基于能量分布和共振峰结构的汉语鼻音检测
2012-06-28张连海
陈 斌,张连海,牛 铜,王 波
(解放军信息工程大学 信息工程学院,河南 郑州 450002)
引言
新一代的语音识别系统框架[1]是以知识为基础并结合统计模型,来模拟人认知语音的过程。在该框架下,知识的获取显得尤为重要。目前语音知识获取主要是声学单元类别和边界信息的获取。作为汉语语音识别中的基本声学单元,声韵母类别和边界信息的准确获取,是新一代汉语语音识别系统的关键。
由于响音(元音韵母、鼻音)对表意有着重要作用,因此,有不少学者对响音的分类和定位进行研究[2-3]。其中,基于Seneff听觉模型的检测系统较好地实现了声韵母边界的检测与响音定位。鼻音作为响音的重要组成部分,发音过程会有部分气流经由鼻腔向外辐射,在频谱上表现为存在一个零点,其声学特性与元音韵母有较大的差异,难以用相同的声学特征参数和模型结构对鼻音和元音韵母进行描述。同时鼻音和元音韵母的准确分类将提高语音识别、编码和合成系统的性能,因此,进一步将响音分为鼻音和元音韵母具有重要的意义。
目前对鼻音的检测主要是根据鼻音的发音特征[4-5](发音位置,发音方式等)、音素配位学[6-7](phonological)和能量变化率、谱峰位置、起始和结束能量值等能量特征[8],以及采用合适的模型对特征进行描述如SVM和条件随机场CRF等。现有的鼻音检测系统[9]会引入较多的插入错误,有的插入错误数与真正标记个数的比值甚至达到2∶1。
本文主要从能量分布和共振峰结构信息对鼻音特性进行刻画,实现鼻音的检测。在基于Seneff听觉模型检测系统的基础上,进一步从响音中实现鼻音和元音韵母的分类识别,检测系统如图1所示。在保证较高正确率的前提下,尽可能的去除插入错误,提高准确率。即先建立鼻音分类模型,从响音中检测出候选的鼻音,保证较高地检测正确率,然后对鼻音检测结果进行后处理,有效地去除插入错误。

图1 鼻音检测系统图
1 基于支持向量机的鼻音检测
1.1 基于听觉谱的特征参数选取
Seneff听觉模型[10-11]由40个临界频带滤波器组组成,能较好地模拟人耳对语音的听觉处理过程,描述听觉神经饱和、自适应调适、掩蔽,对电流感应的单向性,易受低频周期信号激发等特性。将Seneff听觉感知模型的输出称为Seneff听觉谱,能够较好地描述音素的能量分布特性和共振峰结构。Seneff听觉谱由两部分组成:包络响应ED和同步响应GSD,ED凸显语音信号中变化剧烈区域的开始与结束,GSD则突出共振峰结构。由于GSD的求解过程是直接对每个通道的GSDi求平均,会导致频域分辨率降低,同时出现伪峰值。为了避免上述问题,增强共振峰提取的可靠性,Ali[12-13]提出了平均局部同步输出ALSD。
从语谱图上可知,鼻音[14]在低频处有明显的共振峰,其第一个共振峰是位于频率较低处,大约在200Hz~400Hz之间,800Hz以上的能量将大幅衰减。从信号与系统的观点上来看,传统的全极点模型并不适合于描述鼻音,因为口腔与鼻腔的结合处会在频谱上产生零点,此零点也将造成鼻音在第一个共振峰以上的能量有大幅的衰减。因此鼻音与元音韵母的主要区别为鼻音能量集中在低频处,中高频带能量大幅衰减,谱峰位置主要位于低频处,整个发音持续过程中谱峰位置平均值会比较小,元音韵母在中高频带也有能量的分布,全频带能量较大。以下特征参数的提取都是基于Seneff听觉谱特征和声韵母边界检测后两边界点之间的音段(segment based),得到整个音段的能量分布和共振峰结构特性。基于上述分析,本文选取归一化全频带ALSD、ED,中高频带ALSD、ED,ED谱重心、ALSD平均最大谱峰值位置特征。
