基于《知网》的汉语未登录词语义相似度计算
2012-06-28张瑞霞杨国增吴慧欣
张瑞霞,杨国增,吴慧欣
(1. 华北水利水电学院 信息工程学院,河南 郑州 450011;2.郑州师范学院 数学系 河南 郑州 450044)
1 引言
在自然语言信息处理领域中,词汇相似度的计算广泛应用于基于实例的机器翻译、信息检索、信息抽取和词义消歧等领域,并取得了丰富成果,如文献[1-6]利用不同方法计算了词汇相似度。而随着网络的出现,涌现出了大量未登录词,关于未登录词识别有很多研究[7-11],但关于其语义相似度计算的研究甚少,在计算汉语词汇语义相似度的众多文献中,只有文献[3]涉及了,并且其计算方法也有待完善。因此设计合理的未登录词相似度计算方法有利于促进应自然语言处理相关领域的发展。
鉴于上述原因,提出了一种基于《知网》2005的汉语未登录词语义相似度计算方法。该方法首先形式化描述了《知网》的动态角色与意合网络的语义关系,并在此基础上构造了语义关系匹配函数;接着在用概念图表示未登录词语义信息的基础上,根据节点在语义表示中的不同作用,对其分类;然后根据匹配函数定义了不同弧、节点对及节点对集的构成方法;最后提出了未登录词的整体相似度、不同类型节点对及节点对集相似度的计算方法。实验结果证明此方法是有效的。
2 《知网》和意合网络
《知网》是一个以英汉双语所代表的概念以及概念的特征为基础的常识知识库,它主要描述了概念与概念之间以及概念所具有的特性之间的关系[12]。董振东先生强调“关系是知识的核心,关系是《知网》的灵魂”[13]。本计算方法是在利用《知网》的《知识词典》和《中文信息结构库》构造未登录词语义信息的基础上提出的,它在计算过程中能够有效的利用语义关系,能够充分的利用语义信息。
意合网络是鲁川先生根据汉语自身的特点,对语义网络的内容和形式进行了相应改进而提出的关于汉语语法语义表示方面的系统理论;它是由各级“语义单位”组成的,清晰表示“语义关系”、“语义依附”和“语义指向”的有层次网络,是“语义组合系统”的形式化图解[14];当代语言学家胡明扬先生认为它是中国计算机专家写的第一部现代汉语语法理论著作,值得每一个从事汉语研究的人一读[15]。
3 基于《知网》的未登录词语义相似度计算方法
文献[3]中利用《知网》2000版计算了未登录词语义相似度,计算方法不适用于知网新版本;文献[5]利用《知网》2005版计算了汉语登录词的相似度,但此方法若应用于未登录词,则会忽略去部分语义信息从而影响计算效果。例如未登录词“制造商”和“痴迷者”,根据对未登录词语义分析的研究,利用《知网》的《知识词典》和《中文信息结构库》,得到两个词语的概念图分别如图1、图2所示。若采用文献[5]中语义相似度计算方法,则只有图1的节点“人”与图2的节点“人”参与相似度计算,这样“制造商”与“痴迷者”的语义相似度就被简化为“商”与“者”的相似度,显然不合理。所以计算未登录词语义相似度的主要问题有以下三个:
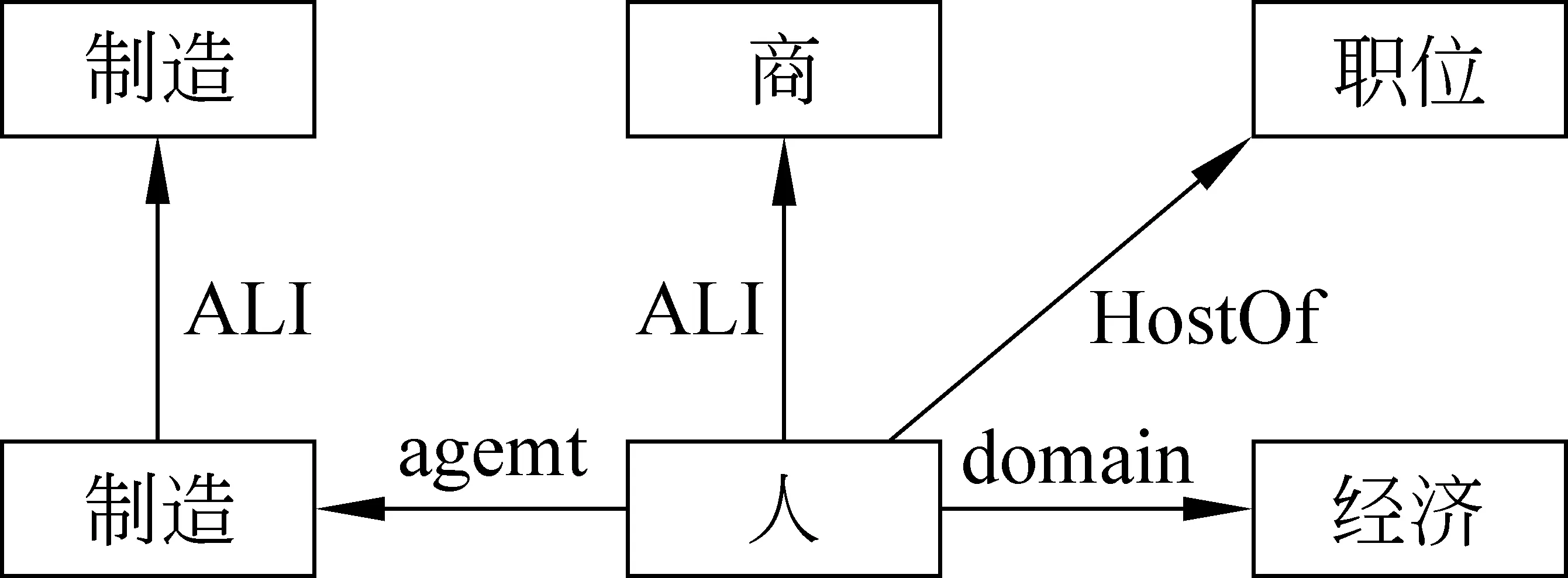
图1 “制造商”的概念图
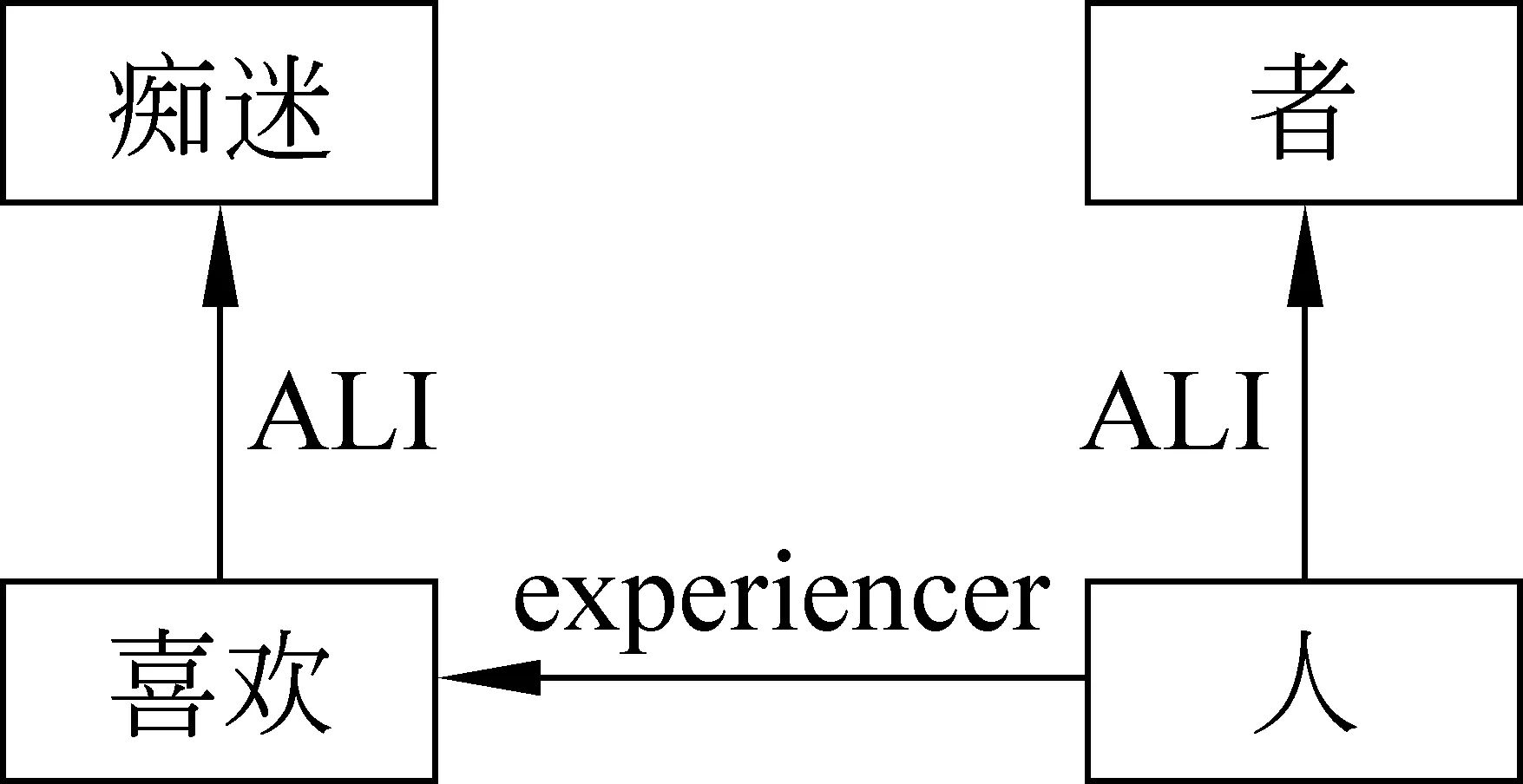
图2 “痴迷者”的概念图
(1)如何实现语义关系的模糊匹配,以使各种语义信息有效的参与计算;
(2)如何按照语义关系的匹配分类节点对;
(3)如何计算节点对、节点对集合及未登录词整体的相似度。
3.1 语义关系的模糊匹配
《知网》对语义关系的描述是比较细化的,如图1中“人”作为“制造”的agent与图2中“人”作为“喜欢”的experiencer是不同的;但若语义关系的粒度稍微粗略一些,图1“人”是 作为“制造”的主体,图2“人”也是作为“喜欢”主体,因此两者的语义关系是相同的,这样计算语义相似度时,“制造”与“喜欢”模糊匹配成功,从而参与计算,提高计算的准确性。鲁川先生的意合网络理论对语义关系划分的粒度比较合适,因此参照其首先形式化描述了语义关系匹配集,然后构造了语义关系匹配函数。
意合网络的语义关系集合记为Roleyihe,《知网》的动态角色集合记为Rolehownet,语义关系标识号集合记为Sid,父语义关系标识号集合记为SparentId。
语义关系记为一个四元组x:x=
根据意合网络语义关系的层次,对语义关系集合按层次进行划分,分别称为:
语义关系第一匹配集,记为MatchFirst={(周边)}。
语义关系第二匹配集,记为MatchSecond={(参与),(情景)}。
语义关系第三匹配集,记为MatchThird={(主体),(客体),(邻体),(系体),……}。
语义关系第四匹配集,记为MatchForth={(施事),(当事),(领事),(受事),……}。
语义关系第五匹配集,记为:
MatchFifth={
下面定义了匹配集间的函数关系f,g,称为语义关系匹配函数:
f:MatchFifth→MatchForth,∀x∈MatchFifth,y=f(x)⟺x.parentId=y.id,则f确定了动态角色按照MatchForth的匹配规则,即若f(xi)=f(xj),则xi.name与xj.name可模糊匹配。
g:MatchForth→MatchThird, ∀y∈MatchForth,z=g(y)⟺y.parentId=z.id,则g确定了意合网络第四层语义关系按照MatchThird的匹配规则,即若g(yi)=g(yj),则yi.name与yj.name可模糊匹配。
由函数的传递性可知,复合函数g∘f:MatchFifth→MatchThird,∀x∈MatchFifth,z=g(f(x))⟺f(x).parentId=z.id,则g∘f确定了动态角色按照MatchThird的匹配规则,即若g(f(xi))=g(f(xj)),则xi.name与xj.name可匹配。
