复杂网络上的演化博弈研究
2012-03-22杨涵新汪秉宏
杨涵新, 汪秉宏
(1.福州大学物理系,福州 350002;2.中国科学技术大学近代物理系,合肥 230026;3.上海理工大学复杂系统科学研究中心,上海 200093)
博弈论,又称对策论,主要研究具有形式激励结构的个体之间的相互作用.博弈论作为应用数学的一个分支,目前广泛应用于生物学、经济学、计算机科学、政治学、军事战略等诸多学科[1-2].1944年,匈牙利数学家Neumann和经济学家Morgenstern合作出版了划时代巨著《博弈论与经济行为》[3],奠定了博弈论的基础和理论体系.20世纪50年代,美国数学家Nash提出了著名的纳什均衡[4],它是指自私个体在相互作用过程中达到的一种均衡状态,这种状态下没有个体可以通过单方面改变自己的策略而增加收益.纳什均衡的提出极大地推动了博弈论的研究和发展.
通常博弈由4部分组成:至少有两位博弈个体;每个博弈个体都有自己的博弈策略;当博弈个体选择好策略后,按照一定的博弈规则进行博弈并据相应的收益函数获得收益;在博弈过程中,博弈个体遵循自身收益最大化的最终目标,进行策略上的调整.
经典博弈理论认为个体具有完全的理性,它们根据对收益函数的分析,一步到位地选择符合纳什均衡的最佳策略.但是在现实复杂环境中,人的理性是有局限的,即使再聪明的人也会犯错误.同时,在生物的成长与漫长的进化过程中,个体通常无法清晰了解环境,它们只有通过不断地试错来适应环境,也就是说,均衡状态不是一蹴而就达到的.因此,生物学家将生物进化论中的自然选择和遗传变异机制引入博弈论中,提出了演化博弈理论[5],力图解释上述经典博弈论无法解答的问题.演化博弈理论着重研究有限理性的个体如何随着时间的推移在不断地重复博弈过程中去实现收益最大化.
在自然界和人类社会中,合作行为普遍存在,如狮群协作捕猎、人类社会大规模地生产活动等等.从大的方面来看,世界的和平与发展、地球的环境保护都离不开各国之间的相互协作.但是在一个群体中,并不是所有的个体都会采取合作的行为.由于个体存在一定的自私心理,有些人会采取不合作(背叛)的行为.如何理解自私个体之间合作行为的产生和维持受到了各领域科学家的广泛关注[6-8].目前,演化博弈理论被认为是研究合作行为的一个最有力的手段[9].常见的研究合作行为的演化博弈模型有囚徒困境博弈[10]、铲雪博弈[11]和公共品博弈[12]等.
长期以来,在演化博弈理论中通常假设个体以均匀混合的方式进行联系,即所有个体全部相互接触或者个体随机接触.然而,现实生活中个体之间的联系并非是全耦合或者完全随机的,而是具有特定的联系方式.1992年,Nowak和May研究了二维方格上的囚徒困境博弈[13],开创了网络演化博弈研究的先河.最近十年来,随着复杂网络的兴起[14-15],复杂网络上的演化博弈研究受到了广泛的关注,取得了许多重要的进展[16-17].本文将对前人这方面的工作做一综述,以期对未来的研究有所启迪.
1 复杂网络上的演化博弈模型简介
在复杂网络上的囚徒困境博弈和铲雪博弈中,初始时候每个个体(节点)以相同的概率1/2选择合作或者背叛策略.每轮博弈中,每个个体同时和周围的直接邻居进行博弈获取收益.如果两个人都采取合作策略,则两个人都得到R的收益.如果两个人都采取背叛策略,则两个人分别得到P的收益.如果一个合作一个背叛,那么合作者将得到收益S,背叛者得到收益T.在囚徒困境博弈中,这4个收益参数的排序为T>R>P>S.但是在铲雪博弈中,收益参数的排序变为T>R>S>P.为了研究上的方便,囚徒博弈收益参数通常设定为[13]R=1,P=S=0,T=b>1,铲雪博弈收益参数通常设定为[18]R=1,S=1-r,T=1+r,P=0 (0<r<1).人们通常把b和r称为“背叛诱惑”(temptation to defect)参数.