归一化全频带ED:
归一化全频带ALSD:
归一化中高频带ED:
归一化中高频带ALSD:
归一化ED谱重心:
ALSD平均最大谱峰值位置:
式中i=1,…,40为听觉模型通道值,j=1,…,n为每一通道的输出,J为单元的持续时间。
1.2 基于谱特征的鼻音检测
对响音的各音段提取上述特征,组成一个特征矢量作为输入,具有良好模型区分能力的支持向量机(SVM)作为分类器,进行响音的检测分类,得到候选的鼻音。这一过程能较好地保证鼻音检测正确率,需要进一步提高鼻音检测的准确率。
2 鼻音检测结果的后处理
由于检测到的鼻音会引入较多的插入错误,需要对检测结果进行后处理予以去除,这里主要需要去除的是边音/l/、摩擦音/r/和发音能量微弱的元音韵母。由于这三类的能量都主要位于低频带,具有较为明显的共振峰结构,全音段能量不大,易与鼻音音段混淆。本文根据音段持续时间、前端韵母能量、高低频能量差、中低频能量比的差异,进一步实现易混音段和鼻音音段的区分,依次对候选鼻音进行确认,后处理流程图如图2所示。
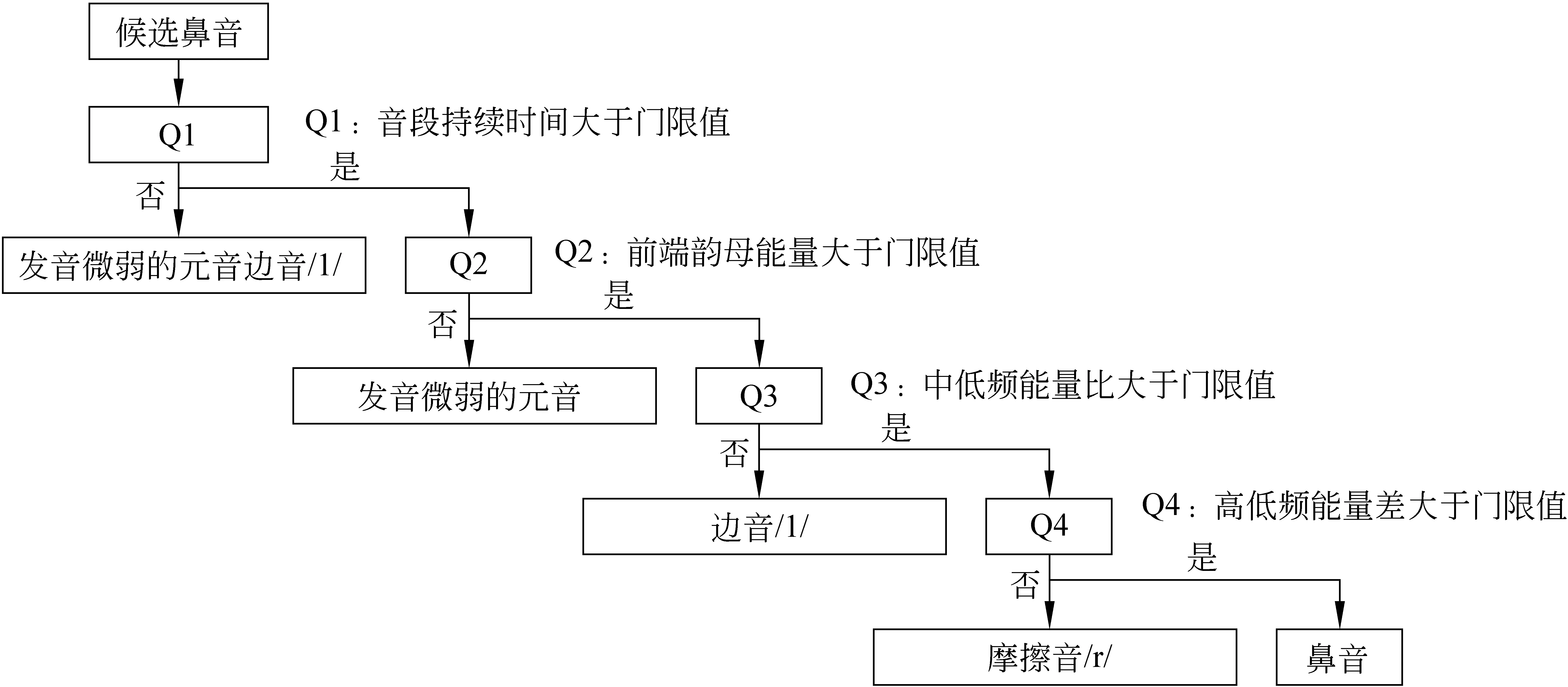
图2 后处理流程图
鼻音一般都有较长的音段持续时间,而大多数发音能量微弱的元音韵母和边音/l/的持续时间都比较小,音段持续时间Dura为边界检测结束点end与起始点start之差,即Dura=end-start。候选鼻音中音段持续时间Dura大于门限值ThDura的语音音段则再进行下一过程的确认,这一过程能较为有效地去除发音能量微弱的元音韵母和边音。
2011年江西省评选的第六届特级教师共233名,本研究随机抽取其中150人为被试,回收有效问卷116份。随机抽取江西省上饶市中小学普通教师246人为比较被试,回收有效问卷197份。特级教师中,男62人,女54人;小学教师46人,初中教师25人,高中教师45人。普通教师中,男106人,女91人;小学教师48人,初中教师34人,高中教师115人。
由于鼻音前端大多会接声学特性较为明显的元音韵母,并且正常发音的元音韵母会有一定的中高频带能量值,因此鼻音前端相邻韵母会有较大的中高频能量。若是因发音能量较低而误检测为鼻音的元音韵母,由于发音具有连续性和平稳性,其前端相邻的韵母能量也会偏低。两者1 200Hz以上的能量会存在较大的差异,这里采用归一化20通道以上的ED能量BMED进行描述,为了去除协同发音和边界检测误差对能量求解的影响,能量计算的起始点和结束点分别后移和前移1/8的音段长度,如图3所示,即

图3 前端相邻韵母能量计算示意图
候选鼻音中前端韵母BMED值大于门限值ThBM的语音音段则再进行下一过程的确认,这一过程对去除发音能量微弱的元音韵母具有较好的效果。
边音/l/存在较为明显的第一共振峰,400Hz以上的频率基本没有能量分布,而鼻音在400Hz~800Hz还有部分能量分布,因此两者400Hz频率以下能量与400Hz~800Hz能量的比值MLRED会存在较大的差异,即
候选鼻音中能量比MLRED大于门限值ThMLR的语音音段则再进行下一过程的确认,这一过程能进一步较为有效地去除边音/l/。
摩擦音/r/由于发音时受到阻碍属于阻塞音,在高频带有大量的能量分布。而鼻音在低频带有较大的能量值会大于/r/音,在1 200Hz以上分布着很小的能量,因而采用ED高低频带能量差HLDED能够较好的进行区分,即
候选鼻音中能量差HLDED大于门限值ThHLD的语音音段为鼻音,这一过程能有效地去除摩擦音/r/。经过上述后处理过程,能较为有效地去除插入错误。
3 测试评估
3.1 实验语料及评估指标
