融合领域命名实体识别的查询扩展方法研究
2012-07-25邹俊杰余正涛刘跃红宗焕云
邹俊杰,余正涛+ ,刘跃红,宗焕云,苏 磊
(1.昆明理工大学 信息工程与自动化学院,云南 昆明650051;2.昆明理工大学 智能信息处理重点实验室,云南 昆明650051)
0 引 言
查询扩展是提高文本检索准确率的最有效的手段,目前已广泛应用于信息检索和问答系统的文本检索中[1-6]。其思想是利用和查询相关的扩展词对查询进行重构,以提高检索准确率。在通用领域中查询扩展的方法有很多,主要有基于全局分析的查询扩展技术[2-3],基于局部上下文分析的查询扩展技术[2],基于语言模型的扩展技术[6],基于随机游走模型的查询扩展技术[7]及基于用户日志的查询个性化扩展技术[8]。但上述方法对特定领域中的问题进行扩展时存在查询结果偏离特定领域的问题。如:在旅游领域中,使用基于全局分析的查询扩展技术[2]对问题 “云南的苹果品质怎么样?”进行查询扩展时,会将 “手机、电脑”之类的词添加到扩展词列表中,而在旅游领域的受限域文本检索系统中,扩展词 “手机、电脑”等通常被认为是不合理的查询扩展,其扩展的结果将会使查询结果发生偏离,影响召回数据的准确率,因此需弱化甚至去除这些非领域扩展词带来的问题。在特定领域文本检索系统中,由于选取的扩展词符合领域特性,能检索出相关性更高的文本,查询召回的是相应的领域文本,而非召回和查询词相关的所有文本,因此加入领域知识来扩展查询词有利于解决查询结果偏离问题。
目前,在特定领域中,查询扩展方法的思想主要是依靠加入特定词典或者特定规则来完成查询扩展。比如在国外的生物医学领域中,针对英文单词的频繁变化问题,文献 [9]提出了基于规则的方法来扩展查询,文献 [10-11]用基于生物医学领域的同义词库来扩展查询,而类似这些方法有一定局限性。如在领域发生改变后需根据不同的领域重新构造新规则或领域词典,而不同的语言其扩展方法可能存在较大差异。因此,这些方法的普适性较低,在一定程度上限制了其推广。
综上所述,在特定领域中,仅使用开放域中基本的查询扩展方法会带来查询偏离问题,而通过编写大量规则或更换领域词典来解决查询偏离问题,将会大大降低方法的普适性。为克服上述查询偏离问题并兼顾查询扩展的普适性,本文根据特定领域查询扩展的特点提出一种结合领域命名实体识别与开放域查询扩展方法进行查询扩展,通过实验表明,该方法不但改善了领域查询扩展的偏离问题,同时改善领域查询扩展方法的普适性。(本文如果没有特别指明具体的受限域或特定领域,默认为云南旅游领域。)
1 领域命名实体识别与查询扩展
1.1 领域命名实体识别
命名实体识别是自然语言处理中的一项基础性子任务。目前在一些受限领域中,命名实体识别也得到了一定的应用。比如文献 [11-12]分别使用支持向量机 (support vector machine)和隐马尔科夫模型 (hidden Markov model)对生物医学领域的一些实体进行识别,文献 [13]使用了重叠条件随机场对旅游领域的景点、特色小吃等实体进行识别,取得了很好的效果。
