基于维基百科和模式聚类的实体关系抽取方法
2012-06-29张苇如韩先培
张苇如,孙 乐,韩先培
(1. 中国科学院 软件研究所,北京 100190;2. 中国科学院 研究生院,北京 100049)
1 引言
信息抽取研究技术是人们获取信息的有力工具,是应对信息爆炸带来的严重挑战的重要手段。信息抽取的目标是从无结构自然语言文本中提取计算机可理解的结构化信息,其中一种主要的结构化信息是实体语义关系。例如,实体间的上下位关系(is-a)、局部—整体关系(part-of)以及更具体的作者—作品关系(author-of)、首都—国家关系(capital-of)等。实体关系抽取是自动知识本体构建的基础,同时也可应用到问答、信息检索等多个领域。
近年来,随着关系抽取任务逐步从限定领域走向开放领域,实体关系抽取研究主要关注如下几个要点: (1)抽取性能。抽取的实体对必须保证高准确率与召回率。由于本文研究面向开放文本的关系抽取,且以知识库构建为目标,所以准确率比召回率更为关键;(2)监督最小化。由于开放领域中关系类别数目巨大,且依赖于人工标注语料的方法耗费大量人力和时间,因此开放领域信息抽取主要关注如何减少或不使用人工标注来构建高性能抽取系统。目前大部分方法采用无监督的机器学习或信息冗余的自举迭代;(3)文本适用性。考虑到开放领域所面对的文本的多样性,抽取算法应能适用于不同风格、不同领域的自然语言文本;(4)关系的多样性。关系抽取算法的性能不能受限于关系类型,不仅在上下位(is-a)、同义(synonym)这样基本的语义关系上,而且在电影—导演(director-film)、出生日期(was-born-on)这些关系上也能取得好的抽取效果。
传统方法通常采用自举迭代的模式匹配方法在自然语言文本上抽取关系实例。在第一次迭代中,该方法使用少量的关系实例作为种子,利用实体共现信息在海量文本中寻找关系的句子实例,从而借助句子实例构建抽取模式,用以抽取新的关系实例。在下一次迭代中,新抽取的关系实例将被加入种子集合以构建新的抽取模式,进一步抽取更多的关系实例。
然而,上述基于模式匹配的方法有如下缺点。1)句子实例的获取过程依赖于实体识别的准确性, 因为不正确的实体识别会导致错误的句子实例识别;2)包含关系实体对的句子不一定准确表示目标关系,这就导致构造的模式可能是不显著或错误的,并因此造成整个迭代过程的错误传播,影响抽取结果。例如,在目标关系capital-of的抽取中,存在关系实体对“北京—中国”共现的句子“北京是中国的政治中心”,并未准确表示目标关系,若不加以区分会被错误地归于正例集合,从而降低抽取性能。
针对上述问题,本文充分利用维基百科的结构化特征,通过挖掘维基百科结构化数据生成句子实例,使得句子实例同时具有准确性和显著性。正如Medelyan等[1]所述,维基百科的结构特点恰好可以克服命名实体识别的问题。每一个维基页面代表一个概念即实体,在它的描述语句中出现的其他实体,以超链接的方式标注。利用上述特性,我们就可以自动地识别出实体对,且共现的实体对通常都是显著的。同时,为了进一步提升模式的可信度,我们提出了两个假设: 1)模式的显著性假设,表示一个关系的模式通常会在句子实例中出现多次;2)关键词假设,关系的模式通常以某个特定的关键词为核心。在此基础上,我们提出了基于关键词的分类和层次聚类算法,对模式进行过滤和泛化。
我们选取五种不同的关系进行抽取实验: 整体—部分关系(part-of)、材料—成品关系(production)、首都—国家关系(capital-of)、地理位置关系(located-in)、出生日期关系(was-born-on)。我们在中文维基百科及搜狗全网新闻语料库(Sogou_CA)上进行新实例对的抽取,大多数关系的抽取得到了良好的实验效果。
2 相关工作
早期的方法采用人工标注的数据作为初始输入,但这样做耗费大量的人力、时间成本。DIPRE和Snowball[2]使用少量的种子实例,通过自举迭代产生新的实例与模式。Ruiz-Casado等[3]将WordNet中的关系实例映射到Wikipedia中,并抽取实例出现的上下文作为输入。实验总共抽取出1 200 个新的关系对,正确率在61%~69%之间。Yan等[4]不使用任何先验知识,提出一种无监督的关系抽取方法,并借助维基百科及互联网语料进行聚类。
