多信息融合的新闻节目主题划分方法
2012-06-29余骁捷孔繁庭李树森
余骁捷,吴 及,孔繁庭,李树森
(1. 清华大学 电子工程系,北京 100084;2. 甘肃联合大学 电子信息工程学院,甘肃 兰州 730000)
1 引言
新闻节目通常包含多个新闻故事单元,用户在检索时关注的是某一新闻事件,利用节目名称以及播出时间等信息的存储与索引方式缺乏对音频内容信息的结构化描述,难以满足基于新闻故事内容的检索需求。新闻节目的主题划分技术能够检测新闻播报节目中具有不同主题的故事单元边界,根据主题内容将新闻播报节目分割成故事单元,对于实现新闻故事的主题分类管理和内容信息检索有着重要的意义。
随着计算机技术及网络技术的飞速发展,来源于广播、电视以及网络的新闻类音频数据也越来越丰富。采用人工标注新闻故事单元不仅费时费力,标注的格式和标准也难以统一,为此迫切的需要对新闻节目的故事单元进行自动划分。新闻播报节目的自动主题划分技术能够依据节目的语义信息和音频信息,自动提取各新闻故事之间的边界线索,将新闻节目划分为不同的故事单元。
现在的新闻播报节目以音频和视频为主要载体,其中的视频信息、音频信息以及语音识别文本等都可用于自动划分单元划分。视频信息包括镜头的切换,主题字幕提示,主持人以及演播室的镜头边界等,目前有许多相关方面的研究[1-2];音频中的停顿、播音员声纹特征[3]也可以用于寻找故事边界;语音识别文本中包含有节目内容的语义,可以使用基于规则方法,例如,使用深度值的TextTiling算法[4]、使用词汇链计算边界强度的SeLeCT(Segmentation using Lexical Chaining on Text)算法[5]等进行基于文本的主题划分,傅间莲等采用基于连续段落相似度方法[6]进行主题划分,杨玉莲等提出了一种基于子词链的新闻故事单元自动分割方法[7],使用投票法融合不同级别词汇,F-估值比传统词链方法提高9.04%。同时还有一些基于统计的方法,例如,局部上下文分析法(LCA),隐马尔可夫模型(HMM),指数模型等方法[8],文献[9]中使用了指数模型和决策树融合的方法,在TDT测试集上错误概率Pk达到7.8%。
上述的信息有它们各自的适用范围,为新闻故事单元分割提供了多种途径。但是单一来源的信息不足,不能达到令人满意的分割结果,为了提高系统性能,需要使用多信息融合的方法。对于新闻视频节目,在使用融合视频、音频和文本多信息的分割方面已开展了大量的研究,文献[10]中利用镜头检测、关键帧技术,以及音频类型信息及说话人切换检测,结合OCR技术识别画面上的字幕文本,综合得到分割结果,文献[11]利用最大熵模型融合不同层次的特征得到分割结果,F-估值达到76%,该方法提取视频的动作、人脸、音频的类型、韵律信息和语音识别结果,复杂度较高。