每轮博弈结束后,每个个体根据某种更新规则进行策略更新,并把更新后的策略作为自己下一轮博弈中采取的策略.在通常情况下,经过足够长的时间演化后,系统会达到一个相对稳定状态,即网络中合作者的比例趋于稳定.稳定状态网络中合作者的比例通常被称为合作频率,是衡量系统合作水平的重要指标.
在复杂网络的公共品博弈中,初始时候,网络中给每个节点以相同的概率1/2随机地赋予合作或者背叛策略.每个时间步,网络上的每一个点i参与以它自己为中心及以它的邻居为中心的ki+1个群体的博弈.这里所说的一个群体是由一个中心节点及其周围的邻居构成.每个合作者i给每个群体分别投入1/(ki+1)的资本(也就是说,合作者i投入的总资本为1),背叛者不投入任何成本.在每一个群体中,获得的总资本为该群体中所有合作者投入资本的总和,群体的总资本会增值(增值系数设为r),升值后的收益平均分配给该群体中的每个点.根据这样的收益分配规则,节点x参与以节点y为中心的群体时,从这个群体获得的收益为
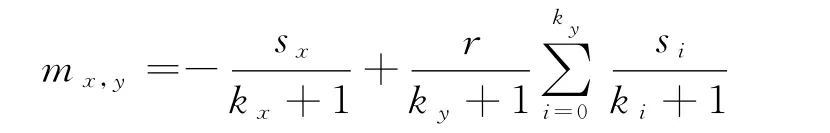
这里的i=0代表节点y,si是与y相连的节点i的策略(si=1表示节点i是合作者,si=0表示节点i是背叛者),ki是节点i的度.节点x的总收益Mx为它从所参加的各个群体获得的收益之和
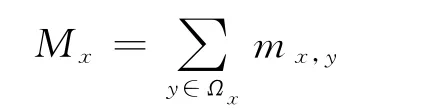
这里的Ωx包括节点x及其周围的邻居.
与囚徒困境博弈和铲雪博弈类似,在公共物品博弈中,个体也是根据某种更新规则不断调整自己的策略.
网络演化博弈中通常采用的策略更新规则有:
a.最优者替代[13]某个个体模仿周围邻居(包括他本人)在此轮博弈中获得最高平均收益的个体,以其策略作为自己在下轮博弈的策略.
b.较好者拥有替代机会[18-19]每个个体随机地选择周围一个邻居进行收益比较.如果他的收益比被选择的邻居高,那么他保持自己策略不变.如果他的收益比被选择的邻居低,则他会以一定的概率选择该邻居的策略作为下一轮博弈的策略.
c.依赖收益差别的策略学习[20]每个个体随机地选择周围一个邻居进行收益比较.他的收益比被选择邻居的收益越高(越低),则他选择该邻居的策略作为下一轮博弈策略的概率就越低(越高).
2 网络结构的影响
在相同的策略更新规则下,不同的网络结构会影响系统的合作水平.
在全连接网络的囚徒困境博弈中,合作者的收益始终比背叛者低,因此群体的所有个体最终都会成为背叛者.Nowak和May发现,在二维格子的囚徒困境博弈中,合作者通过形成团簇结构可以有效地抵御背叛者的入侵[13].在合作簇内部,合作者通过相互协作获得很高的收益,从而保护合作簇内部的合作者不被外面的背叛者所取代.
Santos等发现,相比于规则网络上比较低的合作频率,无标度网络上的囚徒困境、铲雪和公共物品博弈都能出现非常高的合作水平[19-21].他们的研究表明,无标度网络上几乎所有的大度节点在演化博弈过程中逐渐会被合作者所占据.由于大度节点通常拥有比小度节点更多的收益,无标度网络中的许多小度节点将模仿大度节点的合作策略,从而导致很高的合作频率.
