基于ICA降维的车牌汉字识别研究
2012-07-25詹永照单士娟
沈 洋,詹永照,单士娟
(1.江苏大学 计算机科学与通信工程学院,江苏 镇江212013;2.宿迁学院 计算机科学系,江苏 宿迁223800)
0 引 言
智能交通系统是衡量一个国家现代化程度的重要指标,而车牌的自动识别是智能交通系统的关键技术之一[1],在车牌识别中最难的就是汉字的识别,一方面汉字的笔画繁多,提取特征比较困难,另一方面有些汉字因为天气和路况等原因,污染的比较严重,所以车牌汉字识别一直都是车牌识别系统的核心技术。
当前对于车牌汉字识别,应用比较广泛的主要有以下两种方法[2]:第一种是根据汉字的笔画结构特征进行识别[3-5],理论上可以识别结构复杂的汉字,但是对于恶劣环境下的汉字识别率太低。第二种是依据汉字图像的统计特征进行识别,常见的是利用一些不变矩函数提取汉字的特征,从而进行分类。这种方法对于汉字图像的平移,旋转具有不变性,对图像的局部变化也不敏感,所以具有较强的抗干扰性,例如:高全华等[6]提出了一种基于伪Zernike矩的汉字识别方法,该方法将伪Zernike矩作为待识别车牌汉字的特征向量,输入概率神经网络中进行汉字识别,取得了较好的识别效果。然而还存在以下几个问题:①伪Zernike矩作为图像的特征向量时,需要使用比较高的维数才能较好表达图像,而高维特征向量不仅会增大后续操作的计算量,还可能存在冗余信息,在识别时不利于精确度的提高。②概率神经网络的模式层节点的个数等于训练样本的个数,当使用大样本的数据进行训练时,会严重影响识别的时间和对内存的需求。
针对以上这些缺点,本文提出了一种利用伪Zernike矩和独立主成分分析相结合的车牌汉字特征提取方法,并对概率神经网络进行了改进,用于车牌汉字识别,以期降低汉字识别时间,减少所占用的内存容量,提高汉字的识别率。
1 伪Zernike矩
(1)Zernike矩:Zernike矩[7]是一种正交复数矩,它对图像的细微变化和噪声信号具有鲁棒性,有着很好的图像表示能力。它使用了一组在单位圆x2+y2=1上定义的完备的复数正交函数集 {Vmn(x,y)}
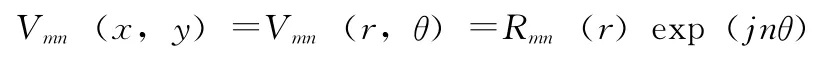

其中,整数m≥0为Zernike矩的阶数,整数n称为矩的重复度,满足大于等于零且是偶数。r=,θ=tan-1(y/x);。
通过此正交函数集,二维车牌汉字图像f(x,y)的m阶重复度为n的Zernike矩可表示为[8]
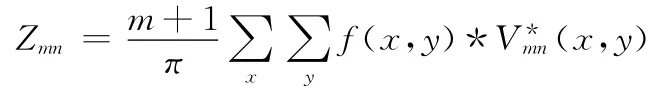
其中x2+y2≤1,(x,y)为Vmn(x,y)的共轭函数。
(2)伪Zernike矩:Bhatia和Wolf等人在Zernike矩的基础上提出了伪Zernike矩,同Zernike矩相比,伪Zernike矩不仅对干扰信号更不敏感而且还具有表达精确,计算速度快等特点[9]。
在计算上,伪Zernike矩和Zernike矩类似,只是正交函数集(x,y)}不同,伪Zernike矩的正交函数

其中整数m≥0为阶数,整数n为重复度,且。
2 伪Zernike矩特征的独立主成分分析降维
独立主成分分析 (ICA)[10]是近年来广泛应用的一种有效多维信号处理技术,其目的是从已知的混合信号中提取出未知的独立信号,经ICA处理得到的各信号之间不仅去除了相关性,而且还是相互独立的。
2.1 独立主成分分析 (ICA)的定义
假设一组观测信号X= [X1,X2…..Xn]是由一组独立信号S= [S1,S2…..Sn]通过未知的混合矩阵A线性组合生成的,即X=A*S,独立主成分分析的目的就是找到分离矩阵B,使得输出信号Y=B*X,其中Y=[Y1,Y2….Yn]是原始独立信号S的一个最佳逼近,ICA的模型如图1所示。

