基于BP网络的木刻藏文经书文字识别研究*
2012-07-25赵栋材
赵栋材
(西藏大学藏文信息技术研究中心,拉萨850000)
1 引言
藏文自公元7世纪创制以来,迄今已有一千三百多年的历史,目前仍是记录书写藏语的文字系统。无论作为传承藏民族传统文化的主要工具,还是作为我国藏族地区传播现代科技知识的主要工具,有其独特的人类文化价值,在藏族地区所发挥的巨大作用是不可估量的。千年来记载了各类历史记载、佛教经典编译,以及各种民间神话传说等。浩如烟海的藏文文献内容广泛,是我国除汉文之外,历史最悠久、文献最丰富的语言文化遗产。正是由于这样的原因,历史文化遗产的数字化,迫在眉睫。通过手工录入去保留这些文化遗产几乎是不可能的,而文字识别技术正是最好的选择。
大量的藏文经典主要以装帧的形式,一般文献呈现长条体,横向是书的宽度,纵向是书的高度,书页以活页方式构成,如图1所示。诵经阅读时,纵向往上翻起。
木刻藏文经书是雕刻的文字,在不同模板上样式相同,书写规则与标准藏文字完全相同,书写方向是从左向右,采用纵向叠加的辅音加上元音进行组合。但是木刻藏文经书大多为人工篆刻,人为因素干扰严重(见图2),再通过特殊的藏纸印刷,加上油墨的干扰,导致木刻藏文经书文中出现字符间粘连、断裂、遮挡现象,为识别带来极大的困难。
由于木刻藏文经书的特殊性,仅依靠字符切分、特征提取等方法已不能满足对木刻藏文经书的识别需要。通过研究发现,增加基于BP网络的训练方法,有助于提高木刻藏文经书的文字识别正确率。

图1 木刻经文样式

图2 干扰严重的经文字
2 BP网络算法描述
2.1 木刻经文文字识别的系统流程
木刻经文文字识别的整体设计流程为如图3所示。
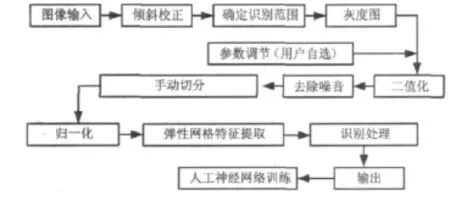
图3 木刻藏文经书文字识别流程
整体识别中主要算法有二值化、去除噪音、切分、归一化、特征提取、人工神经网络算法。特征提取与人工神经网络训练相同,区别在于:
(1)当识别结果与用户实际选择的结果不同时,调用人工神经网络算法,进行训练,收敛结果,然后修正保存的数据,以实现下步识别再遇到这个经文单元时,能够正确识别,提高识别率。
(2)识别处理采用一种加权误差均衡距离,定义两个特征矢量X,Y的距离函数为:

σ是方差,ε为10,α为8。序列中距离f最小的结果为最后识别出的结果字符。
2.2 BP网络训练
木刻经文样式、种类繁多,在进行特征提取过程中会对同一个字在不同印版的经书中提取不同的样本,这样每个经文字就对应了不同的经文样本,如图4所示两个一样的经文字,但其样式不同。

图4 2个木刻藏文样本字
在采用弹性网格特征提取后,每个样本形成了308维的特征数据,共计308×2=616维数据,如果全部保存并参与运算,则会导致整体识别的运算效率大大降低,也不能真正应用到实际识别过程中。这样就需要一套训练算法对这些数据进行训练,整合所有样本,获取多种样本共性的数据,更好的提高系统的鲁棒性。本项目通过研究各种参考资料,最后确定采用基于人工神经网络的改进的BP算法对整个样本进行训练,以便得出鲁棒性更强的、服务于识别的矢量数据。
人工神经网络具有良好的容错能力和自我学习能力,较传统识别技术有一定的优势,对于干扰复杂、识别难度大的经文识别系统,其应用会有效提高识别率和识别效率。
BP算法是神经网络技术中的典型算法,即向前计算-误差反向传播算法,采用广义的δ学习规则,是一种有导师的学习算法。其工作过程分两个阶段:
第一阶段正向传播阶段,将样本导入输入层,计算权重,然后将信息传到隐含层(可以多层)继续计算输出值和期望值,最后传入输出层。
第二阶段反向传播阶段,将网络的实际输出与期望输出相比较,如果误差不满足要求,将误差向后传播,即从输出层到输入层逐层求其误差(实际上是等效误差),然后相应地修改权值。
其算法的执行如下:
设 X1,X2,...,Xn是神经元的输入,θi是 Xi的阀值,Wij是Xi的权系数;Yi是Xi的输出,f是激发函数,e是误差函数;
(1)输入一个样本集,并进行编码,同时给定理想的输出信号Ti;
(2)设定权系数Wij,对各层的权系数置一个较小的非零随机数;
(3)计算各层的输出;
对于任意节点j,输出计算步骤为:
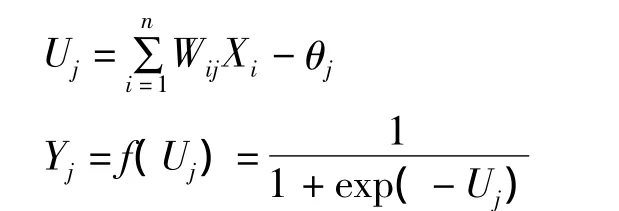
其中Uj是加权后的输入与节点阈值的总和;θj是节点j的阈值;网络中节点非线性的传输关系采用Sigmoid函数。
(4)求各层的学习误差:
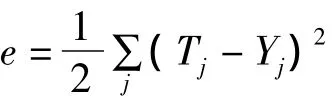
(5)误差反向传播,修正权值和阈值,从输出节点开始逐步向前递推,直到第一层,基于梯度下降法得:
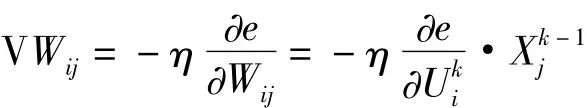
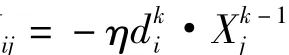
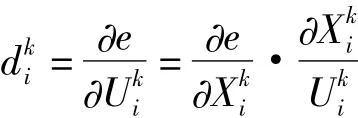
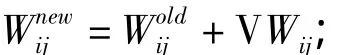
至此样本计算完成。BP算法虽然可以很精确地实现函数的逼近和模式的分类,但是从本质上讲,BP算法仍然是一种梯度算法,不可避免地存在一定问题,改变精度要求 ,将影响BP算法的计算次数,降低运算效率,不同样本有的收敛快,有的运算量大,不同学习速率也会影响运算效率等,因此在处理过程中需要对算法进行改进。
2.2.1 隐层单元数的选择
隐层单元数目k是应用BP算法的关键因素之一,k过小不能很好的收敛,过大则降低运算效率,也会产生多余特征,减低容错率。经过试验测试,BP算法隐层设定为两个隐层,隐层单元数采用两种数据处理,先取较大的k训练,然后取较小k,比对后去掉不起作用的隐层单元,具体表达式为:
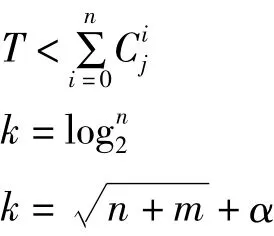
2.2.2 平滑更新权值
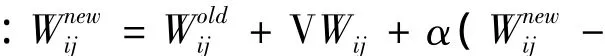
系统经过训练之后,得到新的经文单元数据,数据格式为:

保存所有单元数据,用于为识别系统提供数据基础。
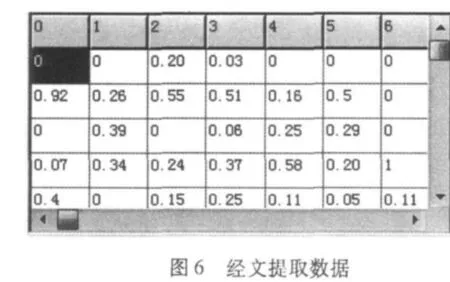
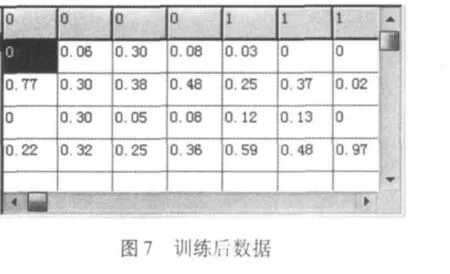
经文字的神经网络训练效果如图5,其下方数据图6为其对应藏经文字的特征提取数据中的288维网格数据。图7为提取后与原数据进行神经网络训练后更新的288维网格数据。
3 实验结果
木刻藏文经书文字识别界面如图8所示。实验共收集经书单个单元样本1643个,训练1643,通过批量样本测试程序测试,正常干扰情况下识别率为92.45%,严重干扰情况下识别率71.23%。


4 结束语
在字符切分、特征提取等文字识别方法基础上,提出基于BP网络训练方法的木刻藏文经书文字识别解决方案,基本实现了普通干扰情况下木刻经文识别率90%以上。当然,木刻经文由于干扰严重、印版断裂、字符粘连等情况导致识别难度特别大,现有的国际国内相关产品和资料都没有很好的方法予以解决,需要进一步的研究和试验,以更好的提高木刻藏文经书的文字识别率。
[1] 范立南,韩晓微.图像处理与模式识别[M].北京:科学出版社,2007.
[2] 吴佑寿,丁晓青.汉字识别-原理方法与实现[M].北京:高等教育出版社,1993.
[3] 李弼程,邵美珍,黄洁.模式识别原理与应用[M].西安:西安电子科技大学出版社,2008.
[4] 王勇,郑辉,胡德文.图像和视频中的文字获取技术[J].中国图像图形学报,2004,9(5):532-538.
[5] 冯宇平,戴明.一种基于角点特征的图像拼接融合算法[J].微电子与计算机,2009,26(7):21-28.
[6] 普次仁.多种印刷字体藏文字符的特征提取方法研究[J].西藏大学学报,2008,23(1):25-28.
[7] 王维兰.藏文基本字符识别算法研究[J].西北民族学院学报,1999,20(3):20-23.
[8] 王浩军,赵南元,邓钢铁.藏文识别的预处理[J].计算机工程,2001,27(9):93-96.
[9] 王维兰,丁晓青,祁坤钰.藏文识别中相似字丁的区分研究[J].中文信息学报,2002,16(4):60-65.
[10] 李永忠,王玉雷,刘真真.藏文印刷体字符识别技术研究[J].南京大学学报,2012,48(1):55-62.
[11] Ngodrup,ZHAO Dong cai.Research on wooden blocked Tibetan character segmentation based on drop penetration algorithm[C].CCPR 2010 Proceedings.IEEE Computer Society.2010:84-88.
[12] Ngodrup,ZHAO Dong cai,Putsren,Daluosanglangjie,LIU Fang,Bianbawangdui.Study on printed Tibetan character recognition[C].AICI 2010 Proceedings.IEEE Computer Society.2010:280-285.
