基于双门限两级判决的语音端点检测方法
2012-06-01路青起白燕燕
路青起,白燕燕
(西安工业大学电子信息工程学院,陕西西安 710032)
端点检测是语音信号处理中的一个基本问题,其目的是从包含语音的一段信号中确定出语音的起点及结束点。有效的端点检测不仅能使处理时间减到最少,而且能抑制无声段的噪声干扰,提高语音信号质量。有学者用一个多话者的数字语音识别系统做实验。首先对所有记录的语音用手工找出准确的端点,得到辨识率;然后逐帧加大端点检测的误差,在每次加大误差的同时得到识别率。结果表明,端点检测准确时识别率为93%的系统,当端点检测误差在±60 ms时,识别率降低了3%;在±90 ms时,降低了10%;而当误差进一步加大时,识别率急剧下降[1]。语音端点检测的成败,直接影响着后续工作的正确率乃至整个语音识别系统的成败。
端点检测的常用方法有:能量阈值、基音检测、频谱分析、倒谱分析及 LPC(Linear Prediction Coefficients)预测残差等。其中基于能量和过零率的双门限判决法最为常用。在许多语音信号处理任务中需要判断,一段输入信号中哪些是语音段,哪些是无声段,哪些是噪声,哪些是语音。在一些语音识别或低速语音编解码器应用中,对于已经判别为语音段的部分,还需进一步判断清音和浊音。这些问题可以称为有声或无声判决,以及更细致的无声(S)、清音(U)、浊音(V)判决[2]。能够实现这些判决的依据在于,不同性质语音的各种短时参数具有不同的概率密度函数,以及相邻的若干帧语音具有一致的语音特性,不会在无声,清音和浊音之间随意跳变。文章比较了利用短时能量和短时平均过零率进行端点检测的方法,并运用双门限两级判决法在Matlab中。
1 语音信号的短时能量分析
语音信号的能量随时间变化比较明显,一般清音部分的能量比浊音部分的能量小。语音实现了端点检测的编程和仿真。
信号的短时能量分析给出了反应这些幅度变化的一个合适的描述方法。对于信号x(n),短时能量的定义如下

式(1)中,h(n)=ω2(n),En表示在信号的第n个点开始加窗函数时的短时能量。可以看出,短时能量可以看作语音信号的平方经过一个线性滤波器的输出,该线性滤波器的单位冲击响应为h(n),如图1所示。

图1 语音信号的短时平均能量实现框图
冲激响应h(n)的选择,或者说窗函数的选择决定了短时能量表示方法的特点。为反应窗函数选择对短时能量的影响,假设式中的h(n)非常长,且为恒定幅度,那么En随时间的变化将很小,这样的窗就等效为很窄的低通滤波器。h(n)对x2(n)的平滑作用较显著,无法反映语音的时变特性。反之,若h(n)序列长度N过小,那么等效窗不能提供足够的平滑,以至于语音振幅瞬时变化的许多细节仍被保留,从而看不出振幅包络的变化规律。通常N的选择与语音的基音周期相联系,一般要求窗长为几个基音周期的数量级。
短时能量主要用于区分清音和浊音,因为浊音比清音的能量大得多;其次可以用短时能量对有声段和无声段进行判定,对声母和韵母分界,以及对连字分界等。在语音识别系统中,短时能量一般也作为特征中的一维参数来表示语音信号能量的大小和超音段信息[1]。
短时能量的一个主要问题是En对信号电平值过于敏感。由于需要对信号进行平方运算,在定点实现时容易产生溢出。解决这个问题的方法是采用短时平均幅度来表示能量的变化,其公式是

与短时能量相比,短时平均幅度相当于用绝对值之和代替了平方和,简化了运算,窗长N对平均幅度函数的影响与短时能量的分析结论是一致的。但平均幅度函数没有平方运算,因此其动态范围比短时能量小,接近于标准能量计算的动态范围的平方根。图2是“西安工业大学”的波形图。

图2 “西安工业大学”波形图
图3是语音“西安工业大学”的短时能量分析图,图4是“西安工业大学”的短时平均幅度的分析图。
从图3和图4中可以看到,尽管短时平均幅度也可用于区分清音和浊音,无声和有声,但二者之间的幅度差就不如短时能量那么明显。