图1 ICA的模型
2.2 快速定点ICA (FastICA)算法
FastICA算法[11-12]是以负熵作为判断依据的一种独立主成分分析方法。熵是指信号中所含的信息量,因为判断输出的信号是否独立,可以转换为判断这些信号的非高斯性是否最大,而在所有的等方差随机变量中,高斯变量的熵是最大的,故可采用负熵作为衡量信号非高斯性大小的依据,又因为负熵很难计算,所以一般情况下输出的信号Y的负熵J(Y)可用下面的近似公式来代替[10]:J(Y)≈{E [G (Y)]-E [G (Yg)]}2,其中Yg是与输出的随机信号Y具有相同方差的一个的高斯随机信号,E(*)为均值运算,G(*)一般取 G (Y)=logcosh (Y)或 G(Y)=-exp (-Y2/2)。
2.3 车牌伪Zernike矩特征的ICA降维算法
本文提出的算法是利用了FastICA将车牌汉字图像的前20阶伪Zernike矩作为特征进行独立主成分分析,提取出特征的独立主成分分量,从而得到新的降了维的特征矩阵,具体步骤如下:
步骤1 对训练样本中汉字图像的前20阶伪Zernike矩组成的特征矩阵Z进行均值化处理,使其均值为零。
步骤2 对处理后的Z进行白化处理,即寻找白化矩阵V=D-1/2*UT,其中的D=diag(d1,d2…dn),di是Z的协方差矩阵E{Z*ZT}的特征值,U是由这些特征值对应的特征向量所构成的矩阵 (本算法在计算矩阵D、U时,保留了占所有特征值总和85%的前n个最大的特征值和相应的特征向量,而将其它的特征值和特征向量去除,从而实现了对特征的降维),求出白化矩阵V后,将V*Z作为ICA模型中的观测信号X,即X=V*Z。
步骤3 开始逐行寻找ICA模型中的分离矩阵B=[B1,B2…Bn]T,首先初始化B中的第一个向量B1。
步骤4 利用以下的近似公式迭代出新的向量:,其中E(*)为均值运算,g(*)为G(*)=logcosh(*)的导数,g′(*)为g(*)的导数。
步骤6 若迭代后的向量B1与本次迭代之前的B1指向的方向相同或相反,则迭代结束,并得到第一个独立分量Y1=B1*X,否则返回步骤4继续迭代。
步骤7 若已求出分离矩阵B的前p-1行向量B1,B2…BP-1,现在要求Bp,首先初始化Bp。
步骤8 利用以下的近似公式迭代出新的向量:,其中为均值运算,的导数,的导数。
步骤11 若新求出的向量Bp与本次迭代之前的向量Bp指向的方向相同或相反,则迭代结束,并得到第p个独立分量YP=Bp*X,否则返回步骤8继续迭代。
最终可求出分离矩阵B中的所有行向量B1,B2…Bn,以及所有的独立主成分分量Y1,Y2…Yn.构成的新的特征矩阵Y。
3 基于代表点的改进概率神经网络车牌汉字识别
概率神经网络 (PNN)是1990年由Specht提出的一种模式分类方法[13],其主要思想是利用贝叶斯决策规则在多维的输入空间内进行分类。
3.1 概率神经网络的拓扑结构
概率神经网络的拓扑结构可以分为以下4层:输入层,模式层,累加层和输出层。如图2所示。
待分类的一个样本特征向量Yi作为输入层的节点,所有的训练样本特征向量作为模式层的节点,模式层的功能是将待分类的样本向量与所有的训练样本向量 (即模式层的节点)相乘,并通过激活函数 (本文采用g(Yi)=exp,σ为平滑参数)运算后传送给累加层,累加层中节点个数等于训练样本的类别总数,其功能是将模式层中属于同一类别的节点传来的输入进行累加求和,其中求和值最大的类别号就传给输出层的节点。
概率神经网络的优点是:网络的训练简单[14]以及网络的模式分类性强 (只要提供足够多的训练样本,不管样本之间有多复杂的关系,都可以达到很好的分类效果[15]),缺点是模式层的节点个数等于训练样本的个数,当使用大量的训练样本时,会占用很多的内存空间,识别时的时间也比较长。

