基于情绪认知评价理论和Q-learning的人机交互中情感决策
2012-05-15赵涓涓杨建峰陈俊杰王玉友
赵涓涓,杨建峰,陈俊杰,王玉友
(太原理工大学 计算机科学与技术学院,太原030024)
在最近几年中,人们在认知心理学、认知科学和神经科学等领域的研究进一步表明:情感、情绪在人们的推理、学习、记忆、决策和创造的过程中饰演着非常重要的角色。所以,在人工智能领域中有一个越来越受到关注的新的研究方向——人工情绪。随着科学技术的进步,人们越来越希望计算机或机器人能够替代和辅助人类从事越来越广泛、越来越复杂的工作,并且要求其具有自然和谐友好的人机界面,更希望它们具有更多的类人功能,如感知功能、思维功能和行为功能等。
自然和谐友好的人机交互是人工智能领域的一个重要研究目标,想要实现这一目标,就必然要求计算机和机器人具有更强的情感识别、情感理解和情感表达能力[1]。人工情感的研究目的就是探索情感在生命体中所扮演的一些角色、发展技术和方法,以此来增强计算机或机器人的适应能力、自治性和社会交互的能力[2]。在自然和谐的人性化和智能化的人机交互研究中,生物信息处理机制有很好的借鉴意义,已经有很多学者在这些方面做了大量工作,同时也获得了非常不错的研究成果。例如,借鉴人类脑神经机制,人们建立了人工神经网络;借鉴生物的进化机制,人们提出了进化算法等。但也存在一些问题,由于生物的行为除了受神经系统和进化系统的调节外,还受认知与情感系统的控制,但是在大部分的机器学习算法中忽略了认知与情感的高层调节作用,因此在人机交互的过程中机器不具有情感反馈的能力,即机器的情感感知与情感决策能力在人机交互中被遗忘了。笔者受生物系统控制论和认知心理学的启发,采用神经、进化和认知去共同控制机器人的情感决策,借鉴人工情感系统的调节作用,研究基于情绪认知评价理论的情感决策。
1 基础理论
1.1 情感计算与人工情感理论
Picard给出的有关情感计算的定义为:关于、产生于或故意影响情感方面的计算[2],它主要集中在情感的发生、识别和情感的表达上,直接研究人类的情感过程(包括人类情感的本质内核和运动形式),试图使计算机拥有情感,即构建一个具有“自发情感的情感平台”,从而使计算机具备情感决策能力和情感行为。情感计算领域高度综合化,它通过计算科学与心理科学、认知科学相结合,研究的范围包括人与人之间的交互、人与计算机之间的交互过程中的情感特点,设计出具有情感反馈的人机交互环境,将有可能使人与计算机的情感交互成为可能。
人工情绪(artificial emotion)是通过信息科学的手段来模拟人类情绪过程,进而对人类的情绪进行识别和理解,属于机器能够产生类人情绪并且和人类进行自然和谐的人机交互的研究领域[3]。目前对人工情绪的研究主要有以下几个领域:情感计算(affective computing)、感性工学(kansei engineering)和人工心理。
1.2 情绪认知评价理论
在情绪认知理论中,情绪产生于对刺激情景或者事物的评价,影响情绪产生的因素包括环境事件、生理状况和认知过程,其中认知过程是决定情绪性质的关键。同一刺激情景,由于对它的评估不同就会产生不同的情绪反应。Richard的情绪认知评价理论(cognitive appraisal theory)认为,人和环境相互作用产生了情绪,人不仅接受环境中的刺激事件对自己的影响,同时要调节自己对刺激的反应,主要包括初评价、次评价和再评价[4]。
