基于GPU的高阶辛FDTD算法的并行仿真研究
2012-03-15马巍巍吴先良孙兵兵
马巍巍, 孙 冬, 吴先良, 孙兵兵
(1.安徽大学计算智能与信号处理教育部重点实验室,安徽合肥 230039;2.安徽大学电气工程与自动化学院,安徽合肥 230039)
0 引 言
时域有限差分算法(Finite-difference timedomain method,简称FDTD)是计算电磁学的一种常用方法。但在电大尺寸或长时间仿真中,由于数值色散性和稳定性等的影响,数值误差会随时间累计,造成计算结果失真。高阶辛时域有限差分算法(the high-order symplectic finite-difference time-domain method,简称SFDTD)可以解决这一问题,其优越性也已被证实[1-3]。
但SFDTD进行电磁仿真相当耗时,且占有更大的计算存储空间[3]。本文提出采用SFDTD与并行算法相结合的方法来进行电磁仿真,以缩短计算时间,取得了较好的结果。本文在时间方向上采用高阶辛差分,在长期仿真中保持麦克斯韦方程的辛结构;空间方向上采用4阶交错差分以减小数值色散。
并行化是数值计算的必然趋势[4]。图形处理器(graphics processing unit,简称GPU)并行技术所需硬件成本较低,且具有较高的计算能力,在计算统一设备架构(compute unified device architecture,简称CUDA)出现后,解决了GPU计算模型中的很多限制,已成为并行计算领域里的热点研究方向,在FDTD算法上的应用也已有了很多的发展[5-6]。但到目前为止,对高阶辛算法进行并行的研究还比较少。
本文在分析SFDTD算法和CUDA架构的基础上,研究了基于GPU加速的二维电磁波的SFDTD并行算法。在最新的Fermi架构下,实现了该算法,与单CPU相比,计算速度可提升数十倍,验证了所提算法的有效性。
1 SFDTD的基本理论
1.1 麦克斯韦方程的哈密顿表述
已知在无源、均匀、无耗媒质中的麦克斯韦旋度方程为:
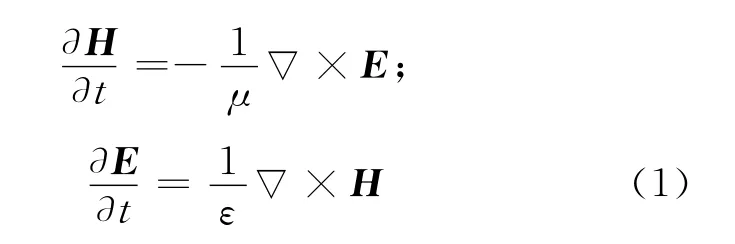
根据哈密顿系统理论[7],其对应的哈密顿函数的微分形式为:
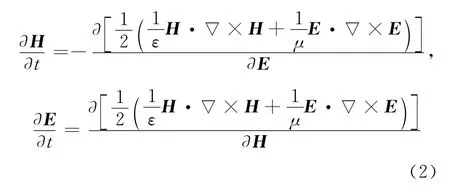
通过变分法,可写成:
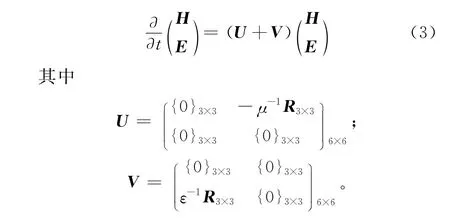
ε和μ分别为媒质的介电常数和磁导率。
1.1.1 时间方向上的离散
