改进的空间协议识别算法
2012-08-04郑天明王韬郭世泽李华赵新杰
郑天明,王韬,郭世泽,李华,赵新杰
(1. 军械工程学院 计算机工程系,河北 石家庄 050003;2. 北方电子设备研究所,北京 100083;3. 中国人民解放军第六九零九工厂,江苏 苏州 215300)
1 引言
当前,各种卫星网络已被广泛应用到民用、军事领域的各个角落,对卫星网络安全性进行分析十分重要,其中协议识别是卫星网络安全性评估的研究热点[1]。空间协议是卫星网络的骨架和神经,是维系网络正常通信的纽带,各层协议在空间信息结构中占有核心地位,通过对卫星网络协议进行识别与分析,可确定各层协议类型,获取网络拓扑结构、路由算法、IP地址分布等信息,探测协议漏洞或获取高层信息,在此基础上进行更高层次的安全评估。
BM算法(boyer-moore algorithm)[2]是最为经典的协议识别算法,算法主要根据常用协议模式串规则,通过对待识别数据特征进行分析,从中查找模式串并确定其所在位置,在此基础上进行协议识别。BM算法主要适用于模式串较长、字符集较大的协议识别。然而,在卫星网络中,由于空间数据具有特征位长度短、数据字符集小特点(如典型的SCPS-NP[3]协议特征仅为3bit),传统的BM算法很难从中获取协议特征,存在执行效率和识别准确度较低问题。
为此,本文提出了一种改进的BM算法。提出的算法给出了一种计算空间数据中相同比特距离的数据预处理方法,降低字符串长度;并引入小数跳进机制,提高了BM算法分组头匹配效率;在此基础上应用正则表达式方法进行规则判断,然后给出了一种基于层次关系法的多层协议识别方法,提高了多层网络协议的识别效率;最后以应用广泛的SCPS(space communication protocol specification)协议识别为例,应用提出的算法进行了实验。
2 空间协议特征分析
空间数据在传输过程中具有传输时延长、信道误码率高、非对称、适合同地面终端进行协议转换等特点[4]。为适应这种特点,CCSDS(consultative committee for space data systems)委员会制订了空间传输协议栈SCPS。SCPS协议栈结构如图1所示,其自下而上包括:物理层、数据链路层、网络层、运输层和应用层,以及介于网络层与传输层之间的安全保护机制等多层协议,其中每层又包括若干个可供组合的协议[5~9]。
经分析,空间数据结构特征可归纳如下。
1) 协议结构层次化,对空间数据进行分析需要首先解调出比特流数据,并逐层开展协议分析;
