基于Berkeley DB的配电终端的设计
2012-06-22李少卿朱中华王文龙缪楠林
程 立 李少卿 朱中华 王文龙 缪楠林
(南京南瑞继保电气有限公司,南京 211100)
随着国网公司对智能电网的建设与推广,配网作为智能电网的重要组成部分,越来越受到重视[1]。配电终端作为信息的采集、控制单元,扮演着越来越重要的作用。同时也集成了越来越多的功能:①集成测量、控制、保护功能;②集成通信管理装置的功能: 能够实现配网电能表、电压无功控制器、监测仪等智能设备的接入与信息的转发;③集成光纤以太环网功能:可以支持以太环网(100M),可以直接接入光纤构成以太环网[2];④集成电压无功控制(VQC)功能:可以实现电容器的自动投切,提高电压质量;⑤集成历史数据、统计数据管理功能:提供多种数据历史量和统计分析值的分类存储、查询、召唤。
在配电终端中,对于历史数据,往往需要大容量的数据存储,而且要做到数据的快速存储、查询和删除等操作。传统的配电终端往往采用简单文件的存储方式,直接将历史数据写入文件中。由于没有对历史数据进行排序和建立索引表,查询、删除等操作采用遍历文件的方式,检索效率极其低下,难以做到在大容量数据条件下的快速操作。本文给出了基于Berkeley DB嵌入式数据库的配电终端的设计方案,实现了大容量数据的可靠存储和快速操作。
1 系统需求分析
随着国网公司两批试点城市配网建设的开展,配电终端的功能需求越来越趋于多样化。尤其对终端的变位数据、操作记录、统计数据的存储需要越来越强烈。配电终端对变位数据和操作记录的存储时间要求不小于3个月,而对统计数据,如日/月电压、电压(电流)极大(小)值、整点值、合格率、不平衡率等,存储时间不小于6个月,部分数据(如月电压合格率)等甚至需要存储不小于9个月。这些存储数据要求实现如下功能:
1)可靠存储:大量的数据能够快速存储到数据库中,做到不丢失、不差错。
2)快速查询:能够支持不同方向上数据的快速查询,不同方向包括远方配电主站、当地调试终端等。
3)快速删除:根据存储的时间、条目等要素,进行数据库的定期删除。
2 Berkeley DB简介
Berkeley DB是Sleepycat软件公司开发的一款健壮的,高速的工业级开源式嵌入式数据库系统,支持C、C++、Java等编程语言。Berkeley DB本身不到300K,却能管理多达256TB的数据。不支持复杂的SQL语言,避免了大量解析和处理开销,适用于实时系统、嵌入式应用等。Berkeley DB函数库和应用程序运行在同一地址空间,不存在服务器概念,具有零管理性,通过API访问数据。同时支持日志管理、数据压缩、备份和恢复等功能。此外,Berkeley DB支持开源,使用者可以免费下载到源代码,根据自己的需求对其进行裁减[3]。
3 系统总体设计
3.1 系统结构
软件的系统结构分为保护测控模块、实时库模块、历史库模块、组态配置模块、VQC模块等,如图1所示。其中保护测控等对实时性有着极为严格要求的模块运行在中断中,而实时库、历史库、VQC模块、组态配置等组件运行在任务中。各个模块之间松散耦合,通过注册机制建立联系,同时各个模块之间通过消息或者管道进行数据交换。
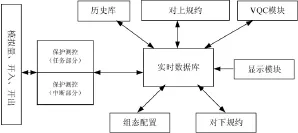
图1 系统结构
1)保护测控模块
保护测控模块分为两部分:中断执行部分和任务执行部分。中断每0.833ms运行一次,测量采用24点采样、并进行开入和开出的计算。保护采用傅立叶算法,设置三段式保护和零序保护。任务执行部分进行PT断线、线路失压、过负荷、电池管理、遥测等计算。