Ahn与Picard提出的情感认知学习与决策的框架模型和Ahn提出的一个简单的情绪认知模型的根据即认知评价理论中非常重要的一点——认知过程是决定情绪性质的关键因素[5]。
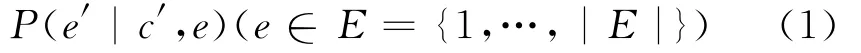
式中:e代表当前的情绪状态;c′代表下一认知状态;e′代表下一情绪状态。
2 基于情感认知评价理论的情感决策算法
2.1 Q-learning学习思想
Q-learning是强化学习中非常经典的算法之一,Q-learning算法主要应用于机器人行为决策和控制领域,其中包括单个自主机器人行为的学习和多个机器人群体行为的学习。Q-learning学习是一种不同于监督学习和无监督学习的在线学习技术。它将学习当成是一个“试探——评价”的过程,学习系统会首先感知外部环境状态,然后对环境采取某一个动作,环境接受该动作后,其状态会发生相应的变化,同时会给出一个回报(reward)反馈给主体,主体根据强化信号和环境的当前状态再进行下一个动作的选择,选择的原则是使受到奖励的概率增大[7]。由于基于情感认知的学习与决策算法采用了强化学习的理论框架,因此在认知奖励模块(cognitive reward model)和情绪奖励模块(emotional reward model)两个模块中主要采取了强化学习中的Q-learning算法。Q-learning学习的积累回报函数Q(s,a)是指在状态s执行完动作a后希望获得的积累回报,它取决当前的立即回报和期望的延时回报。所有状态与动作对应的Q值存放在一张二维的Q表中,Q表中的值在每一步完成后都会被更新一次,更新二维表时Q函数的具体计算公式为:
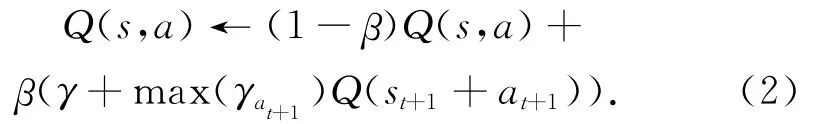
式中:β为学习因子且0<β≤1;γ为折算因子且0≤γ<1;γ为奖励。
Q-learning学习是按照递归方式实现的该方法:在每一时间步t,观察当前状态st,根据某种选择原则选择行为at并且执行行为at,再观察后继状态st+1以及获取奖赏值γt,然后根据公式(2)调整Q表中的值[10]。Watkins已经证明当学习因子满足一定条件时,Q-learning学习算法必定收敛在最优解。
2.2 算法思想
在目前的机器学习中,大多数的学习决策算法仅仅考虑了来自于外部目标或代价的外在动机的奖励,而忽略了来自于内在认知与情感的动机奖励。近几年来,一些学者受到认知心理学和认知神经学关于情感与认知研究的启发,已经开展了将认知模型与来自内在情感的动机模型相结合的研究工作。MIT多媒体实验室的Ahn和Picard提出了基于情感和认知的学习与决策框架,并研究了单步决策任务和连续决策任务[5]。在MIT情感计算研究小组提出的模型中,同时考虑了来自情感的内在奖励和来自认知的外部奖励,并将它们作为了决策和学习的动机。
Q-learning学习不仅能够利用有限的学习经验获取大范围知识,还具有很强的泛化能力[7]。函数比较功能是神经网络要实现的主要功能,若从这个角度来看,神经网络可以分为全局逼近网络和局部逼近网络。如果网络的一个或多个连接权系数在输入空间的任一点对任何一个输出都有影响,则称该网络为全局逼近网络;若对输入空间的某个局部区域,只有少量的连接权影响网络的输出,则称该网络为局部逼近网络。传统的Q-learning算法利用表格来表示Q(s,a)函数即相应的状态-动作对应值以表格的形式存储到内存当中,该方法的优点是简单并且计算的效率高,缺点是当情感状态与认知状态集合S、情感行为动作集合A都比较大的时候,该方法会占用大量的内存空间,并且不具备泛化能力,这样不但占用大量的内存空间而且学习收敛速度非常慢,情感状态信息连续将无法实现。