基于HNC的汉语词语知识库改进
2012-06-29王青海马海慧池毓焕董凌冲
王青海,马海慧,2,池毓焕,李 颖,董凌冲
(1. 装甲兵工程学院 信息工程系,北京 100072; 2. 中国人民解放军63861部队,吉林 白城 137001;3. 中国科学院声学研究所,北京 100190; 4. 中国人民解放军63713部队,山西 忻州 036301)
1 引言
任何一个自然语言处理系统理解自然语言句子,首先要具备词的知识。词语知识库已经被广泛应用于机器翻译、信息检索、问答系统、自动文摘等领域,成为自然语言处理不可或缺的基础资源。比较著名的知识库有WordNet、FrameNet、EDR电子词典、《知网》、HNC等[1]。
目前,HNC知识库在规模上有一定的发展,但是在可扩展性和数据库设计上还有待改进。现有的HNC汉语词语知识库相对设计简单,关联性不足,增大了HNC符号解析的复杂程度,主要存在以下不足。
(1) 系统做语义距离计算时,要进行单独的HNC符号解析,检索周期长;
(2) 概念联想上完全依靠程序计算,概念之间的映射关系在数据库中没有直接的反映。
本文通过分析HNC的编码特点,改进了汉语词语知识库结构,提出了新的汉语词语知识库模型,并且通过实例说明了改进后的词语知识库在语义距离计算上的优势,指出了汉语词语知识库的发展趋势和可能存在的问题。
2 知识库模型的构建
2.1 汉语词语知识库模型设计
2.1.1 汉语词语知识库模型的提出
HNC理论利用HNC1、HNC2、HNC3和HNC4将词语、语句、句群、篇章数字化,为计算机把握语义提供基础[2]。HNC符号有两个重要特点。
(1) HNC符号是对词义的渐进表达,给出概念联想脉络知识的线索,与语种无关;
(2) HNC符号中不仅蕴含着词语层面的知识,还蕴含着语句和语境层面的知识。
根据上述特点可知,利用HNC处理自然语言,建立自然语言与概念空间之间的映射是关键。

图1 基于HNC的汉语词语知识库模型
知识库承担了自然语言与概念空间之间映射的任务。HNC符号中表达概念联想关系的手段主要有概念矩阵、层次性节点、挂靠表达、组合结构等[3]。本知识库设计基于HNC1和HNC2,利用自上而下的建库思想[4],如图1所示,包括中文词条、HNC特性、基本句类、常用组合词和中层特性五个实体。其中,中文词条通过HNC特性外化它们在概念空间的关联。此外,与本知识库设计紧密相关的三层节点和五元组知识会在下面进行简要的说明。
2.1.2 实体设计的必要性分析
(1) 如图1所示,将HNC特性作为一个实体,并分HNC编码、高层特性、中层特性、底层特性、五元组特性和本体层符号六个属性。其中,后五个属性是HNC编码的符号解析。与之前的单表词库相比,新的汉语词语知识库能够省去编程时的符号解析环节,有利于概念联想,降低文字处理系统程序的复杂度,减少不必要的误差。