由(3)式从t=0到Δt的精确解为:
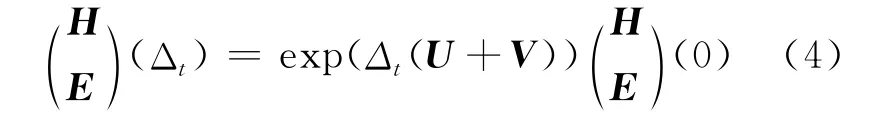
为了近似时间演化矩阵exp(Δt(U+V)),采用m级p阶辛积分方法,即
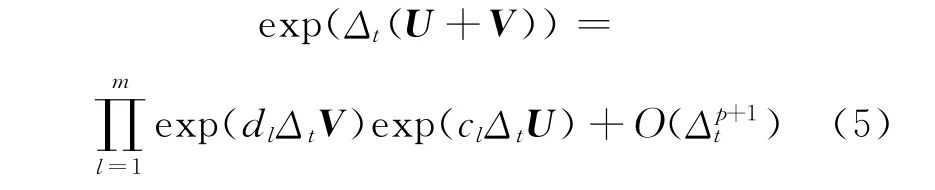
其中,cl和dl为辛算子,具体系数见文献[2]。
当取m=5且p=4时,可得5级4阶辛积分方法。
1.1.2 空间方向上的离散
在YEE网格下建立矩阵差分网格,任一场量函数F(x,y,z,t)在第n个时间步第l级步进的离散表达式为:
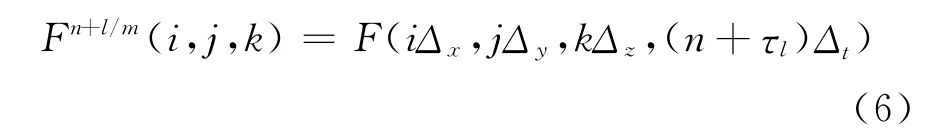
网格节点与相应的整数标号对应,即
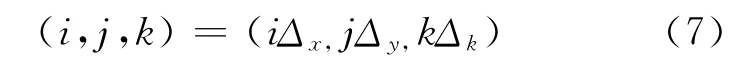
对于普通的FDTD方法,每个时间步只需要1级时间步进。本文用4阶中心(交错)差分离散空间,1阶导数为:
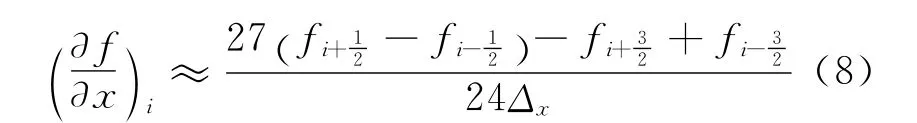
经空间上的4阶中心差分、时间上的4阶离散后,建立了麦克斯韦方程的离散辛框架,即SFDTD(4,4)算法。
1.2 二维SFDTD算法
本文以二维TM波为例,采用5级辛积分方法和4阶中心差分。辛算子及参数的具体取值见文献[2]。为能使电场和磁场具有相同数量级,将方程式进行归一化处理,因此在无源的自由空间中归一化TM波方程为:
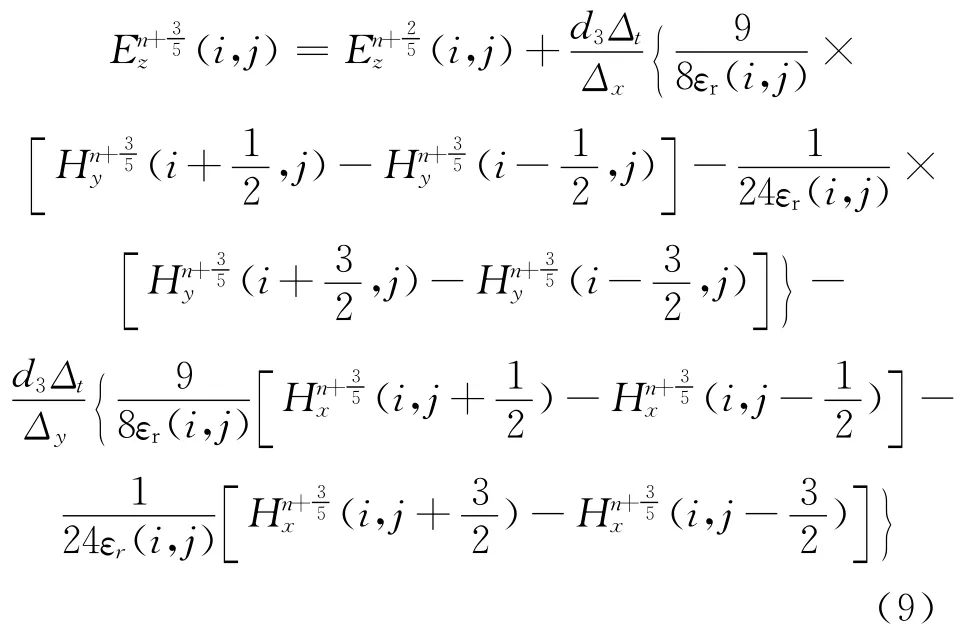
由(9)式可以看出,本文所研究的SFDTD算法为4阶中心差分,具有天然的并行性。其空间电磁场排布为:每1个电场分量被8个磁场分量环绕,每1个磁场分量被8个电场分量环绕。这种空间取样方式同样采用了YEE网格,只不过采用了双环路的形式。
SFDTD电(磁)场的推进仅需要周围的磁(电)场的信息及上一步的本点场值,不需要考虑整个计算区域的场值分布,因此具有很好的空间并行优势。
2 并行化算法
2.1 CUDA模型
计算统一设备架构(CUDA)是通用GPU计算的一种技术规范,由NVIDIA公司推出。它采用了类C语言进行开发,写出在显示芯片上执行的程序。在CUDA架构下,一个程序分为在CPU上执行的Host端和在显示芯片上执行的Device端。在Device中执行的代码称为内核(Kernal)。通常Host端程序会将数据准备好后,复制到显存中,再由GPU执行Device端的程序,完成后,再由Host端程序将结果从GPU中取回,编程模型如图1所示。
