基于R语言的数据挖掘在水环境管理中的应用
2012-08-09彭昌水
肖 凯,魏 菲,彭昌水
(1.长江水利委员会a.网络与信息中心水利发展研究所;b.机关服务中心计划财务处,武汉 430010;2.长江科学院信息中心,武汉 430010)
基于R语言的数据挖掘在水环境管理中的应用
肖 凯1a,魏 菲1b,彭昌水2
(1.长江水利委员会a.网络与信息中心水利发展研究所;b.机关服务中心计划财务处,武汉 430010;2.长江科学院信息中心,武汉 430010)
运用数据挖掘中的分类回归树方法,对河流中的有害藻类生成进行了建模,分析得出河流中藻类生成的重要影响因子是磷酸盐含量、氯化物含量和最大pH值。另一方面,运用R语言实现并验证了CART算法的优越性和易用性。其结论和方法有助于水环境管理部门更有效地对水质进行监测和预测。
数据挖掘;分类回归树;R语言;水质监测
1 问题的提出
水是生命之源,也是人类社会发展赖以生存的基本物质。随着经济的发展,天然水源遭到了不同程度的污染,河流水质变差,从而影响到人类健康和流域生态环境。在诸多水环境问题中,比较严重的是有害藻类在河流中大量繁殖形成的水华爆发,这不仅对河流生命形式也对水质造成极大的负面影响。因此,对河流中藻类生成的监测和预测是改善河流水质的重要方面。
对水质样本进行生物学分析需要训练有素的人员,成本较高并且相当耗时。相比较而言,对其进行化学分析则成本较低且容易实现自动化。因此,建立水质化学性质和藻类发生频率之间关系的数学模型能有效地降低监测成本和时间。此外,通过建立数学模型也有助于更好地理解藻类发生频率的影响因素。
利用数学模型对藻类发生进行预测的研究并不少见,早在1968年加拿大湖泊专家Vollenweider[1]就提出了利用多个营养指标进行水体营养程度的预测。近年来国内学者也采用了多元线性回归[2]、神经网络[3]和系统动力学[4]的方法对藻类生成进行了预测研究。
从现有文献来看,对藻类生成进行预测的方法主要有2大类[5]:一类是基于生态机理和系统动力学的建模,系统动力学模型通过对生态系统进行结构分析,研究生态系统内子系统间相互作用,综合考虑系统内外的影响变量,建立微分方程组,研究生态系统状态变量变化;另一类是基于机器学习的建模,机器学习又称为人工智能方法,它将不完全、不可靠和不确定的信息逐步转变为完全、可靠和确定的信息。机器学习能很好模拟非线性过程,这就为水华机理分析提供了一种有效途径。
基于生态机理建模预测水华在某些特定河湖取得了较大成效,但是水华的发生仍是一个机理不太清楚的非线性问题,需要面对各种不确定性,研究者们还需进行深入的探索。多元统计回归模型一般采用线性关系对模型进行简化,因此在预测藻类生成时效果不佳;而神经网络方法由于具有较强的适应能力、学习能力和真正的多输入、输出系统的特点得到人们的重视。但是神经网络模型对于如何确定输入变量和网络结构没有很好的方法,并且很难解释神经网络结构的功能以及它们对输出变量的影响。
目前,决策树方法开始受到国内外学者的关注,Chen应用决策树和分段非线性统计回归方法预测了荷兰海岸带水华的叶绿素浓度变化趋势。曾勇等[6]采用决策树和非线性回归相结合的方法对北京六海地区的水华进行了分类预警。决策树方法具有良好的预测精度,并且模型的输入输出关系明显,结果易于解释。目前,在水环境方面采取决策树进行预测的文献还并不多见。因此,本文利用开源统计软件来系统地总结整理决策树算法的应用和实现很有意义。