如图2所示,词语的HNC编码包括高层、中层和底层,在语义距离计算时都有不可忽视的作用,具体方法参见3.1。概念的五元组特性和概念的层次性、对比性、对偶性、包含性统称概念同行关联,简称同行[2]。具有同行关联性的概念有相同或相似的层次符号,因而部分语义距离的计算问题就简化为对数字串的逐层比较问题。五元组是概念的外在表现,分别描述概念的五个侧面: 动态v、静态g、属性u、值z、效应r。它们可以多重组合但各有约定的内涵。对比性、对偶性和包含性是概念局部联想的基本特征。从一个对比性概念就能联想到另外n-1个概念,从对偶性概念的一方可以联想到另外一方(或两方),从一个包含性概念就可以联想到它的上下方,这为电脑进行概念联想操作提供了有效的手段[3]。所以,这里将中层特性单独作为一个实体。

图2 词语的HNC编码层次
本体层符号与挂靠概念相关,挂靠就是把一个概念与相关概念的层次符号直接拼接在一起,是HNC符号中表达概念关联性的一种方式[3]。在语义距离计算的过程中,本体层是首先要进行判断的。具体方法参照3.1节的实例。
(2) 通过HNC编码,设计常用组合词词表,建立最常用的词语之间的联系。在语言理解的过程中,如果有一个词语确定了HNC编码,在知识库中找到与它组合的常用词,如果被找到的常用组合词与上下文相符,则可以确定这两个词是一个短语,进而确定常用组合词的HNC编码;另一种情况,在合词阶段,遇到常用组合的形式,可以同时确定这几个词属同一语义块,并确定这几个词的HNC编码。常用组合词可以提高合词和语义块识别的效率,具体办法参见3.2节。
(3) 语义块是句类的函数,要理解语句,确定句类,必须要从语义块上分解句子,以语义块为单位进行翻译,然后进行语义块顺序的调整。语义块必须标注,可以提高语义块识别的效率。
2.2 词语知识库实体属性设计
2.2.1 中文词条
(1) 中文编号,是中文词条的主码,从数字1开始的编号。多义词有多个义项,中文编号对应唯一的词语义项。例如,词语“中央”有两个义项,一个是“中心的地方”,另一个是“国家或者政党政治权利最高的地方”,这两个义项要有不同的中文编号。
(2) 词形、拼音根据《现代汉语词典》填写,词形填写类型是短文本,拼音填写类型是字符串。
(3) 词频,根据已有的HNC汉语语料库进行统计,填写类型是数字。
(4) HNC编码,根据HNC符号规则将词语的当前义项完全数字化,填写类型是字符串。
(5) 可属语义块,包括四种主语义块和七种辅语义块,填写类型是字符串。其中,主语义块有特征(E)、作用者(A)、对象(B)和内容(C);辅语义块有方式(Ms)、工具(In)、途径(Wy)、参照(Re)、条件(Cn)、因(Pr)、果(Rt)。
