词位标注汉语分词中特征模板定量研究
2012-07-25于江德王希杰樊孝忠
于江德,王希杰,樊孝忠
(1.安阳师范学院 计算机与信息工程学院,河南 安阳455002;2.北京理工大学 计算机科学技术学院,北京100081)
0 引 言
在中文信息处理领域,汉语分词是一项基础性研究课题。它不仅是词性标注、命名实体识别等其他词法分析的基础,也是进一步句法和语义分析、文本理解等深层中文信息处理任务的基础,更是信息检索、数据挖掘、机器翻译和智能信息系统等应用的关键环节[1-5]。近年来,汉语自动分词技术取得了长足的发展[6-9]。其中,基于字的词位标注汉语分词技术得到了广泛关注。在国际计算语言学会下属的汉语处理特别兴趣研究小组 (special interest group on Chinese language processing,SIGHAN)举行的一系列评测中性能领先的分词系统几乎都采用了类似的思想[10-13]。综合分析这些文献,都是将汉语分词的本质看作是对一个字串的序列标注问题,借助于统计语言模型实现。统计语言建模中设定特征模板至关重要,特征模板集将直接影响模型训练的时间、训练后模型的大小、训练得到的模型性能等。为了在词位标注汉语分词中更加准确地设定特征模板,本文采用B、M、E、S四词位标注集,使用条件随机场(conditional random fields,CRFs)模型从多个角度定量分析了词位标注汉语分词中的特征模板。文中首先简要阐述了词位标注汉语分词的基本思想,然后对词位标注建模过程中的特征模板作用进行了详细解析,最后,使用CRF++0.53工具包实现了字串序列的词位标注,并在国际汉语分词评测Bakeoff2005的PKU和MSRA两种语料上进行了多组实验,通过对实验数据的分析,从 “量”上揭示出词位标注汉语分词中设定特征模板需要遵循的多组规律,为特征模板对汉语分词及其他词法分析任务的支持作用提供了一个 “量”上的依据。
1 词位标注汉语分词的基本思想
词位标注汉语分词方法实际上是由字构词的方法。汉语中的每个词语是由一个字或多个字构成的,一个词语中的每个汉字又都有一个固定的构词位置,即该字在词中的位置,简称词位。本文中我们规定字只有4种词位:B表示词首位置、M表示词中位置、E表示词尾位置和S表示单字成词。而且同一个汉字在不同的词语中可以有不同的构词位置,例如,在 “天”、“天空”、“异想天开”、“今天”这4个词语中都有汉字 “天”,其词位依次是:单字成词S、词首B、词中M、词尾E。词位标注汉语分词技术就是把分词过程转化为一个字串序列的词位标注问题。要对一个字串进行词语切分,只要对该字串中每个字标注出词位就可以了。
2 词位标注汉语分词中的特征模板
2.1 条件随机场对词位标注建模
2.1.1 条件随机场简介
条件随机场是一种判定性模型 (discriminative model),是一种基于无向图的条件概率模型,由Lafferty等在2001年提出[14]。CRFs能够融合复杂的、重叠的特征进行训练和推理,通过定义给定观察序列条件下标记序列出现的条件概率P(S|C)来预测标注序列。用于对序列数据标注建模的条件随机场是一个简单的链状图 (如图1所示),称为线链CRFs。