2 研究方法
2.1 分类回归树模型
本文采用的建模方法是数据挖掘中的分类回归树方法[7]即CART(Classification and Regression Tree)模型,数据挖掘是从数据中提取出隐含的过去未知的有价值的潜在信息。数据挖掘包括的算法很多,而分类回归树是其中一种用于数据集分类决策树技术,也可称为二元回归分解技术。利用分类回归树可以自动探测出高度复杂数据的潜在结构、重要模式和关系;探测出的知识又可用来构造精确和可靠的预测模型。建立树模型可分为分类树(Classification Tree)和回归树(Regression Tree)2种。分类树用于因变量为分类数据的情况,树的末端为因变量的分类值;回归树则可以用于因变量为连续变量的情况。
分类回归树模型的思想与一般线性回归不同,它并不需要建立一个回归方程,而是用一系列的二元决策规则来反复分割数据。
该模型的优点在于:①可以生成容易理解的规则。②计算量相对来说不是很大。③可以处理多种数据类型,对异常值和缺失值不敏感。④决策树可以清晰地显示哪些解释变量较重要。
建立决策树模型大致分为3个步骤:
第1步是利用样本数据生成决策树结构。从自变量中选择最能有效分割数据的变量和阈值,使分割后的子集内部变异性最小。对数据子集重复划分直到满足终止条件。对于连续数据通常是采用均方误(MSE)作为变异性的判断指标,对于离散数据则采用基尼值(Gini);
第2步是对决策树进行修剪或称为剪枝。之所以要修剪是因为若不加任何限制,模型会产生“过度拟合”的问题,这样的模型在实际应用中毫无意义,而从另一个极端情况来看,若决策树的枝节太少,那么必然也会带来很大的预测误差。综合看来,要兼顾树的规模和误差的大小,因此通常采用一个称为“成本复杂性”(cost/complexity)的标准来对树进行限制,使预测误差和数的规模都尽可能小,通常会使用CP(complexity parameter)参数来加以限定。
第3步是输出最终结果规则,进行预测和解释。
2.2 建模工具
本文采用的实现工具是R语言[8],R语言是一种开源、免费的优秀统计软件。它起源于AT&T贝尔实验室的S语言,相比其他统计学或数学专用的编程语言有着更强的面向对象功能。该软件在国外被广泛使用,包括Google和Facebook公司均使用它进行数据分析的各项工作。
在R语言中有许多扩展包(Packages)可以增强其功能。rpart包[9]的功能就是实现递归分割和树模型构建。其中主要的2个函数分别是用来生成树模型的rpart函数和进行剪枝的prune函数。表1简单罗列了rpart包中用到的主要函数。
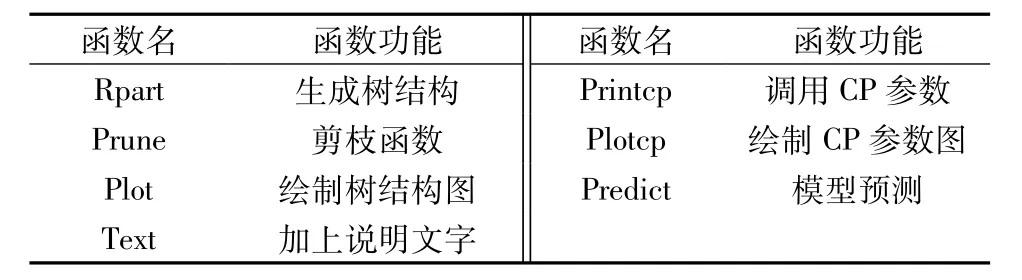
表1 rpart包主要函数名称与功能Table1 M ajor functions of rpart package
2.3 数据来源
本文的样本数据包括了200个水质样本。样本数据是在不同季节和不同河段采集8种水质指标和3种有关变量,上述11个变量将作为模型的解释变量。藻类生成率作为模型的被解释变量。样本数据的各变量名与含义如表2所示。