2)实时数据库模块
实时数据库模块:该模块包括实时数据库、调度端数据引用表的创建,运行时提供快速入库、快速提取数据操作。实时数据库还提供了对SOE、遥信变位、步位置变化等异步事件的支持。
3)历史数据库模块
历史库订阅实时库的变位信息,操作记录和统计数据。历史库就采用Berkeley DB的数据库来实现。BDB支持不同类型的存储,如线性表、哈希表、B树等。在本文的系统中,采用了B树的设计方法。历史数据库采用多个任务来实现,支持同步和异步两种方式,每种方式下实现数据的存储、检索、删除等操作[4]。
4)组态管理模块
组态管理模块:①生成和维护所连装置信息名表;②配置和维护一次间隔信息;③配置和维护板卡和规约信息;④配置和维护对时源;⑤生成和维护送往调度的转发信息表、并对规约需要的参数进行设置;⑥进行信息合成(遥测、遥信、步位置信息计算转换);⑦程序文件的下装、配置文件上装和下装[5]。
5)对上、对下规约模块
对上规约模块负责配电终端同远方主站进行数据通信,常用的有IEC101[6]、IEC104[7]、CDT[8]等规约。对下规约模块负责同电能表、电压无功控制器、监测仪等智能设备通信,常用的有CDT[8]、IEC103[9]、MODBUS等规约。
6)VQC模块
VQC根据测控装置采集的开关刀闸遥信进行主接线拓扑分析, VQC在每个运行周期的开始对接线关系进行一次拓扑分析,能实时的反映拓扑关系的变化,从而保证VQC调节建立在实时的系统拓扑基础之上,从而改善电压质量[10]。
7)显示模块
负责与实时库通信,将实时数据显示在液晶屏,并且将用户操作(修改定值、遥控开关)传递给实时库,负责完成人机交互。同时查看历史信息,包括操作记录、历史事件等。
3.2 历史库模块划分
如图2所示,历史库由三个模块组成:变位事件历史库、操作记录历史库、统计数据历史库。实时库发布订阅的信息给历史库,通过一个历史信息过滤器,丢弃掉无效数据,过滤出所需信息,分别发布给变位事件历史库、操作记录历史库和统计数据历史库,最终由这三个数据库来完成数据的存储。对上规约模块和组态模块通过历史信息操作器对数据进行操作,历史信息操作器提供操作接口,用以实现数据的快速检索和删除[11]。
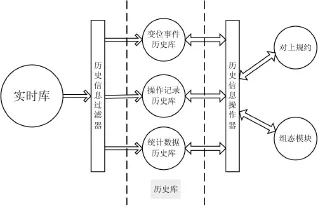
图2 历史库模块图
4 历史库功能模块实现
4.1 历史信息过滤器模块
实时库发布数据信息,历史库对这些数据信息进行处理。当实际系统触发一个变位事件(如开关变位、保护动作等),实时库会向历史库发布这个事件。事件参考IEC103规约中通用分类服务的格式,其中信息的关键字包括:装置地址、组号、条目号、时标、分合位置[9]。类似地,当远方调度或者当地(如液晶、调试终端)发出控制开关分合指令,实时库也会触发一个操作信息,通知历史库,信息的关键字包括:命令来源、装置地址、组号、条目号、时标、分合类型等。统计数据也是类似,但不同的是统计数据通过实时库内部的一个专门任务来实现,定时对数据进行扫描,其信息关键字包括:装置地址、组号、条目号、起始时间、终止时间、统计数值(通常是浮点数)。
当这些数据真正进入数据库存储之前,先要经过历史信息过滤器,过滤器的目的在于信息的删减和分类。过滤器按照内部约定好的格式,对数据进行下列检测:①对数据类型进行检验,如果发布的数据不属于变位事件、操作记录、统计数据,过滤器会做丢弃处理;②根据所属数据类型,进行长度验证,如果不符合,也做丢弃处理。当数据检测过后,符合完整性要求,过滤器负责对数据进行分发,根据不同的类型分别交给变位事件历史库、操作记录历史库、统计数据历史库来处理。至此,过滤器将外部的数据经过“净化处理”交给历史库。