2) 协议特征位较短,数据中模式串不易被识别;协议长度可变,典型模式串识别方法不具优势;
3) 链路层协议兼容各种上层协议,空间数据各层具有紧密相关性,分析网络层协议可获取传输层协议类型,而分析链路层协议却无法降低网络层协议分析难度;
4) 数据量大,同一时段内截获的数据类型多样,针对单一协议的识别效果不佳;业务需求大、种类多,卫星通信技术以及协议更新速度快。
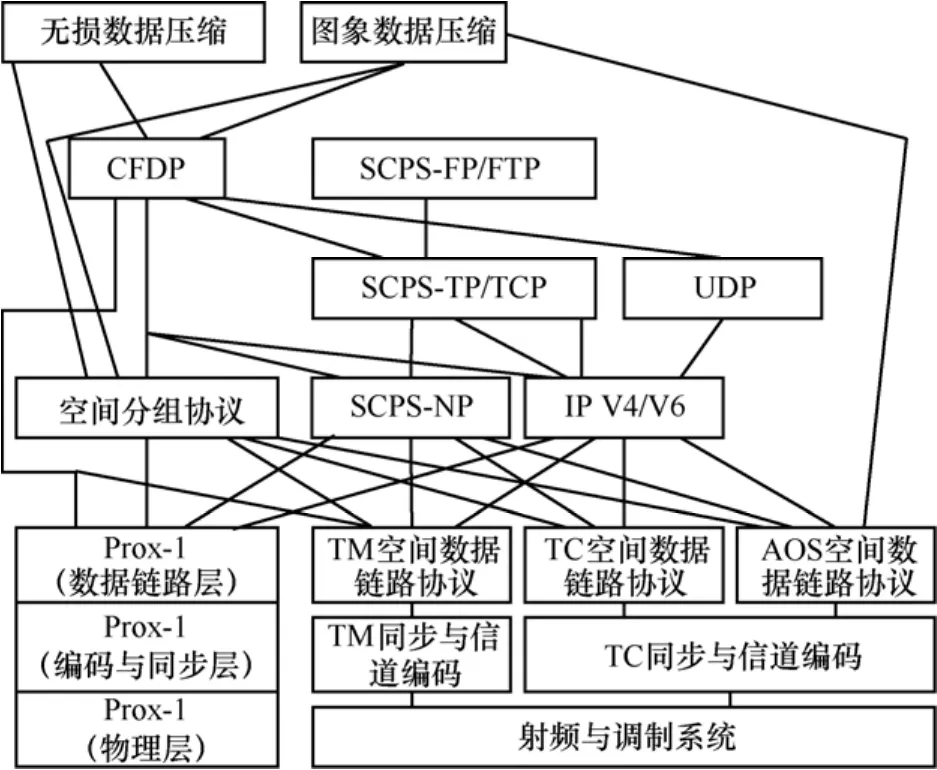
图1 SCPS协议栈结构
综上,空间协议识别应根据协议栈结构进行层次分析,分析可选取协议特征位作为识别基准点,参照协议结构拆分数据进行分析,并在单层协议识别基础上对多层协议开展分析。
3 基于BM算法的空间协议识别分析
将截获数据存储到一个字符数组,将协议特征转化为特征模式串,可将协议识别归结为模式串匹配[10,11]问题,通过对协议特征和数据进行逐位匹配,可分析出协议类型。BM 算法[2]是最具有代表性的模式串匹配算法,识别速度较快,执行时间复杂度为O(n+σm)[12],σ为模式串在数据中出现频率相关变量,m、n分别为模式串、目标串长度。如果模式串频繁出现,BM算法在查找阶段时间复杂度可以表示为O(mn),最好时间复杂度是O(n/m)。
图2为应用BM算法对基于比特、英文字母字符集的匹配对比。易见,字符集{0,1}所生成的数据,每位出现0、1的概率为50%。应用BM算法进行模式串匹配时,在模式串跳进过程中遇到干扰项概率较高、跳进距离较短、误判率较高、任意4bit出现模式串概率为6.25%。相比较而言,由字符集合{a~z}所生成的模式串,每项出现概率仅为3.8%,跳进过程中遇到干扰项概率较小,跳进距离也相对较大,误判率较低,任意4bit出现模式串的概率约为0.000 207 9%。
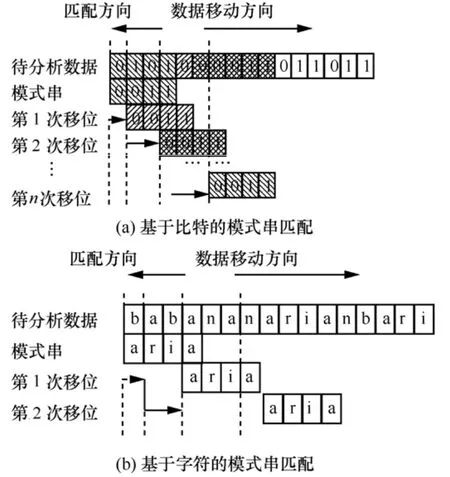
图2 应用BM算法对不同字符集的模式串匹配对比
为提高模式串匹配效率,现有研究大都着眼于改进BM算法的模式串跳进方式,研究者相继提出了 QS[13]、RSPS[14]、Wu Manber和 SBOM[15](set backward Oracle matching)等算法。以SBOM算法为例,算法的预处理过程是根据所有模式串构造匹配使用的Oracle结构,以识别匹配窗口内最长字串,其算法复杂度为p为命中密度,α为字符集大小。
