基于协同过滤技术的在线学习资源个性化推荐系统研究*
2012-09-09王永固邱飞岳
□孙 歆 王永固 邱飞岳
基于协同过滤技术的在线学习资源个性化推荐系统研究*
□孙 歆 王永固 邱飞岳
在线学习资源建设已经成为了当今数字化学习研究的热点问题.本文以学习过程中学习者学习行为和在线学习资源的特点为基础,结合协同过滤算法,设计了基于协同过滤技术的在线学习资源个性化推荐系统模型.实践证明,该模型可以更好地为学习者创造数字化学习环境,提高学习者的自主学习效率.
协同过滤;个性化推荐;学习行为;自主学习
一、引言
E-learning作为一种基于计算机通信技术的学习方式,可以最大限度地利用网络教学资源,学习者在学习过程中不必受到时空环境的限制,随时随地根据自身需要进行自主学习.这种新型的学习形式目前已经广泛的应用于各种在线课堂教学和技能培训领域.虽然E-learning教学资源建设已经取得了阶段性成果,但是主要有以下几个问题:(1)资源数量爆炸性增长.如今在线学习资源数量繁多,资源的质量和水平参差不齐,学习者往往无法辨别资源的优劣,导致学习资源的利用水平并不理想.(2)资源种类多样化.在线学习资源除了传统的文本类型以外,还有声音、图像、视频等多种媒体类型,媒体类型的不一致也给资源的搜索和归类带来了不便. (3)资源非线性呈现.与传统教学中的书本不同,在线学习资源一般以超文本链接联系各个知识点,学习者以非线性的方式进行学习,知识点的"跳跃性"也容易让学习者在学习时产生迷茫感.以上问题使得目前很多的E-learning系统无法根据不同学习群体的不同学习特征来提供个性化的学习支持服务.随着人们对在线学习资源认识的不断深入,具有智能分析技术的在线学习资源系统将是未来资源建设发展的趋势之一.由于学习者群体的特殊性,每位学习者都有其潜在的学习兴趣,协同过滤技术可以帮助学习者快速地发现有价值的资源,自主选择学习内容,根据自身的兴趣度来完善知识体系.因此,本文将协同过滤技术手段和在线学习资源的特征相结合,从学习者自主学习的角度来构建满足学习者个性化需要的在线学习资源系统.
二、文献综述
个性化推荐是对用户的兴趣、爱好、行为进行分析和建模,根据分析得出的结果给用户提供"个性化"、"定制化"的服务,以解决目前互联网中信息过载这一问题.目前,个性化推荐技术可以分为内容过滤推荐、规则过滤推荐和协同过滤推荐.
1.内容过滤推荐技术
基于内容的推荐是较早提出的一种推荐技术,该算法的原理是利用概率或者机器学习技术将用户的已有兴趣表示为模型,然后与资源进行比较,通过两者之间的相似程度来为用户进行推荐.
2.规则过滤推荐技术
基于规则的推荐是将推荐规则事先进行保存,然后通过这些规则对用户进行推荐.规则过滤推荐系统中规则的质量和数量决定了推荐的效果,从本质上说规则就是"if-else"类型的语句,这些语句分别描述了不同情境下以何种方式进行推荐.
3.协同过滤推荐技术
协同过滤技术最早于1992年出现在Tapestry系统中,当时主要用于解决电子邮件系统的筛选问题.随着协同过滤技术的发展,协同过滤技术在商业领域取得了较大成功.国外最具代表性的协同过滤系统有Amazon和Facebook的广告系统,Amazon是根据用户购买和查看图书的记录来为其推荐可能感兴趣的书籍,Facebook则是依托其庞大的用户群,根据朋友间的兴趣来进行广告营销.与国外相比,国内的协同过滤系统研究起步较晚,目前国内比较成熟的协同过滤系统主要有当当网和豆瓣猜.当当网和A-mazon的功能类似,同样是用于图书商品的推荐,豆瓣猜是通过分析用户读书记录来预测用户可能喜爱的书籍.协同过滤技术为网站增加了收入来源,增强了用户体验度,受到了用户的好评.
