片上网络拥塞感知算法研究
2012-07-05才华杨勇李洋
才华,杨勇,李洋
(长春理工大学,长春 130022)
半导体技术的发展使一块芯片上集成了越来越多的功能,可以在一片芯片上实现系统级功能,形成片上系统。但是,随着深亚微米技术的发展,芯片内互联延时、信号线上码间干扰、芯片功耗和散热问题等日益严重。片上网络技术(Network on Chip NoC)[1]作为一种有效的解决问题新方法,日益得到人们的重视,通过基于互联的分布式处理,提高了处理性能,同时降低了现在集中式处理。
1 片上网络
片上网络改变了以往数字系统基于总线结构和全局时钟树的设计模式,采用片内分布式设计,片上网络系统由节点和节点间链路构成网络系统,其中节点除了具有处理器、存储器等具体硬件功能外,还包含一个具有转发功能的路由器。片上网络中的通信数据,以包的形式经过路由器和链路在节点间传递,网络拓扑、路由算法、流量控制是其片上网络体系中关键技术[2]。
1.1 网络拓扑结构
片上网络拓扑结构定义为在NoC网络环境下,链路和节点在物理结构上的组织排列,常用的拓扑结构如图1所示。拓扑结构决定了数据包交换的路径,是路由算法和流控策略得以实现的基础。
在拓扑结构中,每个节点与链路连接的数目,直接影响了片上网络中有效路径数量,路径丰富的拓扑结构,在相同注入率下,可以得到更短的时延,反之,网络容易发生拥塞,致使网络饱和。但是,在设计网络拓扑时,除了考虑网络性能外,还需要考虑实际制造的成本,尤其是片上互联线的密度和长度,以及由此带来的功耗和面积等问题。所以,在二维结构中,mesh和torus结构是常用的拓扑结构,现在也在研究三维拓扑结构[3]。

图1 片上网络常用的拓扑结构Fig.1 Topology in the network on chip
1.2 路由算法
路由算法是在特定的拓扑结构下为一条数据流选择从源节点到目的节点通过的路径。路由算法的选择是影响片上网络性能的重要因素之一,在设计路由算法时,要尽量使每个数据流在片上网络的链路上均匀分布,避免数据集中到某个节点或链路,产生拥塞,这样才能达到网络设计的最大吞吐率,常用的路由方法有X-Y路由,显式路由和自适应路由[4],Mesh拓扑结构下由节点A到节点B的三种路由如图2所示。其中黑色实心节点代表拥塞节点。

图2 片上网络常用的路由算法Fig.2 Network-on-chip routing algorithm
X-Y路由算法是一种简单的路由策略,数据流首先由源节点沿着一维方向(X维或Y维)到达目的节点所在的此维终点,然后再沿着另一维方向前进。显式路由算法在路由之前已经确定了源节点和目的节点之的多条路由路径,每次路由时随机选取其中
一条路径。X-Y路由算法和显式路由算法都没有考虑网络当前的状态,属于简单路由算法,即使是前进的节点发生拥塞,也按照既定的路由策略寻找路径。自适应路由是复杂的路由算法,自适应路由会根据当前网络拥塞状态,按照路由规则选择最佳路由路径。由于自适应路由算法只是根据当前节点信息判断路由策略,可能会引起死锁或活锁现象。因此,具有全局拥塞信息和拥塞感知机制的路由算法成为研究热点,本论文提出的就是具有全局网络状态信息的拥塞感知算法。
1.3 流控策略
流控策略定义为在片上网络环境中,如何为数据包在传输过程中分配带宽、缓冲容量等片上资源。一个节点中的流控过程如图3所示。
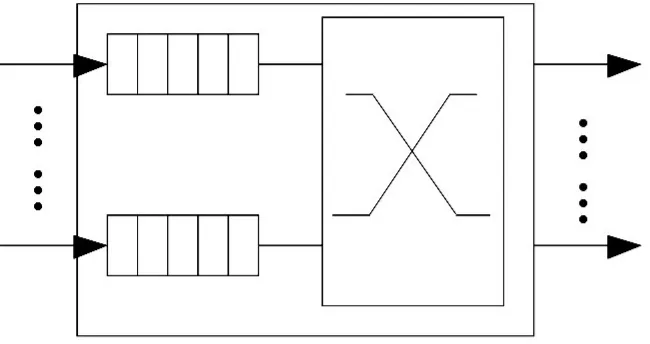
图3 一个节点内流控示意图Fig.3 Diagram of flow control in one node