在提升模式质量方面,DIPRE和Snowball在每次迭代中,选取可信度高的实例加入正例集合,产生的模式在下一轮迭代中使用,其中,可信度高低由匹配到的模式数量决定。这种方法的问题在于对信息冗余的依赖性很大。由此,Pantel和Pennacchiotti[5]提出的Espresso 方法采用了Web Expansion策略,在整个Web上获取冗余信息来挖掘大量的文本模式,并利用互信息判断模式和实例的可信度。该方法的潜在问题是,Web上抽取的模式不一定能在当前领域的小数据集上可用。
在正例反例的区分上,Shchanek等[6]提出的LEILA包含发现、训练、测试三个阶段,在发现阶段,利用与先验知识产生冲突的关系实例生成反例。王刚[7]等提出了一种基于正例的关系抽取方法,用以在维基百科中抽取关系实例。
正如上一章所言,维基百科为信息抽取提供了一个非常适合的平台。我们借鉴Ruiz-Casado从人工标注知识体系到Web用户生成的内容文本(UGC)进行映射的思想,挖掘知网中丰富的语义关系,将其映射到维基百科。我们利用维基百科的结构化信息生成句子实例,解决实体识别的问题。为了进一步提升模式质量,我们提出了模式的显著性假设与关键词假设,利用基于关键词的分类、层次聚类算法对模式进行过滤与泛化。
3 关系抽取
我们提出的关系抽取策略共分为以下几个步骤。
1. 关系实例获取。在知网中挖掘潜在的语义关系实体对,作为关系抽取的实例种子。
2. 句子实例获取。利用实体消歧技术,实现《知网》到维基百科的实体映射,并利用维基百科的结构化特性挖掘句子实例。
3. 模式构建与挖掘。采用基于关键词的分类和层次聚类算法对模式进行过滤与泛化。
4. 新实例抽取。利用构建的模式,在自然语言文本中挖掘新的关系实体对。
3.1 关系实例获取
语义关系挖掘是指借助《知网》的概念描述体系,获取概念之间的潜在关系。除了本身所定义的16种显式关系外,《知网》中还存在大量隐式的语义关系。例如,在下面的概念描述中:
CPUpart|部件,%computer|电脑,heart|心
通过包含关系符号“%”,我们可以推断得知“CPU”是“电脑”的一部分。本文的目标是实体间的语义关系,因此我们更多地关注涉及命名实体的隐式语义关系。通过制定规则,我们从《知网》中挖掘出大量潜在的语义关系实体对。
3.2 句子实例获取
我们首先对维基百科数据进行如下处理: (1)所有的繁体字符转换为简体;(2)处理重定向页面之间的链接关系;(3)对于消歧页,将其释义关联到对应页面;(4)抽取每个词条及其对应文本,进行分词、词性标注及命名体识别。
为了实现实例映射,我们在维基百科中寻找 3.1 节得到的实体对,只有当关系实例中的两个实体都能与维基百科中的词条对应时,才进行映射。这样做是为了保证随后抽取的句子实例的质量,避免因为实体歧义造成的错误。沿用上面的例子,实体对(CPU,电脑)中的两个实体都能在维基百科的词条中找到。其中,如图1所示,“CPU”有多个义项。

图1 词条“CPU”的多个释义
我们采用一种基于字面匹配的算法Lesk进行消歧[8],并选取维基百科中的释义及知网中的描述作为消歧上下文。经过消歧,我们选取“中央处理器”义项。这种算法虽然简单,但是由于有丰富的解释性上下文,因此可以得到理想的实体消歧效果。
经过消歧与映射,我们得到了维基百科中高质量的关系实例,接下来,抽取其对应文本中共现的句子作为句子实例。之所以选择维基百科作为句子实例的数据源,是因为维基百科中包含大量结构良好的信息: 每一个维基页面表示一个主题,即实体,在文本中出现的其他重要实体,都以超链接的方式标注。利用这种超链接结构,我们就可以避免实体识别的错误,同时保证句子内实体对之间关系模式的显著性(维基百科只对重要实体进行链接)。
3.3 模式挖掘
为了构建关系抽取的模式,传统的启发式方法对句子实例进行词性标注,并用通配符替换实体对出现的位置来构建模式。例如,“北京是中国的首都”的模式构建结果为“object 是/v target 的/u 首都/n”。