以上三种个性化推荐技术的优缺点如表1所示.
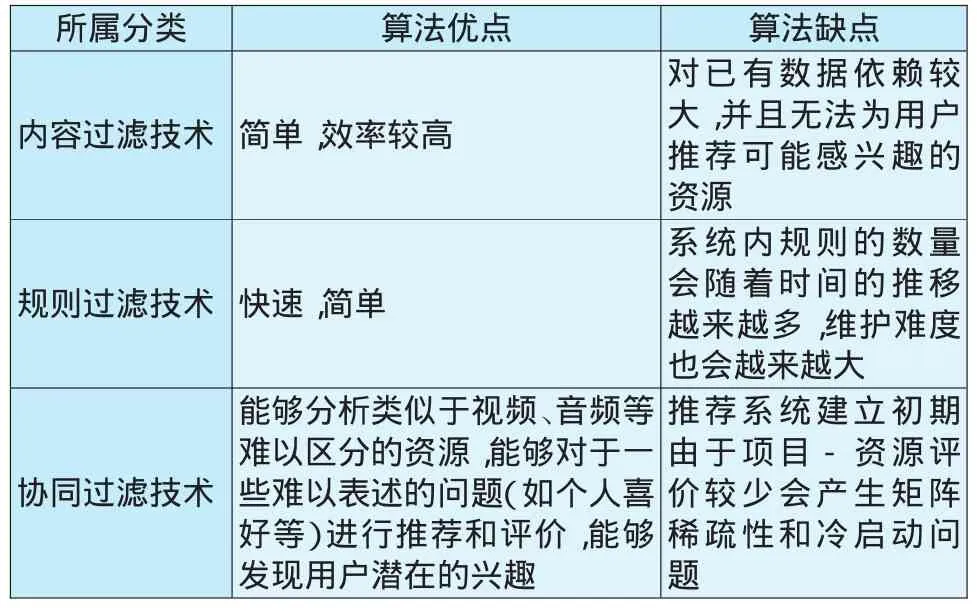
表1 个性化推荐技术分类及其优缺点
协同过滤技术从算法上分类可以分为基于用户的(User-based)协同过滤算法和基于项目的(Item-based)协同过滤算法.基于用户的协同过滤算法认为相似用户评价的项目之间存在相似性,可以以此来预测某个用户对该项目可能的评价;基于项目的协同过滤算法则采用计算项目之间相似度的方法来预测用户对其他项目的评价.
围绕协同过滤技术算法,国内外研究人员从个性化推荐的角度进行了一系列的研究工作.关于User-based算法,2009年Xia提出了一个改进的User-based协同过滤算法[1],在算法中引入用户加权值,来提高算法的准确度;2010年,Robert和Istvan将分布式技术与User-based协同过滤算法相结合,提出了一个完全的分布式推荐系统[2];Zhao和Shang提出了一个云平台的用户协同过滤算法,提高了协同过滤算法的可扩展性能[3];Mu和Chen在User-based协同过滤算法基础上引入了犹豫度概念(Hesitation Degree)来提高协同过滤算法的准确性[4].关于Item-based算法,2009年,Luo和Tian采用slope-one方案来应对协同过滤中的评级矩阵稀疏性问题[5];2011年,Lei和Junzhong将用户从众的心理和一般用户评价心理区分开来,采用均衡的基于项目的预测方法来对项目进行评价预测[6]; Gao和Wu以Userrank排名的数据模型为基础计算项目之间的差异性,提高算法的推荐质量[7].以上研究工作的重点是从协同过滤的算法效率和扩展性的角度来提高个性化推荐的精度,而对于学习者进行在线学习时产生的学习行为特殊性并没有给予太多的关注.鉴于以上问题,本文的研究重点是设计出一个基于协同过滤技术的在线学习资源模型,该模型能够利用协同过滤技术的突出优点,分析学习者的学习行为特征,为学习者推荐出可能感兴趣的学习资源,提高在线资源的利用率,促进学习者完成知识的加工和建构.
