地点信息在话题检测中的应用
2012-06-01谢林燕戚银城
谢林燕,戚银城,孙 卓
(华北电力大学电子与通信工程系,河北保定 071003)
随着信息传播手段的进步,尤其是互联网的出现,已对信息爆炸的情况,如何快捷准确地获取有效信息是人们关注的主要问题。由于网络信息数量过大,与一个话题相关的信息往往孤立分散在不同地方,并出现在不同的时间,仅通过这些孤立的信息,人们对某些事件难以做到全面把握。因此人们迫切希望拥有一种工具,能够自动把相关话题的信息汇总供人查阅。话题检测与跟踪(Topic Detection and Tracking,TDT[1])技术在这种情况下应运而生。话题检测与跟踪是一项旨在依据事件对语言文本信息流进行组织、利用的研究,也是为应对信息过载问题而提出的一项应用研究。话题检测是TDT测评中的一项测评任务,即将新闻数据流中的报道归入不同的话题,并在必要时建立新话题的技术。话题检测可分为两个阶段:检测新话题的出现和将后续报道加入相关的话题。图1为话题检测的基本思想。
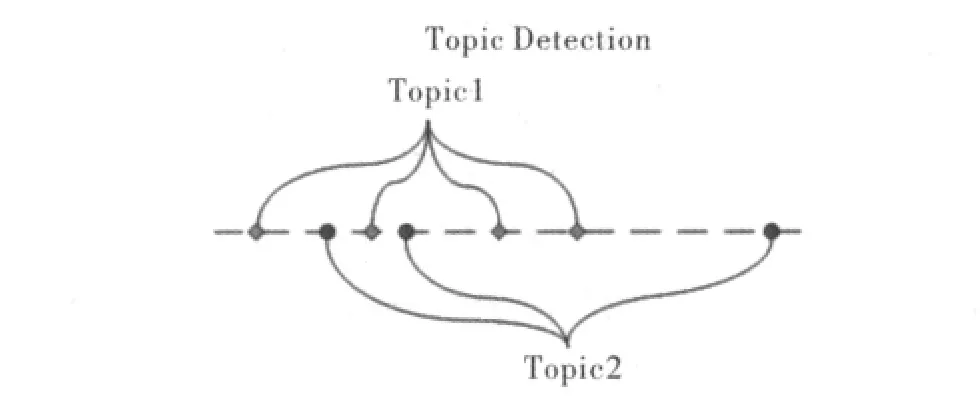
图1 话题检测基本思想
目前,已有多位学者针对话题检测技术展开研究,并取得了一定的进展。文献[2]提出了一种带有时间窗口的单遍聚类方法,话题和报道之间的相似度计算主要采用向量夹角余弦值,但根据时间因素利用一个时间窗口作调整。UMass[3]大学系统的核心算法仍是单遍聚类算法,在质心比较策略中,设置了两个阈值θmatch和θcertain,当前报道与某话题类的质心相似度高于θmatch时,就断定该报道应当归入此类,只有当它们之间相似度值高于θcertain时,才用当前报道调整该话题类的质心,即该话题类的向量表示。文献[4]提出了基于多层聚类的有向无环图生成算法,通过将单层文本聚类变为多层聚类,记录各层次间结点的合并过程,得到话题层次结构。文献[5]提出基于单遍聚类算法和改进的KNN算法相结合的方法进行话题检测。这些方法的共同点是均采用聚类的方法来实现话题检测,以语法信息为基础计算话题和报道的相似度,通过改进聚类方法来提高检测精度。然而在话题检测研究中存在一个难题,就是难以区分相似话题[6],比如两次不同的地震灾害或者恐怖事件,因为关于这些事件的报道中所用的词汇大部分是相同的,所以单一地依靠文本内容的相似度计算,难以将这些报道正确地进行分类。