(6) 句类编号,是中文词条的外码,基本句类实体的主码,对应唯一的实体基本句类,填写类型是从1开始的数字。
2.2.2 常用组合词
常用组合词的主码也是中文编号。常用组合词分四项属性,紧前、紧后、隔前、隔后,每项属性填写的都是HNC编码。
2.2.3 基本句类
基本句类的主码是句类编号,范围是1-57,根据HNC有限的57种句类填写基本句类名和句类表达式。基本句类名的填写类型是短文本,句类表达式的填写类型是字符串。例句由HNC的语料库提供,是完成句类成分分析的例句,例句格式如下:
这||是||<{总结|
2.2.4 HNC特性
HNC特性的主码是HNC编码。同时,HNC编码也是它与中层特性联系的外码。不同于以往的知识库,本知识库不仅根据HNC概念联想脉络对词条进行HNC编码,还将词条的高层、中层、底层以及五元组特性分开描述,不用对HNC符号进行分析解读就能从高层特性直接判定这个词条所属的概念属性,并且,中层特性作为单独的实体被描述。
2.2.5 中层特性[3]
中层特性的主码是HNC编码,包括对比、对偶和包含三项属性,填写类型是字符串。
(1) 对比性概念用符号cnk或者dnk(k取值1~n)。n表示对比的总级数;k表示排序中的序号;c表示正序,即序号k越大值越大;d表示反序,即k越大值越小。例如:
幼u10bc51 少u10bc52 青u10bc53 中u10bc54 老u10bc5
冠军(j00d01,l15,gvc730) 亚军(j00d02,l15,gvc730)
对比符号在排序、信息查询的过程中有着不可忽视的作用。
(2) 对偶性概念分为黑氏对偶和非黑氏对偶两种,用ekm或者m表示,m取值0~7,分为0,1,2,3和4,5,6,7两组。1、5和2、6表示对偶的双方,0、4表示统一方,3、7用于表示对偶中的第三方,不同的对偶类型可能没有统一方或第三方[5]。
(3) 包含性概念的表示式中,“-”是最高一级的包含概念,“-0”表示比“-”还低一级的包含概念,“0”越多包含概念的级别越低,这对于语义块的识别有很重要的参考意义。例如,对于时间短语“1949年10月1日”,其中“年”、“月”、“日”的HNC编码可写成: 年wj10- ,月wj10-0,日wj10-00。
根据符号可判定,这三个词具有包含的意义,属同一语义块。还有另外一种包含信息,例如,“中国”、“上海”这两个词,从上海可以判定的地理信息就有中国这一层。
2.3 词语知识库填写原则
知识库的基本设计思想是概念矩阵的近似实现。HNC符号对词语之间概念联想的关系脉络给出形式化的表达,以服务于自然语言处理的需要[3]。本着便于计算、便于语义块识别,降低非专业用户使用难度的原则,汉语词语知识库的建库原则[6]如下。
(1) 以消解模糊、语义块识别为目的选词。汉语没有很严格地、如印欧语言那样的“词”。收集词语以概念和语义为中心,考虑词语的流行性和固定性;