条件随机场是一个无向图模型,是一种用来标记数据的统计模型。最早是由Lafferty等人在文献 [14]中提出,模型的核心思想来自于最大熵模型,同时使用了隐马尔科夫模型中提出的Viterbi算法、前向算法和前向后向算法来求解模型。通常情况下,条件随机场都是使用其一阶链式结构,其概率模型的表示形式为

式中:O——观察序列,L——标记序列,Z(O)——归一化因子,μk——特征权重,fk——状态函数或转移函数。当得到标记序列L以后就可以很容易的将序列所对应的命名实体词序列提取出来。
文献 [13]提出了一种基于层叠条件随机场 (CCRFs)的旅游领域实体识别方法,该方法将识别过程分为两层,低层模型采用字一级进行建模,识别地点及简单景点、特产小吃等,然后将识别结果传递到高层模型,在高层采用词一级进行建模,识别嵌套的景点、特产小吃,本文在其基础上对旅游领域4个类别 (景点、地方、风土民情、酒店)进行标注,并对每个类别再次细分并标注为18个小类,其类别信息见表1,利用上述标注语料,训练出旅游领域的命名实体识别模型。

表1 旅游领域详细类别
文献 [13]的方法在封闭测试中准确率为91.35%,开放测试中准确率为87.24%,本文采用相同的方法对上述类别进行试验,也达到了85%以上的准确率。
1.2 基本查询扩展方法
首先介绍本文使用的几种基本查询扩展方法:
(1)基于TF-IDF的查询扩展:基于TF-IDF的查询扩展模型的基本思想是,先对初检回来的前N个信息片段(Snippets)进行分词并去停用词,然后利用TF-IDF权重计算方法式 (2)对Snippets中的词进行计算,选择前k个分值靠前的词作为查询扩展词并加入到原始查询Q中再次检索

(2)基于互信息的查询扩展:从信息论的角度看,互信息 (mutual information,MI)度量的是两个随机事件x和y发生的相互依赖程度,通常为这两个随机事件发生的概率p(·)的函数,如下表示
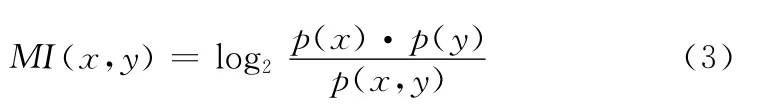
基于互信息的查询扩展方法其核心思想是在文献 [16]的方法上,计算侯选词Wi与问句Q的互信息。考虑信息检索或问答系统中,查询通常由多个关键词构成,因此在选取扩展词时,本文先计算候选扩展词与查询Q中的每个词的互信息,再求和,最后做归一化处理。其处理过程参照式 (4),式中m代表初始查询Q中的关键词数,qt为初始查询中的关键词,Zm是归一化因子,δ是一个平滑项,称为防零因子,本文取δ=0.01。P(wi,qt)为候选扩展词wi与关键词qt,同时出现的概率。式中P(·)的概率值均采用极大似然估计来计算
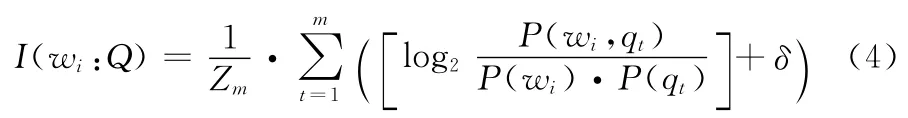
(3)基于局部上下文分析的查询扩展:局部上下文分析[2]的思想是将术语看成概念,然后在上下文环境中计算概念与查询之间的相关度并排序,利用排序结果选取排名靠前的概念作为候选扩展词,通常使用概念和查询词的共现频率的方法来选择概念。概念的上下文环境类似于相关性反馈技术。对于传统相关性反馈技术计算其相关性是根据初始召回的前N篇相关文档与查询Q对比进行分析,而局部上下文分析是从初始召回的前N篇文档中的每篇文档中选择最好的一段,然后将选取的每一段与查询Q对比来进行分析。局部上下文分析技术是全局分析技术和局部反馈技术相结合的实用技术,常用于查询扩展。