通过对上述几种算法进行对比分析不难发现:改进的BM算法在命中密度低(模式串较长、字符集较大[16])情况下识别效率极高[17],应用到汉字搜索等领域,可有效提高匹配效率。但随命中密度的增大,上述算法的识别效率将急剧降低(在处理0、1数据时,字符集较小所以p极大,SBOM的复杂度约为O(mn),接近于BM算法)。
总的来说,应用BM算法及其改进算法进行空间协议识别存在以下不足:模式串长度较短,字符集元素有限(只有0、1组成),模式串跳进和识别效率低下;即使增大模式串长度,将不可避免增多模式串中通配符数量,降低BM算法识别效率。
4 改进的空间协议识别算法
4.1 主要思想
为解决应用BM算法进行空间协议识别问题,我们提出了一种改进算法。通过对空间数据进行预处理,增大模式串字符集;然后改进模式串跳进规则,提高数据识别效率,形成数据分组;通过分组标识使用特定DFA匹配引擎,抑制DFA状态数膨胀,实现单层协议识别;在此基础上结合多层协议间关联关系,缩小多层协议识别范围,并调整匹配顺序,提高多层协议识别效率和准确度。应用改进算法进行空间数据分析过程如图3所示。
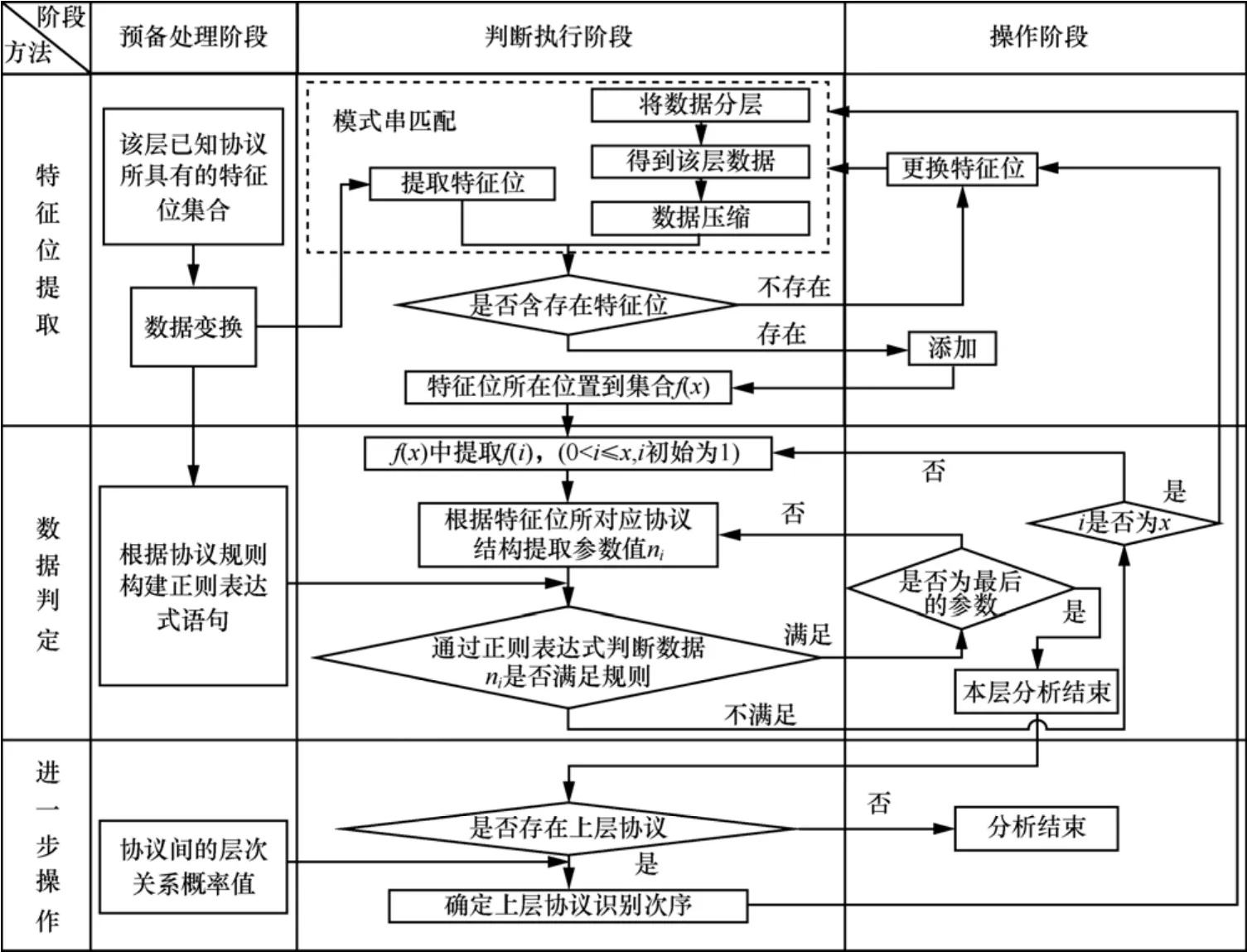
图3 基于CRB算法的数据分析过程
4.2 基于比特距离的空间数据预处理
在协议识别前,常需先将数据转换为比特流,基于比特流进行协议分析。由于信道误码等原因可造成部分比特数据误码,主要表现为2个方面:首先,数据内容倒置,在这种情况下,如果直接将比特数据按照十六进制方式进行存储,将1bit误码存储后造成1byte误码,即误码放大,因此,基于软件系统的协议分析,比特流中的每1bit通常按照字符(字节)进行存储,文中称为字节流;其次,数据首字符难于确定,通常的分析方式无法判断数据起始位置,将造成大量错误分析,将BM算法同正则表达式方法结合起来可有效解决该问题。
传统BM算法基于字符进行比对跳进,虽然能够有效解决起始位置难于确定问题,但由于空间比特流转换成的“0”和“1”字符较多,且由“0”和“1”组成的字符集数目较小,导致协议分析效率低下。为此,文中给出了一种计算相邻比特距离的空间数据预处理算法。具体算法如下:选择字符“1”为特征位,并记录连续2个字符“1”之间的字符“0”的个数N,并将N以字节形式保存。该预处理算法可增大模式串字符集数量、提高字符跳进距离、降低数据分析时间复杂度。
图4为应用BM算法对原始空间数据和预处理后数据进行识别的过程。对于16byte存储的“0101000011011011”字节流,经预处理后可转换为 8byte“11401010”。