构造匹配函数后,就增强了动态角色模糊匹配的可操作性,如动态角色experiencer和agent按照匹配函数g∘f可以进行匹配。
3.2 节点、弧及节点对的分类
设概念图G1、G2分别为词语W1、W2的概念图,其中:
G1= G2= 令v1i∈V1,e1j∈E1且e1j与v1i相关联,e1j的关系类型为《知网》的动态角色kind,则其对应的语义关系为x1j=(kind);令v2k∈V2,e2l∈E2且e2l与v2k相关联,e2l对应的语义关系四元组为x2l;有x1j,x2l∈MatchFifth。 文献[16]对词图中的节点分为词语节点、中心义原节点、基本义原节点,由于未登录词的概念图是由词图合并得到的,因此在文献[16]对节点分类的基础上添加了次中心义原节点。 定义1:次中心义原节点:若一节点在概念图合并之前是中心义原节点,在合并之后不是中心义原节点,则称此节点为次中心义原节点。 对图1和图2中的节点进行分类如表1所示: 表1 图例节点分类表 根据弧被加入概念图中的时间不同将其分为基本弧和扩展弧,根据语义关系的匹配性可分为基本同型弧、α扩展同型弧、β扩展同型弧、χ扩展同型弧。 定义2:基本弧:构建登录词概念图过程中添加的弧称为基本弧。 定义3:扩展弧:合并两个概念图过程中添加的弧称为扩展弧。 定义4:基本同型弧:e1j与e2l为基本同型弧当且仅当e1j与e2l是基本弧且x1j=x2l。 定义5:α扩展同型弧:e1j与e2l为α扩展同型弧当且仅当e1j与e2l是扩展弧且x1j=x2l。 定义6:β扩展同型弧:e1j与e2l为β扩展同型弧当且仅当e1j与e2l是扩展弧且x1j≠x2l且f(x1j)=f(x2l)。 定义7:χ扩展同型弧:e1j与e2l为χ扩展同型弧当且仅当e1j与e2l是扩展弧且f(x1j)≠f(x2l)且g∘f(x1j)=g∘f(x2l)。 对图1和图2中的弧进行分类如表2所示: 表2 图例弧分类表 跟据节点所关联的弧的类型不同,对节点对可分为不同的类别。 定义8:节点v1i与v2k是基本同构节点对:当v1i和v2k满足下列所有条件时,称v1i与v2k为基本同构节点对,记为 (1)e1j和e2l为基本同型弧; (2)v1i与v2k均为基本义原节点; (3)v1i与v2k分别为e1j和e2l的始点或终点。 对于 类似的当v1i与v2k分别为G1和G2的次中心义原节点时,可定义α扩展同构节点对,记为 定义9:默认次中心同构节点对:当vi是概念图G的次中心义原节点且vi不包含在与G关联的任一α扩展同构节点对、β扩展同构节点对及χ扩展同构节点对中,则称vi与是默认次中心同构节点对,记为(vi,)s。 类似的可定义默认基本同构节点对,记为(vj,)。 