Tang等研究了网络平均度对于囚徒困境博弈中合作行为的影响[22],发现适中的网络平均度能最好地促进合作.当网络平均度很大时候,系统近似于全连接的情况,这个时候合作者的收益始终比背叛者低,合作行为无法存在.当网络平均度很小的时候,合作者周围邻居过少,导致合作簇内部合作者的收益不高,也抑制了合作.当网络平均度适中的时候,合作簇内部合作者的收益比较高,能有效地抵御外部背叛者的入侵.
Rong等研究了度度相关性对于囚徒困境博弈中合作行为的影响[23].发现相比于随机相配网络,在背叛诱惑参数值低的时候正配合网络抑制合作,而在背叛诱惑参数值高的时候负配合网络能够促进合作.在正配合网络中,大度节点之间的连接很多,在演化的初始阶段,由于背叛的大度节点获得比合作的大度节点更多的收益,因此合作的大度节点容易采取背叛大度节点的策略,导致网络中所有的大度节点迅速被背叛者所占据,从而降低了网络的合作水平.在负配合网络中,大度节点之间的连接很少,合作的大度节点的周围节点采取合作策略,而背叛的大度节点的周围节点采取背叛策略,这样一来,当背叛诱惑参数值高的时候,网络中的合作者依然会在合作的大度节点周围存活下来.
Rong等还研究了聚类系数可调的无标度网络上的公共品博弈[24].他们的研究发现,随着聚类系数的增大,网络的合作频率提高.公共品博弈是一种群体性博弈,个体不仅参与以自己为中心的群体博弈,还参加以其邻居为中心的群体博弈.因此在公共品博弈中,个体的收益不仅和邻居的策略有关,而且和邻居的邻居策略有关.高聚类的网络中会有大量的三角构造(一个节点及其周围的两个相互连接的邻居),使得公共品博弈中的合作簇(相互连接的合作者组成的集团)获得更高的收益,从而有效地促进合作行为在整个网络中的扩散.
Ren等研究了均质小世界网络上的囚徒困境博弈[25].他们发现,当网络的交叉换边比例适中的时候(此时网络中即有短程连边也有远程连边),网络的合作水平达到最高.网络中短程连边的存在,使相临近的合作者能形成稳定的合作簇,同时,适当比例的长程边,有利于合作者在网络中进行大范围扩散.
3 策略更新规则的影响
在相同的网络结构上,设计不同的博弈策略演化规则会很大程度地影响系统合作行为的表现.
Wang等提出了基于记忆的铲雪博弈[26].每轮博弈结束后,每个个体会根据邻居上一时刻的策略进行反思,即采取自己的反策略做一次虚拟博弈,从而得到虚拟收益,然后将真实收益与虚拟收益进行比较,得到所对应的最佳策略,并将其记录到该个体的记忆中.在之后的博弈中,个体会根据前几轮所存储的记忆,决定采取何种策略.研究发现,二维网络上合作频率和收益参数r之间具有分段式的台阶关系,在某些r值附近,合作频率会从一个值突变到另外一个值.
Szolnoki等[27]和Guan等[28]研究被模仿能力对复杂网络演化博弈的影响.他们把个体分为A、B两类.A类个体的被模仿能力比B类个体高,表示A类个体的策略比B类个体更容易被别人所模仿.在策略演化时,个体i采取邻居j的概率,不但与两者的收益差有关,而且正比于邻居的被模仿能力.设网络中A类个体的比例为v,他们发现存在适中比例的v,使得网络的合作频率达到最高.
Wang等提出了一种最差者改变策略的演化规则[29].每轮铲雪博弈结束后,网络中收益最低的个体将会改变自己的策略,而网络的其他个体保持策略不变.通过先逐渐增大后逐渐减小收益参数r,他们发现网络的合作频率与收益参数r之间的关系曲线呈现迟滞回线的形状.