4.2 历史数据存储模块
在嵌入式装置中,必须考虑装置意外掉电或者系统崩溃的情况。在意外掉电或系统崩溃的情况下,数据往往还没有来的及写入或者刚刚部分数据写入了flash,此时数据库往往记录数据发生错误,严重时可能破环数据库的完整性,造成数据库损坏。对于用户而言,丢失大量存储信息,造成不必要的损失。因此,在设计历史数据存储模块时,必须充分考虑这些情况。Berkeley DB提供了一种Transaction事务机制,当意外掉电或者系统崩溃的情况下,保证数据库信息的完整性。
为了应用Transaction机制,我们必须先建立一个environment环境,并且设置为线程安全,其次在这个environment下,指定数据库的创建方法,在这里我们采用BTree机制,并且指定数据的排序方法。在这里,我们先创建一级库(primary db),对于变位事件历史库、操作记录历史库、统计数据历史库均按照装置地址、时间、组号、条目号的优先级创建排序方法,其次创建二级库(secondary db)(在4.3节中详细介绍)。当过滤器完成信息处理后,历史数据库就来进行数据的存储了。数据库要调用txn_begin函数启动事务机制,将数据put进主库,接着commit提交数据,最后再调用sync同步二级库(secondary db)。
4.3 历史数据操作模块
Berkeley DB中,二级库(secondary db)提供了对数据库的多种检索方式。比如说,在DB1中,我们存储了key为员工ID,data为员工籍贯、工资等信息,而DB中存储了key为员工名字,data为员工ID,我们如果想要将几张表结合起来操作,就要用到二级库。
历史数据库创建后,应用模块需要对数据库进行操作,历史信息操作器就提供了相应的接口。对于三个历史库需要实现不同的检索/删除方式,具体来说:①变位历史数据库:按照时间跨度检索/删除、按照事件类型+时间检索/删除、按照FIFO顺序进行检索/删除;②操作记录历史数据库:按照时间跨度检索/删除、按照事件类型+时间检索/删除、按照FIFO顺序进行检索/删除;③统计数据历史库:按照时间跨度检索/删除、按照统计类型+时间检索/删除。要实现以上需求,必须用到Berkeley DB的二级库(secondary db)。
为了实现以上功能,单独创建一个任务来完成。首先,将检索条件生成关键字 key,然后通过创建游标cursor使用DB_SET_RANGE方法定位查询点,依次通过DB_NEXT的方法获得数据,直到检索区间越限。将检索到的数据采用同步或者异步的方式返回给应用模块。删除的方法也是类似,在此不再赘述。
5 测试
基于Berkeley DB的配电终端研制过程中做了各种测试对其性能进行验证。与传统的用简单文件结构方式进行存储的方式比较,具有明显的优势。笔者选择了10000条数据进行测试,其中检索、删除选择其中的100条。硬件平台:CPU为PowerPC,主频400M;内存64M;Flash为128M,操作系统为VxWorks。试验数据摘录见表1所示。
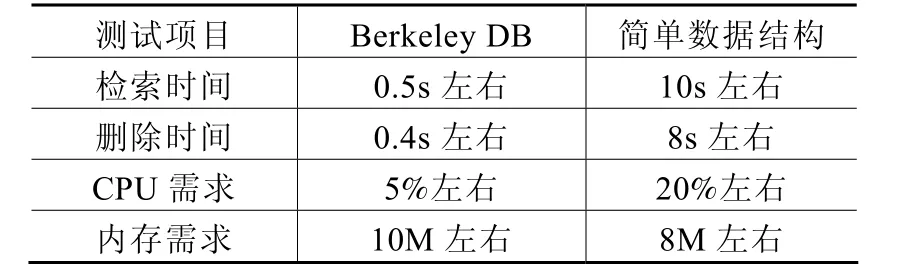
表1 数据库试验结果摘录
