片上多处理器共享Cache的访存时间最优划分方法
2012-08-04李浩谢伦国
李浩,谢伦国
(国防科技大学 计算机学院,湖南 长沙 410073)
1 引言
为了保持处理器性能的持续增长,多核(multicore)处理器或片上多处理器(CMP, chip multiprocessor)已成为现代处理器发展的主流。片上处理器核数目的不断增加,以及芯片管脚数目的有限使得处理器核片外访存开销越来越大,这给本来已经很严重的存储墙问题带来了更大的挑战。人们不得不在芯片上放置更多层次更大容量的片上存储系统,以减少处理器对片外存储器的访问需求。片上存储系统性能的好坏已经成为决定 CMP系统性能的关键因素。为了提高片上存储系统的性能,很多设计都采用大容量的末级共享 Cache。本文的研究目标旨在有效管理CMP末级共享Cache,优化CMP上运行多个应用程序时的整体性能。
当运行在 CMP上的多个应用程序竞争同一个共享Cache空间时,传统的LRU替换策略会显式的按照请求的频率给那些请求频率高的应用分配更多的Cache空间。但是,给一个请求频率高的应用分配更多的Cache空间不一定就能给它带来相应的性能提升。例如,当一个流应用的工作集大于Cache总容积时,由于它访问过的Cache块重用性较低,即使给它分配更多的Cache空间,也无法给性能带来多大的提升。为了提高多程序整体的访存性能,本文希望能够把Cache空间分配给那些能通过得到更多Cache空间获得较大性能提升的应用,以提高多个竞争程序总的执行性能。
目前大部分Cache划分方法,无论是静态最优划分方法[1],还是动态划分(DP, dynamic partitioning)[2]方法,还是基于利用率的 Cache划分(UCP,utility-based Cache partitioning)[3]方法,都是以降低多个程序总的Cache失效率为优化目标。在很多情况下,减少Cache失效次数确实能够带来性能的提升,但是在某些情况下,失效次数的减少并不意味着程序执行性能的提升[4],这是因为:1)应用程序的访存特性导致它们对Cache失效的敏感度各不相同,相对而言,计算密集型应用对Cache失效的敏感度比访存密集型应用要小很多;2)非阻塞Cache[5]、乱序执行、以及提前执行[6]等技术的出现,使得有些 Cache失效引发的片外访存能够重叠执行,称之为存储级并行(MLP, memory level parallelism)[7],这种存储级并行对程序执行时间的影响是不同的。由于每个Cache失效带来的实际性能开销各不相同,因此不同应用程序之间,Cache失效率的高低变化并不能直接反映程序执行性能的高低变化,划分后总的 Cache失效率最优并不能代表总的程序执行时间最少。以往的大多数Cache划分方法都没有考虑MLP问题,Zhou等人[8]提出了一种考虑了MLP问题的Cache划分算法,但是他们主要针对的是Cache的公平性。本文提出一种访存时间最优的Cache划分(OMTP, optimal memory time Cache partitioning)方法,通过独立的硬件获取每个划分区间内每个应用程序在占用不同大小的Cache空间时失效率的变化情况以及这些失效带来的平均访存时间,将两者用于指导Cache划分算法的执行,使多个竞争程序总的执行时间最少。模拟实验结果表明,OMTP相比UCP吞吐率平均提高了3.1%,加权加速比平均提高了1.3%,取得了较好的性能提升。
2 访存时间最优Cache划分
目前许多多处理器系统都采用共享 L2 Cache来减少片外访存,当有多个应用程序同时运行在这样一个系统上时,有可能会出现某些应用程序占用很多Cache空间却无法得到相应的性能提升,而某些只需要再获得很少Cache空间就能大幅提升性能的应用程序则不能获得所需 Cache空间的情形。Cache划分(partitioning)的目的就是给每一个应用程序分配适当的L2 Cache空间,以提高多个应用程序总的执行性能。