在片上网络中,片上资源为缓存器、链路、状态寄存器等内容,流控策略就是要高效的分配这些资源,构成数据流传输时的逻辑链路,达到网络最大的吞吐量和数据包传输时最小的时延。根据缓冲使用程度,流控策略可分为[4],最简单的流控机制是无缓存机制,由于不能暂时存储,一次只能处理一个数据包,多余的数据包或者丢弃或者采用随机路由处理。电路交换是简单存储流控,电路交换机制中,只是存储数据包的头信息,通过数据包的头信息建立通信路径,在发生拥塞的节点,数据包的头信息会一直等到资源释放,直至建立完整的通信路径;最为高效的流控机制是基于缓存的存储-转发机制的流控,利用缓存去处数据的耦合性,同时可以采用虫洞交换和虚通道等技术,提高网络吞吐量。
2 基于神经网络的拥塞控制算法
片上网络中的诸多关键技术,目标都是追求网络的最大吞吐率和数据包传输最小延时。但是,当网络发生拥塞,会直接影响网络性能,因此,在拥塞控制中,会综合考虑网络拓扑、路由算法和流控策略。
2.1 现有拥塞控制算法分析
文献[5]提出了一种近似拥塞感知技术进行拥塞控制,这种方法是由路由节点的交换机接收临近节点交换机的流量压力信息,根据周围节点的通信状态,再做出本节点路由和流控的判断,采用这种方法避免拥塞区域的发生。但是,这种方法缺少全局信息,不能充分利用整个网络的整体资源和性能。文献[6]提出在缓冲区控制和带宽分配上进行拥塞控制,虽然这种方法能够在容错控制上分为不同级别,导致不同区域和功耗的权衡,但是逻辑控制稍显复杂。一个高效的拥塞控制机制,要能够根据网络中全局状态,使数据流均匀分布在节点和链路间,避免“热点”及其区域的出现。本文根据片上网络关键技术和神经网络可以并行化处理信息的特点,采用神经网络感知网络上数据分布状态,根据此信息,调整路由及流控策略,降低拥塞发生概率,达到网络最大的吞吐率。
2.2 基于神经网络的拥塞预测算法分析
神经网络提供一种可以进行并行信息处理的机制,由神经元及其之间互联构成。神经元是计算节点,互联完成计算节点之间的连接[7]。本论文采用采用两个步骤选择拥塞节点,第一部分是判断拥塞节点所在的维,利用多感知层神经网络结构,第一层为汉明网络,计算片上网络中每一维链路的资源使用状况,第二层竞争网,从汉明网中寻找资源使用最大的一维,第二个步骤是在确定的维中寻找拥塞节点。拥塞控制如图4所示。
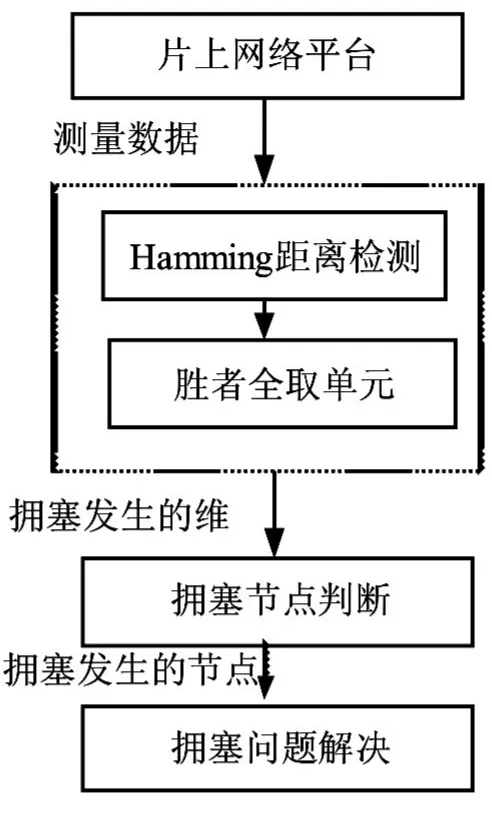
图4 拥塞感知控制流程图Fig.4 Diagram of congestion aware control
拥塞感知网络结构如图5所示。
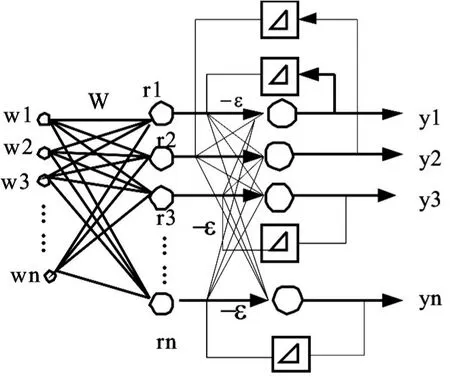
图5 拥塞感知神经网络Fig.5 Congestion-aware neural network
神经网络的输入为片上网络中某一维节点拥塞状态,权矩阵W为输入拥塞状态前一时刻状态值,初始状态为0,hamming网计算两者上取整差之后的hamming距离,得到中间节点,后面的竞争网络是除了反馈的权值为1外,其余的为-ε的Maxnet,经过Maxnet算子可以得到中间节点的一个最大输出[8],即得到片上网络通信过程中,数据流量增加最大的一维,然后在这维中,依次找到占用资源最多的节点,即可得到潜在的最可能发生拥塞的节点。
3 仿真结果与分析
在仿真分析中,采用SystemC建模,构建8×8 Mesh NoC模型,片上网络数据流模型采用均匀分布模型,即每个节点等概率发送数据包,路由算法采用改进的X-Y路由,当拥塞节点与路由方向在第一个前进维同向时,数据包临时转向另一维一次,避开拥塞节点;当拥塞节点与路由方向在第二个前进维同向时,路由算法令数据流暂存于所在节点,等待直至拥塞释放。
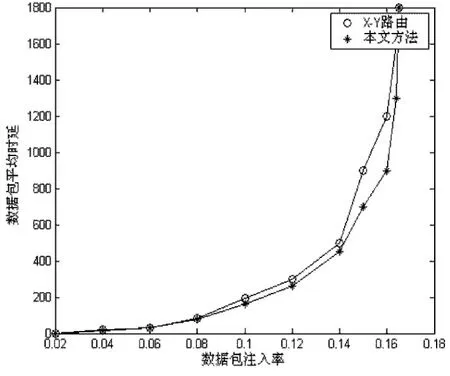
图6 数据包平均延时曲线Fig.6 Average delay of packet transmission
仿真比较了两种片上网络性能曲线,图6显示的是数据包传输延时与注入率关系,图7显示的是网络吞吐率与注入率关系,分别于标准X-Y路由进行比较。