本文采用类似于文献 [2-3]的方法来对旅游领域的查询Q进行扩展。
首先需要确定上下文的段落集SP,利用Google召回的前N个信息片段集合S= {s1,s2,…,si,…,sn},对每一个片段si进行句子切分,然后利用式 (5)来选取段落。其中length是统计si的句子数目;f(di)是自动摘要提取函数,本文采用了文献 [10]的方法来对文档di进行自动摘要的提取。因摘要提取细节不是论文研究重点,故本文不对其详述

然后利用段落集SP,计算每一个概念和查询Q的相关度SIM (Q,C),计算公式如下
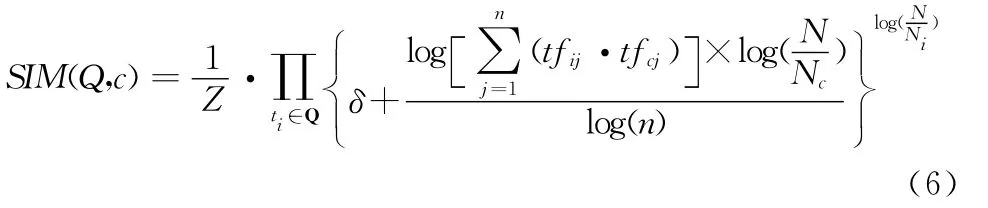
式中:Z——归一化因子,δ——为了防止等式为零的平滑因子,tfij、tfcj——词ti、概念 C 在段落 SPj中的词频;N——段落检索集的段落总数,Ni、Nc——词ti、概念C在出现在段落检索集的段落数目。
接着对计算结果进行排序。最后选取前k个概念作为候选词加入到初始查询中。为了让词的排序有意义,使用Indri检索平台 (www.lemurproject.org)的Indri查询语言对查询进行重构,重构后的查询表达式如下式
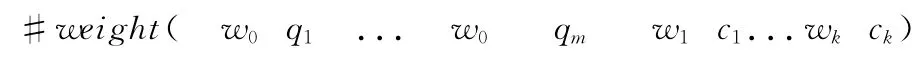
式中:qi——原始查询Q中的关键词,ci——排序以后的第i个概念,wi——关键词在查询时的权重,本文使用和文献[2]类似的方法来计算权重,见式 (7)。式中,当wi是原始查询Q对应的权重时i=0;k表示扩展词的个数,经过多次对k值的实验,本文取k=70
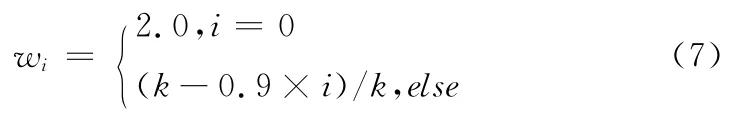
1.3 融合领域命名实体识别的查询扩展方法
若在开放域的基本查询扩展方法中,通过加入特定词典或特定规则来完成特定领域的查询扩展,则限制了查询扩展方法的推广,不仅使其普适性降低,同时会带来查询偏离问题。为克服上述查询偏离问题并兼顾查询扩展的普适性,本文根据特定领域查询扩展的特点提出一种结合命名实体识别与开放域查询扩展方法进行查询扩展,其处理过程如图1所示。

图1 命名实体识别与基本查询方法结合扩展过程
为发挥命名实体识别与基本查询扩展方法两者的优势,同时克服其本身不足,如命名实体识别技术存在自身识别准确率的不理想问题、基本扩展方法在特定领域查询存在偏离问题,本文将两者进行结合并使用线性差值平滑法,具体结合方式用如式 (8)进行处理

式中:wi——候选词汇集中的第i个词;Λwi——布尔型的概率函数,其表示在段落组成的序列O在进行旅游领域命名实体识别以后,词wi是否是旅游领域的实体的概率,如果是,Λwi为1,否则为0;λ∈ [0,1]是平滑参数;p(Wi|Q)为在查询Q的前提下,词wi的概率,当结合方法为基于 TF-IDF的查询扩展方法时p(Wi|Q)=Weigthi,当结合方法为基于互信息的查询扩展方法时P(Wi|Q)=I(Wi:Q),当结合方法为局部上下文分析时p(Wi|Q)=SIM (Q,C)。
2 实验与结果分析