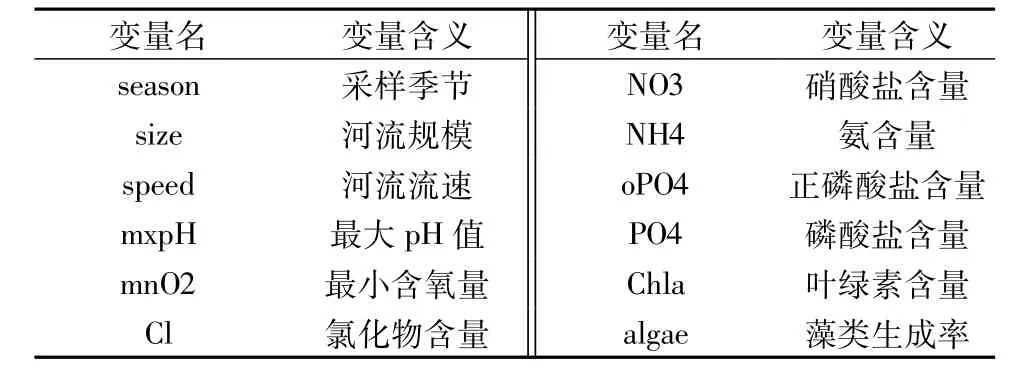
表2 样本数据的变量名与含义Table2 Names and meanings of variables
表3是对样本数据中分类变量的描述性统计,样本中包括了各个季节和各类河流样本,有着较好的代表性。

表3 分类变量的描述统计表Table3 Description of categorical variables
3 实证分析
3.1 分析步骤
第1步,载入所需软件包和数据:
Library(rpart)
Data(algae)
第2步,整理数据,将缺失严重的2个数据删除:
algae=algae[-c(62,199),]
第3步,建立回归树模型,结果存于变量fit:
fit=rpart(a1~.,method=‘nova’,data=algae[,1:12])
第4步,绘制回归树的结构图:draw.tree(fit)
第5步,对树模型进行剪枝:
调用CP(complexity parameter)与xerror的相关图,寻找最小xerror点所对应的CP值,并由此CP值决定树的大小
Plotcp(fit)
根据上面得到的CP值,用prune命令对树模型进行修剪。
3.2 分析结果和讨论
由于篇幅所限,仅列软件计算得到的模型结果部分显示如下:
1)root 198 90 401.29 16.99
2)PO4>=43.81 147 31 279.12 8.97
4)Cl>=7.81 140 21 622.83 7.49
8)oPO4>=51.18 84 3 441.14 3.84*
9)oPO4<51.11 56 15 389.43 12.96
5)Cl<7.806 5 7 3 157.76 38.71*
3)PO4<43.82 51 22 442.76 40.10
6)mxpH<7.87 28 11 452.77 33.45
12)mxpH>=7.045 18 5 146.16 26.39*
13)mxpH<7.045 10 3 797.64 46.15*
7)mxpH>=7.87 23 8 241.11 48.20
模型输出结果的第1行表示根节点,其它末尾加星号的表示叶节点。每1行均表示了1次数据划分或者说决策树的分叉。输出结果的第1列为结点序号,第2列为数据划分依据,第3列为分组后的样本数,第4列为组内误差,第5列为组内因变量均值。以输出结果的第2行为例,“PO4≥43.81”即表示以磷酸盐含量43.81作为划分数据的阈值,将整个数据进行了第1次分割,磷酸盐含量>43.81的为1组,构成2号结点,小于43.81的为另1组,构成3号结点。数值147即表示归入2号结点的样本数有147个,第3个数字表示这1组的残差平方和为31 279.12,最后1个数据8.97表示本组样本中藻类生成的平均值。
从第1次划分数据的结果可以看出,3号结点藻类生成均值为40.10,明显大于2号结点数字,因此初步判断磷酸盐含量较大的河流,其藻类生成率较低。由于决策树的建立过程是一个不断选择最佳预测变量的过程,因此在划分数据方面,高层结点上的分类规则比低层结点上的分类规则更有价值,所以可以根据分类规则在分类树的位置确定预测变量对目标变量影响的重要性。可以看出针对藻类生成这一因变量,在自变量中最为重要的因素是磷酸盐含量,其次是最大pH值与氯化物含量。
