基于DOM和神经网络的网页净化应用
2012-06-01李剑
李 剑
(南昌陆军学院战斗实验室,江西南昌 330103)
互联网规模的几何级数增长和万维网的缺乏规范性,使网络信息检索与传统信息检索相比呈现出明显的不同之处:互联网络信息检索面向的对象为海量数据[1];互联网络信息检索所提供的信息内容包罗万象,形式多样。在这种情况下,网页净化技术成为网络信息检索特有的一个研究领域,受到越来越多研究人员的关注。对于有主题的网页,文中提出了基于DOM和神经网络的网页净化方法。
1 网页净化系统的模型
文中网页净化系统模型分为3个模块,分别对应系统处理网页的3个不同阶段:在第一个模块中,是把整个网页的文档分割成不同的内容块,然后对这些块进行分析;第二个模块是将内容块树中的按照给定标准选择出固定数量的子树,作为模块三的输入数据;模块三是神经网络的运行部分,能够选择出网页的主要内容块,模型图如1 所示[2-3]。

图1 整个模型框架图
2 网页净化方法
HTML文档是一种半结构化的文档,这里运用了HTML Parser工具对它进行解析。HTML DOM是一种树形的结构,通常被称为HTML DOM树。它的每个结点都代表一个块单元,这里把DOM树的结点分为两种[4]:(1)组织结点,例如:<table>,<tr>,<div>,<ui>等,是被用以划分整个网页的结构或组织网页的内容。(2)作非组织结点,展示网页内容,例如:<td>,<Ii>,<p>,<img>等。通常非组织结点包含在组织结点内。
2.1 建立内容块树
通过对大量带有主题的网页进行研究分析,发现这类的网页有着鲜明的特征,内容基本都是被按照所处位置不同被分割成几个内容块,几个内容块在视觉上都有区别,并且网页大部分都用 <table>或者<div>划分页面内容。因此,可借用这个特征,把一个网页转化成一个内容块树,而内容块树又是由子内容块树构成,子内容块树是由它所在的块中的一些相关DOM结点组成。这样,就方便地把一些有相关信息和有相似布局的DOM结点集中在一起,从而为下面去除噪音信息做好准备工作[5-6]。对此,设计算法如下:

(1)建立HTML文档的DOM树,然后把DOM树转化成DOM结点属性,同时把组织结点和非组织结点分别标上对应的标签。
(2)建立一个空的以<body>为根结点的内容块树,再把所有的组织结点给放进一个结点池里。
(3)从结点池中取一个结点。
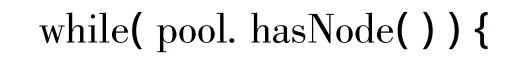
1)如该结点的左孩子是组织结点,则跳到2),否则跳到3);如该结点没有孩子,则跳到4)。
2)如该结点是<table>,<tbody>,<div>并且它的后代结点包含<p>,<li>结点的话,就把该结点和它所有的后代结点都放进到一个新的队列中去;否则就把该结点的左孩子给读进来,然后跳向1)。
3)如该结点的其它孩子结点都不是组织结点,则把该结点和它的后代结点都放进到一个新队列中去;否则,把它的其它孩子给读进来,然后跳向1)。
4)如该结点没有父结点或者它是<h1~h2>,<hr>,则把该结点标注成S(j++);否则把该结点,它的父结点和它所有的兄弟结点都放进一个新的列表中。
5)从结点池中取出下一个结点。
6)for((3)中建立的所有队列)。
7)检查每个队列中的父结点的所有属性,比如,fontsize,fontcolor等。若有一个孩子结点和父结点有相同的属性,这个父结点就将被作为一个分离结点从它的队列中移除。
(4)如果队列中的父结点中包含<h1~h6>的话,该父结点也会被作为分离结点从队列中移除。
高情千古一真隐——陶渊明的隐逸思想和隐逸生活探析………………………………………………………………………李兰东(3.49)
(5)根据建立队列的顺序在<body>结点下把所有的子内容块树线建立起来,最终一个完整对应于网页的内容块树也就建成了。
2.2 初步选择子内容块
在对主题型网页分析研究中,还发现一些网页内容在网页的展示中需要较多的HTML标签去进行修饰编码,特别是标题、边栏、广告栏、眉头和页脚等。从中可以统计出,与网页主题关系度较小的网页信息块,它所包含的HTML编码都较多。因此,为了从内容块树中抽取得网页的主要内容块,把冗余的不相关的或者相关度低的信息过滤净化掉,文中参考了子块中文本内容和HTML编码的比例特征对子块进行初步筛选:
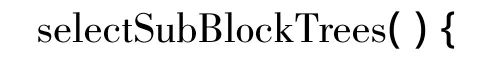
(1)设定子内容块占总内容文本比例的临界值和子内容块和它对应的HTML编码的比例的临界值。
(2)计算整个内容块树的文本大小。
(3)计算各个内容块子树的文本大小,并得出各文本占内容块树文本的比例。
(5)计算出各个内容子块和它对应的HTML编码的比例。
(6)通过上面的临界值,来综合选出用于作为神经网络的训练输入子内容块。
2.3 选择出主要内容块
本模块以BP神经网络为基础构建,整个模块分成两个阶段:训练阶段和测试阶段。
文中运用的神经网络由3层结构组成:输入层、隐含层和输出层。实验证明,多层神经元并不会使结果更优化,反而增加了计算的复杂度,因此采用标准3层结构。作用函数为非线性的Singmod型函数,表达式为