根据第3节,模式串频繁出现时,查找阶段时间复杂度O(mn)同目标串、模式串长度成正比。文中数据预处理算法可减小模式串长度m和目标串长度n,降低模式串匹配复杂度。数据查找阶段复杂度可降低到O(mn/4),预处理时间复杂度为O(n)(在长度为n数据中查找“1”所耗时间),整体时间复杂度为O(n+mn/4),显然O(n+mn/4)<O(mn),提出算法可加速数据分析效率。
由于 BM 算法效率同模式串字符集数量成反比,在空间数据识别过程中,传统模式串字符集仅为“0”、“1”2种,单个跳进距离最多为 1,跳进次数等同于数据串长度。应用本节预处理算法,模式串字符集可扩展至“0到255”256种。当数据串字符为0时,跳进距离为1,等同于BM算法;而当数据串字符A大于0时,单次跳进距离为A+1。由图4可知,应用BM算法模式串匹配的平均跳进距离为1,跳进次数为16,而应用本节预处理算法,平均跳进距离为 2,跳进次数为 8。易见提出算法增大了BM算法的跳进距离,减小了跳进次数,进而提高了识别效率。
4.3 基于小数跳进的模式串查找
在4.2节对空间数据预处理的基础上,本节给出一种基于小数跳进机制的数据查找算法,可有效改进BM算法后缀转移和不良字符转移机制。
小数跳进机制基本思想如下:依据变换后数据内在意义,即每比特代表变换前数据1的前后间隔比特数,将目标串自起始位置起往右一个模式串长度的字符与模式串最小值进行比较。如果模式串长度的字符小于模式串最小值,则应从目标串的下一比特开始新一轮匹配,相当于把模式串在目标串中向右滑过,即一次跳过“滑过距离”个字符,从而实现数据匹配的快速跳进。
算法1给出了基于小数跳进机制的数据查找算法,同BM算法一样,文中小数跳进机制也采用从右向左逆向检索匹配窗口。
算法1 基于小数跳进机制的数据查找算法
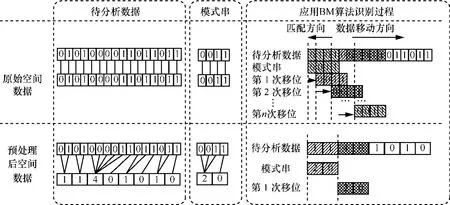
图4 算法对比
输入:预处理后数据串T, 模式串P
输出:模式串匹配位置集合S

小数跳进机制正确性证明如下。
命题1 已知数据T长度L(T)和模式串P长度L(P),在数据匹配过程中,模式串最小值min(P),若Tx<min(P),数据T中下一个大于min(P)位置为Ts,则T从xbit开始的子串Tx-1+i(0<i<s-x)与模式串P不匹配,即¬(Tx-1+i+k=Pk)。
证明 假设命题不成立,则Tx-1+i+k=Pk,0<=k<L(P),即Tx+i+k-2还原数据所得值最后 1bit应为“1”,Tx-1+i+k最后1bit也为“1”,即2个“1”之间“0”的个数应为Tx-1+i+k个。