三、基于协同过滤技术的在线学习资源个性化推荐系统模型
通过对国内外研究成果进行分析,本文将学习者在线学习过程中的学习行为与在线学习资源特点作为设计基于协同过滤技术的数字化学习资源模型的依据,在强调学习者自主学习的基础上结合协同过滤技术算法,形成一套基于协同过滤技术的在线学习资源个性化推荐系统模型,如图1所示.该模型中最重要的部分有3个:学习者行为日志和学习资源库、数字化模型以及协同过滤引擎.
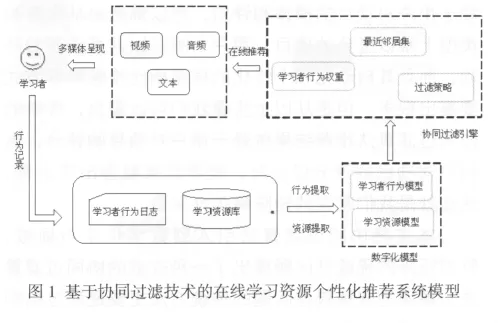
1.学习者行为日志
由于学习者在线学习的过程中不仅仅是对学习资源库中资源的简单提取,同时会产生收藏、下载、浏览和评价等学习行为.这些学习行为显性或隐性地表现了其学习兴趣,所以在该模型中,我们将学习者的学习行为收集并记录下来,挖掘学习者的学习行为轨迹,建立学习者的行为模型.
2.学习资源库
学习资源是个性化推荐系统的基础.作为学习者学习资料的来源,学习资源库提供了文本、音频和视频等资源供学习者学习.由于资源库中资源数量庞大,推荐系统对于每个资源都加入了社会化标签,标签的引入有助于对资源内容进行分类,实现资源的统一管理和高度共享.
3.协同过滤引擎
协同过滤引擎是个性化推荐系统的核心.该引擎将学习资源库中带有社会化标签的"孤立"资源关联起来,并且将学习者行为模型数字化为学习权重值,选择合适的推荐策略,产生候选推荐资源集,以多种媒体呈现的方式为学习者推荐其可能感兴趣的学习资源.协同过滤引擎能够有效地解决目前学习资源建设水平低,不利于学习者搜索等问题,保证了个性化推荐的质量.
四、基于协同过滤技术的在线学习资源个性化推荐算法
协同过滤算法基于以下假设:(1)用户之间的兴趣是具有相似性的.(2)由于用户对资源的操作评价包含了他们的兴趣偏好,所以我们以此来作为对其他用户预测项目的依据来源.传统的协同过滤算法主要分为三个步骤:获取用户-项目信息、计算查找相似用户集、产生推荐结果.协同过滤技术主要依赖于用户对项目的操作和评价,可以筛选出从内容和类型上难以区分的项目,用户之间可以共享资源和经验,而且其自动化和个性化的程度相比传统推荐方式要高出很多.但是从以上步骤我们可以看出,传统的协同过滤算法推荐结果依赖于用户对项目的评分,当用户对项目的评分过少时,推荐结果就会出现误差,这也就是我们常说的矩阵稀疏性问题.
本文将协同过滤算法引入到数字化学习领域,针对矩阵的稀疏性问题提出了一种改进的协同过滤算法.解决矩阵稀疏性问题的传统方法主要是通过给矩阵添加默认值,这种方法虽然能从一定程度上缓解矩阵的稀疏性问题,但是不能有效地对用户的兴趣倾向给出正确的分析.基于以上问题,本文给出的推荐算法的思路是在矩阵初始化时,如果用户对项目的评价较少,则挖掘用户对资源的其他行为(如:浏览、收藏、下载等),将用户的行为操作作为权重值加入到用户相似性计算中,该算法与传统的协同过滤算法相比,能够有效地解决矩阵的稀疏性问题,推荐精度也有了大幅提高.