由于目前没有比较权威统一的旅游语料资源,所以本文人工收集了2300篇旅游领域的语料,其中包含了上述18个不同类别的语料,每个类别大约有120篇文档。本文通过统计语料的词频信息筛选出旅游领域的停用词表,同时加入了通用的停用词表一起组成总停用词库,同时实验中使用的外部信息摘要的片段数目设定为100。
2.1 建立识别模型
本文使用人工收集的2300篇旅游领域语料作为训练集(相关语料资源可到http://www.liip.cn获取),采用文献[13]中的原子特征模板和复合特征模板,并利用CRF++工具对其进行训练,生成旅游领域命名实体识别 (SNER)模型,其平均识别准确率达到了85%。
2.2 λ参数的确定
采用逐步迭代的方法来确定式 (8)中的λ。首先从基础问句语料库中按18个类别分别随机抽取10个问句,组成180个问句集,然后对问句集去停用词,组成训练问句集QS,最后使用领域命名实体识别 (SNER)技术分别结合TF-IDF方法、互信息方法、局部上下文分析方法进行实验,实验前采用逐步迭代的方法确定各方法的最优λ。本文λ取值从0到1,并设置步长为0.1进行迭代求解,得到图2的实验结果。经实验验证,当λ分别为0.5、0.8和0.6时获得对应方法的最优解,这样就确定了上述3个对比试验中的最优λ值。
从图2可以看出,当λ=0时,式 (8)退化为p(wi)=p(wi|Q),即为普通的查询扩展方法,但随着λ的增加命名实体技术所对应的Λwi(O)项逐步得到加强,其准确率得到逐步的提高。从图2数据说明随着λ值的增大,其准确率不会一直提高,当λ增加到一定值时,准确率达到最值点,随后随着λ的增加准确率会随之下降,通过实验室说明随着λ比重的逐步增加,命名实体识别技术也能阻碍查询扩展的准确率,因此不能只靠命名实体识别技术来提高查询扩展的准确率。
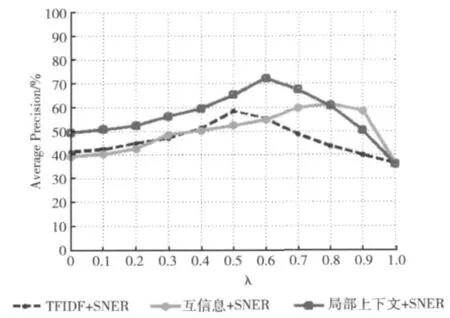
图2 不同参数λ的3种方法的平均准确率
2.3 查询扩展方法对比
为验证方法的有效性和普适性,本文选择基于TF-IDF的查询扩展方法、基于改进的TF-IDF查询扩展方法、基于互信息的查询扩展方法、基于改进的互信息查询扩展方法、基于局部上下文分析和结合命名实体识别与局部上下文分析的查询扩展作对比实验。
对比实验一:基于TF-IDF和基于改进的TF-IDF的查询扩展实验
基于TF-IDF的查询扩展方法,其核心思想[15]如式(2)所示,加入命名实体识别进行改进,通过线性插值做平滑处理,用改进式 (8)进行实验,其中P(Wi|Q)取式 (2)所述 Weigthi。具体形式如下

对比实验二:基于互信息和基于改进的互信息查询扩展实验
基于互信息的查询扩展方法其核心思想参见式 (4),基于改进的互信息查询扩展方法,在互信息查询扩展方法的基础上结合命名实体识别技术,进行线性插值做平滑处理,用改进式 (8)进行实验,其中P (Wi|Q)取式 (4)所述I(Wi:Q),具体形式如下

对比实验三:基于局部上下文分析和基于改进的局部上下文分析查询扩展实验
基于局部上下文分析的查询扩展方法中心思想参见式(6)所述,对其进行改进,结合命名实体识别技术,进行线性插值做平滑处理,用式 (8)进行实验,其中P(Wi|Q)取式 (6)所述SIM (Q,C)。
在进行对比实验之前需要确定式 (8)中最优λ值。也就是确定上述3种不同方法的最优λ值,然后依次根据P(Wi|Q)所取值代入式 (8)进行实验。