2 短时平均过零率
短时平均过零率是语音信号时域分析中的一种特征参数。它是指每帧内信号通过零值的次数。对于连续语音信号,可以考察其实域波形通过时间轴的情况。对于离散信号,短时平均过零率实际就是信号采样点符号变化的次数。短时平均过零率仍可以在一定程度上反映其频谱性质,可以通过短时平均过零率获得谱特性的一种粗略估计。短时平均过零率的公式为

其中,sgn是符号函数即

图5给出了短时平均过零率的计算过程。

图5 短时平均过零率的计算
首先对语音信号序列x(n)进行成对处理,检查是否有过零现象,若有符号变化,则表示有一次过零现象;然后进行一阶差分计算,取绝对值;最后进行低通滤波。
短时平均过零率可以在一定程度上反映频率的高低,因此在浊音段,一般具有较低的过零率,而在清音段具有较高的过零率,可用于初步判断清浊音。
在矩形窗条件下,式可以简化为

图6和图7均是“西安工业大学”语音波形图与短时平均过零率。

从图中可以看出,在背景噪声较小的情况下,短时能量较准确,但当背景噪声较大时,短时平均过零率可以获得较好的检测效果。有些发音仅用短时能量或短时平均过零率来判断起点和终点比较困难,由于短时平均幅度更适合检测浊音,而短时过零率更适合检测清音,因此将短时平均幅度和短时平均过零率相结合进行端点检测是一种有效的端点检测方法。
3 双门限判决法
在开始进行端点检测前,首先为短时能量和过零率分别确定两个门限。一个是较低的门限,其数值较小,对信号的变化较敏感,很容易被超过。另一个是比较高的门限,数值较大,信号必须达到一定的强度,该门限才可能被超过。
基于Matlab程序实现能量与过零率的端点检测算法步骤如下:
(1)语音信号x(n)进行分帧处理,每一帧记为,n=1,2,…,N,n为离散语音信号时间序列,N为帧长,i表示帧数。
(2)计算每一帧语音的短时能量,得到语音的短时帧能量

(3)计算每一帧语音的过零率,得到短时过零率

其中
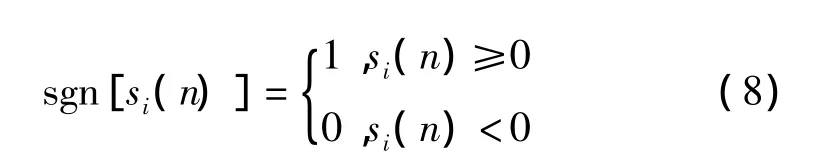
(4)考察语音的平均能量设置一个较高的门限T1,用以确定语音开始,然后再根据背景噪声的平均能量确定一个较低的门限T2,用以确定第一级中的语音结束点,T2=α1EN,EN为噪声段能量的平均值,完成第一级判决。第二级判决同样根据背景噪声的平均过零率ZN,设置一个门限T3,用于判断语音前端的清音和后端的尾音。α1,β1为经过大量实验得到的经验值。图8是语音“西安工业大学”的端点检测图。

图8 语音“西安工业大学”的端点检测
图8可以看到检测结果:将短时平均能量和短时平均过零率结合,进行端点检测,可以很好地检测语音的开始和结束。虽然这种方法可以有效地区分语音信号中的清音和噪声,但它难区分语音信号中的浊音和噪声,也存在检测时漏掉某些音素这一问题。因此对于端点检测仍需进一步研究。
4 结束语
针对声纹识别系统所作的端点检测前端处理,运用Matlab实现了双门限法端点检测的编程和仿真,仿真结果显示,端点检测准确识别率为93%。
[1]赵力.语音信号处理[M].北京:机械工业出版社,2010.
[2]韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004.
[3]何强,何英.Matlab扩展编程[M].北京:清华大学出版社,2002.
[4]张雪英.数字信号处理及Matlab仿真[M].北京:电子工业出版社,2010.
[5]尹巧萍,吴海宁,赵力.含噪语音信号端点检测方法的研究[C].成都:2008'促进中西部发展声学学术交流会论文集,2008.
[6]刘建,郑方,吴文虎.基于幅度差平方和函数的基音周期提取算法[J].清华大学学报:自然科学版,2006,46(1):74-77.
[7]张仁志,崔慧娟.基于短时能量的语音端点检测算法研究[J].电声技术,2005(7):52 -59.
[8]陈艳.改进的独立分量分析在语音分离中的应用[J].电子科技,2009,22(12):87-91.