文中将地点信息运用到话题检测中,将报道与话题语料用向量空间模型表示。改进基于Baseline模型中的文本内容相似度计算方法,将新闻报道中涉及的地点因素应用到相似度计算中,并与文本内容相似度相结合,两者的加权和作为最终的新闻报道与话题的相似度,由此来克服相似话题的难以区分问题。实验证明,该方法提高了检测精度。
1 建立报道与话题模型
1.1 预处理与报道模型
对收集到的报道语料进行分词,分词结果中含有大量的冠词、介词、连词等出现频率较高的词汇,其对文本表达的意思基本没有任何贡献,更多的作用在于语法上,即称为停用词。为去除噪声,降低后续处理流程的复杂度,减轻整个算法的计算开销,提高检测精度,首先要去除停用词。
采用VSM模型表示报道和话题。基本思想是:它把文本表示成为一个空间向量,向量的每一维代表该文本的一个特征(Term),假设F为经过预处理的报道,term1,term2,…,termm是报道S中的m个不同的词,那么S可以表示为:S=(term1,ω1;term2,ω2;…;termm,ωm),ωi是 termi在报道S中的权值,文中采用TF - IDF[7]公式来计算特征项权值
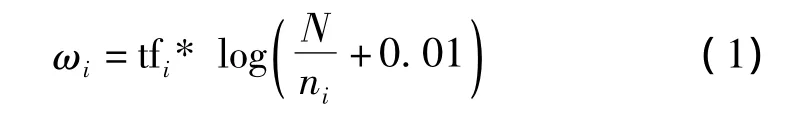
其中,tfi是termi在报道S中的词频;N是所有已输入报道的总数;ni是N篇报道中含有termi报道的数量。
1.2 话题模型
话题是用质心来表示,质心是用向量空间模型表示。为了将话题表示成质心,需经过抽取特征项和计算特征项权值两步。实验过程中,从收集到的相关语料中随机抽取4篇作为训练语料形成相应话题。首先对训练语料进行预处理,然后分别计算每篇训练语料的特征项权重。最后进行话题特征项的权重计算。文中通过式(2)计算话题特征项权重。
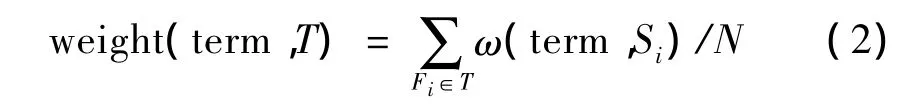
其中,weight(term,T)表示特征项term在话题T中的权重;Si是话题T中包含的新闻报道;N为话题T包含新闻报道的总数量;ω(term,Si)是特征项term在Si中的权重值。
2 报道与话题相似度计算
2.1 基于Baseline模型的报道与话题相似度计算
在基于Baseline模型的报道与话题的相似度计算中,选用向量夹角余弦函数作为相似度计算方法。假设报道S与话题T的向量空间模型分别为S=(ws1,ws2,…,wsn)和T=(wt1,wt2,…,wtn),那么报道S与话题T基于夹角余弦函数的相似度如式(3)所示。
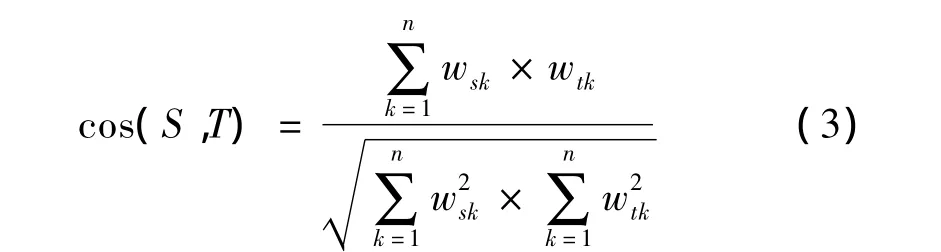