2.4 实验结果
本文从实验室2.3万句的基础问句语料库中随机抽取100个问句作为测试问句集。使用基于TF-IDF、基于改进的TF-IDF、基于互信息、基于改进的互信息、基于局部上下文分析以及基于改进的局部上下文分析分别进行查询扩展实验,得到表2、表3以及表4中的实验结果,实验表格中括号里面的内容为增长率。
由表2、表3以及表4实验数据说明,领域命名实体识别技术对基于TF-IDF、基于互信息及基于局部上下文分析的查询扩展都有较好的表现,且测试结果比较稳定。在对比实验中所使用的基本方法 (基于TF-IDF、基于互信息、基于局部上下文分析)通常都是针对开放域的系统,对受限域的问题没有做相关优化,本文是对特定领域的查询扩展进行研究,对于特定领域直接上述基本方法进行查询扩展,实验结果表明其平均准确率都不高,而加入特定领域命名实体识别技术以后,其准确率得到了很大的提高,相比其基本扩展方法平均P@n提高幅度均超过了50%,且任何单项提高都超过了10.4%以上。当然这与将结果定位在特定领域有关,但实验确实说明提高幅度较大。
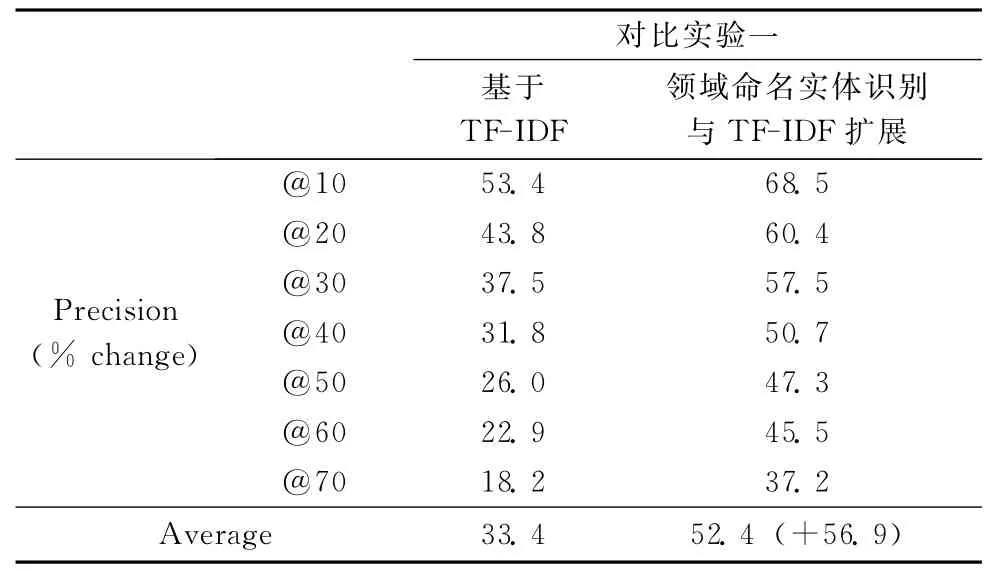
表2 基于TF-IDF及结合SNER的IF-IDF的改进对比实验

表3 基于MI及结合SNER的MI的改进对比实验
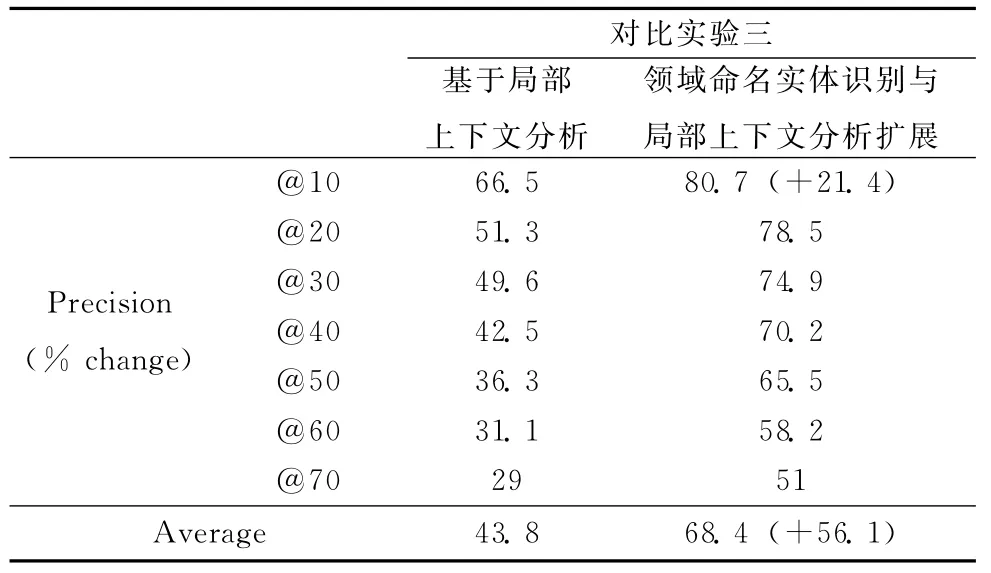
表4 基于LCA及结合SNER的LCA的改进对比实验
通过表2到表4的实验数据,可得出以下分析。第一,在特定领域的查询扩展中,对开放域的基本查询扩展方法上融入领域命名实体识别技术对获取领域相关扩展词有很大提高;第二,在上述对比实验中,结合领域命名实体识别与局部上下文分析查询扩展方法取得的效果最好;第三,因本文研究的是受限域系统,评价扩展词是否是领域相关扩展词,因此加入领域知识后其准确率得到一定的提高;第四,本文采用的技术可应用在很多特定领域,只需对相关领域定义模板并进行标注,然后利用CRF建立模型,因此本文方法具有一定的普适性。
另外,对本文查询扩展方法进行稳定性比较,计算准确率在p@10到p@70之间的变化情况,实验中取步长为10。图3说明在加入领域命名实体识别技术 (SNER)之前和之后的相关方法稳定性比较。从图3分析可知,各基本方法加入领域命名实体识别技术之后,其下降速率得到明显的缓解,相对加入领域命名实体识别技术之前的基本方法稳定。

图3 3种方法稳定性分析
3 结束语
在受限域问答系统答案文本检索查询扩展中,将领域命名实体识别技术和通用领域基本查询扩展方法相结合,有助于提高扩展效果,其中局部上下文分析查询扩展方法提高最显著。通过本文对比实验说明,结合领域命名实体识别技术能很好改善受限域系统的查询扩展性能,并提高查询扩展的稳定性。问答系统查询通常是以问句的形式表述,必然存在语义信息,下一步将在查询扩展中考虑问句的语义信息来提高扩展的准确性。
[1]Attar R,Fraenkel A S.Local feedback in full-text retrieval systems [J].ACM,1977,24 (3):397-417.