基于协同过滤技术的在线学习资源个性化推荐算法流程如图2所示,在推荐过程中当学习者-资源矩阵过于稀疏时,该算法会对用户行为进行挖掘,填补矩阵稀疏的缺陷,以此提高推荐的精度.
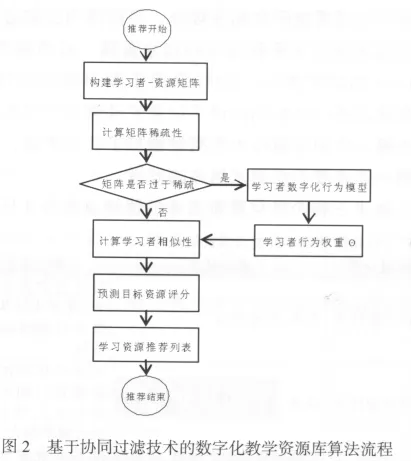
1.获取学习者-教学资源矩阵信息
首先将M个学习者对N个教学资源的评价转化为分值(主要是学习者对学习资源的显式评分),然后形成如表1所示的MN矩阵.其中第i行j列的Ei,j代表了第i个学习者对第j个教学资源的评分.
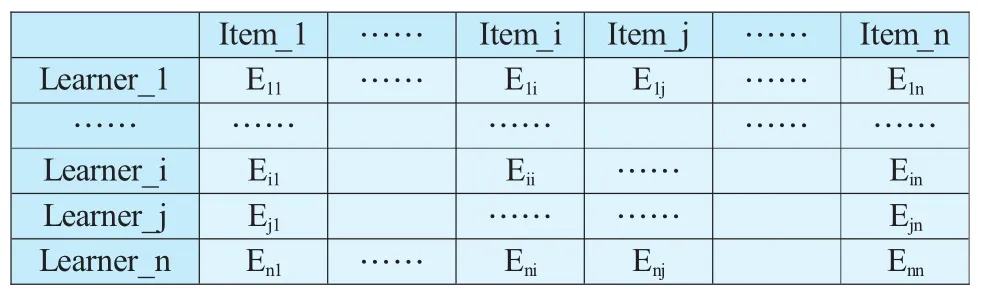
表2 学习者-学习资源评价矩阵
2.计算学习者-学习资源矩阵稀疏性
首先我们给矩阵稀疏性设定一个最小限定值Φ,然后计算矩阵的实际稀疏情况.
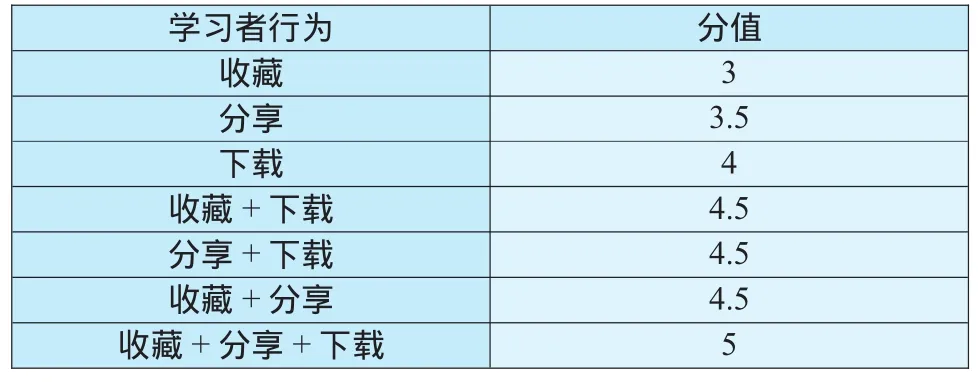
表3 学习者隐式行为分值
3.计算查找相似用户集
在协同过滤算法中,计算查找相似的邻居集是最为关键的一步,首先从表3取出中m个学习者对n个教学资源的评分,然后通过相似度计算方法计算出学习者之间的相似度.其中相似度计算方法主要有两种:余弦相似性算法和修正的余弦相似性算法.