设C= {C1,C2,……,CT}表示可被观察的有待标注词位的字序列。S= {s1,s2,……,sT}表示被预测的词位序列 (例如,词首B、词中M等)。在给定一个可被观察的字串序列情况下,权重参数为Λ= {λ1,λ2,…,λK}的CRFs,其词位序列的条件概率为
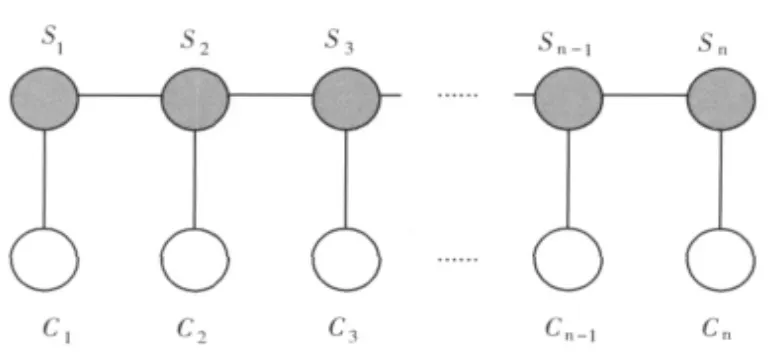
图1 线链CRFs的图形结构

式中:ZC——归一化因子,公式如下
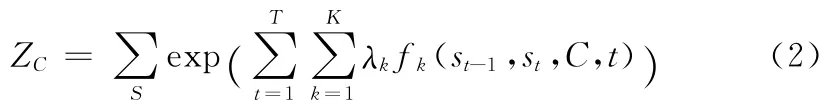
式中:fk(st-1,st,C,t)—— 一个任意的特征函数,通常是一个二值表征函数,用于表达上下文可能的语言特征。λk—— 一个需要从训练数据中学习的参数,是相应的特征函数fk(st-1,st,C,t)的 权 重。 特 征 函 数fk(st-1,st,C,t)能够整合上下文的任何特征,包括给定的字序列C在时刻当前字位置的所有特征,以及词位转移st-1→st特征等。
给定一个条件随机场模型,在给定输入数据字序列C的情况下,待预测的该字串序列最可能的词位标注序列可以由下式通过类似于隐马尔科夫模型中的韦特比算法动态规划求出

2.1.2 CRFs对词位标注问题建模
建立CRFs模型的一个关键问题是如何针对具体的任务选择有效的特征集,用筛选出的特征集来表示复杂的语言现象,其实质是模型对上下文特征的刻画,这些特征是通过特征模板从特征空间中扩展而来的。
通常情况下,上下文的选取是基于当前位置前后一定范围进行的,这个固定的范围称为 “窗口”。由于语言特征要从该上下文 “窗口”中获取,所以将该 “窗口”称为特征空间。图2示意了词位标注汉语分词中可能的特征空间。对基于字的词位标注汉语分词这一具体任务而言,上下文中可供选择的特征很少,主要需要考虑的是当前字本身及其上下文中的字所构成的字特征[6]。黄昌宁等提出了构造字特征时 “使用前后各两个字是比较理想的”的结论[6]。此时的特征空间就是一个 “5字窗口”,该窗口下字特征是指当前字本身、以及当前字前后各两个字所组成的特征。如果选取的字特征是指当前字本身、以及当前字前后各一个字所组成的特征,此时的特征空间就是一个 “3字窗口”, “3字窗口”是文献 [6,11]中配合6词位标注集(B、B2、B3、M、E、S)选取的特征空间。
2.2 特征模板及其作用
习惯上,特征模板可以看作是对一组上下文特征按照共同的属性进行的抽象。在CRFs的训练学习中,上下文的每个特征会对应了一组特征函数,这些特征函数对条件随机场模型的训练和学习至关重要。而每个特征又都是通过特征模板扩展而来,所以,特征模板集的设定就显得尤为重要。

图2 可能的特征空间
2.3 词位标注汉语分词中常用特征模板