但是,上述方法构建的模式有如下缺点: 1)通用性不足,需要泛化。例如,上述模式无法从句子实例“伯尼尔是欧洲联邦制国家瑞士的首都”中抽取出关系实例(尼泊尔,瑞士),尽管这两个句子的构造只有细微差别;2)准确性不足。这是因为仅仅基于共现得到的句子实例通常包含大量噪声和反例。例如,从“北京是中国政治文化的中心”中得到的模式并未表示北京和中国之间的capital-of关系。
为此,我们提出了基于关键词的分类和层次聚类算法。我们的方法基于下面两个假设: 1)模式的显著性假设:表示一个关系的某种模式会在句子实例中出现多次;2)模式的关键词假设: 模式通常以某个特定的关键词为核心。基于上述两个假设,我们利用基于关键词的分类与层次聚类方法,过滤可信度低的模式,并在此基础上对模式进行泛化。
3.3.1 关键词的选择
我们观察到,特定关系的模式通常是以关键词为核心的。例如,上下位关系中通常含有关键词“is a”,位置关系中可能含有关键词“位于”。基于关键词的分类能找到无论在语义还是结构上都相似的模式。基于上述分析,选择关键词是模式过滤与泛化的重要步骤。本文采用一种基于熵的特征选择[9]方法来确定关键词。其基本思想如下: 假设P={p1,p2,…,pN}为所有模式的集合,W={w1,w2,…,wM}为P中所有模式的词集合。本文利用如下公式计算P的熵值,其中,Si,j为pi,pj之间的相似度函数。
(1)
该方法从P集合中依次去掉W集合中的每个元素,计算得到{E1,E2,…,EM},进行排序,Ei值越大,则wi越重要。我们选取对E值提升贡献最大的K个名词或动词作为目标关系的关键词。
3.3.2 基于关键词的过滤
对特定的目标关系,本文首先对其候选模式进行基于关键词的分类: 按关键词的排序,包含该关键词的模式被归为一类,每个模式至多只能属于一个类。具体算法如下:
输入: 特定关系的候选模式集合P = {p1, p2,…,pn}, 关键词集合K = {k1, k2,…,km},
输出: 基于关键词分类得到的类Class= {class1,class2,…,classm};
Begin
初始化类的集合 Class = { class1,class2,…,classm} ( classi=∅ 1<=i<=m+1 )
fori∈[1,m]do
forp∈Pdo
ifp包含kithen
classi←classi∪{p} P.remove(p)
returnClass
End
包含同一个关键词的模式也可能有多种。例如,对于关键词“首都”,可能存在“object 是/v target 的/u 首都/n”,“target 的/u 首都/n 是/v object”等多种模式。因此,针对每个基于关键词的类,我们对其内部样本再进行层次聚类, 合并相似的模式,同时过滤出现频率较低的不可信模式。
具体算法如下:
输入: 基于某个关键词的模式集合P = {p1, p2,…,pn}, 阈值t1,t2
输出: 聚类后得到的簇Cluster={cluster1,cluster2,…};
Begin
初始化簇的集合 Cluster={cluster1,cluster2, clustern} ( clusteri= {pi} 1<=i<=n)
whilemin<=t1do
ifminclusteri,clusterjClusterdiscomplete-linkage(clusteri, …,clusterj) <=t1then
merge(clusteri, clusterj)
forcluster∈Clusterdo
ifsize(cluster) < t2thenCluster.remove(cluster)
returnCluster
End
距离的计算采用完全连锁(Complete-Linkage)即最大距离,保证一个簇中的模式两两之间都具有较高的相似性,其计算公式为:
max(d(a,b):a∈A,b∈B)
(2)
其中,d(a,b)表示模式a,b的编辑距离。
3.3.3 基于编辑距离的泛化
本文在普通的编辑距离算法基础上,加入词性的影响,具体公式如下:
其中
我们对Ruiz-Casado[3]的方法做出了一些改进,基于上面的编辑距离计算公式进行模式泛化。其基本思想是,在编辑距离矩阵中反向寻找编辑距离最短路径,同步进行保留、添加、删除、修改操作,最终得到泛化后的模式。