这些研究中视频的信息都起主导作用,音频信息作为辅助特征没有得到充分的挖掘和利用。对音频中的语音数据进行语音识别,可以得到包含语义的文本信息来进行主题划分,目前的特征融合方法,对识别文本提取常用文本特征,但并没有特别针对语音识别错误采取有效措施。使用词汇链的SeLeCT算法通过串联文本中的词汇,有效的避免了识别错误带来的词汇失配问题,同时音频中的类型、韵律等信息对于广告、体育比赛、天气预报以及新闻片头等检测时效果较好[12],根据语音识别结果中的语义信息和音频信息各自对于主题划分的优势,可以设计规则来融合不同层次的信息,以达到较好的分割性能。
本文设计了一种多信息融合的新闻节目的自动主题划分方法。对于新闻播报类节目的音频数据,利用语音识别结果文本中的语义信息作为主题划分的主要依据,首先通过自动分段得到一系列间隔点作为主题划分候选点,根据语音识别结果的特点,利用改进的SeLeCT算法进行基于文本的主题划分,同时结合候选点邻域内的音频类型信息,例如,静音、音乐等,设计了一套基于规则的信息融合方法,从而完成故事单元的分割。第二部分介绍了使用语音识别结果的语义信息进行主题划分的方法,第三部分介绍了用于主题划分的音频信息,第四部分介绍了信息融合的规则,最后给出了划分结果并分析划分性能。
2 用于主题划分的语义信息
为了充分的利用音频数据中的信息,我们对音频信号中的语音数据进行识别,利用得到的识别结果进行基于语义信息的主题划分。自动分段模块会将音频文件按句切分以达到较好的识别效果。由于故事单元的边界一般也都是语句的边界,所以自动分段得到的切分点可以作为故事单元边界的候选点。
2.1 改进的SeLeCT算法
目前的语音识别系统很难保证识别的结果完全准确,错误的识别结果会对利用相似度或深度等的文本主题划分系统造成很大的影响,而SeLeCT算法[5]统计文本中的词汇链(Lexical Chain),计算边界候选点处的边界强度,从而进行文本主题划分。词汇链是在基于词汇的语义关系构成的上下文中的词序列,可以使不相邻的语句得以连通,从而在一定程度上减少了错误识别结果的影响。
语音识别的结果按音频自动分段模块得到的分段点切分成句。采用中国科学院计算技术研究所的汉语词法分析系统ICTCLAS[13]对识别文本进行分词并标注词性,根据词性对于故事主题的代表性,选取其中的名词和动词,相同的词汇在符合句子间隔距离的限制下串联起来,构成词汇链,表示为如下形式:
{词汇|起始句序号,结束句序号}