本文使用条件随机场工具包进行词位标注的时候,设定的特征模板有两大类:①Unigram (一元)特征模板;②Bigram (二元)特征模板。这里划分 “一元”、 “二元”特征所依据的是特征函数中包含的词位标记个数,而不是依据特征中的字个数来划分,这种划分的方法和CRF++工具包中是一致的。在图2给出的可能特征空间下,根据特征模板中出现的字与当前字的距离属性可以将常见的字特征设定为13类,即将字特征设定为13个特征模板,这些模板属于一元特征模板。表1详细列出了这些特征模板的类型、特征模板的标识及其表征的意义等。从表中可以看到,仅仅有一个特征模板:T-1T0属于二元特征模板,该模板用于表征上下文中相邻两个字所对应的词位之间的转移特征st-1→st。在模型的训练中该模板扩展出的特征数是有限的,从实验数据中容易知道:四词位标注汉语分词中此类特征模板可以扩展出16个 (词位转移)特征。

表1 特征模板
为了对词位标注汉语分词中的特征模板有个 “量”的认识,我们从多个角度进行定量分析并设计了相关实验。表2列出了实验中用到的几组特征模板集。其中,TMPT-10是在相关工作中最常用的一组特征模板,TMPT-10’是本文作者在前期研究中用到的一组特征模板[15],TMPT-6是文献 [6,9,11]中使用的特征模板,它是配合6词位标注集使用的。后缀 “Single”和 “Double”分别表示相应特征模板集中的单字或双字特征模板。例如,T10-Single是指TMPT-10中单字特征模板。另外所有的特征模板集都可以包括词位转移特征模板T-1T0,由于在特征模板的表示文件中对应的特征模板是B,所以,相应的特征模板集名称用 “+B”表示。

表2 特征模板集
3 特征模板定量分析实验
3.1 实验环境、实验数据集及性能评估
本文所有实验是在实验室DELL Optiplex 760台式机上进行,软硬件环境主要参数为:CPU:Intel(R)Core(TM)2Quad CPU Q8200 2.33GHZ;内存:4GB;操作系统:Microsoft Windows XP Professional 2002Service Pack 3。
本文实验所使用的训练语料和测试语料是由国际计算语言学会举办的第二届国际中文分词评测Bakeoff2005所提供的简体中文语料,这些语料分别是由北京大学 (PKU)和微软亚洲研究院 (MSRA)提供的。
在对汉语分词性能进行评估时,采用了同类评测中常用的5个评测指标:准确率 (P)、召回率 (R)、综合指标F值(F)、未登录词召回率 (OOVRR)、词表词召回率 (IVRR)。
3.2 实验及其结果分析
3.2.1 实验设计
我们设计了3组实验,分别从不同的角度对词位标注汉语分词中特征模板进行定量研究。①模型训练过程反映出的 “量”属性。本组实验关注的是不同特征模板对模型训练的影响,主要从不同模板扩展出的特征数、模型训练时间、迭代次数、训练出的模型大小等几个 “量”化指标进行考察。②不同特征模板对分词性能的贡献情况。本组实验关注的是使用不同特征模板集训练出的模型的分词性能情况。③词位转移特征模板:T-1T0的影响。