根据图1所示的树模型结构图中还可更为直观地观察到,整个模型有10个叶节点,深度为6层,根节点以及内部节点处都标明了此节点所对应的依赖变量和阈值。
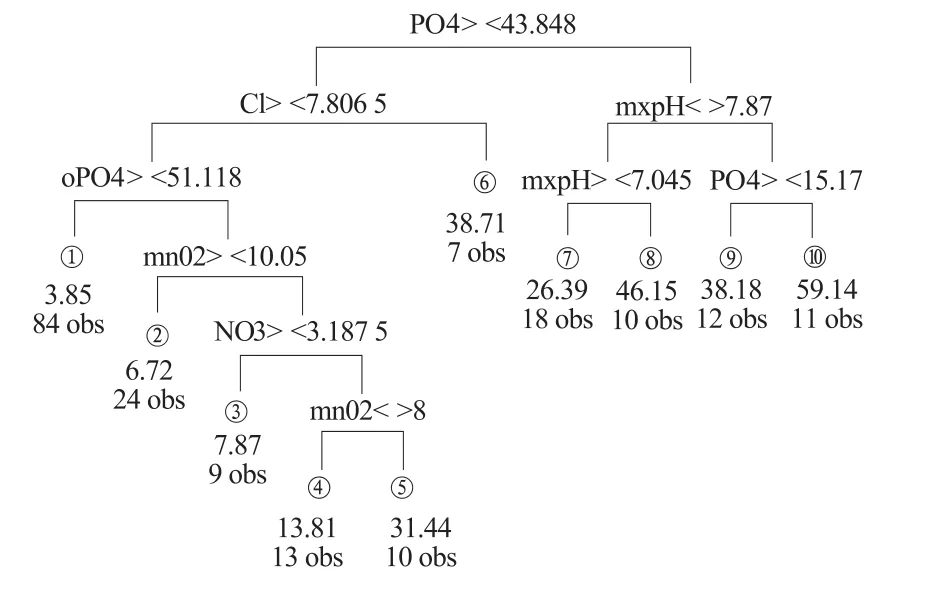
图1 分类回归树模型的结构图Fig.1 Tree structure of CART model
由决策树结构图还可以得到对藻类发生的解释规则,若水环境管理部门监测到河流中磷酸盐含量在15.17以下,并且最大pH值超过7.87,那么预计藻类生成率将最高,其期望值为59.14,即图1中10号叶节点的情况。此时说明河段中出现了水华问题,水环境生态系统不正常,水环境管理部门应提高警惕,及时确认和处理水华问题。若检测到磷酸盐含量>51.118,且氯化物含量超过7.806 5,则预期藻类生成率为3.85,此时的水环境系统处于较为正常状态。
由上述模型可以得到以下结论,河流中的磷酸盐含量、氯化物含量和最大pH值是影响藻类生成的重要因素。要抑制河流中水华形成,可以采取的措施就是提高磷酸盐含量,并同时加大氯化物含量。这就是树图中左侧节点所处的情况。而河流的规模、流速以及季节变量均未出现在模型中,可见这3个解释变量对藻类生成没有很大影响。
4 结 语
从模型运行结果分析可以得出,CART模型对河流中藻类生成预测具有一定的参考意义。但是作为数据挖掘算法的一种,只有样本足够多时,结果准确率才会更高,而本文中的样本数偏少,在实际的水质监测工作中,采样范围应该远远不只200个。另外,样本中所涉及的水质化学指标也可以更丰富一些。这些都是影响模型结果准确率的主要因素。
从研究方法上来看,CART模型有很多自身的优点,一个比较显而易见的优势就是它特别直观明了,决策者根据树形图的分枝走向很容易预测因变量的取值,在这方面它与神经网络相比,其逻辑和操作都更易理解;另一方面,因为数据划分的依据是观测值的顺序而非具体大小,因而对异常值并不敏感,而且对缺失值的处理机制能提高数据的利用充分程度。但其缺点在于对连续数据的分析精度不够,因此建议因变量多采用分类变量,将藻类生成按标准分为多个警戒级别,再进行建模预测。
当然分类回归树模型也并非完美,目前该方法也得到了进一步的发展。例如以随机森林(random forest)的方法来扩展CART模型,随机森林是一个包含多个决策树的分类器,其输出值是由个别树输出值的众数而定。在R语言中,randomForest扩展包可以实现分类回归树的随机森林算法。
[1] VOLLENWEIDER R A.The Scientific Basis of Lake Eutrophication,with Particular Reference to Phosphorus and Nitrogen as Eutrophication Factors[R].Paris:Organisation for Economic Co-operation and Development,Technical Report DAS/DSI/68.127.OECD,1968:159.