(1)余弦相似性算法是最为典型的相似性计算方法,过程是将用户对项目的评分看做是n维的向量,然后通过计算其余弦的夹角来得出用户之间的相似度,其具体算法如公式(1)所示.
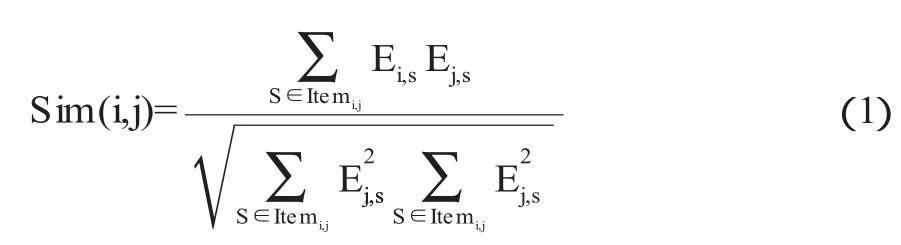
(2)修正的余弦相似性算法将余弦相似性算法做出了修改,为了减少用户主观性引入用户对项目平均评分的概念.在计算时将项目的评分减去该用户对所有项目的平均评分.其具体算法如公式(2)所示.
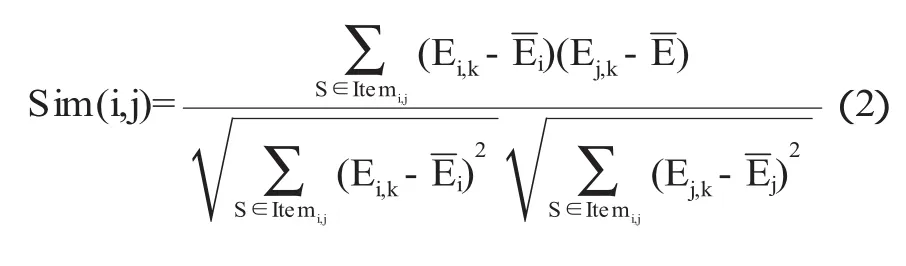
本文将步骤2中的用户行为权重值Θ加入到相似性算法中,形成了一种改进的相似性计算方法,为加入权重值的学习者-资源评价数值,改进的相似性算法如公式(3)所示.
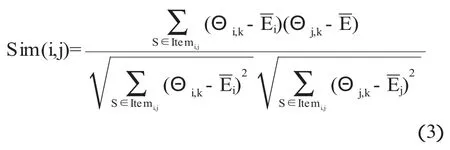
相似度计算完成后将会得到与用户相似度最为接近n个用户的邻居集Z={User_1,User_2,User_3,…User_n;}
4.产生推荐结果
一般根据上步得出的邻居集中用户对项目Itemn,s的评分,就可以预测出目标用户对该项目的评价,并且产生最终的推荐结果.因为学习者学习和评价的风格有所不同,所以本文采用如下推荐方式.
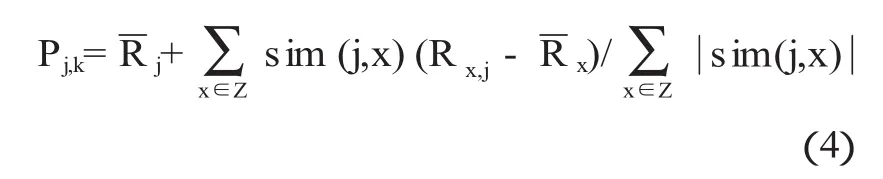
在公式(4)中Pj,k为推荐系统预测的学习者j对资源k的评分,为学习者j所有已经评分分值的平均值,Z为上一步得出的最近邻居集,最后取出相似度最高的N个资源,得出推荐结果,推送给学习者.
