基于深度分层图的虚拟视点合成方法的研究
2012-08-01程浩
程 浩
(武汉工程大学电气信息学院,湖北武汉 430205)
随着视频数据采集和显示技术的不断发展,三维视频已被引起关注,3D电视和自由视点视频是典型的三维视频应用。在自由视点视频应用中,用户可自由的选择角度,不受限制的享受立体盛宴。目前的商业网络传播系统还不能满足多视点视频信号的处理和传输,这是因为多视点视频有海量的数据要进行处理。为解决这一问题,研究人员提出一些不同的3D表示方法和视点合成方法。已经有三类不同的三维立体视频格式,一类是由多路是视频直接组成,称为多视点视频[1]。这种格式表示的好处是可完整的现象三维场景,观众也能更好选择视点和视角,这个格式可利用基于图像的描绘技术(IBR)[2]在终端虚拟合成视点,但这种格式最大的问题是要采集大量的视频数据。IBR技术是需要大量视点视频数据支持的。为减少数量,出现了单视点视频与其深度的三维立体视频格式,它由一个视点和该视点的深度图序列组成,在终端可以利用基于深度图的描绘(DIBR)虚拟合成视点,但其主要问题就是不能解决因遮挡问题到导致的空洞问题。最终出现了多视点视频+深度视频(MVD)的三维立体视频格式[3],它可以利用DIBR技术合成虚拟视点。
基于深度图像描绘是一种基于图像的描绘方法。基于深度图像描绘系统流程如图1所示。该系统由深度图像信息预处理;3D图像变换;空洞填充组成。其中,根据深度图像信息预处理的效果,空洞填充可有可无。