假设有N个应用程序共享同一个Cache空间,Ci代表分配给应用程序i的Cache块数,C为总的Cache块数,则Cache划分可以用集合来定义。Suh等人[2]提出的最优 Cache划分是使总失效次数( )(iiCM代表应用程序i在占用iC个Cache块位置时的失效次数)最小的划分。把这种最优划分称作失效率最优划分。在以往的一些研究中,无论是动态划分(DP, dynamic partitioning)[1]方法,还是基于利用率的Cache划分(UCP)[2]方法,都是追求失效率最优的划分方法。
但是,由于每个Cache失效所造成的开销不同,并且各个应用程序内在的访存特征也各不相同,使得失效率的多少并不能代表 Cache实际性能的高低,失效率最优并不能代表访存时间最优。真正的性能最优划分应该是多个应用程序总的执行时间表示应用程序i占用iC个Cache块位置时的执行时间)最小的集合
应用程序的执行时间可以用式(1)计算[7]:
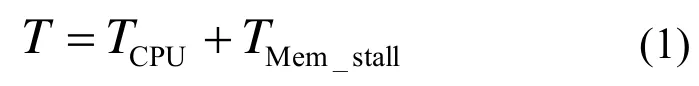
式中TCPU代表 CPU运算时间,它表明了执行应用程序所有操作必须花费的时间(这个时间包括L2 Cache命中延迟),不会随着存储系统性能的好坏而改变,在本文的研究中,它是一个常量。TMem_stall代表存储系统停顿时间,因为本文研究的对象是L2 Cache,因此这个存储系统停顿时间指的是L2失效导致的系统停顿时间(不包括 L2命中延迟造成的系统停顿时间重叠)。使多个应用程序总的存储停顿时间最小的集合{C1,C2,… ,CN}就是访存时间最优Cache划分。

式中NMisses代表应用程序失效次数,Caverage代表每个失效的平均失效开销。因此,只要能够知道每个应用程序的失效次数和对应的每个失效的平均失效开销,就可以预测出总的存储停顿时间。
因为对组相联Cache中的每一个Cache块进行划分硬件开销太大,本文只对组相联 Cache的路(way)进行划分。
3 划分算法与实现
3.1 平均失效开销计算
根据式(2),每个应用程序的平均失效开销可以根据该应用程序在划分区间内总的存储停顿时间和总的失效次数来计算。
通过监测每个处理器核流水线的状态,可以统计出处理器核上运行应用程序的流水线停顿周期数,但是流水线停顿周期数里包含了与L2命中延迟所造成的停顿时间重叠的部分,从所有的停顿周期数中减去这一重叠部分就可以得到由L2 Cache失效引起的总停顿周期数。为了判断一段时间是否属于重叠时间,给每一个L1指令和数据Cache都增加一个计时器,当发生一次L1Cache失效,向L2发送一次请求时,该计时器被赋予一个值L2_Latency,L2_Latency的大小为L2 Cache的命中延迟(一般是一个固定值),每过一个时钟周期,计时器减1。当计时器时间大于0时,说明这段时间还属于与L2命中延迟时间重叠的部分,不能记入总的存储停顿时间。
每个划分区间内各处理器核在 L2 Cache上的失效次数通过监测L2失效状态保持寄存器(MSHR,miss status holding register)的状态获得,为了判断MSHR中的失效属于哪个处理器核,在MSHR的每一项中添加lbN位用于标识该失效属于哪个处理器核。平均失效开销计算的算法如算法1所示。
算法1 计算平均失效开销Caverage


3.2 Cache失效率预测