在本算法中BP神经网络的工作方式是:接收外界环境的完全或不完全状态描述即交互人的情感状态和认知状态,将其看做BP神经网络的输入,并通过BP神经网络对其进行计算,输出Q-learning学习算法中所需要的Q值,通过Q值在情感行为集合A中寻找与之对应的情感行为,然后情感虚拟人做出刚刚查找到的情感行为[8]。采用BP神经网络实现Q-learning学习算法克服了传统Q学习存在的问题,使Q-learning学习算法具备更强的泛化能力以实现对一个大范围知识的有效获取和表示,在较大程度上发挥了两种技术各自的优势。该算法主要思想框架见图1。
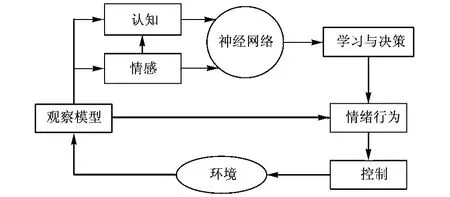
图1 基于BP神经网络和Q-learning情感决策算法框图
2.3 算法步骤
1)初始化外在情绪状态空间集E={喜悦、悲伤、恐惧、生气}和认知状态集C={幼年、少年、青年、成年};
2)获取当前的认知状态ct∈{c1,…,c|C|}、交互者的情感状态at∈{a1,…,a|A|},并且更新情感智能体的外在情绪概率分布e
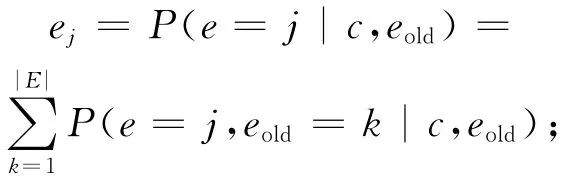
3)把当前的认知状态信息和情感状态信息送到BP神经网络的输入层中,通过决策值公式(决策值QDM由来自认知评价系统的外部决策值Qext和来自情感模型的内在决策值Qint构成)计算并输出决策值QDM;
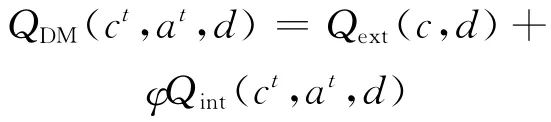
4)根据Boltzmann选择策略[5]计算出行为策略d

5)执行决策d,由BP神经网络获得一个新的认知状态ct+1,并且通过计算如下公式获得外部奖励值rext

7)利用外在奖励的情绪模型QEER(j,c,d)更新外在情绪状态的概率分布;
8)利用情感认知决策模型QDM(j,c,d)更新外在情绪状态与情感行为对应关系;
9)返回第(2)步继续执行。
3 仿真试验
情感迷宫问题模型是验证情感决策的经典环境。在Matlab中的仿真环境实现该算法,可在仿真过程中直观地观测情感智能体在为得到某一种特定情绪时的移动路线和移动情况。情感智能体在情感迷宫中通过学习能够以最快的速度搜索到目的情绪,并且在寻找过程中躲避不需要的其他情绪。情感智能体通过观察获得当前认知状态和情感状态,并且通过Boltzmann选择策略计算出行为策略,然后执行相应的动作,若遇到障碍物则会受到惩罚;相反的,若没有遇到障碍物则得到奖励。智能体在迷宫中寻找目的地的路线和性能的表现如图2所示。
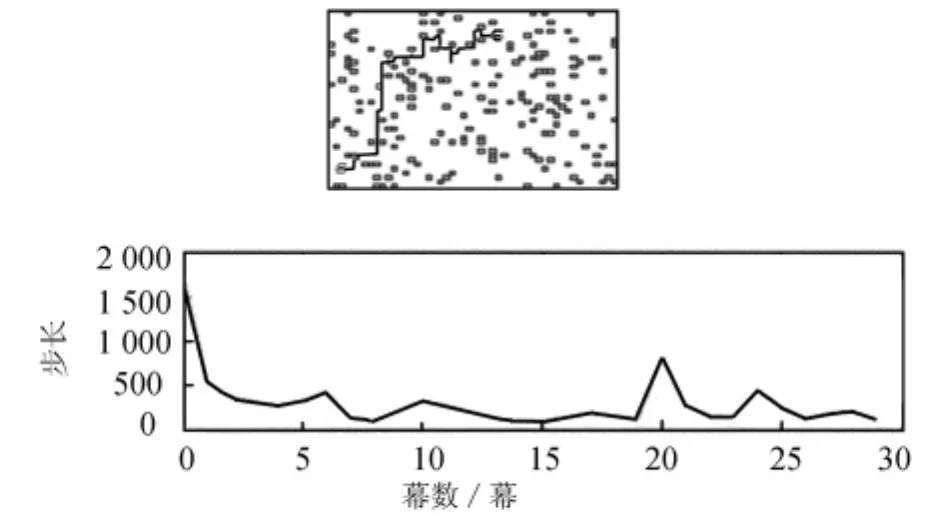
图2 情感迷宫模型和性能曲线
在图2所示的情感迷宫模型和性能曲线中,基于情感认知评价理论的情感决策算法中的参数选择如下:学习效率α=0.1;折算因子γ=0.9;温度参数初始值T=100。BP神经网络的结构是4-8-4,隐含层激励函数是Sigmoid函数,输入输出为线性函数。为了更清楚地观察自适应状态构建方法的有效性,与采用传统Q-learning算法中函数方法进行仿真结果对比。在传统算法状态空间构建中参数α大小分别设为0.1和0.4两种情况。