两个不同新闻故事边界处的词汇链开头和结尾的点具有高度密集性,即词汇链的开始和结束越集中的地方,越有可能是事件划分的边界。根据词汇链的首尾信息可以计算边界强度。边界强度的计算方法较为灵活,Stokes等人根据划分性能采用求和计算[5],即定义每个段落之间的边界强度w(n,n+1)为: 以第n个句子结束的词汇链的个数与以第n+1个句子开始的词汇链的个数之和。
w(n,n+1)=N(En)+N(Sn+1)
(1)
式(1)中En为以第n句结束的词汇链集合,Sn+1是以第n+1句开始的词汇链集合,N(*)表示集合元素个数。
根据在中文新闻语音测试数据的划分性能,我们对边界强度的计算方法加以改进,采用第n个句子结束的词汇链的个数与以第n+1个句子开始的词汇链的个数的加权和,即:
其中wi是第i个词汇链的权值:
Nlc是整个新闻节目中出现该词汇的词汇链个数,N是识别文本的词汇链总数。原有的求和计算方法可以认为是wi=1时的特例。通过这种权重计算方式,只在某个故事中出现的词汇链会比在大部分故事单元中都出现的词汇链获得更大的权重,即更具代表性。
边界强度越大的候选点越有可能对应真实的边界点。因此可以设定阈值,当某候选点的边界强度大于该阈值时将被判为边界点,否则为非边界点。在此设置高低双门限,分别用thH和thL表示:
(4)
其中E(w)为边界强度的均值,σ(w)是标准差,k是常数。双门限的用途在融合规则中具体说明。
2.2 过渡性语句模板
另外新闻播报类节目通常都有相对固定的结构编排,所以主持人在播报时会使用相同或相近的过渡性语句,这些语句通常代表着播报主题内容的切换,我们总结出一个主题切换提示性语句模板,在根据文本内容划分时首先检测这些模板句,如果发生匹配,则直接判断为故事单元的边界。

表1 主题切换提示性语句模板
3 用于主题划分的音频信息
新闻音频中的声音事件转换对于故事单元划分提供了有效的信息,包括音频类型、说话人切换等。本文选取主题边界候选点邻域的音频类型,作为用于主题划分的音频信息。
新闻故事单元在切换时,通常会有较长时间的静音,或使用音乐作为过渡,以《新闻联播》节目为例,选取了三天的标注数据,对其主题边界的音频类型进行统计,结果如表2所示。
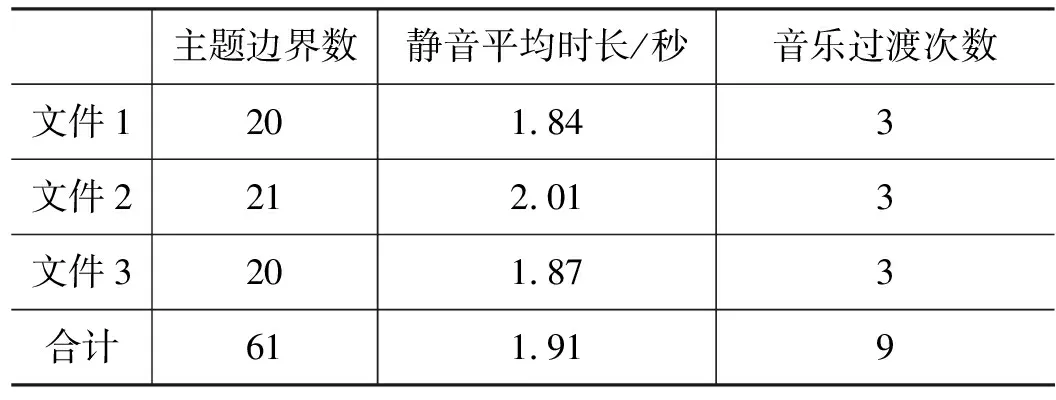
表2 《新闻联播》主题边界音频类型统计
《新闻联播》节目的栏目相对固定,所以以音乐过渡作为主题边界的次数也是固定的,对于以静音分隔的故事单元边界,统计其平均长度约为1.91秒,而语音中正常的句间停顿则相对较小。
在自动分段时得到了一系列主题划分的候选边界,根据上面的统计结果,我们可以在候选边界点的邻域片段中提取音频类型信息,使用GMM进行音频类型判断得到相应的信息作为主题划分的依据,当某个候选边界点的邻域出现音乐或长时的停顿时,这里可能会是故事单元的边界。