因为Tx-1+i+k=Pk,所以根据数据变换规则可知Pk-1之后下一个“1”所在位置应距离Pk-1为Tx-1+i+k位。同样对模式串P进行逆变换后,可知Pk-1后下一个“1”所在位置应该距Pk-1为Pkbit,与Tx<min(P)已知条件相矛盾,故假设不成立,命题结论成立。
4.4 基于正则表达式的单层空间协议识别
由第2节可知,空间数据串中查找到的标识比特并不一定为模式串特征比特。通过较短特征比特匹配方式查找数据可形成集合SN,而真正特征比特集合为ST,SN中元素数量应大于等于ST中元素数量,且ST∈SN式恒成立,所以需要通过规范限制方式减少SN数量,即在SN中查找真正特征位集合ST,文中基于正则表达式[18]DFA方法实现。
DFA方法却受限于状态数膨胀[19,20]问题,解决方法一般通过将规则集分成N组来实现[21],但这样会将处理速度降为原来的 1/N,增加存储器所需带宽,限制匹配速度提高。而应用文中改进算法,在对数据集进行整合的前提下,依据当前所处理子集,将相互之间导致状态膨胀的正则表达式分在不同分组,在不影响匹配速度前提下可有效抑制DFA状态数膨胀。通过对空间协议结构进行分析,将空间数据类型归纳为4种,并用正则表达式进行规则判定,具体类型及分析方式如表1所示。

表1 数据类型及分析方式
4.5 基于层次关联关系的协议选择
单层协议识别完成后,可分析出单层使用协议、数据长度、源目的地址等参数。如果要进一步分析下层协议,一般做法是通过分析本层数据长度,跳转到下层数据起始位置,逐层进行协议识别。设当前识别的底层协议包含m个协议,上层包含n个协议,在等概率的协议分析条件下,应用一般的协议分析模型,一共有mn个协议组合,需进行mn次协议分析判定。该方法忽略了本层协议往往规定、限制上层协议这一规则,导致识别效率低下。
事实上,协议上下层协议之间存在一定的关联关系,论文通过分析这种关联关系,并计算上层协议的出现概率,将上层协议分析次序进行了合理调整,减小了不必要的判定,进而降低了协议识别复杂度。如图1所示,如果在网络层使用“空间分组协议”,那么在传输层就不会使用 SCPS-TP、TCP或 UDP协议,进行传输层协议识别时就无需选取SCPS-TP等协议特征位,可在一定程度上提高识别效率。
基于该思想,给出了一种基于层次关系的协议选择机制,根据已识别协议所兼容上层协议,缩小上层协议识别范围,提高识别效率。算法在实现自底向上分层识别后,统计并记录该层协议同上层协议关系,在大量数据样本基础上,对上层协议出现概率进行归纳,后续识别可根据归纳概率确定多层协议识别顺序,提高识别效率。基于层次关系的协议选择机制算法如算法2所示。