3.2.2 特征模板对模型训练的影响
我们首先分别使用表2中的9组特征模板集 (都不包含词位转移特征模板),在PKU和MSRA两个语料集上进行了汉语分词的训练,表3给出了训练过程记录数据,其中f参数值是训练过程中特征出现次数所取的阈值,因为本文所用工具包在训练语料较大、特征数较多时不能完成训练致使部分数据为空。
综合分析表3中的数据可以得出如下结论:①同等条件下,训练出的模型大小与扩展出的特征数成正比。②模型训练的时间长短和扩展出的特征数并没有必然联系。例如,在MSRA训练语料上,6号特征模板集扩展出61 884个特征,训练时长为2337.98s。而7号特征模板集扩展出的特征数为6 231 012个,训练时长仅为1778.14s。③不同的单字特征模板在同一语料中扩展出的特征数基本相同。例如,第4、6、9号特征模板集分别由5个 (C-2,C-1,C0,C1,C2)、3个 (C-1,C0,C1)和1个 (C0)单字特征模板构成,不论在MSRA训练语料还是PKU训练语料上,由4号、6号特征模板集扩展出的特征数是由9号特征模板集扩展出的特征数的5倍、3倍。这个结论也在其他实验中得到了进一步验证。④双字特征模板扩展出的特征数要比单字特征模板扩展出的特征数多得多。
3.2.3 特征模板对分词性能的影响
第二组实验采用第一组实验训练出的模型对测试语料进行分词,该组实验关注的是使用不同特征模板集训练出的模型的分词性能情况,采用汉语分词性能评估的5个评测指标进行考察。并从更深的层次分析了不同特征模板对分词性能的贡献情况。表4给出了这9组特征模板集训练出的模型在PKU和MSRA测试语料上的分词性能。
综合分析表4中的数据可以得出如下结论:①TMPT-10、 TMPT-10 ’、 TMPT-6、 T10-Double、 T6-Double、TMPT-5这些特征模板集分词性能差别较小,综合指标F值的差别在2个百分点以内。这些特征模板集都包含双字以上特征模板。②单字特征模板对分词性能的贡献要比双字特征模板小很多。例如,在PKU语料上,从6号特征模板集到4号特征模板集,增加了两个单字特征模板:C-2,C2,综合指标F值从78.1%增加到了82.0%。而从6号特征模板集到8号特征模板集,增加了两个双字特征模板:C-1C0,C0C1,F值从78.1%增加到了90.9%。在 MSRA语料上,也有同样的规律。③特征空间从 “3字窗口”扩大到 “5字窗口”对分词性能的提高也很有限,综合指标F值的变化在1个百分点左右。

表3 PKU和MSRA语料上的训练过程记录数据

表4 不同特征模板集的分词结果
3.2.4 词位转移特征模板的影响
从2.3节对特征模板的分析可知,所有用于训练的特征模板集都可以包括词位转移特征模板T-1T0,该模板是唯一的二元特征模板。该组实验选取了1~7号特征模板集进行了包含和不包含词位转移特征模板对模型训练、分词性能等方面影响的对比实验。表5给出了这些特征模板集训练过程的对比数据,对比实验过程中除特征模板集包含或不包含B模板的区别外,其他参数都相同。
