基于梯度向量的复杂场景文本定位*
2012-07-13杨高波朱宁波
杨高波,吴 潇,朱宁波
(湖南大学 信息科学与工程学院,湖南 长沙 410082)
视频包含的文本可提供重要的语义信息,视频文本的检测、定位和识别是实现基于内容的视频检索的基础.视频包含的文本可分为场景文本和人工文本2类[1].由于视频内容的复杂性和文本本身的不确定性,视频的字符文本检测和定位面临很多挑战[2].
现有的视频文本检测方法大致可分为3类:基于边缘和梯度的方法、基于连通域的方法和基于纹理的方法[1].第1类方法利用文本区域和背景之间的对比度,当背景比较复杂,例如包含树枝、栏杆等,存在较多的强边缘时,字符定位的效果不理想.第2类方法假定属于同一连通区域的文本像素具有相同的特征,检测算法相对简单,但是对于复杂背景或者同时包含人工文本与场景文本的视频,检测效果不够理想[3-4].第3类方法认为视频文本具有特殊的结构且表现出不同的纹理特性,利用Gabor滤波器、DCT纹理能量或者小波变换等计算图像纹理特征,再借助神经网络或者支持向量机进行文本区和非文本区的分类[5-7].该类方法对于文本像素和非文本像素之间的纹理差异有较高的要求,通用性不够强.
在基于梯度文本检测基础上,本文提出一种复杂场景下视频字符文本检测与定位方法.它综合运用运动矢量和字符的方向性特征,并利用视频文本的时间域特点进行文本区域的跟踪.
1 算法原理概述
字符笔画主要集中在0°和90°方向,以及少量的45°方向.因此,文本区域的图像边缘方向呈现U型的分布.由于背景的复杂性以及无规律性,背景区域的边缘方向分布与字符区域存在明显的差异.例如,当背景是杂乱无章的枝叶时,其边缘方向分布呈现近似均匀分布的特点.结合字符笔画的分布特点,本文综合利用文本梯度向量的幅度和方向,并结合其他文本特征,提出一种由粗到精的两阶段视频文本定位方法,原理框图如图1所示.粗检测时,利用加权平均梯度能量特征和运动能量特征,以去除大部分的非文本区.精检测时,则利用连通域分析和梯度方向分布的统计特征,滤除虚假的文本区域,得到最终检测结果.
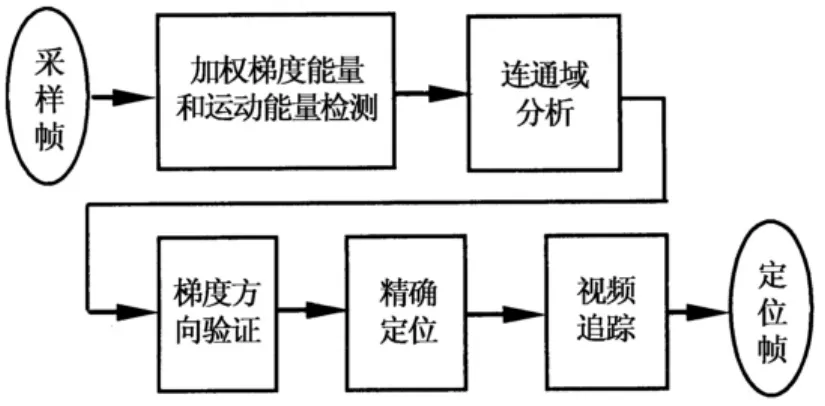
图1 算法流程图Fig.1 Block diagram of the proposed approach
2 算法实现
2.1 梯度能量和运动能量
文本区域与背景区域通常具有较强的对比度,且存在很多的笔画边缘,使得文本行具有较高的梯度能量.视频文本检测广泛使用基于梯度能量的方法.对于新闻等背景相对简单的视频,单独使用梯度能量能够检测出大部分文本区域.
图像的边缘有幅度和方向两个属性,沿边缘方向像素变化平缓,垂直于边缘方向变化剧烈.利用梯度算子可检测出图像的边缘点.假设Gx和Gy为图像fx,(y)的偏导数,梯度算子定义为:

首先计算各像素的梯度幅值GM和梯度方向GRO,再把视频帧分成16×16大小的块Block(i,j),计算每个分块内像素的加权平均梯度能量AVG.相对于8×8分块,16×16块样本像素点更多,抑制虚检现象效果更好.