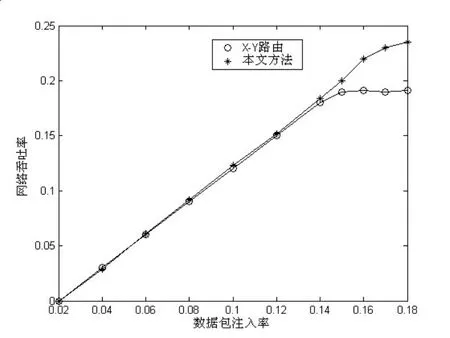
图7 片上网络吞吐率曲线Fig.7 Throughput of Network on Chip
在图6中,当在较低注入率时,由于网络空间很大,两者性能接近,在较高注入率时,网络接近饱和,网络平均时延都急剧增加,当处于中间状态时,能够进行拥塞感知的算法性能优于标准X-Y路由。在图7中,拥塞感知控制算法,带来15%关于网络吞吐率性能提高。
4 结语
本文提出的感知全局拥塞状态的方法,可以更加有效的提高片上网络性能,在中度饱和的网络环境,可以降低数据包传输时延,同时提高网络的吞吐率。
[1]K Goossens,J Dielissen.Aethereal network on chip:Concepts,architectures,and implementations [J].IEEE Des.Test Comput.,2005,22(5):414-421.
[2]A Hansson,K Goossens.A unified approach to constrained mapping and routing on network-on-chip architectures[J].in Proc.Int.Conf.Hardware/Software Codesign and System Synthesis,Sep,2005.
[3]JongmanKim.A noveldimensionally-decomposed router for on-chip communication in 3D architectures[J].Proceedings of the 34th annual internationalsymposium on Computer architecture,2007:138-149.
[4]William James Dally.Principles and Practices of Interconnection Networks[J].Morgan Kaufmann Publishers,2004.
[5]Nilsson E,Millberg M,Oberg J.Jantsch,A.Load distribution with the proximity congestion awareness in a network on chip[J].Design,Automation and Test in Europe Conference and Exhibition 2003:1126-1127.
[6]Pullini,A,Angiolini,F,Bertozzi,D,Benini,L.Fault Tolerance Overhead in Network-on-Chip Flow Control Schemes[J].18th Symposium on Integrated Circuits and Systems Design,pp,224-229,4-7 Sept.2005
[7]SmithsR.Adaptive Hybrid Learning forNeural Networks[J].Neural Computation,2004,16:139-157.
[8]Schmid,A.,Leblebici,Y.,Mlynek,D.Hardware realization of a Hamming neural network with on-chip learning[M].IEEE InternationalSymposium on Circuits and Systems.ISCAS,'98.pp.191-194,31 May-3 Jun 1998.
