显会更高.
接下来比较查询命中率,传统的资源推荐策略并不能保证在有推荐资源时请求节点的查询能够到达推荐策略的资源节点.在已有确定资源的情况下,增加TTL值后仅仅对该资源进行查询,在保证所查询资源节点可达的情况下还不会增加网络负载.
最后比较网络负载.在到达资源节点所需的路径比较短时,两种算法产生的网络流量相当.但是随着到达资源节点所需的路径加长,由于基于缓存的路由推荐策略会针对确定的路径进行查询,所以产生的网络流量会比现有算法低.
4 结束语
本文对分布式非结构化P2P网络以及传统Gnutella协议进行了概要性阐述.在对现有的资源推荐策略的路由算法进一步分析的基础上,提出了改进的基于缓存的路由搜索算法.该算法在能够保证较高的查询消息命中率的同时,通过路由缓存的策略来加速相似查询和重复查询,从而提高查询效率,减轻网络负载.通过性能分析,在原有的路由搜索算法的基础上,改进算法能够改善提高查询命中率和加速相似查询和热门资源查询,从而使得整体的查询效率有了改善.
[1]张春红,裘晓峰,弭 伟,等.P2P技术全面解析[M].北京:人民邮电出版社,2009:3-5.
[2]郭大江,陈闳中.Gnutella网络搜索算法的改进[J].计算机工程与应用,2005(36):123-124.
[3]Gkantsidisc, Mihailm,Saberia.Hybrid search schemes for unstructured peer-to-peer networks[C]∥Proc of IEEE International Conference on Network Protocols.2005.
[4]汤景新,李景涛,赵一鸣.Gnutella半结构化自适应拓扑方案[J].计算机工程2009.9(17):112-114.
[5]吴 绮.基于节点流行度的Gnutella路由查询策略[J].计算机与网络,2009(2):192-193.
[6]刘焱旺,杨小军.一种基于Chord的缓存路由算法[J].现代电子技术,2008(23):133-138.
[7]董西广,张治国,张文欣.Gnutella网络中基于消息跳数的分段搜索策略[J].河南工程学院学报,2011,6(2):34-38.
[8]叶 飞,刘玉梅,马伟华.基于DSR协议的缓存路由选择与分组抢修算法[J].应用科技,2008,4(4):61-64.
[9]熊忠阳,刘玉龙,张玉芳,等.基于Gnutella协议的P2P搜索改进算法[J].计算机应用研究,2008(1):108-110.