[2] 李 星,何宇飞,杨艳玲,等.采用预测模型预测水库水的藻类生长潜力[J].哈尔滨商业大学学报(自然科学版),2008,24(1):36-39.(LIXing,HE Yu-fei,YANG Yan-ling,et al.Application of Forecasting Model for Algae Growth Potential Forecast of Reservoir Water[J].Journal of Harbin University of Commerce(Natural Sciences Edition),2008,24(1):36-39.(in Chinese))
[3] 姚志红,费敏锐,孔海南,等.基于改进遗传算法的藻类神经网络识别[J].上海交通大学学报,2007,41(11):1801-1805.(YAO Zhi-hong,FEI Min-rui,KONG Hai-nan,et al.Neural Network Recognization for Algae Based on Improved Genetic Algorithms[J].Journal of Shanghai Jiaotong University,2007,41(11):1801-1805.(in Chinese))
[4] 贾海峰,张岩松,何 苗.北京水系多藻类生态动力学模型[J].清华大学学报(自然科学版),2009,49(12):1992-1996.(JIA Hai-feng,ZHANG Yan-song,HE Miao.Multi-species Algae Ecodynamic Model for the Beijing Water System[J].Journal of Tsinghua University(Sci&Tech),2009,49(12):1992-1996.(in Chinese))
[5] 刘载文,吕思颖,王小艺,等.河湖水华预测方法研究[J].水资源保护,2008,24(5):42-47.(LIU Zai-wen,LV Si-ying,WANG Xiao-yi,et al.Forecast Methods for Algal Bloom in Rivers and Lakes[J].Water Resources Protection,2008,24(5):42-47.(in Chinese))
[6] 曾 勇,杨志峰,刘静玲.城市湖泊水华预警模型研究[J].水科学进展,2007,18(7):79-85.(ZENG Yong,YANG Zhi-feng,LIU Jing-ling.Algalbloom Prediction Models for Liuhai-lake in Beijing City[J].Advances in Water Science,2007,18(7):79-85.(in Chinese))
[7] BREIMAN L,FRIEDMAN J,OLSHEN R A,et al.Classification and Regression Trees[M].Boca Raton,Florida:Chapman&Hall/CRC,1984.
[8] TORGO L.Data Mining with R:Learning with Case Studies[M].Boca Raton,Florida:Chapman and Hall/CRC,2010:11-15.
[9] 谢益辉.基于R软件rpart包的分类与回归树应用[J].统计与信息论坛,2007,22(5):67-70.(XIE Yihui.The Application of the Classification and Regression Tree Based on the Package rpart in R-Language[J].Statistics&Information Forum,2007,22(5):67-70.(in Chinese) )
(编辑:王 慰)
App lication of R Language-Based Data M ining in Water Environment M anagement
XIAO Kai1,WEIFei2,PENG Chang-shui3
(1.Network Information Center of Changjiang Water Resources Commission,Wuhan 430010,China;2.Agencies Service Center of Changjiang Water Resources Commission,Wuhan 430010,China;3.Information Center,Yangtze River Scientific Research Institute,Wuhan 430010,China)
The authors analyzed themodel of harmful algal blooms in the river on the basis of classification regression tree(CART)algorithm of datamining.Results indicated that phosphate,chloride and themaximum pH values are key factors of algae generation.Furthermore,we employed the R language to validate the superiority and convenience of using CART algorithm.The conclusions and methods could contribute to a more effective water qualitymonitoring and forecasting.
datamining;classification and regression tree(CART);R language;water qualitymonitoring
X52
A
1001-5485(2012)09-0091-04
10.3969/j.issn.1001-5485.2012.09.021
2011-06-28;
2012-05-25
肖 凯(1977-),男,湖北武汉人,工程师,硕士,主要从事水资源管理与数据挖掘方面的研究,(电话)13545284695(电子信箱)xccds1977@gmail.com。