(2) 词语义项的选择需要考虑现代流通性;
(3) 符号编码以句类知识为核心,词语库中的各项知识都以句类知识为纲领;
(4) 知识库的主要知识项都用HNC的符号体系表述,是完全符号化和数字化的。
3 词语知识库的应用分析
汉语词语知识库的应用有很多。依据知识库中同行优先、常用组合、概念类别[3]等与HNC相关的先验知识和已经确定的HNC符号编码,既可以推测上下文关联词的编码,也可以开展填空造句,或者翻译的时候也能根据HNC编码进行语义距离计算从而确定句子最准的目标词语。下面利用实例简要分析一下本文提出的汉语词语知识库在语义距离计算方面的优越性。
3.1 语义距离计算
以前的单表知识库,提取高层、中层、底层信息需要专门的程序,改进后却可以直接读取。
如表1所示,以“暂停”、“形势”、“冠军”、“亚军”为例进行语义距离计算,计算公式[7]如下:
SDC(H1,H2)=MAX(Sim(S11,S21), Sim(S11,S22),…,Sim(S11,S2m),Sim(S12,S21), Sim(S12,S22),…,Sim(S12,S2m),
……
Sim(S1n,S21), Sim(S1n,S22),…,Sim(S1n,S2m))
(1)
Sim(S11,S21)=Sim(S11.网络符号,S21.网络符号)*( Sim(S11.五元组,S21.五元组)+( Sim(S11.本体层符号,S21.本体层符号)* Sim(S11.中层符号,S21.中层符号)* Sim(S11.高层符号,S21.高层符号)+ Sim(S11.高层符号,S21.高层符号)*Sim(S11.底层符号,S21.底层符号)))))
(2)
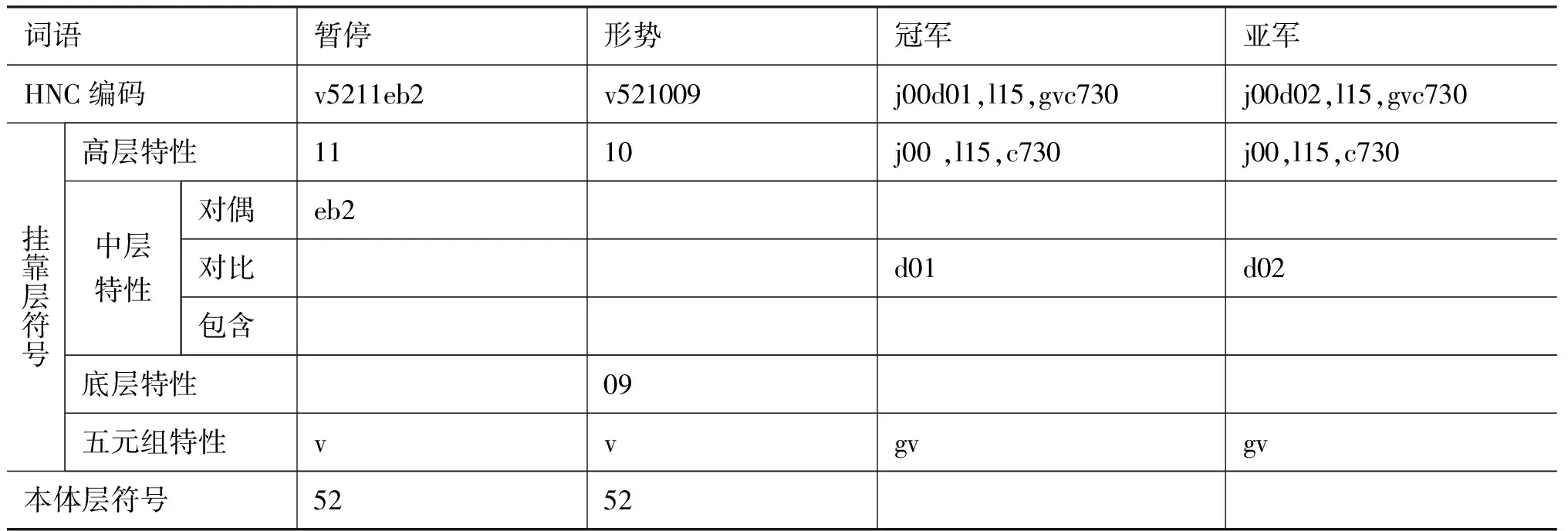
表1 中文词条建库填写举例
要进行高层、底层、五元组、本体层的比较,这些比较都没有考虑组合符号的作用,也就是说单纯的是字符的比较,计算结果用数字0~7表示[7]. 例如,(1) “暂停”与“形势”的HNC符号直接可以抽取五元组信息比较的得出匹配成功,本体层完全匹配,高层部分匹配成功,Sim(S11,S21)的结果为4;(2) “冠军”与“亚军”的HNC符号进行分层比较。用本文提出的知识库进行的只是符号读取与顺序匹配,不用对全部HNC符号进行解析。中层符号有d01,d02,而其他层的比较都匹配,Sim(S11,S21)的结果为7,最终得到的结果是对比性概念。
影响语义距离计算的因素有很多。例如,语义距离计算的两个词语的高层概念不同说明概念的基本类型不同,语义距离会很大,但底层有交叉的可缩短它们的距离,这不是本文讨论的重点。