假设有如下两个模式:
object/nx 是/v 位于/v target/nx 南部/f 的/u 一个/NUM 州/n
object/nx 是/v target/nx 西北部/f 的/u 一个/NUM 地区/n
泛化后的结果如箭头所示,图2展示了编辑距离计算及模式泛化的过程。

图2 编辑距离的一个计算示例
3.4 新实例抽取
最后,我们利用生成的模式进行新关系实例的抽取。对象可以是维基百科也可以是其他语料或Web文本。一旦任意模式匹配成功,object和target所对应的实体就被作为目标关系的一个实例抽取。最终得到的结果将是新关系实例的列表。
4 实验
我们使用中文维基百科2011年1月10日的版本作为实验数据(总共包含714 682个词条),另外还加入了1.1G的搜狗全网新闻语料(Sogou_CA)。实验过程中,我们使用中国科学院自动化所开发的汉语分词、词性标注、命名实体识别一体化软件NlprCSegTagNer2.0对语料进行预处理。
实验分为三部分: 关系实例映射,模式性能验证,新实例抽取。
4.1 关系实例映射
为了验证《知网》中关系实例的挖掘性能以及从《知网》到维基百科的实体映射性能,我们选取了首都—国家(capital-of)、位置关系(located-in)、整体—部分关系(part-of)、材料—成品关系(production)、属性—宿主关系(attribute-host)以及出生日期关系(was-born-on)作为目标关系,结果如表1所示。前五种关系从知网中挖掘而来, 括号内是关系实例成功映射到维基百科中的比率。出生日期关系直接从维基百科的分类信息中得到。

表1 关系实例挖掘与映射数量
由表1数据,我们可以看出: 1)《知网》及维基百科的结构化信息中蕴含了大量的潜在关系实例,为抽取提供了良好的初始样本;2)《知网》和维基百科的数据存在大量冗余,特别是维基百科几乎覆盖了《知网》中的命名实体;3)命名实体消歧可以很好地实现《知网》到维基百科的映射: 对于有歧义的词,我们使用的消歧算法达到82%的正确率,且大多错误是由于维基百科本身不存在与之对应的概念造成的。
4.2 模式性能验证
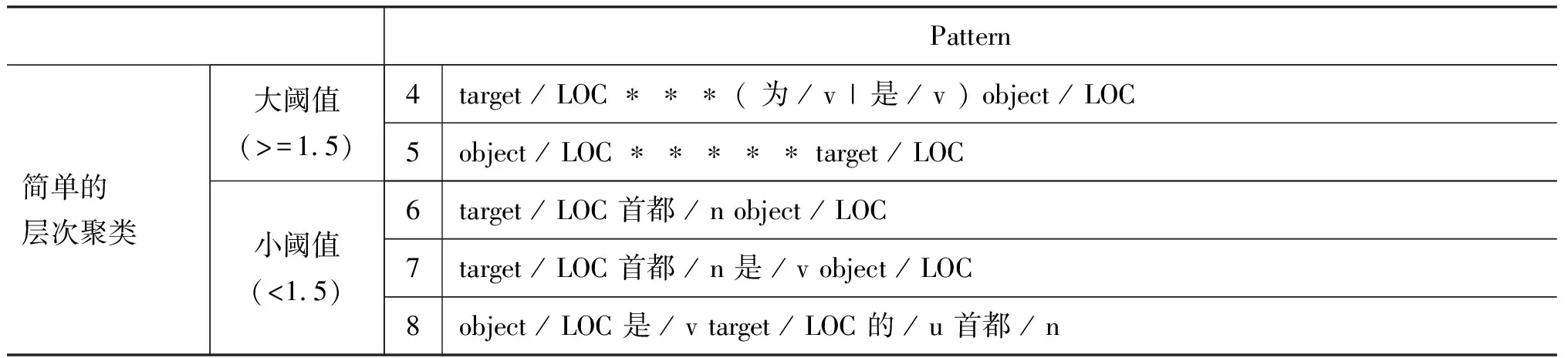
为了检验模式的性能,我们利用维基百科的结构化信息得到句子实例,进一步地通过基于关键词的分类与层次聚类算法过滤和泛化模式。表2是首都—国家关系(capital-of)的模式,其中,1~3是使用我们提出的方法获得的模式,4~8由一种简单的层次聚类算法生成。

表2 capital-of关系的泛化模式
续表
从表2可以看出,由于失去了关键词的依托,层次聚类终止条件的阈值设置较大可能造成过度泛化,包含大量反例与不显著的模式,因而影响准确性;而低阈值对模式的筛选过于苛刻,遗漏一些有用模式,降低了通用性。这一实验结果充分表明了,我们提出的基于关键词的分类与层次聚类算法能有效地进行过滤与泛化,得到通用且准确的模式。
4.3 新实例抽取

表3是在维基百科和搜狗全网新闻语料库上的实验结果。其中,capital-of关系在维基百科和搜狗语料中抽取的新实例个数分别占49%,57%;was-born-on分别占73%, 99%。其他关系在两个数据集上抽取的关系对基本完全不同于种子数据,即所占比率达到100%。
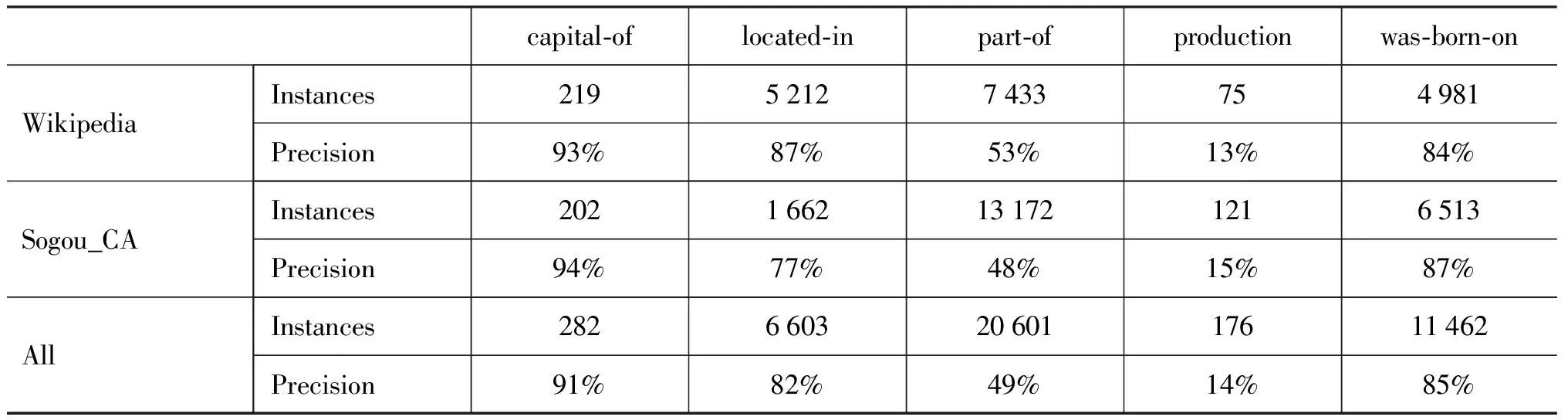
表3 抽取效果
分析实验结果,我们可以得到以下结论。
(1) 本文提出的方法能够取得良好的关系抽取性能
对于capital-of, located-in, was-born-on,无论是在维基百科数据集,还是在更为冗余的Web语料中,我们的方法都抽取出大规模高质量的关系实例。通过分析,我们认为高准确率得益于高质量的模式。这也就证明了利用维基百科作为句子实例的来源能有效地提高实体识别的准确性和显著性,而基于关键词的过滤与泛化策略能在模式的可信度和覆盖度之间取得好的平衡。尤其是对capital-of这种具体的关系类型,我们提出的方法非常有效,准确率在90%以上。少量错误源于特殊的上下文语境,例如,“许多人认为悉尼是澳大利亚的首都”。located-in关系在维基百科中的准确率较搜狗语料更高,是由于维基百科文本相对噪声较少。而was-born-on在搜狗新闻语料中反而得到更高的准确率,因为这种关系在搜狗语料中呈现的模式较为单一。例如,容易造成抽取错误的模式“target/ PER ( / w object/TIM ”在搜狗语料中出现的概率很低。
