一种基于移动用户行为的回路融合社区发现算法
2012-07-25孟祥武史艳翠
肖 觅 孟祥武 史艳翠
(北京邮电大学智能通信软件与多媒体北京市重点实验室 北京 100876)
(北京邮电大学计算机学院 北京 100876)
1 引言
随着移动网络服务的日益涌现及其广泛应用,移动网络服务类型和信息内容的增长将逐渐超出人们所能接受的范围,加之移动设备的界面显示、终端处理、输入输出等能力有限,将导致严重的“移动信息过载”问题[1]。如何实时、准确地为移动用户提供个性化的移动网络服务是其盈利最大化的关键。社区发现是一种解决用户需求个性化问题的可行方法,并且广泛应用于互联网社会化网络服务中。与互联网相比,移动网络中移动用户主要与朋友,同事及家人等联系,所构成的移动社会网络比较稀疏,因此不能完全依照互联网中社会化网络服务的方法对移动社会化网络进行分析。“位置”、“实时性”、“绑定身份”和“动态交互”是移动互联网区别于传统互联网的关键特性[2]。因此将移动用户行为引入到社区发现中,能起到很好的辅助作用,提高移动社区发现的准确性。
移动社会化网络是一个现实网络,每个用户可以属于多个社区,比如朋友社区、同事社区和家人社区等,因此本文着重研究重叠社区发现问题。文献[3]中总结了目前重叠社区发现算法,大体上分为派系(完全子图)过滤算法和非派系过滤算法。派系过滤算法:Palla等人[4]提出了用于发现重叠社区的派系过滤CPM(Clique Percolation Method)算法,如果网络中的派系非常密集,该算法将把整个网络认为是一个社区;OCBCC (Overlapping Communities Based on Community Cores)算法是将派系作为初始的社区核心[5],然后将社区核有条件地进行融合,最后将剩余节点根据给定的规则加入到相应的社区。以上两种算法都是以派系为基础,对派系较少的网络难以实施。非派系过滤算法:基于标签传播是一类主要的算法,RAK(文献[7]根据文献[6]的作者Raghavan, Albert, Kumara命名)算法是一个简单的标签传播算法[6],RAK算法受多种随机性因素影响,其结果不稳定,每次产生的社区结构存在一定差异;COPRA(Community Overlap PRopagation Algorithm)在 RAK 标签传播的基础上[7],使每个节点携带多个标签,通过扩展标签的方式进行重叠社区划分,但是COPRA需要指定v参数,此参数对社区发现的结果影响很大,所以该算法有一定的局限性。
近年来,实体用户行为的研究越来越广泛,文献[8]利用移动用户行为信息建立模型,得出用户之间的信任关系及其信任程度,并将其与基于项目评分的相似度结合,应用到项目评分预测模型中。文献[9]提出以实体用户行为和时间戳为条件的信任预测模型,引入多维测量指标度量实体交互满意度,使得满意度计算更加精确。这些研究结果表明实体用户行为可以很好地预测用户之间的信任关系,提高算法的精确性。
根据上述研究,本文提出一种基于移动用户行为的回路融合社区发现算法,简称 CM(Circuits Merging)算法。该算法具有以下意义:(1)相比于目前的基于派系的社区发现算法,CM 算法对派系较少的网络可以得到更好的社区划分;(2)提出的回路融合策略和节点添加策略能有效地提高模块度;(3)通过加入移动用户行为,使得社区的划分具有了移动社会化网络的特性,提高了划分的准确性,这样的社区为文献[10]中阐述的移动服务推荐提供了基础。本文第2节提出和分析了基于移动用户行为的回路融合社区发现算法;第3节利用公开数据集和仿真数据集进行实验验证,结果表明了该算法的有效性和合理性;最后给出结论。