对比表5中的数据可以得出如下结论:①增加B特征模板之后,训练中扩展出的特征数都增加了16,这也进一步验证了在四词位标注汉语分词中该模板可以扩展出16个(词位转移)特征。②训练时间和迭代次数都大大增加,是相应的2倍以上。例如,增加B模板后,训练时间是相应特征模板集训练时间的2.14~5.59倍。③增加B特征模板基本不改变训练出的模型大小。
表6给出了1~7号特征模板集包含和不包含B模板的分词结果对比数据。对比表6中的数据可以得出如下结论:增加B特征模板之后,两种语料上反映分词性能的5个指标除了一组数据 (见斜体加粗部分)之外,其他所有的数据都是清一色的增加,虽然增加的幅度不是太大。所以,加入词位转移特征对分词性能是有提高的。
4 结束语
汉语分词作为中文信息处理领域一项基础研究课题,从首届国际汉语分词评测活动以来得到了广泛的关注,其中基于字的词位标注汉语分词技术成为主流。为了在词位标注汉语分词中更加准确地设定特征模板,本文采用B、M、E、S四词位标注集,使用条件随机场模型从多个角度定量分析了词位标注汉语分词中的特征模板。通过对实验数据的分析,从 “量”上揭示出词位标注汉语分词中设定特征模板需要遵循的多组规律:①同等条件下,训练出的模型大小与扩展出的特征数成正比。②不同的单字特征模板在同一语料中扩展出的特征数基本相同,单字特征模板对分词性能的贡献要比双字特征模板小很多。③增加B特征模板之后,训练时间大大增加,模型大小基本不变,对分词性能都是正增长。这些规律为特征模板对汉语分词及其他词法分析任务的支持作用提供了一个 “量”上的依据。
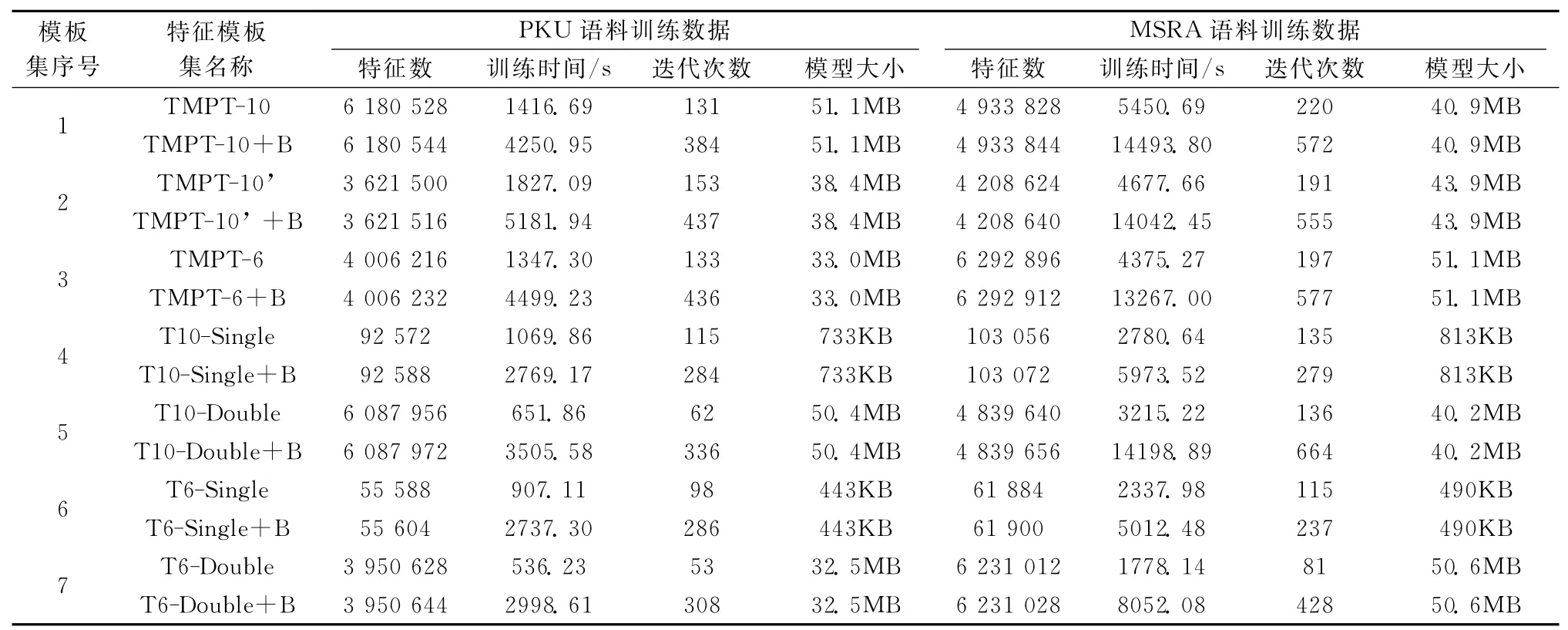
表5 包含和不包含词位转移特征模板的训练过程对比数据

表6 不同特征模板集的分词结果
[1]JIANG Wei,WANG Xiaolong,GUAN Yi,et al.Research on Chinese lexical analysis system by fusing multiple knowledge sources[J].Chinese Journal of Computers,2007,30 (1):137-145 (in Chinese).[姜维,王晓龙,关毅,等.基于多知识源的中文词法分析系统 [J].计算机学报,2007,30 (1):137-145.]
[2]LUO Yanyan,HUANG Degen.Chinese word segmentation based on the marginal probabilities generated by CRFs [J].Journal of Chinese Information Processing,2009,23 (5):3-8(in Chinese).[罗彦彦,黄德根.基于CRFs边缘概率的中文分词 [J].中文信息学报,2009,23 (5):3-8.]