为了能够知道应用程序在占用不同数目 Cache路时的失效率变化情况,给每个处理器核增加一个额外tag目录(ATD, auxiliary tag directory)[3],就像给每个处理器核分配了一个虚拟的私有 L2 Cache。ATD跟目标 L2 Cache(待划分的共享 L2 Cache)组相联结构相同,采用LRU替换策略。每个ATD仅仅包含目录项,不包含数据块。当L1发生失效时,请求会同时发向实体L2 Cache和对应处理器核的ATD。ATD和真正的私有L2 Cache一样运转,但它不会返回数据,而是用来统计处理器在不同路上的命中信息。由于基本的 LRU替换策略遵循一种堆栈机制,即如果一个数据在Cache路数为N时命中,那么它在Cache路数大于N时也必然命中,因此根据应用程序在不同Cache路上的命中次数分布情况,可以得到应用程序占用Cache路数目发生变化时失效率的变化情况。
因为每一个处理器核都要有一个对应的ATD,每个ATD的大小都跟真正的共享L2Cache目录一样大,当处理器核数目增加时,ATD的硬件开销将会变得不可接受。采用组抽样技术[3]来减少硬件开销。ATD以某一个固定间隔选取组(这个策略叫做简单静态策略[4])来进行统计,最后得到的数据近似全局的统计数据。Qureshi[3]认为,总共选取 32组作为抽样进行统计可以很好地近似全局统计数据。
3.3 OMTP划分算法
每个划分区间结束时,通过监测每一个竞争程序在ATD中各路的命中情况以及计算出来的Caverage,选择使总访存时间最少的划分策略。假设ma和mb分别代表一个应用占用a路Cache和b路Cache时的失效率(a<b),则该应用程序占用的Cache路数从a增加到b时所节省的访存时间Uab可以如下定义:
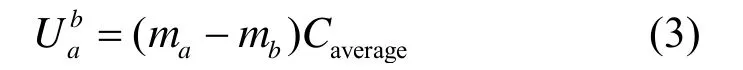
假设2个应用程序A和B共用一个 16路的Cache。A和B分别代表2个应用程序节省的访存时间,则应用A和B总共节省的访存时间Utot可以如下计算:

使2个程序总共节省的访存时间值最大的划分(i,16-i)就是访存时间最优的划分。
划分算法的目的是从所有的划分组合中寻找一个使总的访存时间最优的一种划分。当应用程序只有2个时,N路Cache的划分组合只有N+1种。但是当应用程序数量增加时,划分组合的数量会呈指数值增长,这样要找出所有组合中访存时间最优的划分不太现实。例如当有4个应用程序共享一个32路组相连Cache时,划分组合有6 545种,当应用程序数目增加到 8个时,划分组合猛增至15 380 937种。这个寻找最优划分的问题已经被证明是一个 NP难(NP-hard)问题[9]。采用 Qureshi等人提出的超前(lookahead)算法[3]来寻找符合条件的划分,算法伪码如算法2所示。
算法2 超前算法
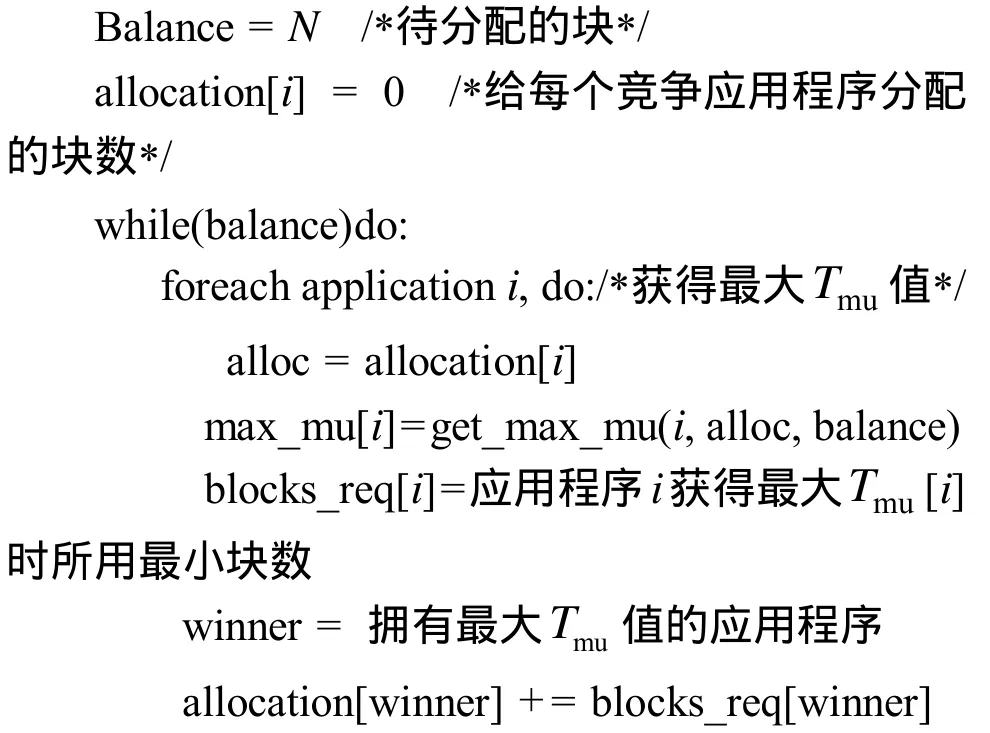

U= 当分配的块从a增加到b时,应用p所节省的访存时间
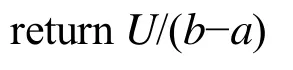
在该算法中,muT代表应用程序在分配的块数从a增加到b时的平均每一路节省的访存时间,它的定义如下:
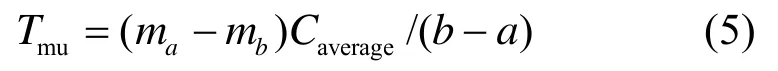
超前算法的时间复杂度为O(N2),对于一个32路组相联Cache,采用超前算法只需要512次操作,相对于500万时钟周期的划分区间来说几乎可以忽略不计。在本文的研究中,每一个应用都至少要分配1路,并且在每个划分区间结束开始一个新的划分区间时,将 ATD中所有命中计数器的值减半,使得ATD得到的命中信息具有局部时间相关特征。
3.4 OMTP方法硬件实现
OMTP方法的硬件结构如图1所示,每个处理器核都拥有各自的L1指令和数据Cache,每个处理器核对应一个Profiler模块,该模块的作用主要有2个:1)获取每一个应用程序的平均MLP失效开销;2)获取每个应用程序在占用不同大小 Cache路数时的失效率变化情况。Profiler模块获得信息提供给划分算法硬件单元。划分算法硬件单元负责每一个划分时间区间内划分算法的实现。
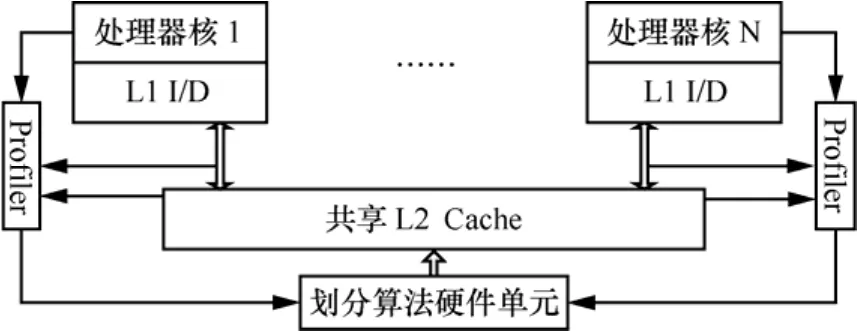