但是同一个新闻故事单元中,场景或说话人的切换的也可能出现较长时间的静音停顿,所以单独使用这些音频信息会出现很多虚警。
4 语义信息和音频信息的融合规则
识别结果和音频信息都有其局限性,单独使用就不足以得到很好地切分效果,为此我们设计了一套信息融合规则,有效的综合文本语义和音频信息进行处理。
首先对候选边界点进行预处理。自动分段得到的结果语句长短变化较大,每句包含的信息量不一致,这会改变词汇链的生成结果,从而对边界强度的计算造成一定的影响,因此我们希望能够尽量使句子包含的信息量一致,即希望句子长度能够向着长度一致的方向有所调整。为此对候选边界点的邻域音频类型做初步判断,如果该邻域音频是语音,则对语句进行合并。这样可以使平均的句子长度变长,从而使处理单元的信息量呈现平均的趋势。由于后面还将结合语义信息进行划分,为了保证这一步不把真实的故事单元边界过滤掉,采用较小的邻域长度L0。
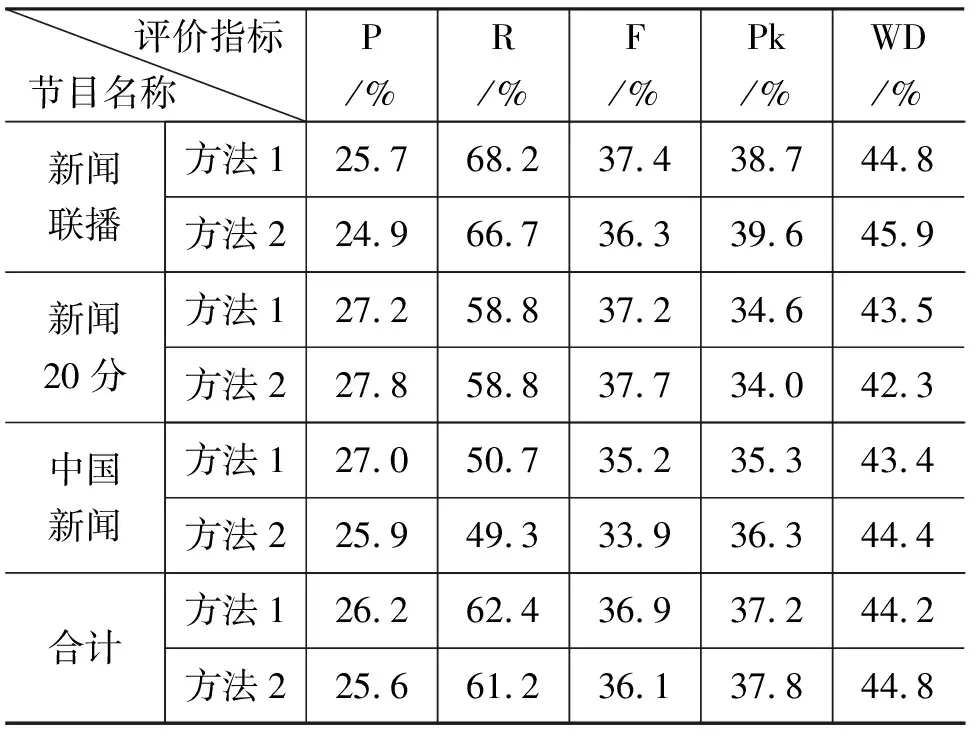
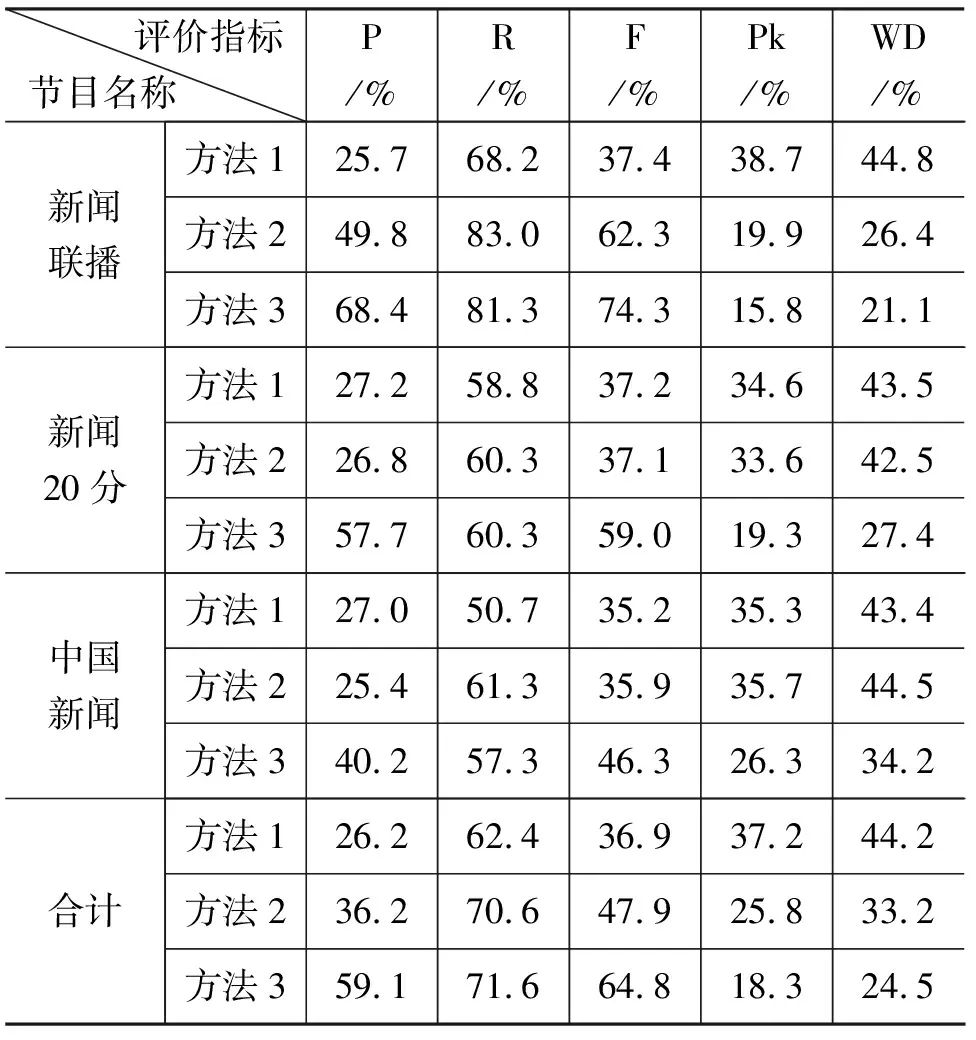
然后从文本和音频两方面查找最可能是主题边界的音频分段点。音频信息方面,候选边界点的邻域出现长度大于LM的音乐片段则可以直接判定为故事单元的边界;文本中如果出现提示性语句,或者使用SeLeCT算法中计算得到的边界强度大于高阈值thH,说明此处语义信息较强,可以直接判断为故事单元边界。如果边界强度大于thL而小于thH,则判断为可能的边界,再采用的邻域长度L1(L0 图1 语义信息和音频信息的融合规则 信息融合规则如下(图1): 1) 对于某一边界候选点,如果它的前句中出现提示性语句,则判断为故事单元边界; 2) 如果某一边界候选点处计算得到的边界强度大于高门限thH,则判断为故事单元边界; 3) 如果某一边界候选点的邻域长度大于LM,且音频类型为音乐,则判断为故事单元边界; 4) 对于其他的边界候选点,如果边界强度小于thH且大于低门限thL,且该边界候选点的L1邻域音频类型为静音,则判断为故事单元边界; 5) 不满足上述条件的边界候选点不是故事单元的边界。 实验数据采用CCTV的《新闻联播》、《新闻二十分》和《中国新闻》节目,其中以《新闻联播》节目为主,长度约300分钟,《新闻二十分》和《中国新闻》各约100分钟,采用人工标注得到主题划分的真实结果。 包含以上三类节目的实验数据集语音识别字正确率约为83.9%。 5.1.1 精确率、召回率和F-估值 准确率(Precision)、召回率(Recall)以及F-估值(F-measure)是信息提取方面最基本的评测指标,在主题划分方面的定义为: 这三个指标能够在一定程度上反映系统的主题划分性能。