[3]ZHAO Hai,Chunyu Kit.Unsupervised segmentation helps supervised learning of Character tagging for word segmentation and named entity recognition [C].Proceedings of the Six SIGHAN Workshop on Chinese Language Processing.Hyderabad,India:ACL Press,2008:106-111.
[4]YANG Erhong,FANG Ying,LIU Dongming,et al.The evaluation of Chinese word segmentation and POS tagging [J].Journal of Chinese Information Processing,2006,20 (1):44-49 (in Chinese).[杨尔弘,方莹,刘冬明,等.汉语自动分词和词性标注评测 [J].中文信息学报,2006,20 (1):44-49.]
[5]JIANG Wenbin,HUANG Liang,LIU Qun,et al.A cascaded linear model for joint Chinese word segmentation and part-of-speech tagging [C].Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics,2008:897-904.
[6]HUANG Changning,ZHAO Hai.Chinese word segmentation:A decade review [J].Journal of Chinese Information Processing,2007,21 (3):8-19 (in Chinese). [黄昌宁,赵海.中文分词十年回顾 [J].中文信息学报,2007,21 (3):8-19.]
[7]SONG Yan,CAI Dongfeng,ZHANG Guiping,et al.Approach to Chinese word segmentation based on character-word joint decoding [J].Journal of Software,2009,20 (9):2366-2375(in Chinese).[宋彦,蔡东风,张桂平,等.一种基于字词联合解码的中文分词方法 [J].软件学报,2009,20(9):2366-2375.]
[8]ZHAO Hai,HUANG Changning.Effective tag set selection in Chinese word segmentation via conditional random field modeling[C].Wuhan,China:Proceedings of PACLIC-20,2006:87-94.
[9]HUANG Changning,ZHAO Hai.Which is essential for Chinese word segmentation:Character versus word [C].Wuhan,China:Proceedings of PACLIC-20,2006:1-12.
[10]ZHAO Hai,JIE Chunyu.Effective subsequence-based tagging for Chinese word segmentation [J].Journal of Chinese Information Processing,2007,21 (5):8-13 (in Chinese).[赵海,揭春雨.基于有效子串标注的中文分词 [J].中文信息学报,2007,21 (5):8-13.]
[11]HUANG Changning,ZHAO Hai.Character-based tagging:A new method for Chinese word segmentation [C].Proceedings of Chinese Information Processing Society 25Annual Conference.Beijing,China:Tsinghua University Press,2006:53-63 (in Chinese). [黄昌宁,赵海.由字构词——中文分词新方法[C].中文信息处理前沿进展——中国中文信息学会二十五周年学术会议论文集,北京:清华大学出版社,2006:53-63.]
[12]HUANG Degen,JIAO Shidou,ZHOU Huiwei.Dual-layer CRFs based on subword for Chinese word segmentation [J].Journal of Computer Research and Development,2010,47(5):962-968 (in Chinese).[黄德根,焦世斗,周惠巍.基于子词的双层CRFs中文分词 [J].计算机研究与发展,2010,47 (5):962-968.]
[13]Levow G.The third international Chinese language processing bakeoff:word segmentation and named entity recognition[C].Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing.Sydney:ACL Press,2006:108-117.
[14]Pereira L J,Mccallum F A.Conditional random fields:Probabilistic models for segmenting and labeling sequence data[C]Proceedings of 18th Int Conf on Machine Learning.San Francisco,USA:AAAI Press,2001:282-289.
[15]YU Jiangde,SUI Dan,FAN Xiaozhong. Word-positionbased tagging for Chinese word segmentation [J].Journal of Shandong University (Engineering Science),2010,40 (5):117-122(in Chinese). [于江德,睢丹,樊孝忠.基于字的词位标注汉语分词 [J].山东大学学报 (工学版),2010,40(5):117-122.]