由此可以看出,在检索时间、删除时间、CPU需求方面,Berkeley DB远远超出简单的数据结构的存储方式。虽然在内存需求方面,由于Berkeley DB采用了复杂的数据结构,内存占用稍多一些,但对于64M的内存配置来说,完全可以忽略。
6 现场运行
本文设计的配电终端成功应用北京的开闭站中,典型的北京开闭站应用如图3所示:保护管理机对下接入10kV保护装置,采集遥信、遥测,实现远方遥控,对上接入配电终端,规约采用平衡式IEC101。低压表、网络表计及一些低压信号也接入配电终端,规约采用 MODBUS。配电终端通过通信设备,同配电主站进行连接,将信号远传,同时接受配电主站的控制命令,规约采用IEC104或者平衡式IEC101。
该终端自2008年在北京地区投运以来,为运行单位提供了大量历史数据:如保护动作信号、开关位置信号、电压合格率、不平衡率。积极促进了配电网故障隔离、故障恢复、电压质量的改进,保证了配电网安全稳定可靠的运行,提高了电网公司的生产效率,为建设智能电网起到了良好的示范作用。
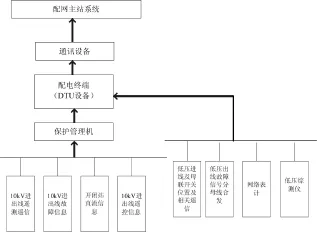
图3 开闭站结构图
7 结论
本文提出了Berkeley DB在配电终端的设计思路,并且成功实现在配电终端的研发上。和传统的配电终端相比,采用嵌入式数据库不仅占用CPU资源很少、系统开销较低、和应用紧密结合、系统健壮、伸缩性良好等特点,而且能够满足用户日益多样化的需求。本文提出基于Berkeley DB设计的配电终端,已经成功在北京、山东、青海等地使用,为用户提供了大量历史数据,减少了用户工作量,提高用户工作效率。
[1]陈树勇,宋书芳,李兰欣,沈杰. 智能电网技术综述[J].电网技术,2009,33(8):1-7.
[2]焦磊,叶继明.一种适用于配电自动化系统的新型以太网通信方式[J].继电器,2006,34(22):84-86.
[3]刘巍巍,徐成,李仁发.嵌入式数据库 Berkeley DB 的原理与应用[J].科学技术与工程,2005,5(2):86-90.
[4]刘钟情,余平. 基于 Berkeley DB的电力直流监控系统的设计[J].电力科学与工程,2008,24(4):53-55.
[5]王剑. 基于组件对象模型技术的变电站监控组态软件设计[D]. 西安:西安交通大学,2004.
[6]中华人民共和国国家经济贸易委员会.DL/T 634.5101—2002(idt IEC60870—5—101:2002)远动设备及系统第 5—101部分:传输规约基本远动任务配套标准[S].北京:中国电力出版社,2003.
[7]中华人民共和国国家经济贸易委员会.DL/T 634.5104—2002(idt IEC60870—5—104:2000)远动设备及系统第5—104部分:传输规约采用标准传输协议子集的IEC60870—5—101网络访问[S].北京:中国电力出版社,2002.
[8]电力部.CDT循环式远动规约(电力部行业标准 DL451—91)[S]. 北京:水利电力出版社,1991.
[9]中华人民共和国国家经济贸易委员会.DL/T 667—1999(idt IEC60870—5—103:1997)远动设备及系统第5部分传输规约第103篇继电保护设备信息接口配套标准[S].北京:中国电力出版社,1999.
[10]王顺江.关于软件VQC的研究和应用[D]. 大连:大连理工大学,2009.
[11]崔志强,翟永杰,陈昕,施建中. Berkeley DB在实时历史数据库中的应用[J]. 华北电力大学学报,2008,35(1):48-51.