但是这些指标不能反映那些接近边界的错误,即将划分对与错界定的特别明确,举例来说,系统识别的边界与真实的边界间隔一句或间隔多句所体现的系统性能应当是不同的,这套评价指标无法表现出来。 5.1.2 Pk 为了解决以上指标不能充分反映分割性能的问题,Beeferman等人提出的新量度Pk[9]逐渐成为衡量分段性能的标准。Pk表示随机抽取间隔k个处理单元的处理单元对,判断其属于同一单元片段或者属于不同单元片段的概率,定义如下: 式中,δref(i,i+k)和δhyp(i,i+k)为指示函数,表示在分割模式中,i和j对应的处理单元是否属于同一主题,是则为1,否则为0。0≤Pk≤1,当算法或系统得到的分割边界越准确时,得到的Pk值越小。 5.1.3 WindowDiff 用Pk衡量分割性能仍存在一些问题,例如,漏检的错误比虚警要对Pk值的贡献更大,同时接近正确边界的错误对Pk值的贡献度过大等。针对这些不足,Pevzner和Hearst提出了改进的评价指标——WindowDiff[14]。 其中,b(refi,refi+k)代表标注结果中i和i+k对应处理单元之间的边界数量,b(hypi,hypi+k)代表系统划分结果中i和i+k对应处理单元之间的边界数量,I(*)为示性函数,当|b(refi,refi+k)-b(hypi,hypi+k)|>0取1,否则取0。 0≤WindowDiff≤1,当算法或系统得到的分割边界越准确时,得到的WindowDiff值越小。 SeLeCT算法中边界强度的计算方法根据测试集上的实验结果来确定,实验中使用了文献[5]中的求和方法以及修改的加权和方法,对比结果如表3所示。 方法1: 使用加权和计算边界强度,对语音识别结果做主题划分。 方法2: 使用求和计算边界强度,对语音识别结果做主题划分。 在计算边界强度门限时,根据划分性能将常数k设为0.7。 P,R,F,Pk,WD依次为5.1节中所述的各项评价指标。 表3 不同边界强度主题划分性能对比 从结果中可以看出,《新闻联播》和《中国新闻》节目中使用加权和计算边界强度的SeLeCT算法在划分性能上略高于使用求和计算边界强度,尽管《新闻二十分》节目使用求和计算边界强度的方法划分性能更高,但是根据总体的性能我们选择了使用加权和计算边界强度的SeLeCT算法处理语音识别结果文本。 对于语音识别文本,自动分段导致句子的长度和实际句子不一致和语音识别错误都会影响词汇链的长度,导致词汇链变短,从而边界强度的峰值出现频繁,得到的主题段落偏多,所以精确率较低。 为了说明语义信息和音频信息的融合规则 方法1: 单独使用语义信息做主题划分,即前述实验中的方法1。 方法2: 使用音频类型信息做主题划分,这里采用语音自动分段点邻域的类型作为判据,当出现非语音时即为主题边界。 