随机从微软语料库Speech Corpora(Version 1.0)中截取35段连续语流作为实验语料,声韵母共有521个,其中有鼻音250个,非鼻音271个。语音的采样频率为16KHz,量化精度16bit,人工进行声韵母的边界和响音标注。对检测结果的评估采用语音识别的评估方式进行。实际检测单元的总数记为N,正确检测单元的总数记为H,删除错误的总数记为D,插入错误的总数记为I。正确率和准确率定义如式(10)和(11)[15]:
3.2 实验结果及分析
表1为基于听觉谱特征构成的特征向量,采用SVM分类器得到的鼻音检测性能。表中正确个数H为算法检测出来的正确的鼻音个数,插入个数I为算法检测出来的非鼻音的个数,删除个数D为算法没有检测出来的鼻音个数, 并且H+I=250。从表中可以看出采用所提特征参数和分类器可以得到较高的正确率,由于存在较多的插入错误,使得准确率较低。对插入错误进行进一步观察和分析,可知插入错误主要是由浊辅音/l/、/r/和有时发音能量微弱的元音韵母/u/、/i/等引起的,因为它们都是浊音在低频带有较多的能量分布、谱峰位置和谱重心位于低频处与鼻音有较大的相似性。特征矢量中含有描述谱重心、最大谱峰位置和全频带能量的分量,因此会引入较多的插入错误,需要对检测结果进行后处理,有效地去除插入错误。

表1 基于支持向量机的鼻音检测结果
鼻音检测后处理阶段各门限值的选择是去除插入错误提高鼻音检测准确率的关键。门限值设立的太大将会带来删除错误,门限值设立的太小将不能有效地去除插入错误,因此需要讨论后处理各过程门限值对鼻音检测性能的影响,以便选取合适的门限值。图4为鼻音检测准确率和正确率与门限值选取的变化关系。图中的正确率与准确率分别为绝对变化量,即为经过后处理各过程得到的正确率和准确率与基于SVM得到的正确率和准确率之差。
图4(a)为不同的ThDura下的检测结果比较。可以看到,ThDura选择在80ms较为合理。图4(b)为不同ThBM下的检测结果比较。可以看到,ThBM选择在0.2较为合理。图4(c)为不同ThMLR下的检测结果比较。可以看到,ThMLR选择在1.2较为合理。图4(d)为不同ThHLD下的检测结果比较。可以看到,ThHLD选择在0.1较为合理。表2为对鼻音检测结果依次进行各过程的处理后正确率、准确率、正确个数、插入个数和删除个数的变化过程。其中ThDura=80ms,ThBM=0.2,ThMLR=1.2,ThHLD=0.1。

图4 检测性能随门限值的变化

表2 经过后处理的检测性能
由表2可知经过后处理能在保证较高正确率的基础上,有效地去除插入错误,提高准确率。后处理所采用的特征参数能刻画易混音段与鼻音的差异,具有良好的区分特性,各过程都能较好地提高检测性能,且提高的性能相当,能起到互补的作用。通过对剩下的几个插入错误进行分析,得知这四个韵母鼻音化的程度较高,声学性质与鼻音非常类似。由实验结果可知,本文所采用的鼻音检测框架是合理的。
目前常用的鼻音检测方法[8]是基于中、低频带能量特征,该方法先对语音信号进行短时傅氏变换得到宽带语谱,然后根据语谱求得中、低频带的能量特征,其中低频带能量是指150Hz~1 000Hz频带的能量,中频带能量是指1 000Hz~3 000Hz频带的能量。表3为本文方法与基于中、低频带能量的鼻音检测方法的性能比较。
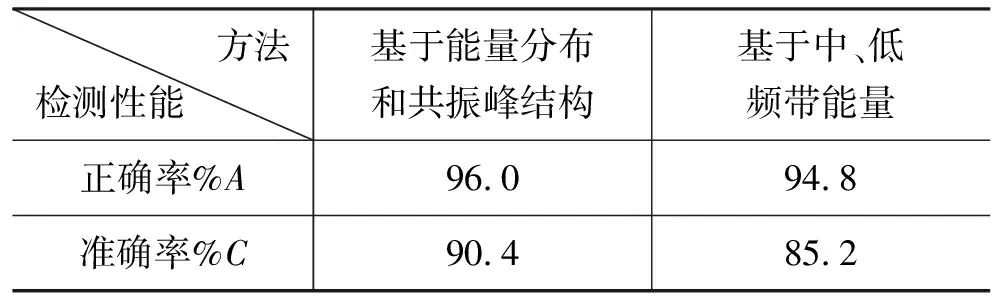
表3 不同鼻音检测方法检测性能