2.2 地点信息报道与话题相似度计算
特定话题中涉及到的地点信息在解决相似话题难以区分的问题中起着不可忽视的作用。由于相似话题通常采用相同的词语进行描述,如两次不同的交通事故或恐怖事件,仅采用基于Baseline模型的相似度计算方法很难将相似话题正确区分。文中提出结合地点信息的话题检测方法,通过构造地点相似度计算函数,获得地点相似度,并将其计算结果应用于话题检测中。实验结果证明,提出的结合地点相似度的话题检测方法能很好地改进系统性能指标。
提取报道的地点信息形成地点向量,并与相应话题的地点向量进行相似度计算,计算公式如式(4)所示。


将基于Baseline模型的相似度和地点相似度分别计算,通过两类相似度计算结果线性组合的方式得到最终的相似度

其中,α为设定的参数,实验中α=0.4。
3 话题检测算法
文中以Single-Pass聚类策略为基础实现话题检测算法,该算法按新闻报道输入的先后顺序依次处理信息流中的报道,直到所有的报道处理完毕,具体过程如下:
(1)对新闻报道进行预处理,然后利用上述的特征权重计算方法计算报道和话题中各个特征词的权值,分别建立报道模型和话题模型。
(2)计算新闻报道与话题的相似度,与预设的阈值进行比较,报道与话题的相似度高于阈值,则判定该报道与话题相关,否则判定该报道与话题不相关。
(3)重复上述过程直到信息流中的所有报道都处理完毕。
4 实验结果与分析
4.1 评价指标
文中实验采用的性能指标为正确率(Precision)、召回率(Recall)和F1指数,其定义如表1所示。
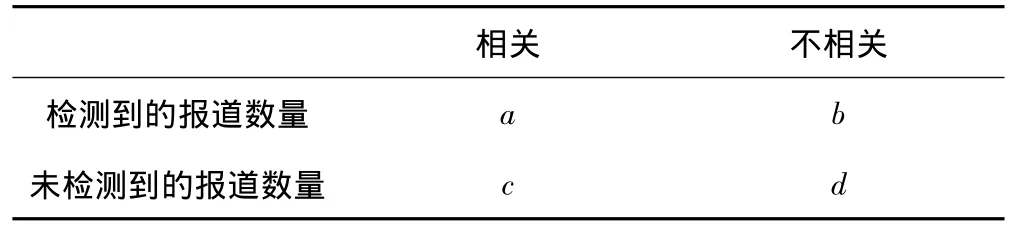
表1 评价指标
其中,收集到的测试新闻语料中与话题相关的报道数目为a+c,不相关的报道数目为b+d。检测结果中,判定与话题相关的报道数目为a+b,不相关的报道数目为c+d。正确率、召回率和F1指数计算方法如下所示。

4.2 实验结果与分析
实验采用从互联网收集到的新闻报道作为评测语料,该语料包含725篇中文报道,定义了10个话题,表2为话题事件与相关新闻报道数目。
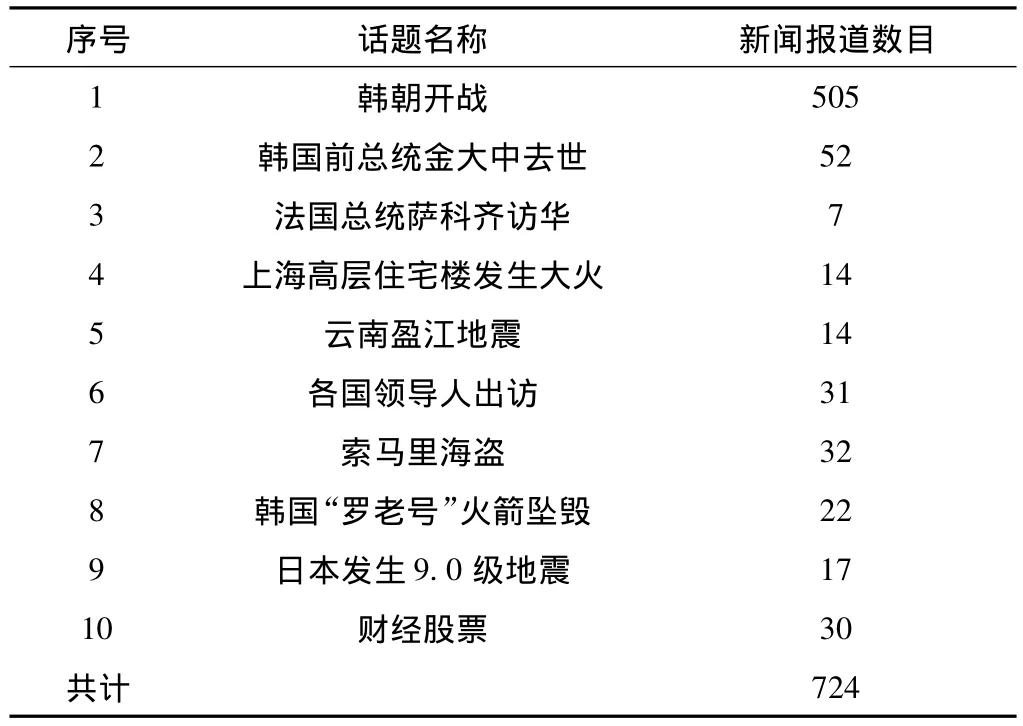
表2 话题事件与相关新闻报道数
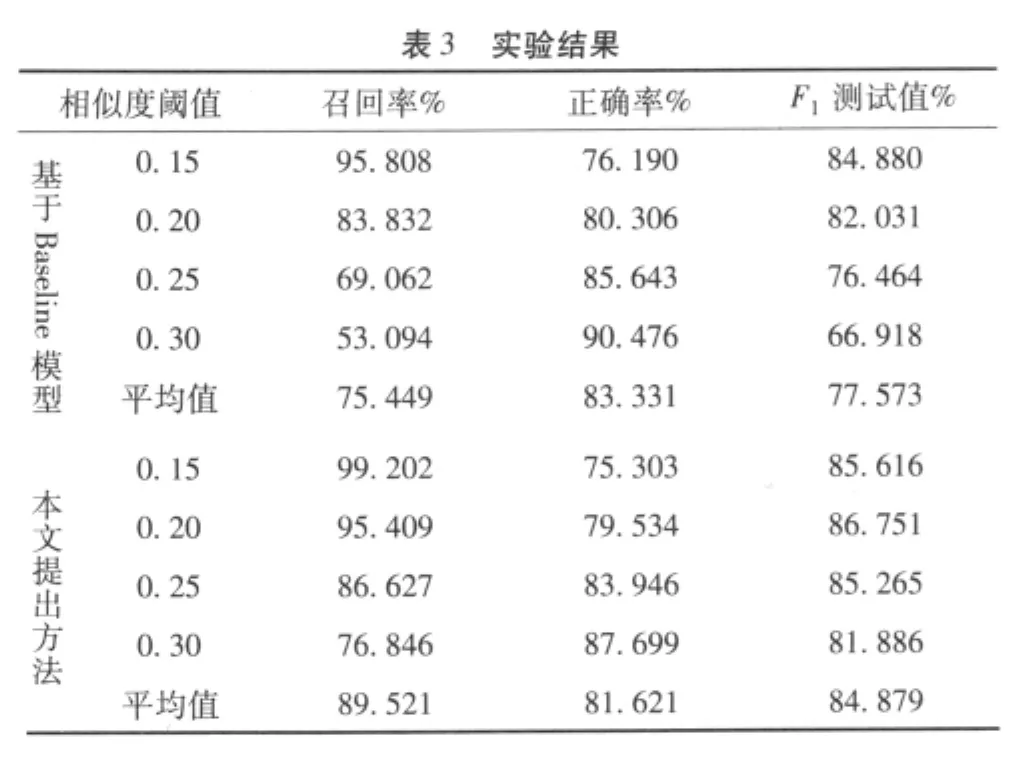
随机选取4篇与韩朝开战相关的新闻报道作为训练语料,构建话题模型,剩余720篇新闻报道作为测试语料,其中选取韩朝开战事件作为本次实验的相关话题,其余话题作为与该话题不相关的反例话题,共计219篇。分别对基于Baseline模型和结合地点信息两种方法进行实验对比,实验结果如表3所示。