在通常的网络演化博弈研究中,网络中的节点随机地选择其中一个邻居进行策略学习.也就是说,节点选择哪个邻居进行策略模仿是没有任何偏好的.Yang等考虑社会差异性对于选择邻居的影响[30].由于社会差异性的存在,每个节点的影响力是不同的.设定每个节点i的影响力为kαi,其中α是一个可调参数.当α=0时候,网络中每个节点的影响力都是相同的,当α>0(或者α<0)时候,度大(或者度小)的节点的影响力比较大.节点x选择一个邻居y进行策略更新的概率正比于节点y的影响力,即
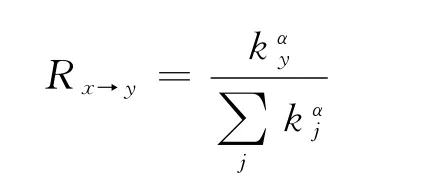
节点x采取节点y的策略作为自己下一时间步策略的概率为
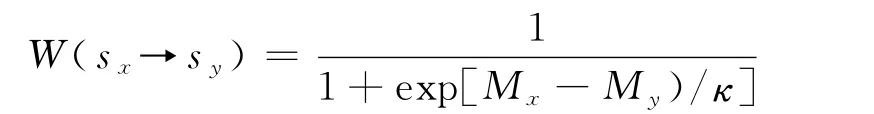
式中,κ为噪音参数(设定κ=0.1).节点x保持自己策略不变的概率为1-W(sx→sy).研究发现,当α是一个适中的正值的时候,网络的合作频率最高.这个结果表明,当大度节点的影响力适当大的时候,能够促进系统的合作.
此外,Szabó等研究策略更新规则中噪音κ的作用[31],发现适中的噪音强度能使网络的合作频率达到最高.Wu等将博弈关系对象和策略学习对象分离开[32],发现当博弈关系对象和学习对象之间存在一定的差异性的时候,可以最好地促进合作.
4 演化博弈动力学与网络结构的共同演化
在通常的网络博弈研究中,网络结构是静态不变的.近年来,人们开始关注在演化动力学的影响下,网络的结构是如何变化的.
Zimmermann等提出了一个动态网络囚徒困境博弈模型[33-34]:从一个ER随机网络开始,每轮博弈中个体与直接相连的邻居进行囚徒困境博弈,它们会采纳周围邻居(包含自己)中收益最高者的策略作为下一轮博弈.如果一个背叛者发现它模仿的邻居是背叛者,并且收益比自己高,则这个不满意的个体会以概率p断开与被模仿的背叛者之间的边,重新在网络中随机选择一个节点连接.他们的研究结果显示,只需要一个很小的概率p就可以使动态网络的合作频率达到一个很高的值.这是因为网络中的节点会不断抛弃那些背叛节点,而和合作节点建立联系,从而使合作节点的度增大,成为网络的中心节点,进而促进整个网络合作水平的提高.
Li等提出了一种由演化博弈驱动生成的无标度网络型[35].初始时候,在一个方格网络上,每个节点拥有一个活动的长程边,每个节点可以控长程边的另一端指向期望的节点.节点进行按照囚徒困境博弈,策略更新时个体x将它的收益与邻居中收益最高者y进行比较,如果y邻居收益高则采纳其策略.同时,x把它拥有的长程边连向y拥有的长程边所指向的节点.随着时间演化,网络的度分布呈现无标度特性.
Helbing等提出的成功驱动的博弈模型[36].在其模型中,博弈个体分布在一个二维方格上,个体会迁移到周围中能使其收益最高的格点上.他们发现,即使初始所有人都是背叛者,在一定的噪音情况下(个体的策略会以一定概率重置),随着时间演化,合作行为会出现突然爆发的现象,即在很短的一段时间内,合作者比例迅速增加.
Meloni等[37]在一个二维的连续空间上,考虑博弈个体随机移动的情况.在他们研究的模型中,每个时间步,每个个体与其周围一定距离内的其他个体进行囚徒困境博弈,随后以速度v随机地移动到另外一个地方.他们研究发现,随着个体移动速度v的增大,合作频率降低.
Yang等研究了预期导致的移动在演化博弈中的作用[38].个体与周围邻居进行囚徒困境博弈获得收益,当个体获得的收益低于它的预期的时候,它将随机地迁移到另外一个地方.研究发现,当预期适中的时候,背叛簇内部的背叛者由于收益低于预期产生移动,而合作簇内部的合作者由于收益高于预期保持不动,导致背叛簇的瓦解和合作簇的扩张,使合作行为在整个群体中得以蔓延.预期过低和过高的时候,都不利于合作行为的扩散.预期过低,个体很少进行移动,使得合作簇和背叛簇能同时稳定存在.预期过高,由于个体的频繁移动,无法形成稳定的合作簇,导致合作者的灭亡.