由表3可知本文方法与常用的基于中、低频带能量的鼻音检测算法相比正确率略有提高,但能较为明显地提高检测准确率。因为发音能量微弱的元音韵母和摩擦音/r/,在150Hz~1 000Hz和 1 000Hz~3 000Hz 这两个频带上也有着与鼻音类似的特性,这种检测算法会引入较多的插入错误,降低检测准确率。本文方法通过分析易与鼻音相混的声韵母能量分布和共振峰结构特性,采用后处理对插入错误进行了去除,提高了鼻音检测的准确率。
为了进一步验证鼻音检测算法的抗噪声性能,对本文确立的鼻音检测方法进行鲁棒性测试,表4为测试结果。

表4 鼻音检测鲁棒性测试结果
由表4可知,噪声对鼻音检测性能有较大影响,但在信噪比为10dB的环境下,本文算法的准确率仍能达到84.4%,说明本文鼻音检测算法具有较好的鲁棒性。这主要是由于Seneff听觉模型本身具有较好的抗噪声性能,且鼻音的能量分布和共振峰特性具有较好的稳定性,因此能较好地保证检测性能。在频谱上能量分布较为均匀的噪声,对能量分布和共振峰参数的影响较小,对鼻音检测性能影响不大,反之,噪声能量在频谱上分布不均匀,会给检测性能带来较大的影响。因此白噪声对检测性能影响最小,粉红噪声对检测性能影响最大。
4 小结
本文基于Seneff听觉谱特征提取了一组描述共振峰和能量分布的特征参数,实现了鼻音的检测。采用了一种先保证检测准确率再提高准确率的检测框架,并通过实验验证了这种框架对鼻音检测的合理性。经过鲁棒性测试,得知本文方法在鼻音检测上的有效性,能为后续的语音系统提供较为稳定的鼻音类别和边界信息。由于鼻音声母与鼻音韵尾不可避免的会对相邻元音韵母进行影响形成鼻化元音,同时相邻的声韵母也会对鼻音进行影响产生去鼻化现象,降低鼻音检测性能。如何有效地检测鼻化元音和去鼻化鼻音以及对鼻化和去鼻化程度进行量化,进一步提高鼻音检测的准确率是值得后续研究的。
[1]Chin-Hui.Lee.From knowledge-ignorant to knowledge-rich modeling:A new speech research paradigm for next generation automatic speech recognition[C]//Proceedings of ICSLP Keynote speech,2004.
[2]S.R.Mahadeva Prasanna,B.V.Sandeep Reddy,P.Krishnamoorthy.Vowel onset point detection using source,spectral peaks and modulation spectrum energies[J].IEEE Transactions on Audio,Speech and Language Processing,2009,17(4):556-565.
[3]Almpanidis G.,Kotti M.,Kotropoulos C..Robust Detection of Phone Boundaries Using Model Selection Criteria With Few Observations[J].IEEE Transactions on Audio,Speech,and Language Processing,2009,17(2):287-298.
[4]K.Y.Leung,M.Siu.Speech Recognition Using Combined Acoustic and Articulatory Information with Retraining of Acoustic Model Parameters[C]//Proceedings of ICSLP 2002,3:2117-2120.