算法2 基于层次关联的协议选择机制
输入:变换后数据串T,某层协议C(Xi)
输出:整条数据所使用的协议

r1、r2← 权重值
L← 模式串匹配起始位置
1) 如果现有的协议特征库中有U(Xi+1)协议符合规则C(Xi).NextProtocol
2) 则把该协议视为已知协议
3) 本算法将提供基于临近层协议权重比较的方式,将数据进行分类
4) 之后重新设置P(C(Xi-1)|C(Xi))、P(C(Xi+1)|C(Xi))、P(C(Xi+2)|C(Xi))的出现权重值r1、r2、r3。
5) 给出上层协议类型C(Xi+1).Pattern
6) 回到第1)步,进行下一轮比较
7) 如果现有的协议特征库中没有协议符合规则
8) 本算法将对临近层协议的置信区间进行比较,将数据进行分类
9) 出现概率分别为P(C(Xi-1)|C(Xi))、P(C(Xi+1)|C(Xi))、P(C(Xi+2)|C(Xi)),而权重值分别为r1、r2、r3。如果对于未知协议C1(Xi),同该未知协议集合中临近协议相对比
10) 如果待分析的数据段∑rtP(C(Xk)| C(Xi)){其中,k∈(i-1、i+1、i+2),t∈(1、2、3)}较大
11) 更新临近层协议的置信区间
12) 返回该未知协议C(Xk). Protocol的所属类别
13) 将该类别进行归纳
14) 更新协议类别库
15) 返回到第7)步,循环进行之后的识别
16) 反之
17) 判定该数据使用一种新协议
5 实验结果与分析
在Windows 2000环境下,基于Visual C++6.0语言,设计实现了空间数据分析系统,可生成符合SCPS空间协议标准的数据流,并存入数据库。此外,针对SCPS协议族,对几种当前常用的网络层、传输层、应用层协议特征进行了归纳,建立了相应的协议特征规则的正则表达式,并应用文中改进算法进行了大量的数据分析实验。
5.1 单层空间协议识别实验
实验中,首先读取待分析数据,应用 4.2节算法进行数据预处理,然后应用 4.3节小数跳进机制算法实现协议模式串的快速查找,实现单层协议识别。
图5为应用4.3节方法同传统BM算法识别空间数据的比较,可以看出,提出算法识别效率可提高至BM算法的2倍。
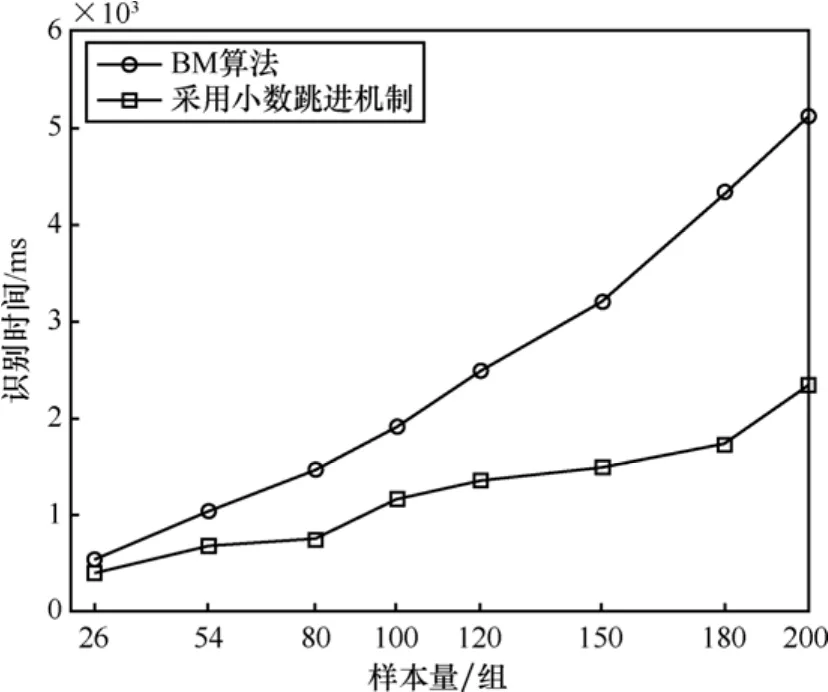
图5 空间数据单层协议识别比较
由上可知,提出算法在规则复杂度较高,数据量较大的情况下,通过变换空间数据的方法有效减小了n、m,增大了跳进距离,解析单条数据复杂度为O(4y(mn/(4+α)+n) (y表示经筛选后某一层可能的协议个数,y<P,α与m中连续“1”出现的频率有关)。