方法3: 根据规则融合语义和音频信息进行主题划分。 使用音频信息划分时,主题边界候选点邻域长度为1.6s。信息融合时使用的参数,L1为1.6s,LM为4s,L0为1.4s。 上述方法的划分性能如下(表4): 表4 信息融合前后主题划分性能对比 采用音频类型信息进行主题划分有着较高的召回率,精确率仍偏低,这一结果符合预期,由于采用了长时停顿和音乐作为划分依据,节目中播报员和记者的语速相对稳定,但被采访人说话时需要思考,容易出现较长的停顿,从而被判断为主题边界,造成虚警。 通过总体结果的对比可以看出,融合了语义信息和音频信息的主题划分方法相比于单独使用语义信息,F-估值提高了27.9%,Pk和WindowDiff分别降低了18.9%和19.7%,相比于单独使用音频信息,F-估值提高了16.9%,Pk和WindowDiff别降低了7.5%和8.7%,主题划分性能显著提高了。音频信息的引入消除了采用语义信息进行划分时部分较小的边界强度峰值带来虚警,使得精确率上升,弥补了语音识别结果文本不准确导致的SeLeCT算法的划分错误,同时音乐信息的引入定位到了语义信息没能检测到的边界,降低了漏检。同时语义信息也能在一定程度上消除音频信息的中被采访人语音长时停顿带来的虚警。信息融合效果明显。 《新闻联播》节目作为一个十分正式且受人关注的节目,其组织结构相对比较严整和清晰,故事单元之间的停顿和音乐过渡都有严格的规范,音频信息明显,单独采用音频信息进行主题划分时性能较好。 《新闻二十分》和《中国新闻》的划分性能略低,因为这两者的组织结构远不如《新闻联播》清晰,识别结果也不够准确。这些节目中含有比较多的外景采访,这对于语音识别来说是比较困难的,同时由于采访人语音停顿较长的特点,在音频信息的利用方面也有比较大的影响,单独使用音频信息进行划分性能明显低于《新闻联播》。另外节目中一些栏目出现的背景音乐,以及栏目中插播的广告,都会对主题划分造成一定的影响。 F-估值反映了一种划分的正确程度,使用1-F-估值定义相应的错误程度衡量,可以与其他的两种评价指标进行比较。可以看到,虽然《新闻二十分》和《中国新闻》在F-估值的评价下与《新闻联播》相差不小,但在Pk和WindowDiff的评价体系下差距没有那么大,这是由于前者的组织结构不够清晰,使得划分结果会更多的出现小范围的偏差,虽然确实找到的故事划分的边界,但是并不准确,这在F-估值的评价系统中被认为是完全错误的,而在后两种评价指标中给予了一定程度的肯定。 在引入信息融合规则后,Pk和WindowDiff的相对提升比F-估值要高,这说明信息融合更多的修正的是在Pk和WindowDiff下贡献大的错误,也就是大范围的边界偏差,根据这种现象,后续我们可以研究小范围偏差的特点并进行一些针对性处理。 