图3与图4分别为传统Q-learning学习算法与基于情感认知评价理论的人机交互情感决策算法下情感虚拟人获得平均报酬和成功找到目标情感时的试验次数对比结果。从图3中可以看出,BpQ-learning算法的性能优于传统Q-learning算法的性能。对于传统的Q-learning算法来说,分割越小性能越好,当α=0.1时,经过200次试验训练后,其平均报酬可达0.72,而BpQ-learning算法的平均报酬可达1.1,因此很明显使用BpQ-learning算法的情感虚拟人在寻找目的情感的试探过程中获得奖励要比使用传统Q-learning算法的情感虚拟人获得的奖励高。图4为情感虚拟人在使用两种算法寻找目标情感时试探次数的对比结果,从图4中可以看出,两种算法在第一幕的时候几乎是经过相同的试探次数才找到目标情感,但是随着幕数的增加,基于情感认知评价理论的情感决策算法用越来越少的试探次数找到目标情感,说明BpQ-learning算法的学习能力要比传统Q-learning算法的学习能力强、学习得快,但是随着幕数的增加传统Q-learning算法几乎也能达到BpQ-learning算法的试探次数。

图3 BpQ-learning与Q-learning的平均奖励值比较
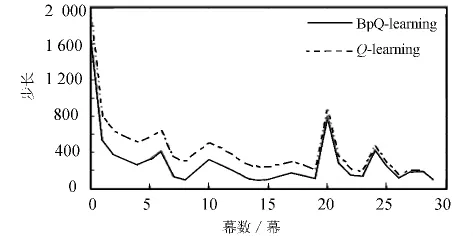
图4 BpQ-learning与Q-learning的试探次数比较
4 结束语
本文改进了一种基于认知、情感的内在奖励与外在世界的外部奖励相结合作为在学习和决策动机的学习与决策算法,同时把BP神经网络运用到该算法中。采用BP神经网络来代替Q表格,这样的改进不仅提高了Q学习的泛化能力,而且能够大大缩减了计算量,在一定程度上提高学习的精度,增强稳定性。未来的工作将会进一步更详细地证明基于情绪认知评价理论的人机交互情感决策的实效性,以及试验最优化该算法的各种参数因子并且在更复杂的环境中验证该算法的可靠性与先进性。
[1] 王志良,王巍,谷学静,等.具有情感的类人表情机器人研究综述[J].计算机科学,2011,38(1):34-39.
[2] Picard R W.Affective Computing[M].Cambridge:MIT Press,1997.
[3] 王国江,王志良,杨国亮,等.人工情感研究综述[J].计算机应用研究,2006,23(11):7-11.
[4] 黄希庭.心理学导论(第二版)[M].北京:人民教育出版社,2007.
[5] Ahn H,Picard R W.Affective-cognitive learning and decision making:the role of emotions[C]∥Proceedings of the 18th European Meeting on Cybernetics and Systems Research.Vienna,Austria:Austrian Society for Cybernetics Studies,2006.
[6] 吴忠植.认知科学[M].合肥:中国科学技术大学出版社,2008.
[7] Fuchida T,Aung K T,Sakuragi A.A study of Q-learning considering negative rewards[J].Artificial Life and Robotics,2010,15:351-354.
[8] 王义萍,陈庆伟,胡维礼.机器人行为选择综述[J].机器人,2009,31(5):472-480.
[9] 王琦.情感虚拟人研究[D].上海:上海师范大学,2008.
[10] 张云,刘建平.Q 学习的改进研究及其仿真实验[J].计算机仿真,2007,24(10):111-114.