?
由上述实验可知,通过设定不同的相似度阈值发现,随着该值的增大,正确率提高,召回率下降;结合地点信息的话题检测方法的召回率在同等条件下,高于基于Baseline模型的检测结果,同时,F1测试值较Baseline模型改进了7.306%,说明结合地点信息的话题检测系统的检测性能优于基于Baseline模型的话题检测系统。综上所述,将地点信息应用到话题检测是一种行之有效的方法。
5 结束语
针对话题检测方法进行了初步研究,通过分析新闻报道语料的特点,将新闻报道中的地点信息融入报道与话题的相似度计算中,即构建地点相似度计算公式,并结合基于Baseline模型的相似度计算结果,将两类相似度的计算结果进行线性组合,从而得到报道和话题的相似度计算结果,完成话题检测任务。实验结果表明,将地点信息应用于话题检测能够提高性能指标。
[1]李保利,俞士汶.话题识别与跟踪研究[J].计算机工程与应用,2003,39(17):7 -10.
[2]YANG Y,CARBONELL J,BROWN R,et al.Multi- strategy learning for topic detection and tracking[C].Proc.of the TDT2002 Workshop,2002:85 -114.
[3]KUPIEC J,PEDERSEN J.A trainable document summarizer[C].Seattle,Washington,USA:Proceedings of the 18th Annual Int'l ACM SIGIR Conf on Research and Development in Information Retrieval(SIGIR'95),1995:68 -73.
[4]于满泉,骆卫华,许洪波,等.话题识别与跟踪中的层次化话题识别技术研究[J].计算机研究与发展,2006,43(3):489-495.
[5]李保利.汉语新闻报道中的话题跟踪与识别研究[D].北京:北京大学,2003.
[6]洪宇,张宇,刘挺,等.话题检测与跟踪的评测及研究综述[J].中文信息学报,2007,21(6):71 -87.
[7]刘海峰,王元元,刘守生.一种组合型中文分类特征选择方法[J].广西师范大学学报:自然科学版,2007,25(4):208-211.