本文改进的汉语词语知识库模型中,一个中文词条的HNC编码是确定的,高层、中层、底层也是可以分别读出的。从程序实现的角度来讲,提取表格中的概念比将每个HNC编码解析的计算量要小的多,这样就减小了自然语言处理核心程序的计算量。
3.2 合词
利用常用组合词的合词过程,如图3所示。常用组合词主要用来发现和分析前后词的关联,便于语义块的识别。直接给出常用组合词,可以简化语义块识别的组合判定算法,提高程序的效率。如“热爱学习”,“热爱”是“学习”的紧前词,“学习”是“热爱”的紧后词;“处于紧张时期”,“处于”是“时期”的隔前词,“时期”是“处于”的隔后词。当“学习”的HNC编码确定时,搜索到常用组合词“热爱”在紧挨“学习”前面的位置,可以判定它们可以组成一个短语,增加了同属一个语义块的概率,在做语义块判定时他们之间的关系优先判定。
例如,对于句子“这是总结近代以来中国发展的历程得出的结论。”利用本文改进的知识库,通过合词,可将“近代以来”划为一个短语。如果 “近代”、“以来”已经被填入知识库,常用组合词匹配成功直接形成短语。如果没有进行常用词组关联,可直接读取这两个词HNC符号的各层编码,利用3.1节的语义距离计算进行判定。这两种途径都比之前用单表进行语义块判定的计算量明显减少。
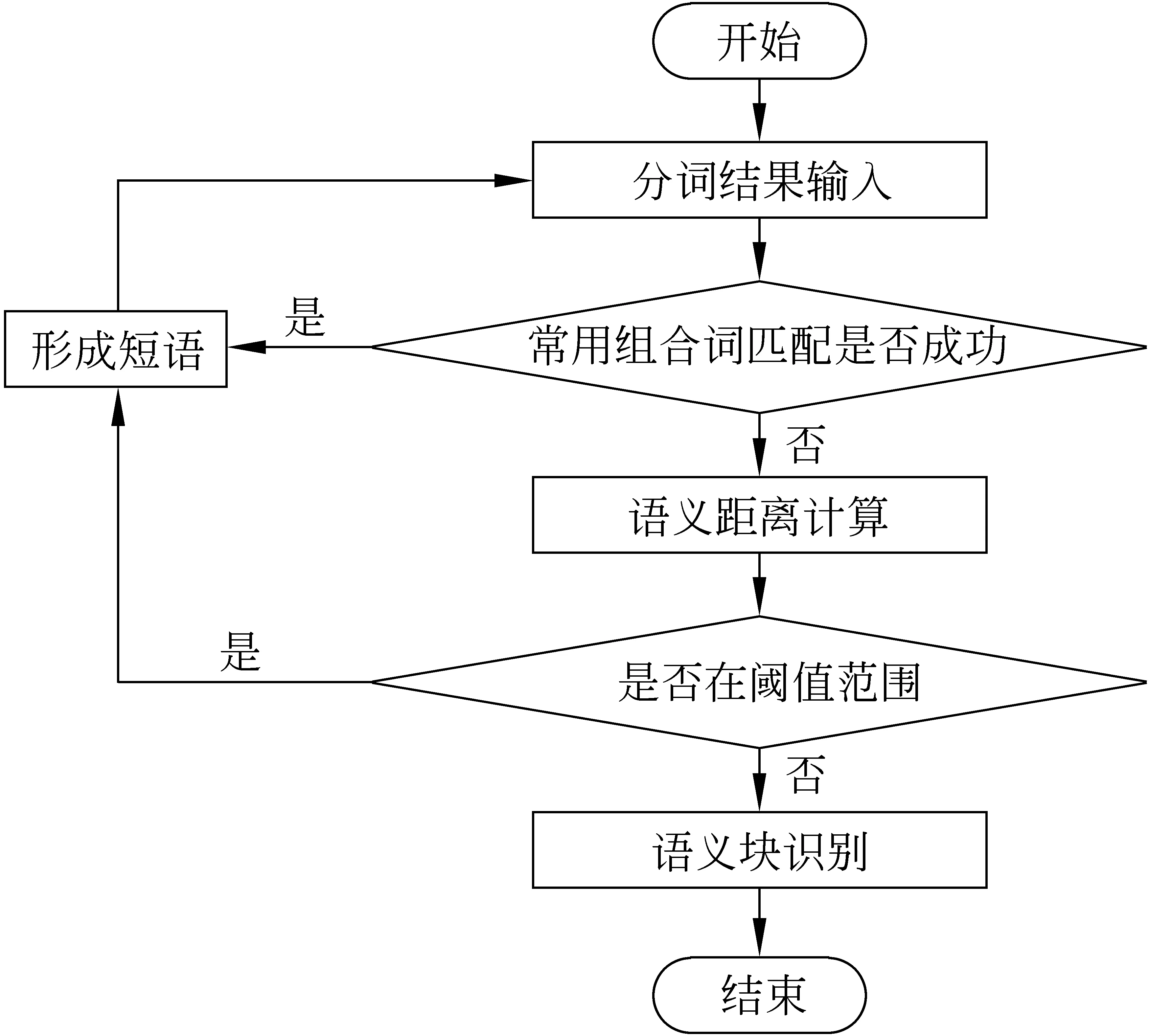
图3 合词流程
4 结语
本文设计的HNC汉语词语知识库虽然增加了建库的复杂度,但增强了知识库的程序可读性,提高了HNC知识库的层次性、逻辑性。尤其将HNC符号分高、中、低三层写入知识库的办法,简化了HNC符号的读取,减小了因读取HNC符号造成的处理误差,同时便于简化接口程序和搜索算法,方便了知识库的管理。
填写HNC知识库的过程,是从词语的文字符号向HNC的概念表述符号映射的过程,要求知识库填写人员理解和掌握HNC的概念符号体系以及HNC的自然语言理解处理策略。所以,要建好HNC知识库,还需要大量跨接语言学和计算机科学的复合型专业人才。
[1] 宗成庆.统计自然语言处理 [M].北京:清华大学出版社,2008:48-71.
[2] 李颖,王侃,池毓焕.面向汉英机器翻译的语义块构成变换[M].北京:科学出版社,2009.
[3] 苗传江.HNC(概念层次网络)理论导论[M].北京:清华大学出版社,2005.
[4] 赫南达斯.数据库设计凡人入门——关系数据库设计指南(第二版)[M].北京:电子工业出版社,2005.
[5] 李颖,池毓焕.对偶性概念的HNC阐释[J]. 中文信息学报, 2004,18(3):39-46.
[6] 苗传江,刘智颖.基于HNC的现代汉语词语知识库建设[J].云南师范大学学报,2010,42(4):15-18.
[7] 晋耀红.HNC(概念层次网络)语言理解技术及其应用[M].北京:科学出版社,2006: 50-61.