图1 DIBR算法流程图
相比IBR技术,DIBR技术改进了因遮挡问题而导致的空洞、重影、伪边缘、像素重叠等问题,但是利用DIBR技术合成出的视点图像中在物体边缘区域仍然会有伪边缘、空洞问题。在多视点视频系统中,视频数据编码后传输,在终端解码,合成视点。由于视频编码后,会丢失大量的数据,特别是深度图像序列[4]。在终端合成虚拟视点时,由于利用了压缩过的视频数据,虚拟合成出的视点的质量必将受到影响。为解决这些DIBR存在的问题,文献[4]提出一种面向虚拟视点绘制的深度压缩算法。在前端编码时,对下采样深度图进行编码,在解码端,对深度图进行上采样处理,并采用双边滤波器优化深度图。这种压缩算法降低了传输码率,但没考虑解决空洞等问题。鞠芹等人先将多幅参考图像分别合成虚拟视点位置的多幅目标图像,再将这些虚拟视点目标图像融合为含有少量空洞的目标图像,然后采用逆映射的方法填充空洞,从而提高虚拟视点图像的质量[5],较好的解决了DIBR技术空洞问题,但没有考虑到压缩对虚拟视点合成的影响。刘占伟等人对深度图像进行边缘滤波处理,对参考图像进行规正处理,采用遮挡兼容算法处理遮问题,融合目标图像得到新视点图像,最后利用插值法处理较小的空洞问题[6]。文献[7]利用空间线投影方法和视点间双向插值算法解决误投影问题。文献[8]对深度图不做预处理,采用两个视点合成虚拟视点,其中一个做主视点,另一个为辅助视点,利用辅助视点进行裂纹,空洞修正。Nurulfajar等人根据视差图的距离将深度图进行分层,利用分层的深度图和插值算法解决了空洞,伪边缘等问题[9]。
针对目前较少考虑深度图压缩后对虚拟视点合成的影响问题,提出一种基于深度分层的虚拟合成算法。该方法先采用均值漂移聚类算法将深度图进行分割处理,使得深度图中的对象块有同一深度值,然后对视频信息以及处理后的深度信息进行3D图像转换,再在对图像中的空洞填充处理,最后完成虚拟视点合成。
1 基于深度图分层的虚拟视点合成算法
1.1 深度图预测处理
预处理深度图主要有2个部分:一个是平滑处理深度图,一个是选取零视差平面(ZPS)距离Zc。一般情况下Zc是由深度图中最近和最远的深度点决定的:
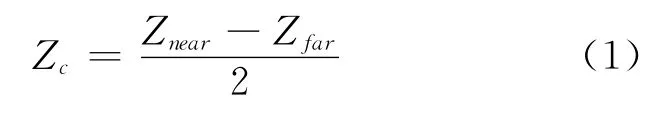
在8位的深度图中Znear,Zfar=0。将深度图中的值归一化后,深度值就在[-0.5,0.5]之间。
采用高斯滤波器g(x,σ)对深度图进行平滑处理:
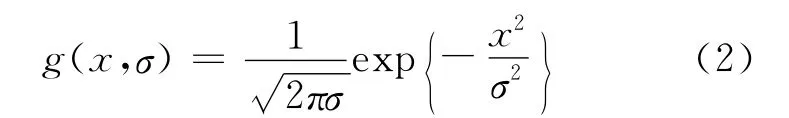
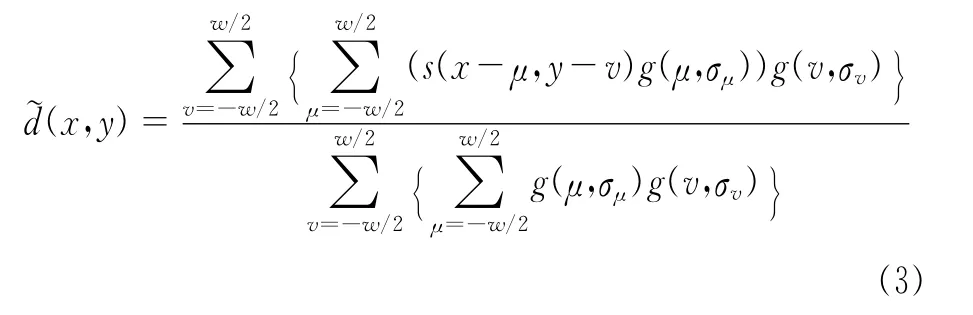
对估计出的深度图进行Mean Shift算法分割处理,方法如下:
一幅深度图可以表示成一个二维网格点上p维向量,每一个网格点代表一个象素,P=1表示这是一个灰度图,表示彩色图,p=3表示一个多谱图,p>3网格点的坐标表示图像的空间信息.统一考虑图像的空间信息和色彩(或灰度等)信息,组成一个p+2维的向量x=(xs,xr),其中xs表示网格点的坐标,xr表示该网格点上p维向量特征。
用核函数Khs,hr来估计x的分布,Khs,hr具有如下形式,
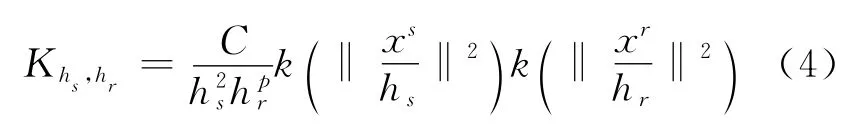
其中hs,hr核算,控制着平滑的解析度,C是一个归一化常数。
设xi和zi,(i=1,2…n)分别表示原始和分割后的图像。用MeanShift算法进行图像分割的具体步骤如下:
(1)对深度图中的所有像素点xi,分别计算每个像素点的Mh(xi),根据Mh(xi)值移动窗口,计算窗口中点的Mh(xi)值,重复这个过程直到Mh(xi)<T(T是收敛门限),不移动窗口后,将该点的深度值X*赋给初始点xi=X*;
(2)运用MeanShift算法的同时,计算yi,j+1,直到收敛.记收敛后的值为yi,c
(3)采用Gausss核函数进行MeanShift计算;
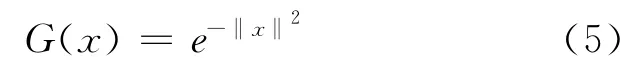
(4)重复2和3两个步骤,直到所有深度点收敛;
(5)赋值zi=(,),合并同一对象区域,将图像区域分类。
1.2 3D图像转换
3D图像转换的目的是将世界坐标系中的点变换到帧图像画面中,假设在齐坐标系下,M=(X,Y,Z,1)T为世界坐标系中的点,其图像中对应点为 m=(u,v,1)T,关系为:

其中P为摄像机投影矩阵,它是由摄像机外部矩阵和内部矩阵组成的,s为收缩因子,

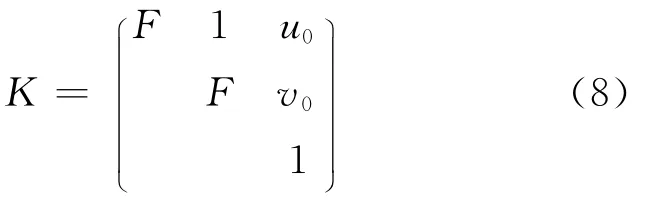
R是旋转矩阵,t是平移矩阵,F为摄像机的焦距,(u0,V0)为帧图像中心点坐标。当知道点m=(u,v,1)T和该点的深度D,则可以根据公式(6),得到下面的线性关系:
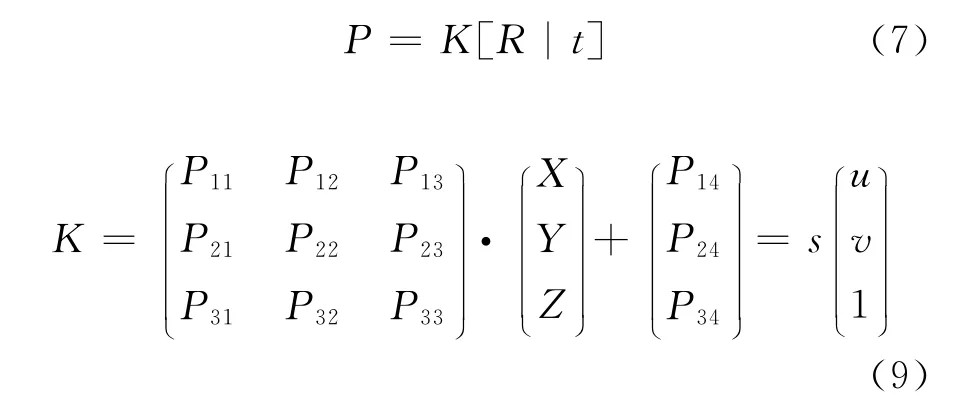
式中Pij是投影矩阵的在第i行j列的元素。从上式不难发现,在已知图像坐标和深度值得情况下,可以求出空间中的坐标M。在得到世界坐标系中的点后,再利用公式(9),将该点重新变换得到虚拟帧图像中对应的点,这个过程也就是3D变换。
1.3 填充空洞
在虚拟视点中,如果有些区域被遮挡,而真实帧图像中对应区域的点没有绘制这些遮挡区域的点,这些被遮挡的区域就会产生空洞,也可以称为“遮挡区域”。为使虚拟出的帧图像不影响观看,这些虚拟帧图像中的空洞点需要其相邻的点插值填充。在摄像机是水平模型时,通常会用空洞点左边或右边的点来填充。
2 实验结果与分析
为验证所提出算法的性能,采用日本名古屋大学提供的的dog测试序列进行仿真实验。在试验中,选择dog测试序列的视点0和做为虚拟视点,视点2为辅助视点,视点1为虚拟视点。计算机硬件条件为:CPU为酷睿i5,主频为2.30GHz,内存为4G,软件编译环境为vs2005。实验结果如图2和表1所示.

表1 dog虚拟图像PSNR比较结果

图2 dog序列的第1帧虚拟合成图像
将虚拟合成出来的图像进行噪声峰值性噪比评价,实验结果如表1所示。dog测试序列的第一个视点的虚拟合成图的质量估计结果表明:利用本文算法产生的深度图像合成出的虚拟图像的PSNR值比较理想,利用压缩后的视频和深度图序列图进行虚拟合成图像的平均PSNR值为36dB左右,而未经过聚类处理而合成虚拟图像的平均PSNR值是29dB左右。这证明该算法有较好的效果。在虚拟合成结果图2中,明显发现,没经过类聚的深度合成出的虚拟帧图有重影和空洞。
3 结 语
基于深度图虚拟视点合成技术是MVD三维视频格式在终端显示的关键。在传统的的DIBR算法中,由于遮挡问题,使得重绘的虚拟图在物体边缘有空洞和重影。为此,上述提出基于深度图分层的虚拟视点合成算法。通过实验证明,该方法很好的虚拟合成出视点,减少了物体边缘的空洞、重影问题。
1 杨海涛,常义林,霍俊彦等.应用于多视点视频编码的基于深度特征的图像区域分割与区域视差估计[J].光学学报,2008,28(6):1073-1078.
2E.Martinian,A.Behrens,J.Xin,A.Vetro,etal,“ExtensionsofH.264/AVCformultiviewvideocompression,”inProc.IEEEInt.Conf.ImageProcess.,Atlanta,GA,2006,pp.2981–2984
3H.-Y.Shum,S.-C.Chan,S.B.Kang,Image-Based Rendering.Berlin,Germany:Springer-Verlag,2007.
4 张秋闻,安平,张艳等.FTV系统中面向虚拟视点合成的深度编码[J].应用科学学报,2011,29(3):298-307
5 鞠芹,安平,张倩等.高质量的虚拟视点图像的绘制方法[J].数字视频,2009.33(9):21-25.
6 刘占伟,安平,刘苏醒等.基于DIBR和图像融合的任意视点绘制[J].中国图象图形学报,2007,12(10):1695-1700.
7 陈思利,李鹏程.一种基于DIBR的虚拟视点合成算法[J].成都电子机械高等专科学校学报,2010,13(1):14-19.
8XiaohuiYang,JuLiu,JiandeSun1,etal.DIBRBased ViewSynthesisforFree-ViewpointTelevision[C].3DTV Conference,2011,1-4
9Manap,N.ASoraghan,J.JNovelViewSynthesisBasedon DepthMapLayersRepresentationC〗.3DTVConference,2011,1-4.