对图1和图2中的节点对进行分类,其中基本同构节点对、α扩展同构节点对、β扩展同构节点对、默认次中心节点对均无,χ扩展同构节点对有<制造,喜欢>χ,默认基本同构节点对有(职位,)、(经济,)。 由不同类型的节点对可构成不同的节点对集,如基本同构节点对集ISO(G1,G2)、α扩展同构节点对集αEISO(G1,G2)、β扩展同构节点对集βEISO(G1,G2),χ扩展同构节点对集χEISO(G1,G2)、默认次中心同构节点对集DSISO(G1,G2)、默认基本同构节点对集DNISO(G1,G2)。 计算词语W1和W2的相似度也即计算其概念图G1和G2的相似度sim(G1,G2)。根据概念图中节点对的分类,局部相似度包括中心义原节点对的相似度sim0、ISO(G1,G2)相似度sim1、αEISO(G1,G2)相似度sim2、βEISO(G1,G2)相似度sim3、χEISO(G1,G2)相似度sim4、DNISO(G1,G2)相似度sim5、DSISO(G1,G2)相似度sim6,G1、G2相似度由局部相似度加权和得到,如公式(1)所示。 (1) 下面探讨不同类型节点对及节点对集相似度的计算。 (1)基本同构节点对相似度的计算: 设 (2)α扩展同构节点对相似度的计算: 设 (3)β扩展同构节点对相似度的计算: 设 由于v1i和v2k是基于语义关系模糊匹配的,所以加入参数β′对原相似度进行调节,并令β′=f(x1j).weight;δi为一调参数,同公式(1)的设置。 类似的有χ扩展同构节点对相似度的计算方法,设 其中χ′为一调节参数,χ′=(g∘f(x1j)).weight,δi为一调参数,同公式(1)的设置。 (4)默认基本同构节点对和默认次中心同构节点对的相似度分别设定为较小的常数ε1和ε2。 (5)中心义原节点对相似度sim0的计算,按文献[5]中的义原相似度计算方法。 (6)sim1的计算,参照文献[5]中同构节点对集的计算,如公式(4)所示: (4) 同理可计算sim2、sim3及sim4。 (7)sim5和sim6的计算如公式(5)和公式(6)所示: 其中n=|DNISO(G1,G2)|,m=|DSISO(G1,G2)|。 如,计算“制造商”与“痴迷者”的相似度即计算图1与图2的相似度,根据实验经验,主要参数设置如表3所示: 表3 参数设置 计算过程中有sim0=1.0,sim1=0.0,sim2=0.0,sim3=0.0,sim4=0.277 777 8,sim5=0.002,sim6=0.0,按照公式(1)有“制造商”与“痴迷者”的相似度为0.705 565 6。 主要参数设置如表3所示,表4列举了一些未登录词相似度的计算结果。 表4中实验举例分两部分,一部分是未登录词“体育部”和一些词语的相似度,另一部分是未登录词“中国队”和一些词语的相似度。