式中:M为块大小;θ(x,y)为位置 (x,y)梯度方向.由式(2)可知,梯度方向越接近垂直或水平方向的像素,其权值越高,加权平均梯度体现了字符笔画的方向分布特点.此外,考虑到文本的加权平均梯度是区域相关的,可采用基于块的梯度能量滤波器进行滤波处理,以去除非文本块.为此,将所有的AVG组成一个滤波矩阵MAVG.对于新闻等大部分视频节目,它们的文本通常是静止的,字幕则出现在相对固定的位置.因此,对于这类特征的文本可使用运动能量ME特征进行检测.ME可定义为B帧或者P帧的宏块运动矢量的模,它的大小可描述相应位置的运动强度.MPEG运动估计算法采用基于块的匹配,运动矢量得到的运动能量通常不够精确,单独使用ME特征检测文本不合适.本文采用ME结合MAVG两个特征,在每个I帧检测文本块.其中,梯度能量特征来自当前I帧,而运动能量特征来自B帧.文本块Block(i,j)的确定规则如下:

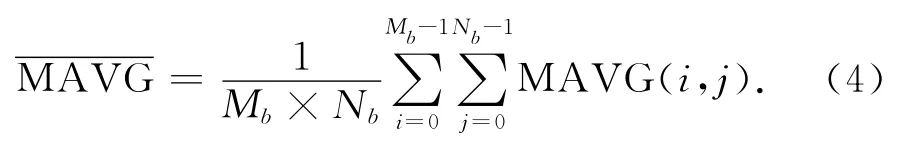
MTTh为最小梯度能量约束,以避免当背景区域比较平滑时出现虚检现象.本文设定MTTh=0.8,α=1.5.TME为ME的阈值,Mb和Nb分别为水平和垂直方向块的数量.
选取来自不同视频的两帧进行比较,分别表示背景变化迅速和相对平缓的情况,实验结果如图2所示.首先分别求取2幅视频帧的梯度能量图(图2(b))和运动能量图(图2(c)),然后对二者进行“与”操作可得到结合运动能量特征与梯度能量特征的效果图(图2(d)).可以看出,当背景运动时可以有效滤除噪声.
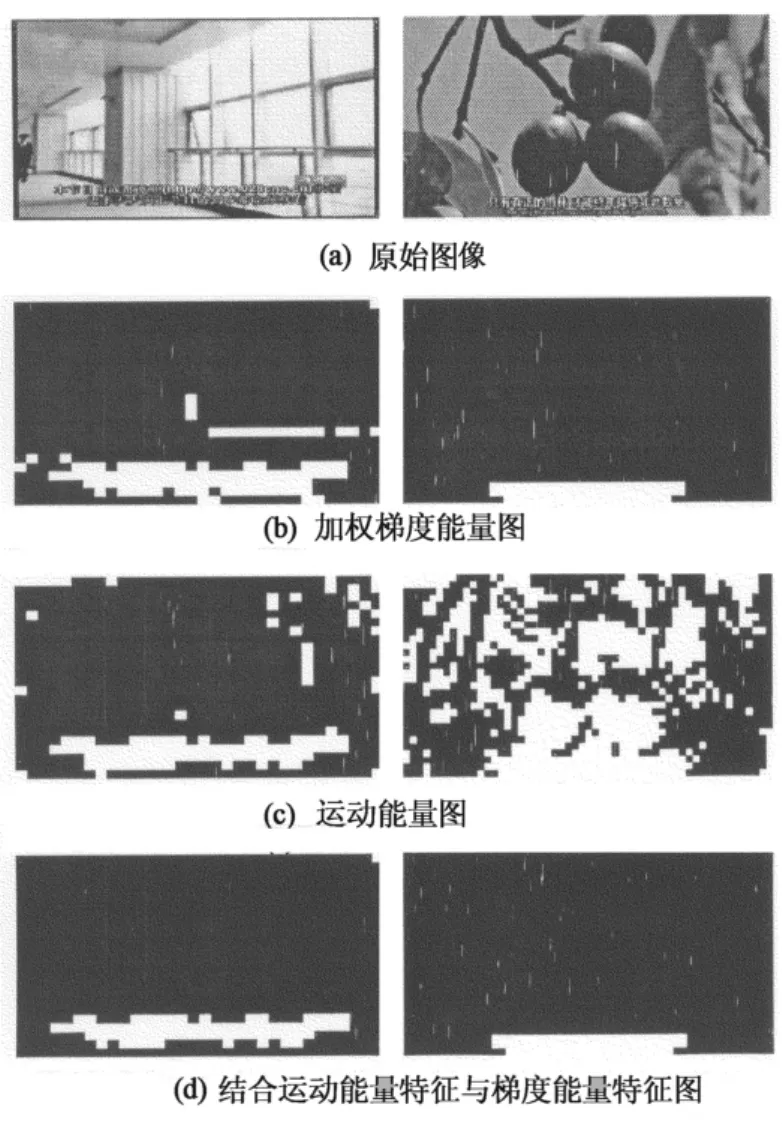
图2 梯度能量和运动能量检测分析Fig.2 Analysis of ME and MAVG
2.2 连通域分析
为了去除虚假的文本块,需要结合连通域分析.对检测到的文本块利用形态学操作形成连通分量,再提取连通分量的各种特征并融合,以区分文本和非文本的连通分量.通过比较各种特征的优劣,本文选用以下几种特征,判别文本和非文本连通分量:
1)字符的大小特征.文本区通常在图像中占有一定的比例.通过连通域的长、宽和面积等基本信息,可以表示字符的大小特征.假设Area(·)表示区域面积,w(·)和h(·)分别表示相应区域宽度和高度,W和H分别表示原图像宽度和高度,则可以定义最小长宽MinWH、最大尺寸比MaxLength_Ratio和最小尺寸比MinLength_Ratio以及面积比Area_Ratio如下:

长、宽信息在连通域提取时可以得到,上述特征计算简单.
2)字符的边缘密度特征.文本是由许多笔画组成的,在文本区域必然存在许多边缘象素点.文本区域具有很高的边缘密度(Edge_Density).因此,只有边缘像素密度高的区域才可能是文本区域,而那些像素稀疏的区域通常是噪声点.假设为连通域内边缘像素点的数量,边缘密度定义为:
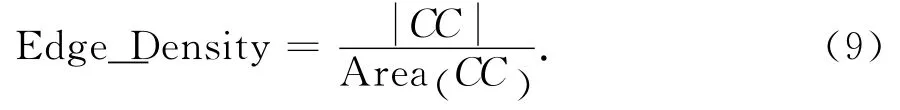
通过上述几种特征的提取,结合先验知识可有效地去除不符合字符特征的虚假文本区.实验时它们的阈值定义为:MinWH≥8,MaxLength_Ratio≤0.8,MaxLength_Ratio≤0.8,MinLength_Ratio≥0.1,Area_Ratio≤0.7和Edge_Densisty≥0.2.
2.3 梯度方向分布验证
对于背景复杂但变化缓慢的视频来说,仅仅利用梯度、ME以及连通域分析仍不能解决很多边缘丰富的虚假文本区问题,还需要参考其他鲁棒性能更好的特征进行验证.本文利用文本字符笔画的梯度方向特点,通过分析候选文本区的梯度方向分布,去除虚假的文本区.本文选用候选文本区的统计特征——均值mL和方差σL.当mL和σL都满足阈值要求时,可判定该候选文本区L(i)为文本区.均值mL和方差σL的定义如下:


选取一幅背景包含条形树枝以及丰富树叶的图像进行实验.设定mL和σL的区间分别为 (0.4,0.6)和 (0.1,0.15).实验结果如图3所示.通过梯度能量和连通域分析去掉大部分的非文本区,最终仅剩下3个候选文本区C1、C2和C3,如图3(b)所示.对它们的边缘像素求梯度方向分布图,得到相应的均值和方差,如图3(c)所示.最后,利用式(12)去除虚假文本区后得到的文本区,如图3(d)所示.
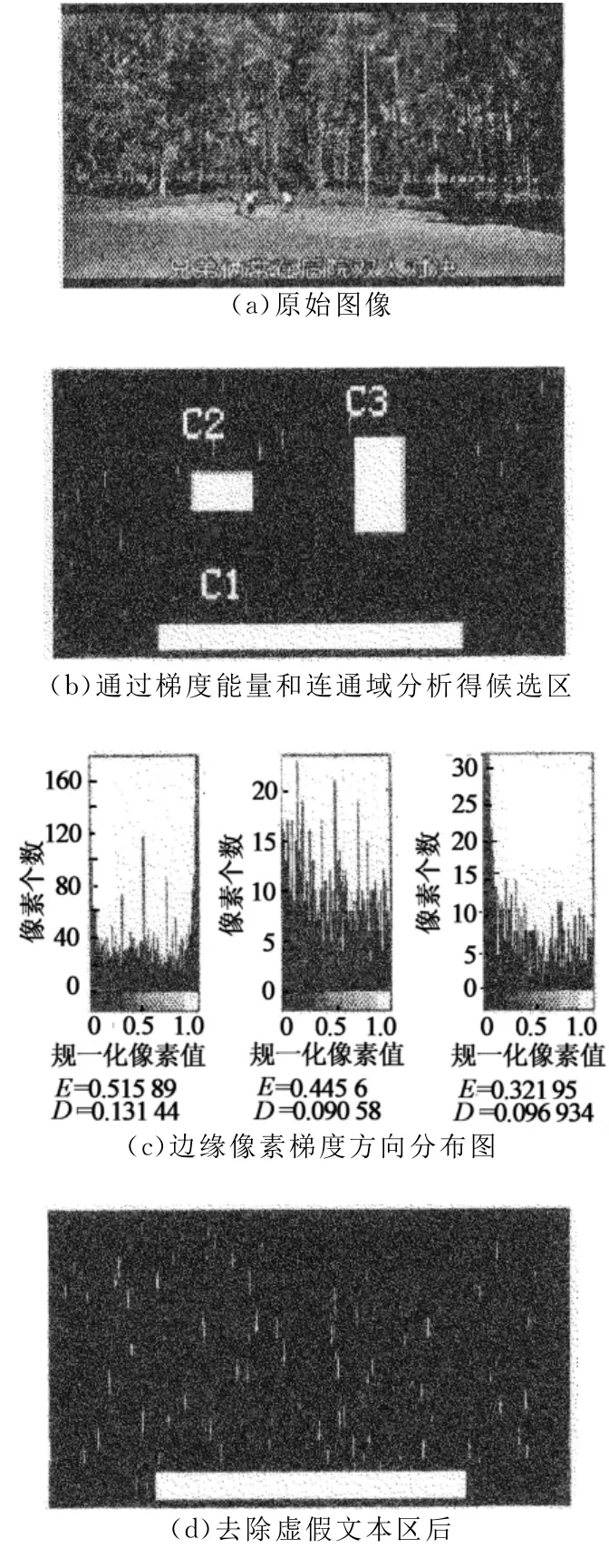
图3 候选文本区验证Fig.3 Candidate text region verification
2.4 视频文本追踪
视频包含的文本持续时间一般为2s以上,而视频的帧率通常为20~25帧/s.为提高效率,采样帧序列由每隔1s的采样获得,即每隔25帧采样一次.如果采样帧有文本区,以此帧为基础进行前向和后向搜索.以前向搜索为例,当该帧有文本区时,对该帧的前一帧的相应位置进行文本区匹配.如果前一帧的重叠度和相似度都满足阈值要求,则继续向前搜索,否则停止前向搜索.按同样的方法进行后向搜索.
假设RAi表示帧t的第i个文本区,RBj表示其相邻帧的第j个文本区.Overlap和Sim分别为它们之间的重叠度和相似度,定义如下:

文本匹配的准则如下:

式中:ThOverlap和ThSim分别表示重叠度阈值和相似度阈值,根据经验取值分别为0.8和0.5.
3 实验结果
为了验证本文提出方法的效果,选取3种不同类型以及不同背景复杂度的视频进行实验,如图4所示.视频大小分别为640×352,704×396和880×480,视频格式为AVI.本文采用常用的查全率和虚警率2个指标来验证算法的优劣.
文本定位的部分实验结果如图4所示.图4(a)的背景复杂度较低且字符区域对比度高,不需要经过梯度方向分布的验证亦可得到较好的定位效果;图4(b)的背景包含许多纹理结构类似字符的枝条,仅仅利用边缘梯度方法时很难将该类线条结构去除掉,往往需要利用梯度的方向信息进一步验证;图4(c)为本文算法对英文字符的检测和定位效果.从实验结果可以看出,本文算法对不同复杂背景的视频都取得了较好的文本定位效果,具体的实验数据如表1所示.
类似英文字符的语言还有法语、德语等,因此英文字符可以作为西方语言的代表,而中文字符则作为东方语言的代表.因此,本文算法对于东西方语言都具有很好的检测和定位效果.

图4 不同视频的文本定位结果Fig.4 Text localization for different videos

表1 不同视频的召回率和虚警率Tab.1 Recall rate and false alarm rate of different videos
4 结束语
本文提出了一种复杂背景视频的文本定位和检测方法.它利用视频序列的文本区域在对比度、边缘和笔画方向等多方面的特征,先采用加权平均梯度能量和运动能量特征进行粗检测,去除掉大部分非文本区.然后,采用连通域分析滤除部分虚假的文本区,对余下的候选文本区通过统计梯度方向分布的统计特征判别是文本区还是非文本区.此外,还根据视频中文本出现的特点进行视频文本跟踪.多种不同类型的视频实验结果表明,本文算法具有良好的文本定位效果.
[1]JUNG K,KIM K I,JAIN A K.Text information extraction in images and video:a survey[J].Pattern Recognition,2004,37(5):977-997.
[2]JIANG Ren-jie,QI Fei-hu,XU Li,etal.A learning-based method to detect and segment text from scene images [J].Journal of Zhejiang University Science,2007,8(4):568-574.
[3]程豪,黄磊,刘昌平,等.基于笔画和Adaboost的两层视频文字定位算法 [J].自动化学报,2008,34(10):1312-1318.CHENG Hao,HUANG Lei,LIU Chang-ping,etal.A twolevel video text localization algorithm based on strokes and adaboost[J].Acta Automatica Sinica,2008,34(10):1312-1318.(In Chinese)
[4]CHEN Xi-lin,YANG Jie,ZHANG Jing.Automatic detection and recognition of signs from natural scenes[J].IEEE Transactions on Image Processing,2004,13(1):87-99.
[5]QIAN Xue-ming,LIU Gui-zhong,WANG Huan,etal.Text detection,localization and tracking in compressed video[J].Signal Processing:Image Communication,2007,22:752-768.
[6]KIM W,KIM C.A novel approach for overlay text detection and extraction from complex video[J].IEEE Transactions on Image Processing,2009,18(2):401-411.
[7]MARIOS A,BASILIS G,IOANNIS P.A two-stage scheme for text detection in video images[J].Image and Vision Computing,2010,28:1413-1426.