图1 Cache划分机制硬件结构
对LRU算法(或者是伪LRU算法)进行扩展。给共享L2Cache中每一个Cache块的tag中增加lbN(N为处理器核数目)位用于标识该块被哪个处理器核占用。每个划分区间结束时,通过3.3节的算法,可以得到每个处理器核所分配的最高占用Cache块数值A(i),用于指导下一个划分区间内的替换策略。在每一个划分区间内,当一个Cache失效,替换引擎统计引发该失效的应用程序i在Cache中占用的路数,如果不超过A(i)值,则在本应用占用的Cache块之外选择一个LRU块驱逐,如果达到或者是超过了A(i)值,则在本应用占用的 Cache块中选择一个LRU块驱逐。每执行5M指令运行一次划分算法,进行重新划分。
4 测试与分析
使用全系统模拟器,从吞吐率、失效率以及加速比3个方面评估LRU替换机制、UCP方法以及本文提出的OMTP方法的性能。
4.1 测试平台
GEMS模拟器[10]是威斯康辛大学在 Virtutech公司开发的通用并行模拟器simics[11]的基础上扩展实现的。simics是一个全系统虚拟机,可以进行功能模拟和时序模拟,它支持 3种模拟模式:1)正常模式;2)微体系结构模式;3)暂停(stall)模式。GEMS模拟器在暂停模式下增加了对Cache系统和互联网络的模拟。采用GEMS模拟器对OMTP划分方法进行模拟测试。
本文模拟实验平台为一个双核 CMP系统,每个处理器核为乱序执行的超标量处理器,有自己的L1指令和数据Cache,2个处理器核共享一个统一编制的L2 Cache和主存。具体参数如下:
1) 处理器核:2个,4流出,乱序执行指令窗口大小为64,保留站大小为128;
2) L1Cache:ICache DCache为32KB,数据块大小为64,B4路组相联;
3) 共享L2Cache:1MB,数据块大小为64byte,16路组相联,命中延迟为15个时钟周期,MSHR大小为32;
4) 主存:400个时钟周期。
4.2 度量指标
多道程序并行执行时的度量指标有很多种,本文选取其中的3种:吞吐率、失效率以及加权加速比。设iI为应用程序i在并行执行时的IPC,iS为应用程序i在单独执行(独享L2 Cache)时的IPC,MRi为应用程序i在并行执行时的L2 Cache失效率。则这3种度量指标定义如下:
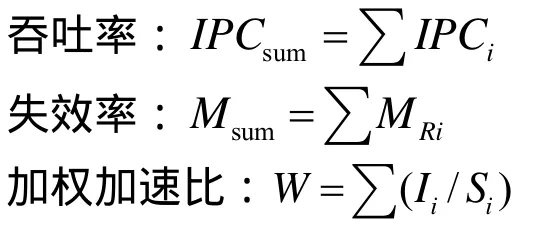
这三者中,吞吐率反映了处理器单位时间里的处理能力,失效率反映了系统的整体性能,而加权加速比直接反映了执行时间的变化。
4.3 测试程序
本文从SPEC CPU2000测试程序里面选择了一些程序,并将它们两两组合起来,构成本文的基本测试用例(如表1所示),表1中第3、4列数据分别是2个应用程序独享L2 Cache时Caverage平均值,第5列给出了2个竞争程序平均失效开销差异。

表1 基本测试用例及它们的平均失效开销特征
采用 simics提供的 magic指令控制程序的执行,在每个程序完成初始化Cache的过程后,每个程序最少执行250M条指令,每5M条指令为一个划分区间。
4.4 实验结果与分析
通过比较LRU替换机制、UCP划分方法和OMTP划分方法在吞吐率、失效率以及加权加速比3个性能度量指标上的变化来评估OMTP方法的性能。
4.4.1 吞吐率
图2比较了LRU和2种划分方法吞吐率的差异,标号1到标号12分别对应测试用例中的1到12组测试程序,标号13为所有测试用例吞吐率平均值。在第7、8、9组中,由于2个竞争应用程序的平均失效开销相差很小,OMTP方法在 UCP方法基础上性能提升不明显。在第3组中,因为程序本身性能提升空间有限,UCP方法和OMTP方法均无明显作用。在其他各组测试中,OMTP方法都取得比较好性能提升。跟 UCP方法相比,OMTP方法的吞吐率平均提高了3.1%。
4.4.2 失效率