在第一部分中,前4行与人的直觉一致;第5行相似度和第6行相似度人的直觉不容易分辨,但是若从语义结构来分析,“体育部”和“读书人”的语义结构要比“体育部”和“美少女”的语义结构更相近,所以实验结果是合理的;第6行和第7行相似度大小从直觉上不易区别,但结果显示第6行相似度略大于第7行,是因为两者的概念图中第6行中的默认基本同构节点对多于第7行中的;第7~10行结果与直觉一致。 第二部分中,“中国队”和一些未登录词的相似度计算,除了第7行,其他均和人的直觉一致,第7行相似度较第6行高,主要原因在于“队”与“画”的相似度大于“队”与“人”的相似度,改善方法为丰富知网对这些词语概念项的描述。 表5 未登录词与登录词相似度实验结果举例 表5列举了未登录词“俄国人”和一些登录词的相似度计算结果,从整体上看,由于未登录词的概念图是根据知网中的《中文信息结构库》构造的,所以按照提出的相似度计算方法,单个来看,相似度值偏低,当整体来看,计算结果是合理的。第4行和第5行相似度相同,因为“熊猫”的主要义原“走兽”和“鸽子”的主要义原“禽”在知网的“实体”义原树中处于同一层次,因此在计算其与“人”的相似度时,按照语义距离计算方法无法区分。 本实验的实验集由两部分组成,第一部分来自《PFR人民日报标注语料》,从中统计出13 890个未登录词,其中名词60%、动词20%、日常用语10%、其他词性的未登录词10%,以及来自哈工大信息检索研究室语言技术平台的标注语料,从中选出4 000个未登录词,其中名词60%、动词20%、其他词性的未登录词20%;第二部分是随机选取《PFR人民日报标注语料》中的2 000个登录词和2 000个未登录词。根据实验结果统计,名词性的未登录词相似度中85.2%和人的直觉一致,动词性未登录词的 70.1% 和直觉一致,日常用语的51.7%和直觉一致,其他词性未登录词的72.4%和直觉一致。名词性未登录词相似度计算效果较好主要原因在于《知识词典》对名词性概念项的描述较详尽,《中文信息结构库》中关于名词性短语的语义结构也较丰富,因此根据《知识词典》和《中文信息结构库》对名词性未登录词概念图构造的正确性比较高,所以其相似度计算效果较好;《知识词典》对动词性概念的描述较简单,《中文信息结构库》中关于动词性短语的语义结构相对不如名词性短语的语义结构丰富,因此其概念图构造的正确性就不如名词性未登录词,其相似度计算效果也不如名词;对于日常用语相似度计算效果较差,主要原因在于《中文信息结构库》中难以找到与其对应的准确语义结构;这些体现了基于知识库的语义相似度计算的缺点。 以《知网》2005版为语义资源提出了汉语未登录词语义相似度的计算方法,该方法首先形式化描述了知网的动态角色与意合网络的语义关系,构造了匹配函数;接着在用概念图表示未登录词语义信息的基础上,根据节点的作用不同对其分类,并根据匹配函数对弧、节点对及节点对集分类;最后提出了未登录词整体相似度、不同类型节点对及节点对集相似度的计算方法。