2 算法设计及分析
2.1 移动社会化网络模型
设图G=<V,E>是一个简单无向图,顶点集为V= {v1,v2,… ,vN},其中vi表示移动通信网中的移动用户;边集为E,如果移动用户vi与vj有通话记录,则vi与vj用无向边相连,记为eij=<vi,vj>;N表示移动用户的个数,本文用网络图来对移动社会化网络进行建模。现实世界中通话方式分为主叫方和被叫方,但实际研究中不能简单通过主叫或被叫来判断两人的地位关系,所以本文将这种有向关系转化为无向关系进行研究。
2.2 基于移动用户行为的移动社会化网络构建
与互联网及固话网相比,移动用户行为具有如下特征:(1)移动用户行为的可确定性,这种可确定性表现为移动通信设备通常是一个号码对应一个确定的用户,这是本文研究移动用户行为的基础,而固定电话和互联网没有这种对应关系,用户行为不可确定;(2)上下文信息,与互联网及固话网相比,由于移动网络的特点,移动用户受周围环境的影响更加明显,并且通过移动终端、传感器、GPS以及基站等可以获取移动用户实时的上下文信息,例如时间、位置、情绪、周围人员以及社会关系;(3)移动用户可以通过语音、短信、飞信等方式进行通信,而且手机还提供拍摄、视频录制、音乐播放、网页浏览、下载应用软件、GPS定位等功能,而固定电话除了语音通话,缺少以上这些丰富的服务体验。为了提高移动社区划分的准确性,本文将移动用户间的通信行为、移动用户与周围人员位置相处信息(位置、时长)引入到移动社区发现算法中,其中位置信息包括实验室、家、工作单位等。
定义1移动用户间总的语音通信时长TTC(Total Time of Communication):表示移动用户v1与v2总的语音通信时长,在不考虑主叫和被叫差异的前提下,TTC定义如下:
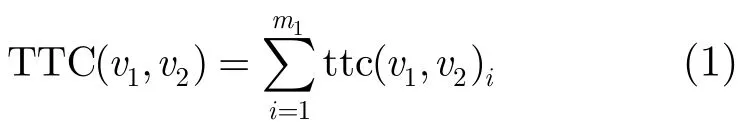
其中 t tc(v1,v2)i表示移动用户v1与v2第i次的通信时长,m1表示通信次数。
定义2移动用户与周围人员总的相处时长TTL(Total Time of Location):表示移动用户v1与v2总的相处时长,TTL定义如下:
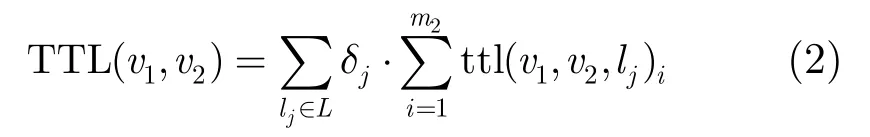
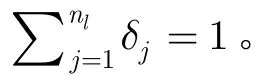
以移动用户v1和v2为例,将v1与其联系人的所有通话时长求和得到 T TC(v1),v1与v2的所有通话时长为 T TC(v1,v2),将v1与周围人员的相处时长求和得到总相处时长 T TL(v1),v1与v2的相处时长为TTL(v1,v2)。
定义3移动用户v1对v2的相关度DC(Degree of Correlation), DC定义如下:
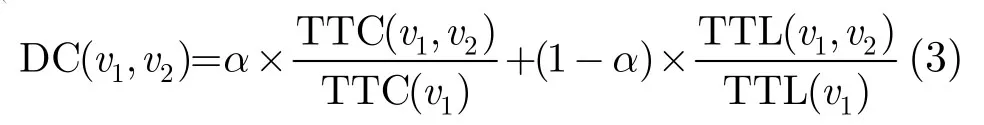
其中α≥0为权重参数,用来调节通话时长和通信次数的权重,α根据3.3节(1)中介绍的遗传算法调优得到。
定义4移动用户间相关度阈值TDC(Threshold of DC):在一次实验中固定不变的数值,用来限定用户间相关度的最小值。利用这个数值把低于阈值的用户间相关度值所对应的联系去除,即将由图G表示的移动社会化网络的相应边去除。当TDC设定太小,所得到的移动社会化网络将引入一些不必要的边,即移动用户之间的联系;当TDC太大时,所得到的移动社会化网络将丢失一些移动用户之间的联系。本文根据 3.1节的评价方法进行多次重复试验选取合适的TDC。