3 实验及分析
从新浪博客、网易体育和百度知道网上分别获取了3个不同类型的网页,数量都为600个,其中各自的500个网页用作训练,另外各自的100个网页用来测试。实验结果的分析通过3个指标来衡量,分别是正确率CR,误取率ER和漏取率LR。
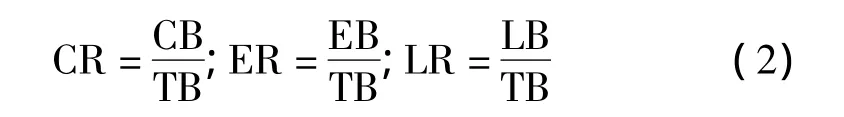
其中,CB是提取出的正确的内容块数;TB是总的主要内容块数;EB是误取的内容块数;LB是漏取的主内容块数。
在运用上述3个模块对实验数据进行实验后,依据实验结果计算出各自的3个指标数据,用柱状图表示如下。

图2 实验结果
如图2所示,无论从正确率、错误率和漏测率都能够比较正确地把网页中的冗余信息去除掉,通过从3类网页的分析和实验结果中,得出网易体育的主题性最强,其次是百度知道及新浪博客。而且网易体育的净化效果在3个指标中也是最好的。从而说明,该方法是对主题越突显的网页效果越好,适合用于网页分类应用中,比如搜索引擎。在搜索引擎按照一定的主题和算法爬取到网页后,要对这些网页进行分类和建立索引,这个净化方法就会为网页的分类提供较大的帮助。
4 结束语
在改进的DOM树和BP神经网络理论的基础上,设计了一种新的中文网页净化方法,通过实验结果,看到了该方法对于有主题网页净化的效果良好,且网页主题越清晰,效果越好。
[1]张志刚,陈静,李晓明.一种HTML网页净化方法[J].情报学报,2004(4):387-393.
[2]王建冬,王继民,田飞佳.一种基于内容规则的网页去噪算法[J].现代图书情报技术,2008(3):51-54.
[3]万乐,左万利,高金.基于主题的网页去噪音机制[J].计算机工程与技术,2008(8):2072-2084.
[4]刘亚清,陈荣.基于隐马尔可夫模型的 Web信息抽取[J].计算机工程,2009(18):25 -27.
[5]HIROSHI S,JUN R,MITSURU N.Modified minimum classification error learning and its application to neural networks[C].SSPR/SPR,1998,1451:785 -794.
[6]SHEN Dou,YANG Qiang,CHEN Zheng.Noise reduction through summarization for Web - page classification[J].Science Direct,Inf.Process.Manage,2007,43(6):1735-1747.