图3给出了LRU和UCP方法及OMTP方法在失效率上测试结果。标号1到标号12分别对应测试用例中的12组测试程序,标号13为所有12组测试程序的平均失效率。从图3可以看出,OMTP方法的失效率比UCP方法要略高。
4.4.3 加权加速比
图4给出了LRU和2种划分方法在加权加速比上的差异。标号1到标号12分别对应测试用例中的12组测试程序,标号13为所有12组测试程序的平均加权加速比。在第7、8、9组中,因为同组2个应用程序的平均MLP失效开销相差不大,因此OMTP方法和UCP方法性能几乎一样,而在其他各组中,OMTP方法的性能都要好于 UCP方法。跟 UCP方法相比,OMTP方法的加权加速比平均提高了 1.3%。加权加速比的对比充分说明了OMTP方法能够提高程序的实际执行性能。
4.5 硬件开销
OMTP方法的硬件开销主要集中在2个方面:
1)为了划分算法的执行,每个 Cache块都要增加lbN(N为处理器核数目)位用于标识所属处理器核;2)Profiler模块所用硬件开销。假设目标系统为双核、共享1MB L2 Cache、16路组相联、块大小为64byte、L2 MSHR有32项的系统。则第一项开销如下计算:

Profiler模块中ATD的硬件开销统计为:ATD目录项(1有效比特+24bit tag+4bit LRU)为29bit,每一组ATD项数为16项,抽样组数为32组,ATD目录开销(29bit×16路×32组)为1 856byte。Profiler模块中还有计数器18个(16个用于统计命中信息,1个用于统计L2失效次数,1个用于统计存储停顿周期数)、计时器 1个,所用硬件开销合计1 856+4×19=1 932byte。

图2 吞吐率测试结果
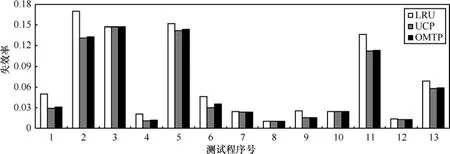
图3 失效率测试结果

图4 加权加速比测试结果
除了1)和2)中的开销以外,L2_MSHR每一项中增加了1bit,共32bit(4byte)。因此实现OMTP方法额外硬件总开销为2 000byte+1 932byte×2+ 4byte=5 868byte。不采用任何划分方法的L2 Cache硬件开销为 1MB+(24+4+1)×(1MB/64byte)=1 488KB。因此 OMTP硬件开销在不采用任何划分策略的原始硬件开销上共增加了5.868KB/1 488KB0.4%≈。
5 结束语
当多个竞争应用程序共用一个共享Cache时,以往的Cache划分算法都是以减少竞争程序总的失效率为第一目标。但是由于每个应用程序的 Cache失效开销各不相同,减少总的Cache失效率并不一定能够提高程序整体执行性能,Cache失效率最优并不能代表程序实际执行时间最优。本文提出一种访存时间最优的Cache划分(OMTP)方法,该方法通过统计计算出每一个应用程序的 MLP失效开销,通过ATD辅助硬件得到应用程序在各个Cache路上的命中分布情况,并将这2项用于指导划分算法的执行,优化了多个竞争程序总的执行时间。
模拟实验结果表明,虽然OMTP方法的Cache失效率比 UCP方法略有增加,但是具有更高的吞吐率和加权加速比,降低了程序实际执行时间。但是本文的实验结果均来自一个双核系统,当处理器核数目增加时,算法的可扩展性问题还有待进一步研究。
[1] STONE H S. Optimal partitioning of Cache memory[J]. IEEE Transactions on Computers, 1992, 41(9): 1054-1068.
[2] SUH G E, RUDOLPH L, DEVADAS S. Dynamic partitioning of shared Cache memory[J]. Journal of Supercomputing, 2004, 28(1):7-26.