(2) 基于自举的模式构建方法并不适用于所有的关系抽取
实验结果中,Production关系抽取的准确率和数量都不理想。据我们所知,目前针对这种关系的相关研究也都没有取得比较好的实验效果。究其原因,这类关系很少在文本中以实例共现的形式出现,因此无法生成适当的模式用以抽取实例。
(3) 抽取效果通过深入挖掘能得到进一步提升
抽取到的实例中蕴含丰富的语义信息。对capital-of关系进行挖掘,我们能得到大量别名信息。例如,“华盛顿”、“华盛顿市”、“华盛顿特区”、“华盛顿哥伦比亚特区”等。Part-of, located-in关系可以进行传递,例如,LocatedIn(费城,宾夕法尼亚州)和LocatedIn(宾夕法尼亚州,美国)进行传递,生成关系LocatedIn(费城,美国)。在大量的part-of实例中,存在短语构成的实例对,如(千佛山,济南的三大名胜)。如果引入语法信息,增强对模式的约束,抽取效果能得到进一步提升。
5 结论及展望
本文提出了一种基于维基百科的抽取策略,旨在从开放文本中抽取高正确率的中文关系实体对。具体来说,我们首次提出了从人工标注知识体系知网到维基百科实体映射的方法获取关系实例,通过充分利用维基百科的结构化特性,我们的方法很好地解决了实体识别的准确性问题,产生了准确和显著的句子实例;进一步,我们提出了模式的显著性假设和关键词假设,在此基础上构建了基于关键词的分类及层次聚类算法,显著提升了模式的可信度。实验结果表明我们的方法无论是在数量上还是准确率上都达到了良好的关系抽取性能。
在下一步工作中,我们希望对关系实例进行进一步挖掘,以提升抽取准确率并获取更多语义信息。另外,我们还将尝试抽取其他类别的关系实例。
[1] O. Medelyan, D. Milne, C. Legg, et al. Mining Meaning from Wikipedia [J].International Journal of Human-Computer Studies, September 2009, 67(9): 716-754.
[2] E. Agichtein, L. Gravano. Snowball: Extracting Relations from Large Plain-Text Collections[C]//Proceedings of the fifth ACM conference on Digital libraries. New York, NY, USA: ACM, 2000: 85-94.
[3] M. Ruiz- Casado, E. Alfonseca, P. Castells. Automatic Extraction of Semantic Relationships for WordNet by Means of Pattern Learning from Wikipedia[J] .Natural Language Processing and Information Systems 2005, 3513: 233-242.
[4] Y. Yan, N. Okazaki, Y. Matsuo, et al. Unsupervised Relation Extraction by Mining Wikipedia Texts Using Information from the Web[C]//Proceeding of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2.
[5] P. Pantel, M. Pennacchiotti. Espresso: Leveraging Generic Patterns for Automatically Harvesting Semantic Relations[C]//Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics, 2006:113-120.