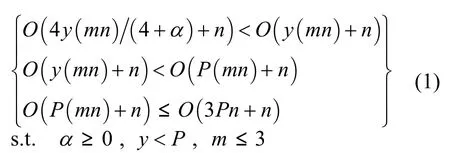
由式(1)可以得出:
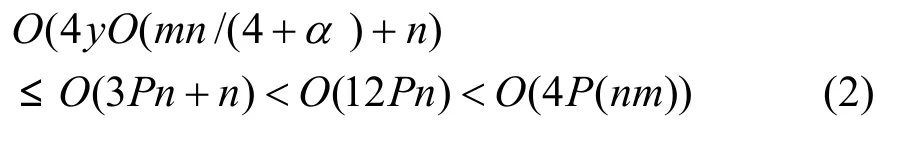
式(2)成立。易见,对于单层协议识别,文中提出算法时间复杂度可降低到BM算法的(1+m/4)/m。
5.2 多层空间协议识别实验
在单层空间协议识别基础上,又应用4.5节算法对多层协议识别进行了实验。
以SCPS协议族为例,传输层协议包括SCPSTP、TCP和UDP 3种典型协议,应用层包括CFDP、SCPS-FP和FTP 3种典型协议。图6给出了卫星网络协议识别中,传输层和应用层协议的架构及出现概率示例。按照单层的协议分析方法,识别由“SCPS-TP、CFDP”组成的一组数据,在最差的情况下,需要执行3×3次协议分析。而应用文中算法,通过分析协议结构和出现概率,首先计算出多层协议分析组合的优先级。
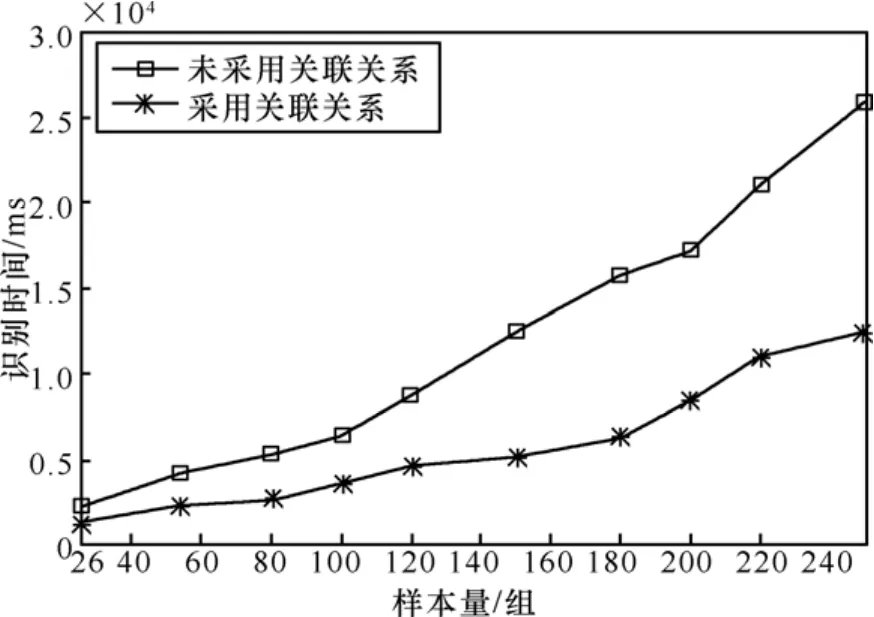
图6 空间数据多层协议识别比较
从表 2可知,应用本文方法,最优仅需 1次、最差仅需7次协议分析,复杂度要低于传统的9次分析。首先应用文中方法按照表2的优先级顺序进行了多次实验,并在随机的协议组合顺序下进行了识别实验,二者的结果比较如图6所示。
可以看出提出算法根据相邻层协议出现概率进行识别,可将多层空间协议识别效率提高2.5倍。
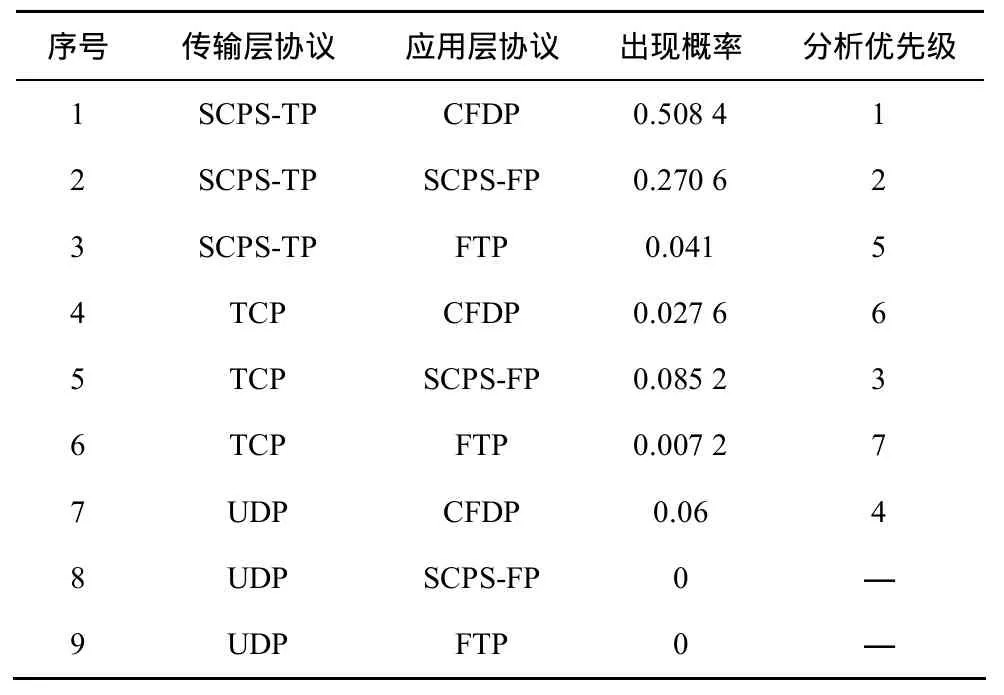
表2 协议组合优先级
对于多层协议,设传输层协议为LT、应用层协议为LA,概率系数为β,提出算法的时间复杂度
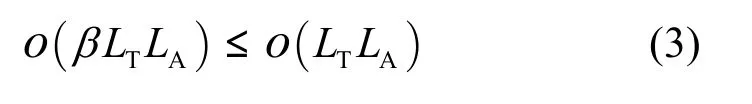
6 结束语
空间协议分析是一个倍受关注的研究领域,本文在对SCPS协议族进行研究基础上,提出了一种改进的空间协议算法。提出算法在空间数据预处理、数据查找跳进、多层协议识别方法进行了改进,在一定程度上解决了特征位难于区分和查找问题,提高了协议识别效率。
[1] 李雄伟. 网络对抗系统及其关键技术研究[D]. 北京: 北京邮电大学,2003.LI X W. Research on Network Operation System and Key Technologies[D]. Beijing: Beijing University of Posts and Telecommunications,2003.
