双泊松回归模型在汽车保险索赔次数中的应用*
2012-07-26郭念国
徐 昕,郭念国
(1.首都经济贸易大学金融学院,北京100070;2.河南工业大学理学院,河南郑州450001)
1 引言
在拟合汽车保险索赔次数的模型中,泊松分布模型是拟合索赔次数的最简单且常用的模型,具有均值与方差相等的特性。而索赔次数模型往往具有方差大于均值的性质,此时如果继续使用泊松分布模型会低估参数的标准误差,高估其显著性水平,导致多余的解释变量保留在预测模型中,最终导致不合理的保费。
对于此类问题,研究人员通常利用各种不同的混合泊松模型来预测索赔次数。Ruohonen[1]提出结构函数为三参数伽玛函数的泊松分布,同时用实际损失数据与两参数结构函数泊松模型即负二项模型进行了比较,得到了比较满意的结果。Panjer[2]运用广义poisson-pascal分布(即Hofmann分布,含三个参数)来建立汽车索赔次数模型,拟合效果也比较理想。Norison Ismail和 Aziz Jemain[3]讨论了负二项回归模型和广义泊松回归模型的参数估计及其在索赔频率预测中的应用,而Denuit Michel[4]等人应用负二项回归、泊松-逆高斯回归和泊松-对数正态回归对汽车保险的索赔频率进行了实证研究。国内关于索赔频率模型的研究主要有孟生旺和袁卫[5]用混合Poisson模型研究了非同质风险的索赔分布。高洪忠、任燕燕[6]研究了一类更广泛的分布,即GPSJ类分布,这类分布描述了一次风险事件多种索赔结果的情况。毛泽春和刘锦蕚[7]分析了免赔额及NCD赔付条件对索赔次数分布的影响,通过比较风险事件与索赔事件的差异引出了一类同质集合保单索赔次数的分布(Poisson-Gamma)。毛泽春和刘锦蕚[8]引出了一类指数类混合型索赔次数的分布并研究了其散度(dispersion)的性质,同时给出了拟合类分布的矩估计方法。徐昕、袁卫、孟生旺[9]将两参数负二项回归模型推广到三参数情况,并利用新模型对Yip和Yau[10]中的汽车保险损失数据进行了拟合,得到了较好的效果,提出了解决过离散问题的一种新办法。
学者们的研究大多数集中在混合泊松分布模型上,而双泊松分布模型也是一类离散型分布模型,具有方差大于均值的特性,但关于利用双泊松回归模型预测汽车保险索赔次数的文献并不多见。本文将在下面内容中详细介绍双泊松回归模型的性质及参数估计,并且利用该模型来拟合一组实际的汽车保险索赔数据,并将其结果与泊松回归模型的拟合进行比较分析。
2 泊松回归模型性质及参数估计
为便于讨论,假设共有p个分类变量,将所有保单分为n个风险类别,其中第i个风险类别在p个分类变量上的取值用xi=(xi1,xip)T表示,T表示转置。用wi表示第i个类别包含的风险单位数(如汽车保险中的车年数)。
令Yi表示第i个风险类别的索赔次数随机变量,i=1,2…,n。如果Yi服从泊松分布,则其概率函数为:

泊松分布的均值与方差相等,即E(Yi)=Var(Yi)=λi。若令 λi=wiexp(xTiβ),即可得到泊松回归模型,其中β是p×1阶的参数向量。容易求得泊松回归模型的对数似然函数为:
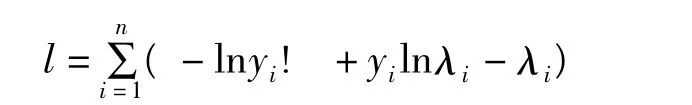
回归参数β的极大似然估计可以通过下述似然方程组求得:

为了求得参数估计的标准误差,首先需要计算Hessian矩阵,其中的元素是关于对数似然函数的二阶偏导数,即

因此信息矩阵的元素为
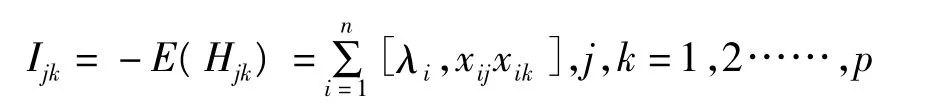
对信息矩阵对角线上的元素先求导数,然后再开方,即可得到参数估计的标准误差。
3 双泊松回归模型的性质及参数估计
虽然无法确定双泊松分布是否也是一种混合泊松分布,但由于其具有方差大于均值的特征,因此也可以用于过离散数据的处理。双泊松分布的概率函数可以表示为:

此处对双泊松分布形式不同于Yip和Yau文献中的双泊松回归模型。这样做的目的是使其均值正好等于λi,与其他分布保持一致。如果采用其他的参数形式,譬如,如果参数的形式使得双泊松分布的均值正好为λi/θ(参见Yip和Yau),则截距项的估计值将发生变化,但索赔频率的预测值不会受到影响。
从上述方差和均值的关系可以看出,当θ在区间(0,1)之间变化时,θ越小,双泊松分布的过离散程度越严重,因此我们将g=q定义为双泊松分布的离散参数。当θ→1时,双泊松分布退化为泊松分布。容易求得双泊松回归的对数似然函数为:

对上式求偏导,可以得到模型的似然方程组为:

双泊松回归的Hessian矩阵H的元素也很容易求得:

因此双泊松回归的信息矩阵的元素为

4 模型检验
4.1 过离散检验
对于索赔数据是否具有过离散的特征,通常利用两种方法来判断。一是在普通最小二乘回归模型的基础上建立的统计量(Cameron 和 Trivedi[11]),满足下述条件