CPU主要负责执行串行部分的代码,从图1可以看出,在CPU中运行的代码只有一个线程,这部分通常是一些控制类的操作。接下来是并行执行的部分,这部分都是在GPU中运行的。显示芯片执行的最小单位是thread(线程),数个线程可组成一个block(块)。数个块可组成一个grid(网格)。关于CUDA编程模型的详细介绍可参阅文献[8]。
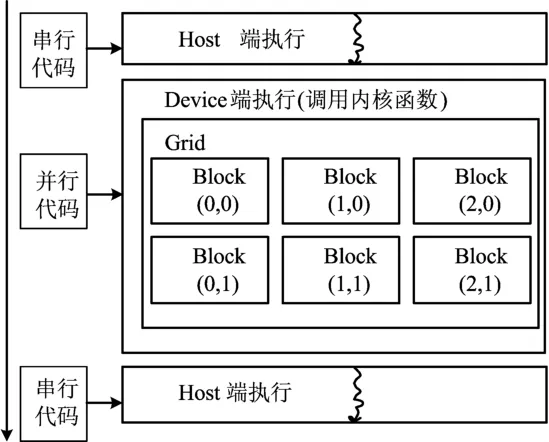
图1 CUDA程序的编程模型
根据这一架构的特点,在实现SFDTD并行算法时,由于SFDTD在空间上的并行性,计算区域被划分成为多个块,然后每个块又划分为多个线程,用每个线程来计算一个YEE元胞。具体实现的主要编程思路如图2所示。
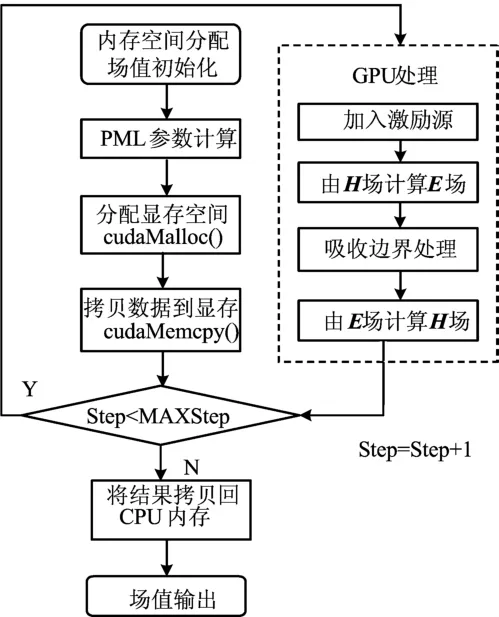
图2 程序实现流程图
2.2 支持CUDA的图形处理器及Fermi架构
2007年发布的CUDA是世界上第1个针对图形显示器(GPU)的C语言开发环境。NVIDIA公司2007年后推出的显存超过256 MB的GPU都可以运行和开发基于CUDA的并行算法。而在短短的几年间,支持CUDA的硬件有了多次重要的变化[9]。基于CUDA编写的代码具有很好的通用性,在任何一款支持CUDA的单机上都可以运行。最新的Fermi架构提升了通用计算的重要性,与之前架构相比有很多的优势。例如,在G80/GT200系列中,Fermi构架中每个线程块支持高达1 536个线程;Fermi允许多个内核同时占用一个SM的计算资源,从而有效提高了设置的利用率;在Fermi中,768 k B的二级缓存,可加速全局存储器和纹理存储器的读取。
3 二维SFDTD算法的CUDA仿真实现
3.1 二维SFDTD算法
为验证本文算法的正确性和有效性,使用SFDTD算法计算带有PML边界的TM平面波点源辐射问题,分别使用CPU和GPU对其进行仿真。本文的程序开发环境为VS 2008,软件运行环境为32位Windows 7,内存1 GB。处理器型号:GPU为NVIDIA GeForce GT 440;显存512 MB;96个流处理器。CPU英特尔Pentium(奔腾)4 3.00 GHz,内存1 G。所选择的激励源为位于区域中心的高斯脉冲源。CUDA在执行程序时,是以warp为单位。目前的CUDA装置,一个warp中有32个线程,分成2组的halfwarp,一次至少执行16个线程才能有效隐藏各种运算的延迟。因此,取Block-size=16,即每个块中有16×16个线程,再建立每个网格中的块,这样,在程序运行时每个线程块中都会有256个线程在同时执行内核。由于时间上是高阶辛积分,在具体编程时与FDTD方法不同,是双重循环,故其系数需小心处理正确放入显存后,才能得出正确的结果。