定义5移动用户间频繁相关度FDC(Frequency of DC):借鉴文献[11]中频繁模式的定义思想,FDC表示移动用户间相关度值与相关度阈值的差值,FDC定义如下:
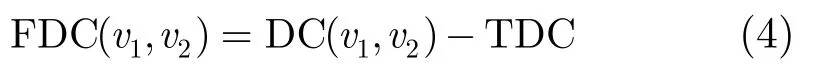
FDC(v1,v2)表示移动用户v1与v2间通信时长的参照值。
按照以下规则对移动社会化网络模型图G进行筛选,完成基于移动用户行为的移动社会化网络构建。
(1)当 F DC(v1,v2) ≥ 0 时,保留图G中节点v1与v2所对应的边 <v1,v2> ;
(2)当 F DC(v1,v2) < 0 时,删除图G中节点v1与v2所对应的边 <v1,v2> 。
定义6孤立子群:社会化网络中与其他群体没有边关联的群体称为孤立子群,包括只有一个节点的孤立节点[12]。
2.3 k-EC算法k值合理性分析及算法效率分析
通过对文献[13]所使用的EC简单回路生成算法进行修改得到k-EC算法,k-EC算法用限定生成回路的长度为k来得到适合本文社区发现的回路。
2.3.1 k-EC算法k值合理性分析基于小世界理论及六度分割理论[14],将k的上限设定为6。当k>6时,算法的效率会降低,并且太长的回路很有可能会使社区发现结果不精确,即在密集的网络中只能发现一个或少数几个很大的社区,不能够真正区分社区结构,失去社区发现的意义。根据简单回路的定义可知最小回路的长度为3,因此将k的下限设定为3。综上所述,k的取值范围为3≤k≤6。
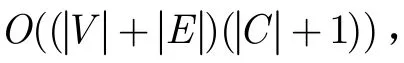
2.4 CM算法及正确性证明
2.4.1 CM算法描述
(1)利用2.3节介绍的k-EC算法提取每个孤立子群中满足规定长度的所有回路,将得到的回路当作是社区核,将这样的社区核的集合表示为Γ;同时将没有社区核的孤立子群看作一个独立社区,加入Γ中。
(2)社区核按照以下规则进行融合:
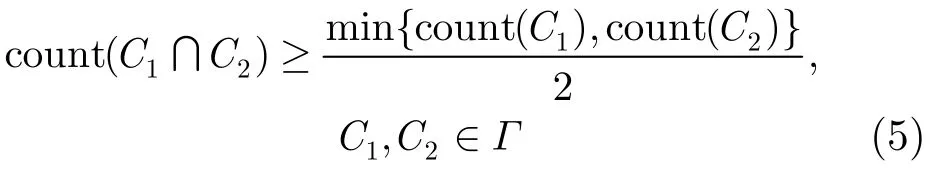
其中count(C)表示社区C包含的节点个数。如果社区核C1和C2满足式(5),将这两个社区核进行融合,形成一个新的社区核C′,新的社区核C′添加到Γ中,并在Γ中删除社区核C1和C2。
(3)如果Γ中没有新的社区核生成,则Γ为生成的初步社区集合,执行(4),否则执行(2)。
(4)Ψ表示网络中没有加入任何一个社区并且与Γ中的一个或多个社区有邻边的节点的集合。对于任意节点θ∈Ψ,如果θ只与一个社区相连,则将θ加入到这个社区中;如果θ与多个社区(C1,C2,…,Cn1)相连,则分别计算θ与每个社区中有连接边的节点的相关度之和,记为 D Ci(i= 1 ,… ,n1)。将θ加入DCi取最大值时所对应的社区中,如果DCi的最大值有几个社区对应,则将θ加入对应的几个社区中。
(5)如果所有节点都加入到一个或多个社区,则得到了最后的社区集合Γ,算法终止,否则执行(4)。
2.4.2 算法正确性证明本文选择利用文献[15]所使用的循环不变式证明方法对CM算法进行证明,将CM 算法归纳为如下的循环不定式:在每一轮循环开始前,对 ∀θ1∈Ci,Ci∈Γ,这样的节点θ1最后属于哪个社区是确定的,每一轮循环将没有社区归属的节点θ归类到一个或多个社区,使得θ∈Ci,Ci∈Γ。