五、基于协同过滤技术的在线学习资源个性化推荐系统应用
本文在上述研究成果的基础上,结合在线学习资源和协同过滤技术的特点,设计开发了基于协同过滤技术的在线学习资源个性化推荐系统(如图3所示),并作为推荐模块应用于网络培训教学中.与传统的在线培训系统相比,在线学习资源个性化推荐系统能有效收集网络教学中学习者的反馈信息,为其他学习者提供需求相似的资源列表,与学习者进行交互,节省在线学习者获取信息和知识的成本.接下来,我们以该推荐系统中实际的用户数据为例,阐述系统是如何为用户推荐个性化资源的.
图3 基于协同过滤技术的在线学习资源个性化推荐系统
首先,个性化推荐系统中的行为收集模块从用户日志文件中收集用户行为,建立用户行为模型(如表4所示),并将其数据化.
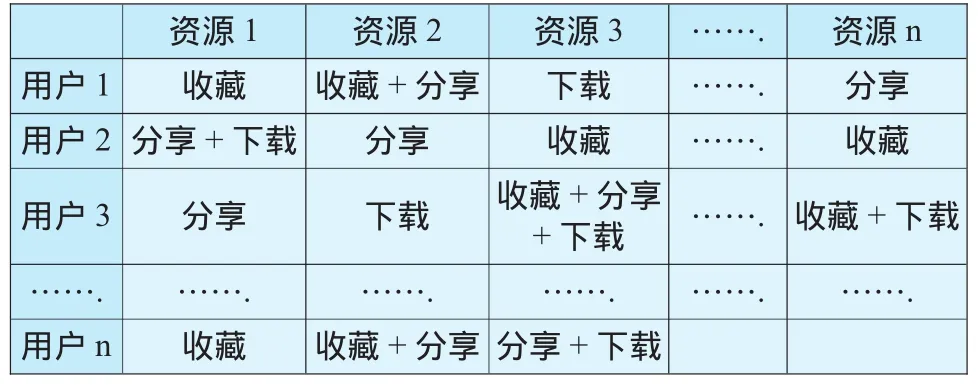
表4 用户行为矩阵模型
然后,推荐系统中的用户显示评价模块收集用户主观评价数据(分值代表用户对资源的喜好程度,分值越大代表用户对该资源的兴趣度越高,如表5所示).
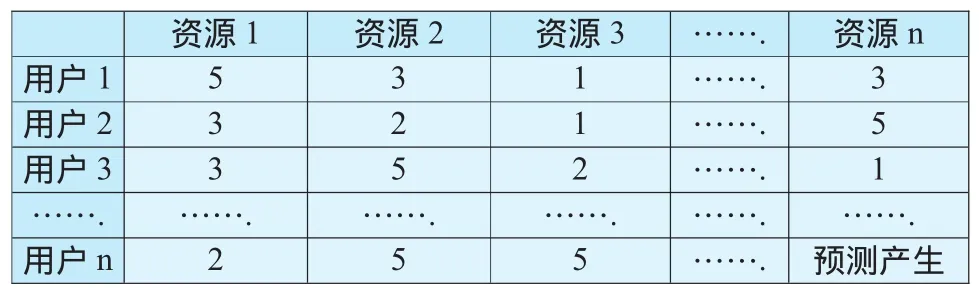
表5 用户主观评价模型
最后,以用户的行为数据和评价数据为依据,计算资源相似度,产生用户最近邻居集,预测出用户n在使用资源n时可能感兴趣的资源列表(如表6所示).该资源列表由推荐系统自动分析生成,以此来提高学习者的学习效率.