其中的λi=exp(xiβ),ei是随机误差项。如果系数α的t统计量显著,说明存在过离散特征。
另外一种方法是拉格朗日乘法(Lagrange Multiplier)检验(Greene[12]提出的)。LM 统计量可以简单表示为

其中的 λ =(λ1,…,λn)',λi=exp(xiβ),e=y -λ,y=(y1,…,yn)。在零假设为泊松分布的条件下,LM统计量服从自由度为1的x2分布。
4.2 拟合优度检验
对模型拟合优度进行评价可以使用Akaike Information Criteria(AIC)统计量和Bayesian Schwartz Criteria(BIC)统计量。AIC 统计量定义为(Akaike[13]):

其中l表示对数似然值,p为参数的个数。AIC的值越小,表明模型的拟合越好。
BIC 统计量定义为(Schwartz[14]):

其中的l也表示对数似然值,p为模型的参数个数,n为观测值的个数,BIC的值越小,模型拟合越好。
5 实证分析
5.1 数据的描述
本节选用一组来自SAS Enterprise Miner数据库中的汽车保险数据。原始数据中有10303个观测值,其中大约有6%的缺失,数据包含索赔概况、驾驶记录、保单信息、被保险人个人信息。索赔概况记录了被保险人的索赔频数、索赔额、索赔时间等信息;驾驶记录包括驾驶人的分数、过去7年中是否被吊销驾驶执照;保单信息有被保险车辆的行驶区域、行驶时间、汽车价格、颜色、用途等;被保险人的个人信息有年龄、性别、教育程度、工作类型、婚姻状况、年收入等。选取与Yip和Yau相同的费率因子(见表1),其中收入为连续变量,其余为属性变量,从10303个客户中随机抽取了4412个有效记录。

表1 费率因子
5.2 过离散检验
首先依据第一种方法利用统计软件SAS的回归模块(即PROC REG)得到结果见下表2,很明显预测变量的P值显著。
表2 预测值的估计结果

表2 预测值的估计结果
?
同样,利用拉格朗日乘法(Lagrange Multiplier),利用SAS中IML模块求得LM值为128.47816,并且显著。
从两种检验方法可以判定,损失数据存在过离散问题。
5.3 拟合结果
从下表3中的回归模型拟合结果来看,双泊松回归模型和泊松回归模型的参数估计值差别不大,显著性水平因子也相同。但由前面判断,此数据存在过离散特性,泊松回归模型费率因子参数估计标准误差明显小于双泊松回归模型。从整体上看,无论是AIC还是BIC,对于该组索赔数据而言,双泊松回归模型的拟合效果要明显优于普通泊松回归模型。

表3 回归模型拟合结果
6 结语
双泊松分布模型虽然不能归为混合泊松模型,但双泊松分布模型同样具有方差大于均值特性,从本文中的实证分析也可以看出,对于处理具有过离散特征的损失数据,双泊松分布可以看做为一种解决办法,也同样可以达到改善拟合结果的效果。
[1] Ruohonen,M..On amodel for claim number process[J].Astin Bulletin,1987(18):57-68.
[2]Panjer,H.H.,Recursive Evaluation of a Family of Compound Distributions[J].Astin Bulletin,1981(12):22 - 26.
[3] Noriszura,I.,&Abdul,A.J..Handling Overdispersion with Negative Binomial and Generalized Poisson Regression Models,2007 CAS Ratemaking Call Papers,2007:103 - 158.www.casact.org/pubs/forum/07wforum/07w109.pdf
[4] Denuit,M.,Marechal,=.,Pitrebois,S.,&Walhin J.F..Actuarial Modeling of Claim Counts:Risk Classification,Credibility and Bonus- Mallus Scales[M].NewYork:Wilely,2007.
[5] 孟生旺,袁卫.汽车保险的精算模型及其应用[J].数理统计与管理,2001,20(3):60 -65.
[6] 高洪忠,任燕燕.二维GPSJ类分布及其在保险中的应用[J].中国管理科学,2004,12(4):30 -34.
[7] 毛泽春,刘锦蕚.免赔额和NCD赔付条件下保险索赔次数的分布[J].中国管理科学,2005,13(5):1 -5.
[8] 毛泽春,刘锦萼.指数类混合型索赔次数的分布及其应用[J].应用概率统计,2008,24(1):1 -11.
[9] 徐昕,袁卫,孟生旺.负二项回归模型的推广及其在分类费率厘定中的应用[J].数理统计与管理,2010,29(4):656 -661.
[10] Yip,K.C.H.,Yau,K.K.W.On Modeling Claim Frequency Data in General Insurance with Extra Zeros[J].Insurance:Mathematics and Economics.2005 ,Vol 36,153-163.
[11] Cameron,A.C.and Trivedi,P.K.Count Data Models for Financial Data[J].Handbook of Statistics,Statistical Methods in Finance,1996,Vol 14,363-392,Amsterdam,North-Holland.
[12] Greene,W.Econometric Analysis(6th edition)[M].Prentice Hall:Englewood Cliffs.
[13] H.Akaike.Information Theory and an Extension of the Maximum Likelihood Principle[J].Proceedings of the 2nd International Symposium on Information Theory,Akademiai Kiade,Budapest,1973,267 -281.
[14] G.Schwartz.Estimating the Dimension ofa Model[J].Annals of Statistics,1978,Vol 6,461 -464.
[15] SAS Institute Inc.Solving business problems using SA Senter prise miners of eware[J].SAS Institute White Paper.1998,(Cary,NC:SAS Institute Inc.).