[6] F. M. Suchanek, G. Ifrim, G. Weikum. LEILA: Learning to Extract Information by Linguistic Analysis [J]. ACL, 2006:18-25.
[7] G. Wang, Y. Yu, H. Zhu. PORE: Positive-Only Relation Extraction from Wikipedia Text. Lecture Notes in Computer Science[C]//Proceedings of Lecture Notes in Computer Science, 2007, Volume 4825:580-594.
[8] Kilgarriff, J. Rosenzweig. English SENSEVAL: Report an Results.[C]//Proceedings of the 2nd International Conference on Language Resourcesand Evaluation, LREC, Athens, Greece. 2000.
[9] J. X. Chen, D. H. Ji, C. L. Tan, et al. Unsupervised Feature Selection for Relation Extraction[C]//IJCNLP, 2005.
[10] F. M. Suchanek, G. Kasneci, G.Weikum. YAGO: A Core of Semantic Knowledge Unifying WordNet and Wikipedia [J]. Proceeding WWW ’07 Proceedings of the 16th international conference on World Wide Web,2007:697-706.
[11] F. M. Suchanek, G. Ifrim, G. Weikum. Combining linguistic and statistical analysis to extract relations from web documents [J]. Proceeding of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, 2006:712-717.
[12] M. Banek, D. Juric, Z. Skocir. Learning Semantic N-Ary Relations from Wikipedia [J]. Database and Expert Systems Applications 2010, 6261:470-477.
[13] D. P. T. Nguyen, Y. Matsuo, M. Ishizuka. Subtree Mining for Relation Extraction from Wikipedia[C]//Proceedings of NAACL-Short ’07 Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion: 125-128.
[14] J. X. Huang, P. M. Ryu, K. S. Choi. An Empirical Research on Extracting Relations from Wikipedia Text [J]. IDEAL Intelligent Data Engineering and Automated Learning-IDEAL 2008, 5326: 241-249.
[15] 王刚.自动抽取维基百科文本中的语义关系[D].上海交通大学硕士学位论文,2008.
[16] 董振东, 董强.《知网》[EB/OL]. http://www.keenage.com.