5 展 望
复杂网络上的演化博弈研究是近年来随着复杂网络研究兴起而逐渐引起关注的一个重要研究课题.基于前人研究工作的基础,作者对未来复杂网络上的演化博弈研究方向做一个展望.
a.前人主要利用数值仿真手段对复杂网络上的演化博弈进行研究,缺乏严格的解析分析.目前的一些近似方法,如平均场方法、对估计方法无法解决异质网络上的演化博弈问题.因此寻求有效的数学和统计物理方法,对数值模拟结果进行理论分析,是非常有意义的.
b.之前复杂网络上的演化博弈研究中,个体通常单纯地使用合作或者背叛策略.然而,演化博弈的研究,尤其是实验研究表明,真实世界中的个体会采用更丰富的策略(如中立策略等),而不仅仅只限于纯合作和纯背叛两种.多策略的演化博弈是未来研究的焦点.
c.目前,复杂网络上的演化博弈研究绝大部分都是在单个网络上进行的.实际上复杂系统是由许多具有不同结构与功能的网络耦合而成的[39].例如,在线社交网络中的个体是通过互联网进行联系的,而互联网又需要电力网提供的电力支持.多层耦合网络上的演化博弈是一个创新型的研究课题,具有广阔的发展空间.
d.大多数的复杂网络演化博弈研究中,个体的策略演化不受外界人为的控制.如何通过调控复杂网络中少数节点或者边上的个体行为,从而使整个系统的合作水平得到提高,是一个具有实践意义的研究课题.
e.演化博弈与其它动力学的结合是未来研究的焦点.例如,个体接种疫苗可以预防疾病的感染,但是接种疫苗也会带来一定的经济成本.可将是否选择接种疫苗看作是两种不同的策略,根据博弈理论的一些研究方法,对个体是否选择疫苗进行分析[40].再比如,利用演化博弈理论研究车辆是否抢道对交通的影响.
[1] Smith J M.Evolution and the theory of games[M].Cambridge:Cambridge University Press,1982.
[2] Colman A M.Game theory and its applications in the social and biological sciences[M].Oxford:Butterworth-Heinemann,1995.
[3] Neumann J V,Morgenstern O.Theory of games and economic behavior[M].Princeton:Princeton University Press,1944.
[4] Nash J F.Equilibrium points in n-person games[J].Proceedings of the National Academy of Sciences,1950,36:48-49.
[5] Smith J M,Price G R.The logic of animal conflict[J].Nature,1973,246(5427):15-18.
[6] Hofbauer J,Sigmund K.Evolutionary games and population dynamics[M].Cambridge:Cambridge University Press,1998.
[7] Hammerstein P.Genetic and cultural evolution of cooperation[M].Cambridge:MIT Press,2003.
[8] Axelrod R.The evolution of cooperation[M].New York:Basic books,1984.
[9] Gintis H.Game theory evolving[M].Princeton:Princeton University,2000.
[10] Axelrod R,Hamilton W D.The evolution of cooperation[J].Science,1981,211(4489):1390-1396.
[11] Sugden R.The economics of rights,cooperation and welfare[M].Oxford:Blackwell,1986.
[12] Hardin G.The tragedy of the commons[J].Science,1968,162:1243-1248.
[13] Nowak M A,May R M.Evolutionary games and spatial chaos[J].Nature,1992,359(6398):826-829.
[14] Albert R,Barabási A L.Statistical mechanics of complex networks[J].Reviews of Modern Physics,2002,74(1):47-97.
[15] Newman M E J.The structure and function of complex networks[J].SIAM Review,2003,45(2):167-256.
[16] SzabóG,Fath G.Evolutionary games on graphs[J].Physics Reports,2007,446(4-6):97-216.