[5]M.Hasegawa-Johnson,J.Baker,S.Borys,et.al.Landmark-based speech recognition:Report of the 2004 Johns Hopkins summer workshop[C]//Proceedings of ICASSP,2005:213-216.
[6]J.Morris,E.Fosler-Lussier.Further experiments with detector-based conditional random fields in phonetic recognition[C]//Proceedings of ICASSP,April,2007.
[7]Carla Lopes,Fernando Perdigão.A Hierarchical Broad-class Classification to Enhance Phoneme Recognition[C]//Proceedings of European Signal Processing Conference,2009,1760-1764.
[8]Limin Du,Kenneth Noble Stevens.Automatic Detection of Landmark for Nasal Consonants from Speech Waveform[C]//Proceedings of ICSLP 2006.
[9]Sarah E.Borys.An SVM Front-end Landmark Speech Recognition System[M].University of Illinois,2008.
[10]Stephanie Seneff.A joint synchrony/mean-rate model of auditory speech processing [J].Journal of Phonetics,1988,16:55-76.
[11]Stephanie Seneff.Pitch and Spectral Analysis of Speech Based on an Auditory Synchrony Model[M].Cambridge,Massachusetts Institute of Technology,1985.
[12]Ahmed M.Abdelatty Ali.Auditory-Based Speech Processing Based on the Average Localized Synchrony Detection [C]//Proceedings of Acoustic Speech and Signal Processing (ICASSP),2000,3:1623-1626.
[13]Ahmed M.Abdelatty Ali,Jan Van der Spiegel,Paul Mueller.Robust Auditory-Based Speech Processing Using the Average Localized Synchrony Detection[J].IEEE Transaction on Signal and Audio Processing,2001,10:279-292.
[14]语音与语言学词典[M].上海:上海辞书出版社,1981.
[15]Steve Young.The HTK Book(for HTK Version 3.4)[M].Cambridge University Engineering Department,2006:289.