[2]Xu J,Croft W B.Query expansion using local and global document analysis [C].Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Zurich,Switzerland:ACM,2006:4-11.
[3]Sun R,Ong C-H,Chua T-S.Mining dependency relations for query expansion in passage retrieval[C].Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Seattle,Washington:ACM,2006:382-389.
[4]Callan J P,Croft W B,Broglio J.TREC and TIPSTER experiments with INQUERY [C].Readings in Information Retrieval:Morgan Kaufmann Publishers Inc,1997:436-439.
[5]Jing Y,Croft W B.An association thesaurus for information retrieval[R].USA:University of Massachusetts,1994.
[6]Bai J.Query expansion using term relationships in language models for information retrieval[C].Proceedings of the 14th ACM International Conference on Information and Knowledge Management.Bremen,Germany:ACM,2005:688-695.
[7]Collins-Thompson K,Callan J.Query expansion using random walk models [C].Proceedings of the 14th ACM International Conference on Information and Knowledge Management.Bremen,Germany:ACM,2005.
[8]Cui H,Wen J-R,Nie J-Y,et al.Probabilistic query expansion using query logs [C].Proceedings of the 11th International Conference on World Wide Web.Honolulu,Hawaii:ACM,2002:325-332.
[9]Cohen A M.Unsupervised gene/protein named entity normalization using automatically extracted dictionaries [C].Proceedings of the ACL-ISMB Workshop on Linking Biological Literature,Ontologies and Databases:Mining Biological Semantics.Detroit,Michigan:Association for Computational Linguistics,2005:17-24.
[10]Goldstein J,Kantrowitz M,Mittal V,et al.Summarizing text documents:Sentence selection and evaluation metrics[C].Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Berkeley,California:ACM,1999.
[11] WANG Haochang,ZHAO Tiejun.SVM-based biomedical name entity recognition [J].Journal of Harbin Engineering University,2006,27 (B07):570-574 (in Chinese). [王浩畅,赵铁军.基于SVM的生物医学命名实体识别 [J].哈尔滨工程大学学报,2006,27 (B07):570-574.]
[12]CHEN Jin,CHANG Zhiquan.HMM-based biomedical named entity recognition and classification [J].Computer Era,2006,24 (10):40-42 (in Chinese).[陈锦,常致全,许军.基于HMM的生物医学命名实体的识别与分类 [J].Computer Era,2006,24 (10):40-42.]
[13]GUO Jianyi,XUE Zhengshan,YU Zhengtao,et al.Named entity recognition for the tourism domain based on cascaded conditional random fields [J].Journal of Chinese Information Processing,2009,23 (5):47-52 (in Chinese). [郭剑毅,薛征山,余正涛,等.基于层叠条件随机场的旅游领域命名实体识别 [J].中文信息学报,2009,23 (5):47-52.]
[14]Lafferty J,McCallum A,Pereira F.Conditional random fields:Probabilistic models for segmenting and labeling sequence data[C].International Conference on Machine Learning,2001.
[15]Liu Y,Ciliax B J,Borges K,et al.Comparison of two schemes for automatic keyword extraction from MEDLINE for functional gene clustering [C].Proceedings of the IEEE Computational Systems Bioinformatics Conference.Washington,DC,USA:IEEE,2004:394-404.
[16]C hurch K W,Hanks P.Word association norms,mutual information,and lexicography [J].Comput Linguist,1990,16 (1):22-29.