本文设计并实现了一种多信息融合的新闻节目自动主题划分系统,初步完成了音频的自动主题分割。 目前系统对音频信息的利用比较简单,后续可以考虑提取音频中其他可用于主题划分的声音事件,例如,说话人变换,韵律等信息,完善音频处理模块。同时,可以考虑结合不同的信息融合方式,例如,可以将多种语义信息和音频信息分别量化,构成特征向量,使用统计方法进行划分,并在此基础上针对错误的具体情况引入一些规则加以处理,以得到更加准确的新闻故事单元划分。 [1] Liu Hua-yong. News story automatic segmentation based on audio-visual feature and text information[J]. Journal of System Simulation, 2004, 16(11): 2608-2610. [2] Zhang Chun-lin, Zhang Peng-lin, Hu Rui-min. News story detection based on anchorpersons identification in news video[J]. Computer Engineering, 2003, 29(14): 20-26. [3] 徐新文, 李国辉, 甘亚莉. 基于播音员识别的新闻视频故事单元分割方法[J]. 计算机工程与应用, 2008, 44(19): 4-7. [4] Marti A. Hearst. TextTiling: Segmenting Text into Multi-paragraph Subtopic Passages[J]. Computational Linguistics, 1997, 23(1): 33-64. [5] Nicola Stokes, Joe Carthy, Alan F. Smeaton. SeLeCT: a lexical cohesion based news story segmentation system[J]. Journal of AI Communication, 2004, 17(1): 3-12. [6] 傅间莲, 陈群秀. 自动文摘系统中的主题划分问题研究[J]. 中文信息学报, 2005, 19(6): 28-35. [7] 杨玉莲, 谢磊. 基于子词链的中文新闻广播故事自动分割[J]. 