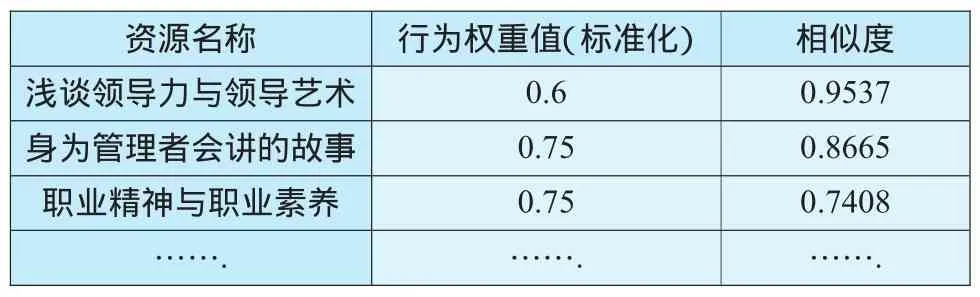
表6 目标用户n使用资源n时最近相似资源列表
六、结论与展望
本文首先分析了传统协同过滤技术普遍存在的问题,进而提出了一种改进的协同过滤算法,该算法引入了用户行为权重值概念,缓解了协同过滤算法普遍存在的冷启动问题.其次将协同过滤技术与在线学习资源相结合,设计了在线学习资源个性化推荐系统,实现了学习者自主学习,自主评价,资源共享等功能,提升学习者的学习效果.虽然在线学习资源内容不会发生变化,但是随着用户学习的不断深入,学习兴趣和方向可能不断变化,如何根据用户兴趣的变化进行实时地推荐,需要进行深入的研究.
[1]Xia Jianxun.An Improved Similarity Algorithm Based on Hesitation Degree for User-Based Collaborative Filtering[A].Conference on CommunicationFaculty[C].Nanning,PEOPLESRCHINA: Proceedingsof2009ConferenceOnCommunicationFaculty, 2009,104-108.
[2]Ormandi,Robert;Hegedus,Istvan.OverlayManagementforFully Distributed User-Based Collaborative Filtering[A].16th International Euro-Par Conference on Parallel Processing[C].Ischia,ITALY: EURO-PAR 2010 PARALLEL PROCESSING PT I,2010,446-457.
[3]Zhao Zhi-Dan;Shang Ming-Sheng.User-based Collaborative-FilteringRecommendationAlgorithmsonHadoop[A].3rd International Conference on Knowledge Discovery and Data Mining [C].Phuket,THAILAND:ThirdInternationalConferenceOn Knowledge Discovery And Data Mining Proceedings,2010,478-481.
[4]Mu,XW;Chen,Y.An Improved Similarity Algorithm Based on Hesitation Degree for User-Based Collaborative Filtering[A].5th InternationalSymposiumonIntelligenceComputationand Applications[C].Wuhan,PEOPLES RCHINA:AdvancesIn Computation And Intelligence,2010,261-271.
[5]Luo,Q;Tian,X.A Personalized Recommendation Algorithm Combining Slope One Scheme and User Based Collaborative Filtering[A] International Conference on Industrial and Information Systems[C] Hankou,China:2009 International Conference On Industrial And Information System,Proceeding,2009,152-154.
[6]Lei Ren;Junzhong Gu.An Item-based Collaborative Filtering ApproachbasedonBalancedRatingPrediction[A]2011 International Conference on Multimedia Technology[C].Hangzhou, China:2011 International Conference on Multimedia Technology, 2011.
[7]Gao,M;Wu,ZF.Userrank for item-based collaborative filtering recommendation[J].Information Processing Letters,2011,(9):440-446.
王永固,副教授,博士,浙江工业大学教科学院副院长(310014).
邱飞岳,教授,博士,浙江工业大学教科学院院长,现代教育技术研究所所长(310014).
责任编辑 平果
G40-057
A
1009-458x(2012)08-0078-05
本文接受浙江省重大科技专项"浙江中小企业信息化服务平台关键技术研究及应用" (2009C11026)、国家社会科学基金"网络环境下个体行为与群体行为研究"(10BGL095)、教育部人文社会科学研究项目"虚拟社区中基于社会网络的知识共享机理及实证研究"(09YJC630207)的支持.
2012-04-15
孙歆,硕士生,浙江工业大学教科学院(310014).