初始化:步骤(1)利用k-EC算法将网络中的回路提取出来作为社区核,Γ为社区核集合,步骤(2)和步骤(3)将社区核进行合并形成初步社区,并得到新的集合Γ,对 ∀θ1∈Ci,Ci∈Γ,节点θ1在后面的循环中是不会再被处理,所以节点θ1社区归属确定不变,这样就证明了循环不变式在循环前是成立的;
保持:在步骤(4)的循环中,每次处理一个节点θ∈Ψ,计算θ与有边连接的社区的相关度DCi(i=1,…,n1),选择max(DC(θ)) = D Ci,将θ→Ci,因此一旦DCi计算出来,θ的社区归属通过这一规则确定了,在重叠社区的环境下,θ可能加入一个或多个社区,使得θ∈Ci,Ci∈Γ,因此每一轮循环都可以保证循环的不变式成立;
终止:由于网络中的节点数目的有限的,即为移动用户个数N,初始化中部分节点归属已经确定,而步骤(4)中每次都会处理完一个节点,因此算法会重复执行不多于N次,最终会在步骤(5)停止,此时∀θ1∈V都有θ1∈Ci,Ci∈Γ,即每个节点都有社区归属,综上可以得出算法是正确的。
3 实验
本小节描述实验方案设计以及实验结果分析,实验环境为:2 GB内存,2.66 GHz双核 CPU,Windows7操作系统,Java1.6开发语言,Myeclipse8.5和Matlab R2010a集成环境,Mysql5.1数据库。
3.1实验数据
公开数据集:麻省理工学院多媒体实验室MIT收集的数据集[16],包括94个移动用户从2004年9月到2005年6月共9个月移动用户的行为信息,并包括通话记录(通话和短信的时间、电话的主叫和被叫、短信的发送和接收)、位置、手机状态、蓝牙设备等信息。数据集中包括通过问卷调查得出的94个移动用户之间的好友关系,以及用户在实验室内和实验室外与其他人员的相处时间等数据。
仿真数据集:参考公开数据集的格式,生成实验所需要的仿真数据集。该数据集包含移动用户通信行为列表、移动用户位置列表,其中移动通信行为列表包含用户标识,通信联系人标识及每次通信时长;移动用户位置列表分为实验室内和实验室外两种情况,分别包括用户标识,相处联系人标识及每次相处时长。移动用户规模设为5000,将其分成5组。假定组内用户间关系较为紧密,组间用户较为稀疏,即设定组内移动用户间的通信时长(相处时长)占本组用户总通信时长(总相处时长)的80%的比例,组内用户和其他组的用户通信时长(相处时长)占20%的比例。参考公开数据集,限定移动用户标识,每次通信时长和每次相处时长的范围(如表1)。为了适应于本文考察派系较少网络的社区发现情况,需要对随机生成的数据集进行派系删减,将网络中90%的派系随机去掉一条或多条边,使得这些派系的结构不满足。

表1 属性范围限定
3.2 评价方法
本文采用文献[5]中提出的适用于重叠社区发现的模块度Qo评价方法,定义如下:
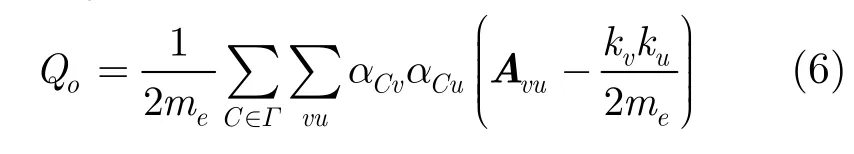
其中A代表社区社会化网络图G的邻接矩阵,me是网络中的总边数,Γ是社区的集合,kv是节点v的度数,αCv表示表示节点v属于社区C的程度,定义如下:
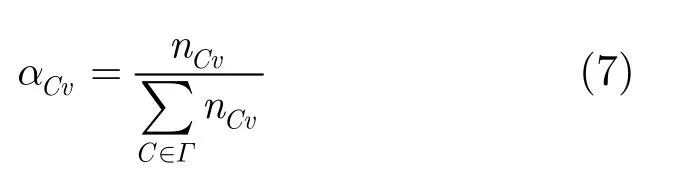
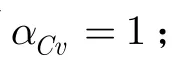
3.3 实验描述及结果分析