实验结果证明此方法是有效的。 在下一步的工作中,需要继续完善本方法。例如在计算过程中,目前所有的参数都是经验值,应尝试一些参数估计法或机器学习法,来自动寻找最优参数;再如,计算过程中,由于《知网》对概念项或对语义结构信息描述的不详尽,而影响了计算效果,应尝试结合统计方法修正计算结果;还有,目前计算词语相似度是单从词语角度来做的,应尝试把词语放入具体语境中计算相似度等。 [1]刘群,李素建.基于《知网》的词汇语义相似度计算[C]//第三届汉语词汇语义研讨会,台北,2002. [2]关毅,王晓龙.基于统计的汉语词汇间语义相似度计算[C]//全国第七届计算语言学联合学术会议论文集,哈尔滨,2003,221-227. [3]夏天.汉语词语语义相似度计算研究[J].计算机工程, 2007,33(6):191-194. [4]李峰,李芳.中文词语语义相似度计算——基于《知网》2002[J].中文信息学报,2007,21(4):99-105. [5]张瑞霞,朱贵良,杨国增.基于知试图的汉语词汇语义相似度计算[J].中文信息学报,2009,23(3):116-120. [6]葛斌,李芳芳,郭丝路,等.基于知网的词汇语义相似度计算方法研究[J].计算机应用研究,2010,27(9):3329-3333. [7]邹纲,刘洋,刘群,等.面向Internet的中文新词语检测[J].中文信息学报,2004,18(6):1-9. [8]刘华.一种快速获取领域新词语的新方法[J].中文信息学报,2006,20(5):17-23. [9]韩艳,林煜熙,姚健民.基于统计信息的未登录词的扩展识别方法[J].中文信息学报,2009,23(3):24-30. [10]程冲,黄水清.自适应分词算法中的未登录词识别技术研究[J].情报学报,2009,28(4):530-536. [11]张海军,史树敏,朱朝勇,等.中文新词识别技术综述[J].计算机科学,2010,37(3):6-10. [12]董振东,董强.《知网》——《知网》简介[R].http://www.keenage.com [13]董振东,董强,郝长伶.《知网》的理论发现[J].中文信息学报,2007,21(4):3-9. [14]鲁川.汉语语法的意合网络[M].北京:商务印书馆,2001:39-69. [15]胡明扬.读鲁川著.《汉语语法的意合网络》[J].汉语学习,2003(2):73-75. [16]张瑞霞,肖汉.基于知网的词图构造[J].华北水利水电学院学报(自然版),2008,29(3):53-56.

3.3 未登录词相似度计算
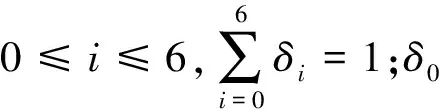

4 实验与分析
4.1 相似度计算举例

4.2 实验结果分析
5 结束语