[17] Perc M,Szolnoki A.Coevolutionary games—a mini review[J].Biosystems,2010,99(2):109-125.
[18] Hauert C,Doebeli M.Spatial structure often inhibits the evolution of cooperation in the snowdrift game[J].Nature,2004,428(6983):643-646.
[19] Santos F C,Santos M D,Pacheco J M.Social diversity promotes the emergence of cooperation in public goods games[J].Nature,2008,454(7201):213-216.
[20] SzabóG,To′′ke C.Evolutionary prisoner’s dilemma game on a square lattice[J].Physical Review E,1998,58(1):69.
[21] Santos F C,Pacheco J M.Scale-free networks provide a unifying framework for the emergence of cooperation[J].Physical Review Letters,2005,95(9):098104.
[22] Tang C L,Wang W X,Wu X,et al.Effects of average degree on cooperation in networked evolutionary game[J].European Physical Journal B,2006,53(3):411-415.
[23] Rong Z,Li X,Wang X F.Roles of mixing patterns in cooperation on a scale-free networked game[J].Physical Review E,2007,76(2):027101.
[24] Rong Z,Yang H X,Wang W X.Feedback reciprocity mechanism promotes the cooperation of highly clustered scale-free networks[J].Physical Review E,2010,82(4):047101.
[25] Ren J,Wang W X,Qi F.Randomness enhances cooperation:a resonance-type phenomenon in evolutionary games[J].Physical Review E,2007,75(4):045101.
[26] Wang W X,Ren J,Chen G,et al.Memory-based snowdrift game on networks[J].Physical Review E,2006,74(5):056113.
[27] Szolnoki A,SzabóG.Cooperation enhanced by inhomogeneous activity of teaching for evolutionary prisoner’s dilemma games[J].Europhysics Letters,2007,77(3):30004.
[28] Guan J Y,Wu Z X,Wang Y H.Effects of inhomogeneous activity of players and noise on cooperation in spatial public goods games[J].Physical Review E,2007,76(5):056101.
[29] Wang W X,LüJ,Chen G,et al.Phase transition and hysteresis loop in structured games with global updating[J].Physical Review E,2008,77(4):046109.
[30] Yang H X,Wang W X,Wu Z X,et al.Diversityoptimized cooperation on complex networks[J].Physical Review E,2009,79(5):056107.
[31] SzabóG,Vukov J,Szolnoki A.Phase diagrams for an evolutionary prisoner’s dilemma game on twodimensional lattices[J].Physical Review E,2005,72(4):047107.
[32] Wu Z X,Wang Y H.Cooperation enhanced by the difference between interaction and learning neighborhoods for evolutionary spatial prisoner’s dilemma games[J].Physical Review E,2007,75(4):041114.
[33] Zimmermann M G,Eguíluz V M,Miguel M S.Coevolution of dynamical states and interactions in dynamic networks[J].Physical Review E,2004,69(6):065102.
[34] Zimmermann M G,Eguíluz V M.Cooperation,social networks,and the emergence of leadership in a prisoner’s dilemma with adaptive local interactions[J].Physical Review E,2005,72(5):056118.
[35] Li W,Zhang X,Hu G.How scale-free networks and large-scale collective cooperation emerge in complex homogeneous social systems[J].Physical Review E,2007,76(4):045102.
[36] Helbing D,Yu W.The outbreak of cooperation among success-driven individuals under noisy conditions[J].Proceedings of the National Academy of Sciences,2009,106(10):3680-3685.
[37] Meloni S,Buscarino A,Fortuna L,et al.Effects of mobility in a population of prisoner’s dilemma players[J].Physical Review E,2009,79(6):067101.
[38] Yang H X,Wu Z X,Wang B H.Role of aspirationinduced migration in cooperation[J].Physical Review E,2010,81(6):065101.
[39] Kurant M,Thiran P.Layered complex networks[J].Physical Review Letters,2006,96(13):138701.
[40] Fu F,Rosenbloom D I,Wang L,et al.Imitation dynamics of vaccination behaviour on social networks[J].Proceedings of the Royal Society B,2011,278(1072):42-49.