(1)CM 参数调优及可行性验证实验:利用 3.1节介绍的数据集对CM算法进行实验,选定两个用户之间的相处行为为实验室内和实验室外的相处时长。首先,对数据进行清洗,删去通信行为为空或通信行为记录为0的用户;然后用CM算法对移动通信网进行社区发现,得到生成的社区;由于目标函数与用户相关度密切相关,所以利用matlab数据包中的遗传算法(Genetic Algorithm, GA)函数分别对两个数据集参数进行调优,适应度函数定义如下:
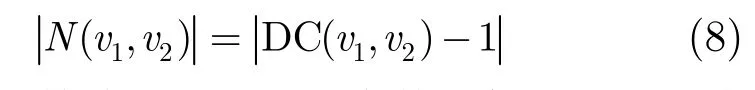
通过遗传算法调优得到两个数据集的最优参数值如表2所示。
然后根据表2中的参数和3.2节介绍的评价方法对模块度和TDC进行调优。通过对公开数据集反复试验对参数TDC进行调优,得到最优的模块度值Qo1= 0 .3521,此时TDC=0.1;对仿真数据集反复试验对参数TDC进行调优,得到最优的模块度值Qo2= 0 .5362,此时TDC=0.15。
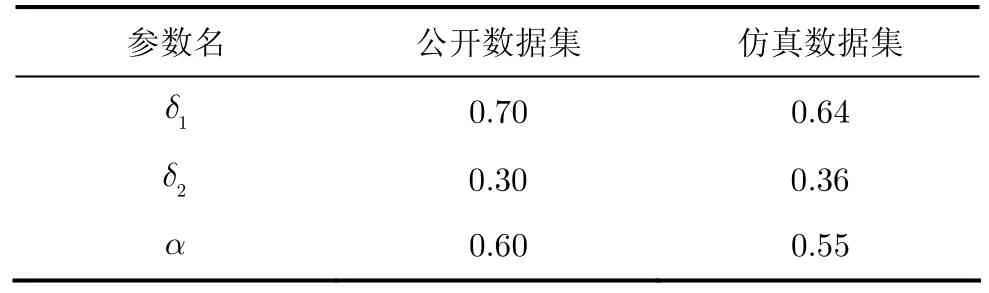
表2 调优参数值
图1为公开数据集的CM社区图,区域A和区域B表示对应的社区1和社区2所包含的节点,区域C表示重叠的节点。由文献[5]所计算出的模块度可知本文计算出的模块度Qo1和Qo2在一个合理的范围内。由图1可知,本文算法很好地区分了整个网络图稀疏和密集的部分,因此可得本文提出的 CM算法对派系较少的网络具有良好的可行性和有效性。
(2)CPM, OCBCC, CM对比实验:第1节介绍的CPM是当前最流行的重叠社区发现算法之一[4],OCBCC是比较新的重叠社区发现算法[5],CM是本文所提出的算法,CM的参数基于实验1的参数进行设置。本节利用3.1节介绍的数据集并结合3.2节介绍的评价方法对这3种算法进行对比实验,实验结果如表3所示。
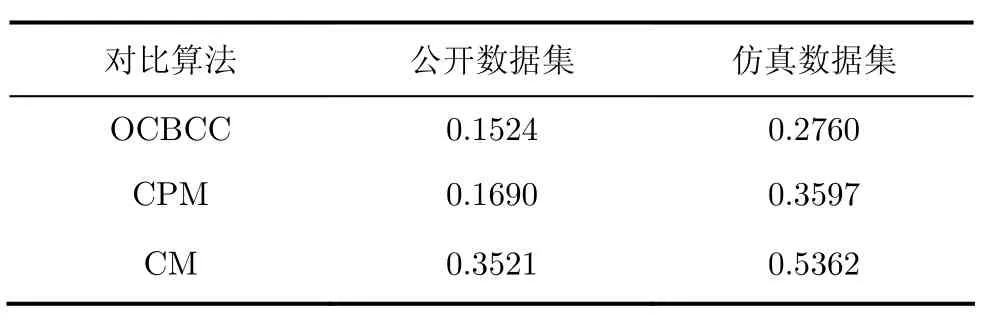
表3 模块度Qo对比
通过对比分析可以得出对 3.1节介绍的公开数据集来构建的派系较少网络时,使用 CM 算法比OCBCC算法的模块度提高了131%,比CPM算法模块度提高了108%;对仿真数据集构建的派系较少的网络时,使用CM算法比OCBCC算法模块度提高了94%,比CPM算法模块度提高了48%。以上结果充分说明CM算法对于派系较少的网络和具有移动特性的网络的社区发现具有更好的性能。
4 结束语
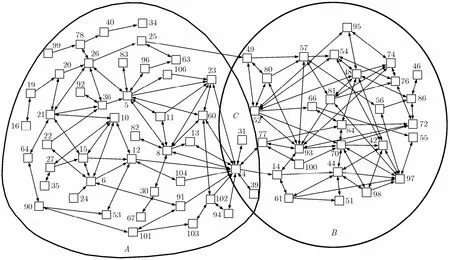
图1 公开数据集的移动社会化网络社区图
本文面向移动社会化网络,提出了一种基于移动用户行为的回路融合移动社区发现(简称 CM)算法,通过加入移动用户行为,采用所提出的回路融合算法,来对移动社会化网络进行CM算法社区发现。实验部分,首先通过实验1,对CM算法的参数进行调优并且对该算法的有效性进行了验证;然后通过实验2,验证了CM算法对于派系较少网络的社区发现具有更好的模块度Qo。实验结果表明,CM 算法能够解决移动社会化网络的派系较少的网络社区发现的问题,并且具有较好的模块度Qo。由于CM算法基于简单回路,相比于基于派系的算法条件更加宽松,所以对于一般派系足够多的网络来说,也能够实施CM算法。
[1]Chiu Po-huan, Kao Yi-ming, and Lo Chi-chun. Personalized blog content recommender system for mobile phone users[J].International Journal of Human-Computer Studies, 2010,68(8): 496-507.