图2 概率神经网络的拓扑结构
3.2 基于代表点的改进概率神经网络训练算法
针对概率神经网络的这个缺点,本文提出了一种基于代表点的改进概率神经网络方法,使得可以用训练样本中的若干代表点作为网络模式层的节点,以期加快识别速度同时达到与改进前相似的识别效果,具体提取代表点的算法如下:
步骤1 取出训练样本中每一类汉字的所有样本特征向量Yi。
步骤2 求出这些样本向量之间的欧氏距离,形成距离矩阵D,并得到样本向量之间的最大距离max。
步骤3 由距离矩阵D得到一维密度矩阵V,V中每个元素V (i)表示第i个样本向量的密度,即与其距离小于0.5*max的向量的个数。
步骤4 求出V的平均值,将密度大于V平均值的所有样本向量,放入一个新的集合C。
步骤5 在C中以密度最大的那个样本向量作为第一个代表点r(1),将与其之间距离超出0.1*max,且密度最大的那个样本向量作为第二个代表点r(2)。
步骤6 将集合C中与前一次求出的代表点之间距离大于0.1*max,且密度最大的那个样本向量作为下一个代表点。
步骤7 重复步骤6,直到没有新的代表点求出为止。
4 实验结果与分析
实验采用的是复杂环境下的车牌汉字图像作为车牌汉字库,该汉字库由31种汉字组成,每一种汉字包含30幅不同的污损、变形图像。从该汉字库中抽取训练样本集和识别样本集。其中训练样本集包含了每种汉字的20幅不同污染变形图像,31种汉字总共有620个训练样本,部分训练样本图像如图3所示,识别样本集是由不包含在训练样本集中的随机抽取的200幅汉字图像组成。
本文主要针对文献 [6]所提出的基于伪Zernike矩的PNN车牌汉字识别方法、对伪Zernike矩进行独立主成分分析降维再送入概率神经网络中进行训练和识别的方法以及本文所采用的对伪Zernike矩进行独立主成分分析降维再送入基于代表点的改进概率神经网络中进行训练和识别的方法这3种方法,分别进行了实验,这3个实验都是在Windows XP环境下的Matlab R2007平台上实现完成的,实验中的测试时间指的是对1幅识别样本的识别时间 (不包括提取该样本伪Zernike矩的时间)。

图3 部分车牌汉字训练样本图像
在第一个实验中,采用文献 [6]所提出的只使用训练样本中每个汉字的4种污染变形图像对概率神经网络进行训练,用训练后的网络对识别样本集进行识别发现识别率极低,只有十几幅汉字图像能够正确识别,很显然文献[6]的方法不适合在复杂环境中应用。随后我们扩展训练样本,使用训练样本集中所有的620个训练样本图像对网络重新训练,训练后的网络模式层节点数为620个,对识别样本集测试,有20幅汉字图像不能正确识别,如图4所示,识别率为90%,测试时间为0.001253s

第二个实验,将所有训练样本提取伪Zernike矩得到210*620的特征矩阵,首先经过2.3节提出的ICA降维算法降维,得到54*620的新特征矩阵Y,以及54*210的分离矩阵B,再将Y送入概率神经网络中进行训练,训练后得到的模式层节点数为620个,对识别样本集测试后,有8幅不能正确识别,如图5所示,识别率为96%,测试时间为0.000845s。
在第三个实验中,将训练样本集提取伪Zernike矩和独立主成分分析降维后得到的54*620的新特征矩阵Y选取出每一类汉字图像样本的代表点,得到的每一类的代表点数如表1所示,其中第一类的样本代表点选取的结果如图6所示,最后以这些代表点作为模式层节点 (共计432个)训练概率神经网络,对识别样本集测试后,有11幅不能正确识别,如图7所示,识别率为94.5%,测试时间为0.000771s