[2] BOYER R S, MOORE J S. A fast string searching algorithm[J]. Communications ACM, 1977, 20(10):762-772.
[3] CCSDS 311.0-M-1 Reference Architecture for Space Data Systems[S].Washington, DC, USA, 2008.
[4] CCSDS 130.0-G-2 Overview of Space Communications Protocols,Report Concerning Space Data System Standards[S]. Washington, DC,USA, 2007.
[5] CCSDS 211.0-B-4 Proximity-1 Space Link Protocol—Data Link Layer, Recommendation for Space Data System Standards[S]. Washington, DC, USA, 2006.
[6] CCSDS 713.0-B-1. Space Communications Protocol Specification(SCPS)-Network Protocol (SCPS-NP)[S]. Washington, DC, USA,1999.
[7] CCSDS 714. O-B-2. Space Communications Protocol Specification(SCPS)-Transport Protocol (SCPS-TP)[S]. Washington, DC, USA,2006.
[8] CCSDS 717.0-B-1 Space Communications Protocol Specification(SCPS)-File Protocol (SCPS-FP)[S]. Newport Beach, California, USA,1999.
[9] 许枫, 尤政. CCSDS空间通信协议及其与互联网通信协议的比较[J] . 中国航天, 2007, (5): 26 - 29.XU F, YOU Z. CCSDS space communications protocol and its comparison with Internet protocols[J] . Aerospace China, 2007,(5): 26-29.
[10] HOOKE J .Evolutionary Paths to Internationally-standardized Space Internetworking[R] . AIAA , 2008. 2 - 9.
[11] 谭建龙. 串匹配算法及其在网络内容分析中的应用[D]. 北京:中国科学院研究生院, 2003.TAN J L. String Matching Algorithm and Application of Network Content Analysis[D]. Beijing: Graduate School of Chinese Academy of Sciences, 2003.
[12] RICHARD O D, PETER E H, DAVID G S. Pattern Classification[M].America: Library of Congress, 2000.
[13] SUNDAY D M. A very fast substring search algorithm[J]. Communications ACM , 1990, 33(8): 132-142.
[14] KAGHAZIAN L, MCLEOD D, SADRI R. Scalable complex pattern search in sequential data[A]. Proceedings of the 17thACM Conference on Information and Knowledge Management[C]. Napa valley California, 2008. 1467-1468.
[15] 范洪博, 姚念民. 一种高速精确单模式串匹配算法[J]. 计算机研究与发展, 2009, 46(8): 1341-1348.FAN H B, YAO X M. A fast and exact single pattern matching algorithm[J]. Journal of Computer Research and Development, 2009, 46(8):1341-1348.
[16] CROCHEMORE M, ALLAUZEN C, RAFFINOT M. Factor oracle:a new structure for pattern matching[A]. Proceedings of the 26th Conference on Current Trends in Theory and Practice of Informatics[C].London, UK, 1999.291-306.
[17] 刘萍, 刘燕兵, 郭莉等. 串匹配算法中模式串与文本之间关系的研究[J]. 软件学报, 2010, 21(7):1503-1514.LIU P, LIU Y B, GUO L,et al. Research on relationship between patterns and text in string matching algorithms[J]. Journal of Software,2010, 21(7):1503-1514.
[18] 范慧萍. 基于正则表达式的协议识别研究与实现[D]. 长沙:国防科学技术大学研究生院, 2007.FAN H P. Research and Realization of High Speed Protocol Identification Based on Regular Expression[D]. Changsha: Graduate School of National University of Defense Technology, 2007.
[19] 陈曙晖, 苏金树, 范慧萍等.一种基于深度报文检测的 FSM 状态表压缩技术[J]. 计算机研究与发展, 2008, 45(8): 1299-1306.CHEN S H, SU J S, FAN H P,et al.An FSM state table compressing method based on deep packet inspection[J]. Journal of Computer Research and Development, 2008, 45(8): 1299-1306.
[20] 杨毅夫, 刘燕兵, 刘萍等. 正则表达式的 DFA 压缩算法[J]. 通信学报, 2009, 30(10A): 36-41.YANG Y F, LIU Y B, LIU P,et al. Effective algorithm of compressing regular expressions' DFA[J]. Journal on Communications, 2009,30(10A): 36-41.
[21] FANG Y, CHEN Z F, DIAO Y L,et al, Fast and memory-efficient regular expression matching for deep packet inspection[A]. ANCS’06:Proceedings of the 2006 ACM/IEEE Symposium on Architecture for Networking and Communications Systems[C]. New York, NY, USA,2006.93-102.