[2]刘经南, 郭迟, 彭瑞卿. 移动互联网时代的位置服务[J]. 中国计算机学会通讯, 2011, 12(7): 40-50.
Liu Jing-nan, Guo Chi, and Peng Rui-qing. The locationbased services of mobile Internet era[J].Communications of China Computer Federation, 2011, 12(7): 40-50.
[3]Santo F. Community detection in graphs[J].Physics Reports,2010, 486(3-5): 75-174.
[4]Palla G, Derenyi I, and Farkas I. Uncovering the overlapping community structure of complex networks in nature and society[J].Nature,2005, 435: 814-818.
[5]Shang Ming-sheng, Chen Duan-bing, and Zhou Tao.Detecting overlapping communities based on community cores in complex networks[J].Chinese Physics Letters, 2010,27(5): 058901(1-4).
[6]Raghavan U N, Albert R, and Kumara S. Near linear time algorithm to detect community structures in large-scale networks[J].Physical Review E, 2007, 76(3): 036106(1-11).
[7]Gregory S. Finding overlapping communities in networks by label propagation[J].New Journal of Physics, 2010, 12(10):103018.
[8]黄武汉, 孟祥武, 王立才. 移动通信网中基于用户社会化关系挖掘的协同过滤算法[J]. 电子与信息学报, 2011, 33(12):3002-3007.
Huang Wu-han, Meng Xiang-wu, and Wang Li-cai. A collaborative filtering algorithm based on users’ social relationship mining in mobile communication network[J].Journal of Electronics&Information Technology, 2011,33(12): 3002-3007.
[9]李峰, 申利民, 司亚利, 等. 一种基于实体用户行为和时间戳的信任预测模型[J]. 电子与信息学报, 2011, 33(5): 1217-1223.
Li Feng, Shen Li-ming, and Si Ya-li,et al.. A trust forecasting model based on entity context and time stamp[J].Journal of Electronics&Information Technology, 2011, 33(5):1217-1223.
[10]Wang Li-cai, Meng Xiang-wu, and Zhang Yu-jie. A heuristic approach to social network-based and context-aware mobile services recommendation[J].Journal of Convergence Information Technology, 2011, 6(10): 339-346.
[11]万里, 廖建新, 朱晓民. 一种时间序列频繁模式挖掘算法及其在WSAN行为预测中的应用[J]. 电子与信息学报, 2010, 32(3):682-686.
Wan Li, Liao Jian-xin, and Zhu Xiao-min. Time series frequent pattern mining algorithm and its application to WSAN behavior prediction[J].Journal of Electronics&Information Technology, 2010, 32(3): 682-686.
[12]吴鹏, 李思昆. 适于社会网络结构分析与可视化的布局算法[J]. 软件学报, 2011, 22(10): 2467-2475.
Wu Peng and Li Si-kun. Layout algorithm suitable for structural analysis and visualization of social network[J].Journal of Software, 2011, 22(10): 2467-2475.
[13]Radde N. Fixed point characterization of biological networks with complex graph topology[J].Bioinformatics, 2010, 26(22):2874-2880.
[14]黄永生, 孟祥武, 张玉洁. 基于社会网络特征的P2P内容定位策略[J]. 软件学报, 2010, 21(10): 2622-2630.
Huang Yong-sheng, Meng Xiang-wu, and Zhang Yu-jie.Strategy of content location of P2P based on the social network[J].Journal of Software, 2010, 21(10): 2622-2630.
[15]Cormen H, Leiserson E, and Rivest L,et al.. Introduction to Algorithms[M]. Second Edition, Beijing: Higher Education Press, 2002, Chapter 2.
[16]Eagle N, Pentland A, and Lazer D. Inferring friendship network structure using mobile phone data[J].Proceedings of the National Academy of Sciences, 2009: 106(36):15274-15278.