表1 31种汉字中每一类提取的代表点数

比较这3种方法的实验结果发现,本文所采用的方法相对于文献 [6]的方法不仅降低了运行时对内存的需求(模式层节点数由620个降为432个),减少了运行时间(由0.001253s降为0.000771s),还显著的提高了车牌汉字的识别率 (识别率由90%提高到94.5%),其原因是本文算法所提取的图像特征之间是相互独立的,去除了冗余信息,所以对样本的分类效果更好。
我们有理由相信,随着训练样本的增大,本文提出的方法相对于文献 [6]的方法在性能上会有更大的提升。
5 结束语
本文分析了传统车牌汉字识别方法的优缺点,提出了一种基于伪Zernike矩和独立主成分分析的改进概率神经网络车牌汉字识别方法,通过与文献 [6]所提的方法进行实验比较,发现本文的方法在对内存的需求,识别的时间和识别率3个方面相对于文献 [6]都有较大的提高。
由于在概率神经网络中,每个模式层节点的激活函数,都选取了相同的平滑参数σ,这也在一定程度上限制了分类的效果,我们下一步的工作将着重研究能否让模式层节点采用自适应的平滑参数σ,以期能进一步提高识别率。
[1]WANG Xiaoxue,SU Xingli.Application of digital image processing in license plate recognition [J].Process Automation Instrumentation,2010,31 (7):22-28 (in Chinese).[王晓雪,苏杏丽.数字图像处理在车牌识别中的应用 [J].自动化仪表,2010,31 (7):22-28.]
[2]ZHAO Zhihong,YANG Shaopu,MA Zengqiang.License plate character recognition based on convolutional neural network LeNet-5 [J].Journal of System Simulation,2010,22(3):638-641 (in Chinese).[赵志宏,杨绍普,马增强.基于卷积神经网络LeNet-5的车牌字符识别研究 [J].系统仿真学报,2010,22 (3):638-641.]
[3]HU Jinrong,ZHOU Jiliu,WANG Ling,et al.High-performance license plate recognition method based on shape feature of character [J].Application Research of Computers,2010,27 (6):2398-2400 (in Chinese). [胡金蓉,周激流,王玲,等.一种新的基于字符形状特征的高效车牌识别算法 [J].计算机应用研究,2010,27 (6):2398-2400.]
[4]WANG Jianxia,ZHOU Wanzhen.A license plate characters recognition method based on improved template matching [J].Journal of Hebei University of Science and Technology,2010,31 (3):236-239 (in Chinese). [王建霞,周万珍.一种改进模板匹配的车牌字符识别方法 [J].河北科技大学学报,2010,31 (3):236-239.]
[5]LI Xingyang, WANG Wenqing.Research of license plate character recognition algorithm based on template matching[J].Journal of Shanxi Normal University (Natural Science E-dition),2008,36 (S1):176-178 (in Chinese).[李兴阳,王文青.基于模板匹配的车牌字符识别算法研究 [J].陕西师范大学学报 (自然科学版),2008,36 (S1):176-178.]
[6]GAO Quanhua,WANG Jinguo,SUN Fengli.PNN recognition of license plate Chinese characters based on Pseudo-Zernike invariant moments [J].Computer Engineering,2009,35(4):196-198 (in Chinese).[高全华,王晋国,孙锋利.基于Pseudo-Zernike不变矩的PNN车牌汉字识别 [J].计算机工程,2009,35 (4):196-198.]
[7]LIU Maofu,HU Hujun.Evolutionary computation base optimization of image Zernike moments shape feature vector[J].Wuhan U-niversity Journal of Natural Sciences,2008,13 (2):153-158.
[8]CHEN Ping,LI Lei,REN Yuemei.Trademark image retrieval using region pseudo-Zernike moments [J].Computer Simulation,2010,27 (8):270-273 (in Chinese). [陈平,李垒,任越美.基于区域伪Zernike矩的商标图像检索 [J].计算机仿真,2010,27 (8):270-273.]
[9]YANG Di,SUN Jinguang,HE Wei,et al.Face feature extraction based on normalization of pseudo-Zernike moment [J].Computer Engineering and Application,2010,46 (35):163-165(in Chinese).[杨迪,孙劲光,何巍,等.基于伪Zernike矩归一化的人脸特征提取方法 [J].计算机工程与应用,2010,46 (35):163-165.]
[10]Aapo Hyvarinen,Juha Karhunen,Erkki Oja.Independent component analysis[M].Beijing:Publishing House of Electronics Industry,2007:274-284 (in Chinese). [Aapo Hyvarinen,Juha Karhunen,Erkki Oja.独立成分分析 [M].北京:电子工业出版社,2007:274-284.]
[11]Aapo Hyvarinen,Erkki Oja.A fast fixed-point algorithm for Indepent component analysis [J]. Neural Computation,1997,9 (7):1483-1492.
[12]FANG Limin,LIN Min.Detection of the main quality indicators in red wine with infrared spectroscopy based on FastICA and neural network [J].Spectroscopy and Spectral Analysis,2009,29 (8):2083-2086 (in Chinese). [方利民,林敏.基于FastICA和神经网络的红酒主要品质参数红外检测 [J].光谱学与光谱分析,2009,29 (8):2083-2086.]
[13]LI Qunhui,ZHANG Hang.A modified PNN-based method for traffic signs classification [J].Systems Engineering,2006,24 (4):97-101 (in Chinese).[黎群辉,张航.基于改进概率神经网络的交通标志图像识别方法 [J].系统工程,2006,24 (4):97-101.]
[14]CAI Jiliang,YE Wei.Air-raid target identification based on probabilistic neural network [J].Fire Control & Command Control,2010,35 (12):25-27 (in Chinese).[蔡继亮,叶微.基于概率神经网络的空袭目标识别 [J].火力与指挥控制,2010,35 (12):25-27.]
[15]LIU Jianxin.The study of algorithm about vehicle detection based on high resolution satellite image [D].Dalian:Dalian Maritime University,2008 (in Chinese). [刘建鑫.基于高分辨率卫星影像的车辆检测算法研究 [D].大连:大连海事大学,2008.]