计算机应用与研究, 2009, 26(2): 583-586、594. [8] Allan J, Carbonell J, Doddington G, et al. Topic detection and tracking pilot study final report[C]//Proceedings of DARPA Broadcast News Transcription and Understanding Workshop, Lansdowne, Virginia, USA, 1998: 194-218. [9] Doug Beeferman, Adam Berger, John Lafferty. Statistical Models for Text Segmentation[J]. Machine Learning, 1999, 34(1-3): 177-210. [10] Qi W, Gu L, Jiang H, et al. Integrating visual, audio and text analysis for news video[C]//Proceedings of 7th IEEE Intn’l Conference on Image Processing, 2000. [11] Hsu W, Kennedy L, Huang C-W. News video story segmentation using fusion of multi-level multi-modal features in trecvid 2003[C]//Proceedings of ICASSP2004, 645-648. [12] Liu Z, Huang J C, Wang Y. Classification of TV programs based on audio information using hidden Markov model[C]//Proceedings of IEEE Workshop on Multimedia Signal Processing, Redondo Beach, CA, USA, 1998: 27-32. [13] 刘群, 张华平, 俞鸿魁,等. 基于层叠隐马模型的汉语词法分析[J]. 计算机研究与发展, 2004, 41(8): 1421-1429. [14] Lev Pevzner, Marti A. Hearst. A Critique and Improvement of an Evaluation Metric for Text Segmentation[J]. Computational Linguistics, 2002, 28(1): 19-36.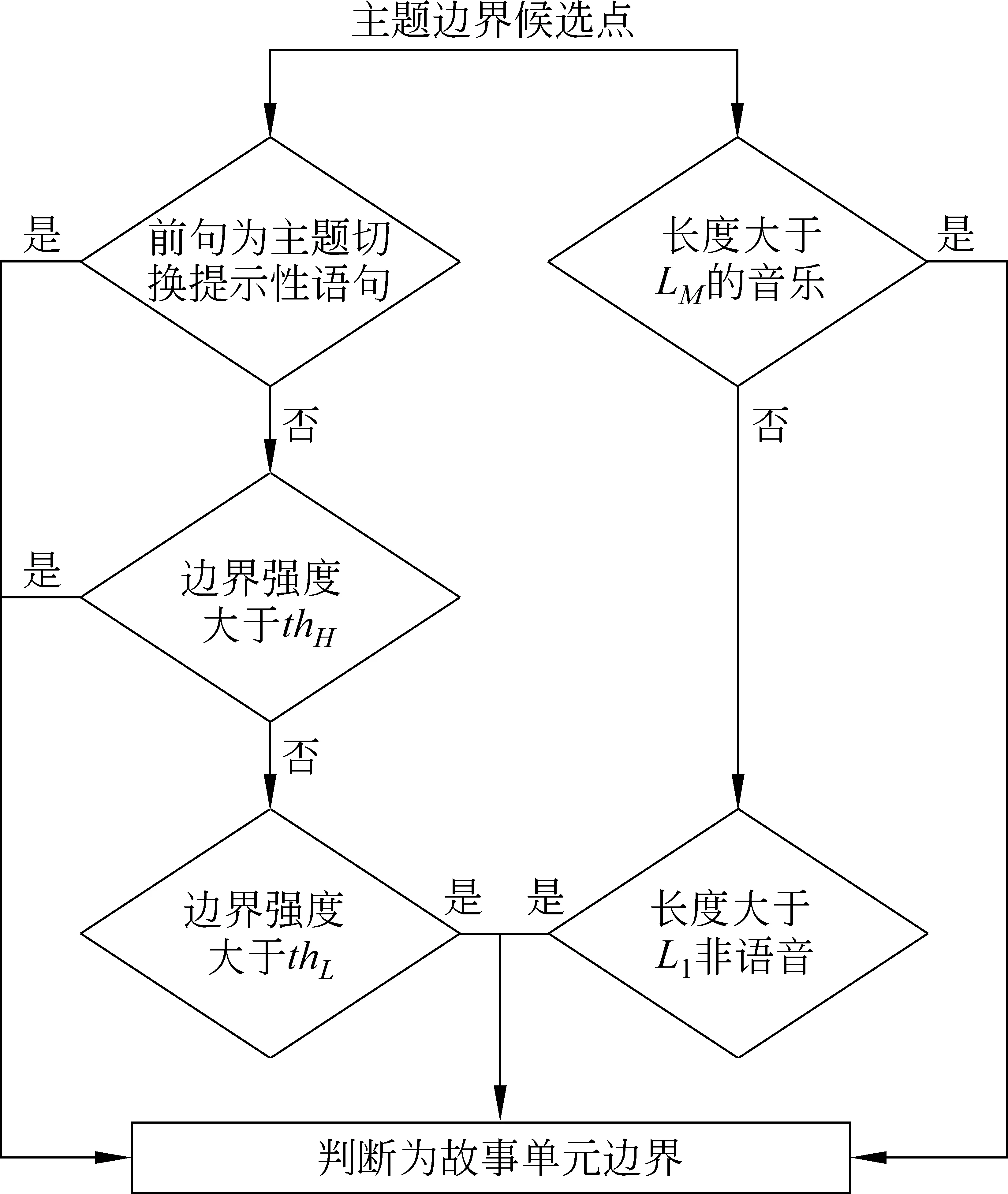
5 实验结果及分析
5.1 评价指标
5.2 实验结果
6 总结与展望