[3] QURESHI M K, PATT Y N. Utility-based Cache partitioning: a low-overhead, high-performance, runtime mechanism to partition shared Caches[A]. MICRO-39[C]. 2006.423-432.
[4] QURESHI M K, LYNCH D N, MUTLU O,et al. A case for MLP-aware Cache replacement[A]. ISCA-33[C]. 2006. 167–178.
[5] KROFT D. Lockup-free instruction fetch/prefetch Cache organization[A]. Proceedings of the 8th Annual International Symposium on Computer Architecture[C]. 1981.81-88.
[6] MUTLU O, STARK J,WILKERSON C.et al. Runahead execution: an alternative to very large instruction windows for out-of-order processors[A]. Proceedings of the 9th International Symposium on High Performance Computer Architecture[C]. 2003.129-140.
[7] CHOU Y, FAHS B, ABRAHAM S G. Microarchitecture optimizations for exploiting memory-level parallelism[A]. ISCA[C]. 2004. 76-89.
[8] ZHOU X, CHEN W G, ZHENG W M. Cache sharing management for performance fairness in chip multiprocessors[A]. Proc 18th International Conference on Parallel Architectures and Compilation Techniques(PACT 2009)[C]. Raleigh, North Carolina, USA, 2009. 384-393.
[9] RAJKUMAR R. A resource allocation model for QoS management[A].The 18th IEEE Real-time Systems Symposium[C]. 1997.298-307.
[10] MARTIN M M K, SORIN D J, BECKMANN B M,et al.Multifacets general execution-driven multiprocessor simulator (gems) toolset[J].SIGARCH Comput Archit News, 2005,33(4):92-99.
[11] MAGNUSSON P S, CHRISTENSSON M, ESKILSON J,et al. Simics:a full system simulation platform[J]. Computer, 2002, 35(2):50-58.
[12] PATTERSON D A, HENNESSY J L. Computer Architechture: a Quantitative Approach[M]. San Francisco: Morgan Kaufmann Publish,1996.
