基于十字链表的Apriori算法的实现
2012-09-01宋广佳张艳明
宋广佳,张艳明
(黑龙江中医药大学 现代教育技术与信息中心,黑龙江 哈尔滨 150040)
基于十字链表的Apriori算法的实现
宋广佳,张艳明
(黑龙江中医药大学 现代教育技术与信息中心,黑龙江 哈尔滨 150040)
针对A p r i o r i算法的若干不足,如需要多次连接数据库,多次扫描事务记录,在剪枝步骤比对次数过多等缺点,文章实现了把数据库映射到十字链表的方法,并且与传统A p r i o r i算法进行了对比,实验表明十字链表的方法可以大幅度减少数据挖掘所需时间,可明显减少连接及扫描数据库次数,减少剪枝步骤对比次数,提升算法执行效率.
关联规则;Apriori;十字链表;数据挖掘
1 介绍
数据挖掘也称为知识发现,是当今数据库研究中的技术热点.发现关联规则是数据挖掘的主要目的,关联规则是指在大型事务或关系数据集中各个项之间的有趣关联或相关.例如可以通过“购物篮”中不同的商品去分析顾客的购物习惯.目前关联规则广发的应用于医疗保健、电子商务、金融证券及生物基因分析等领域.A p r i o r i算法是RA g r a w a l和R S r i k a n t于1994年提出的关联规则挖掘的原创性算法[1,2].算法的基本思想如下:频繁项集的任何子集也一定是频繁的.其中频繁项集是指满足最小支持度的项目集合,比如{A B}是频繁的,则{A}和{B}也一定是频繁的.基于以上原理,A p r i o r i算法使用逐层搜索的迭代方法,用K项集去搜索K+1项集[8].
1.2 A p r i o r i算法步骤如下
(1)首先扫描原始数据库D B,生成频繁一项集L 1
(2)连接步:L k-1通过自身连接产生候选k项集C k
(3)剪枝步:根据A p r i o r i性质,扫描数据库D B,对每个候选项集进行计数,将支持度小于给定阈值的候选项去掉,从而确定L k.
以上(2),(3)步骤循环,直到新产生的L k为空为止[3].
1.3 A p r i o r i算法的不足
通过对算法的分析可以发现算法存在很多不足:
(1)算法需要扫描数据库多次
(2)生成的候选集巨大,而其中很对候选项对于生成频繁集无用,同时时间耗费巨大.
针对(1)可将原始数据库转化为某种内存中的某种数据结构,这样再算法运行时只需扫描数据库一次.常见的转换方式有将原始数据库转换为十字链表[4],转换为图,转换为向量,转换为矩阵等等[5,6,7,9].针对(2)可采用候选树分割的方法将时间上的耗费部分转移到空间上去,即采用空间换时间的方法.
2 十字链表方法
2.1 将事务数据库转换为十字链表
事务T={t i|1<=i<=n},n为事务的长度,且事务中各项按字典有序.如有如下事务数据库D B,则采用图1所示的节点结构可将其转化为如下形式

表1
十字链表节点数据结构

表2
其中:I t e m表示项目名称,N u m b e r表示该项目到事务末尾的长度,D o w n是指向下一个事务中此项的指针,R i g h t是指向同一事务中下一项的指针.事务数据库D B的十字链表表示如下:
2.2 十字链表的特性
性质1:如果事务T中的项与C j[1]匹配成功,且此项的N u m b e r值小于k,则该事务T对产生频繁项集无用.
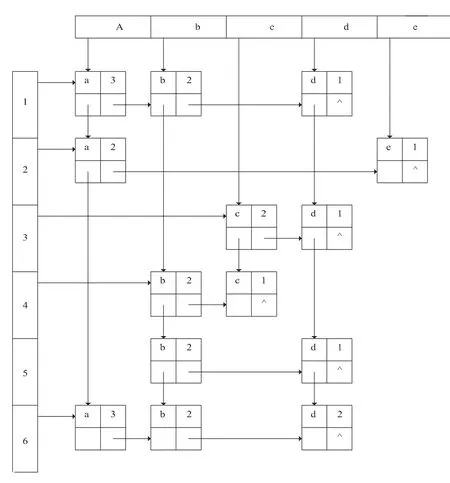
图1
性质2:候选k-项集中的任意项集C i与十字链表中的事务匹配时,假设C i[j]与十字链表中某事务T中的项t匹配成功,C i[j+1]与t的下一项匹配时,如果此项按字典顺序在C i[j+1]之后则停止匹配,此事务对C i的支持度计数没有影响[4].
如果给定支持度为M i n S u p,算法描述如下:(1)扫描十字链表生成频繁一项集L 1. (2)如果L k-1非空,连接L k-1生成C k.
(3)在候选集C k中,沿十字链表的I t e m表头搜索,将c i[1]与I t e m表头中节点进行匹配,直到匹配成功为止.
(4)在I t e m表头中,沿匹配成功节点的d o w n向下域搜索.根据性质1,判断指向的节点的N u m b e r域,如果n u m b e r
(5)在匹配过程中如果项集c i已经与事务t的前j项匹配成功,在进行j+1项匹配时如果按字典顺序c i[j+1]在事务t进行匹配的项之后,则根据性质3,停止匹配,否则如果一直匹配成功则c i的支持度计数加1.
(6)如果c i的支持度不小于M i n S u p则将其添加到L k中.
(7)去下一个c i,继续重复(3)~(6)直到C k中所有的k项集全部扫描结束为止.
(8)输出频繁项集L k,转至(2).
3 十字链表的VB实现
3.1 数据结构设计
转换之后的十字链表有三种结构的节点,一种为左侧垂直的T i d事务标识头表,一种为上部水平的I t e m项目头表,最后一种为剩余的普通节点.定义这三种节点的数据结构如下:

以事务数据库T以文件方式存储为例,为将事务数据库T转换为十字链表,编写了如下四个过程:
生成I t e m项目表头:C r e a t e I t e m H e a d(D B N a m e)
生成T i d事务标识表头:C r e a t e T i d H e a d(D BN a m e)生成十字链表普通节点:C r e a t e N o d e(D B N a m e)完成所有节点的d o w n指针及r i g h t指针:F u l l N o d e()
调用以上四个过程可以生成完整的十字链表,然后扫描十字链表生成频繁一项集L 1,代码如下:
M i n S u p=2'最小支持度

通过L k-1的自身连接可以生成C k,对C k中的项进行支持度计数是A p r i o r i算法中耗费时间较多的步骤,因为理论上检查每个c i的支持度计数都要扫描整个事务数据库,但在十字链表中根据性质1和性质2,对候选集C k进行A p r i o r i性质检查的步骤可以快速的进行,实现的代码如下:

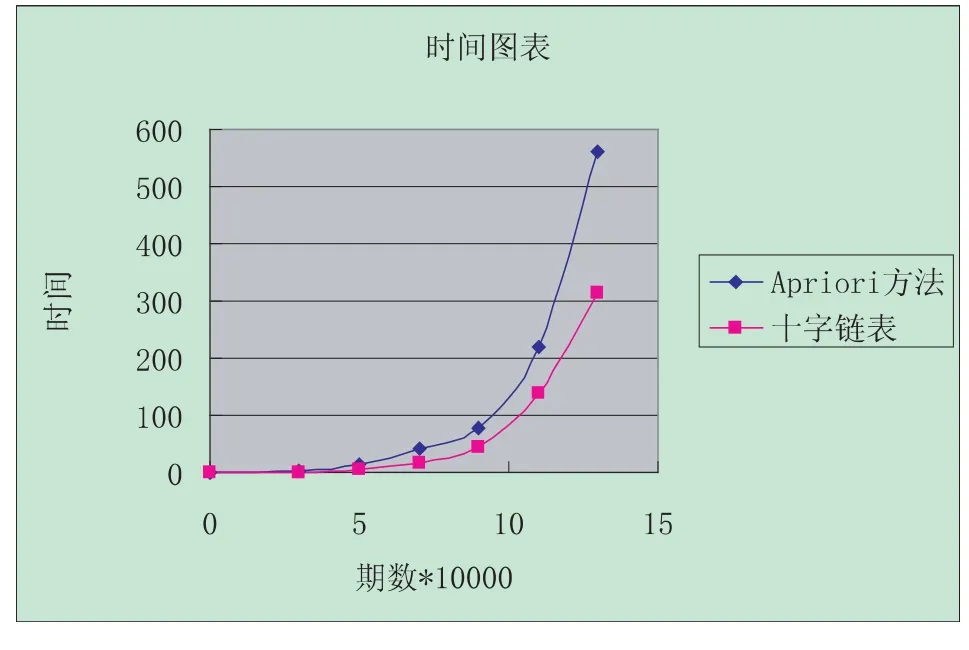
图2
E n dS u b
与传统A p r i o r i算法进行对比实验,实验环境为:C P U为I n t e l Q 8300,内存d d r 28002 G B,操作系统为w i n d o w sX PS P 3,数据库采用T 40 I 10 D 100 K,支持度15%.算法执行时间对比如下:
结果分析:从曲线上来看,十字链表方法的执行时间明显少于传统A p r i o r i算法,抛物线上升趋势上也比传统A p r i o r i算法平缓的多,从时间对比上来看,执行之间要比S Q L方法提升了至少25%.
本文用V B语言以十字链表数据结构为基础实现了A p r i o r i算法,通过实验分析表明:通过转换数据结构可以减少连接数据库次数及I/O操作,利用十字链表的特性额可以有效地减少扫描数据库次数,从而使数据关联规则挖掘的时间大幅减少.
〔1〕Agrawal R,Imielinski T,Swami A.Mining Association Rules Between Sets of Items in Large Database[C].Proceedings of the ACM SIGMOD Conference on Managementof Data.Wasington,USA.1993
〔2〕Agrawal R,Srikant R Fast Algotihms for mining Association Rules[C].In Proc 1994 Int Conf Very Large Data Base Santiago,Chile.1994.
〔3〕于卫红.用VB对基于Apriori算法的数据挖掘的实现[J].计算机工程,2004,30(2):196-197.
〔4〕黄建明,赵文静,王星星.基于十字链表的Apriori改进算法 [J].计算机工程,2009,30(2):37-38,41.
〔5〕白似雪,朱涛,梅君.基于图的Apriori改进算法[J].南昌大学学报,2009,30(1):36-39.
〔6〕方炜炜,杨炳儒,宋威,侯伟.基于布尔矩阵的关联规则算法研究 [J].计算机应用研究,2008,25 (7):1964-1966.
〔7〕刘江华,戴新喜,白似雪.基于模式矩阵的P_Ma
trix算法[J].南昌大学学报,2007,31(5):496-499.
〔8〕JiaWeiHan,Michline Kamber.数据挖掘概念与技术[M].北京:机械工业出版社,2008.
〔9〕李超,余昭平.基于矩阵的Apriori算法改进[J].计算机工程,2006,32(23):68-69.
〔10〕YanbinYe,Chia-ChuChiang.A Parallel Apriori Algorithm for Frequent Itemsets Mining [C].Proceedings of the Fourth InternationalConference on software Engineering Research, Management and Applications, SERA 2006,p 87-94.
T P 311.13
A
1673-260 X(2012)09-0032-03