3.2 数值结果及讨论
考虑设置为计算域中心的二维真空中随时间为高斯源变化的点源辐射问题。计算结果与CPU的计算结果进行比较,如图3所示。图3中沿x,y方向的离散点格数分别为GRIDx=GRIDy=64,取CFL=0.5。边界条件为分裂场PML,时间步为100步。
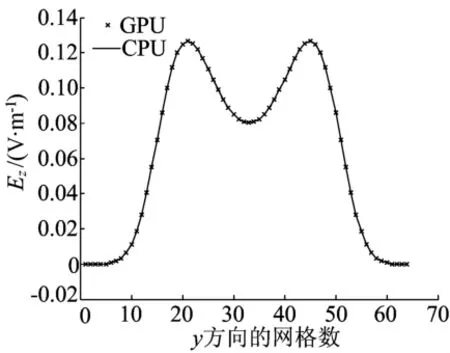
图3 x=20时场值Ez分布图
由图3可见,采用GPU和CPU的图像是一致的,这证明了GPU编码的正确性。对网格数取不同值得到的运行结果如图4所示。
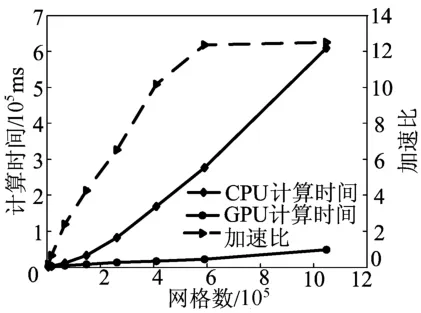
图4 CPU、GPU的计算时间、加速比与网格关系
从图4可以看出,在场点较少时,GPU的优势并不明显。这是由于此时可分配线程数太少,多流处理器并未充分利用,且较少的线程也无法隐藏数据在内存与显存之间的传递时间。但随着网格数的增加,GPU并行计算的优势就得到了明显体现。如在处理640×640个网格时,速度提升了10倍。在仿真实际的物理问题时,YEE元胞的数量通常会在数万,甚至百万以上,正适合于将这些数据分配给GPU的数百个标量处理器进行并行计算。
4 结束语
本文基于图形处理器,提出一种高阶辛时域有限差分方法的并行算法,并将其应用到二维散射场问题的分析中。结果表明,该算法与传统的CPU中实现该算法相比,在精度相当的情况下可节省大量时间,有助于电磁场问题的应用,具有极为重要的实用价值。
[1] 黄志祥,吴先良.辛算法的稳定性及数值色散性分析[J].电子学报,2006,34(3):535-538.
[2] Hirono T,Seki S,Lui W,et al.A three-dimensional fourthorder finite-difference time-domain scheme using a symplectic integrator propagator[J].IEEE Transactions on Microwave Theory and Techniques,2001,49(9):1640-1648.
[3] 吴 琼,黄志祥,吴先良.基于高阶辛算法求解Maxwell方程[J].系统工程与电子技术,2006,28(2):342-344.
[4] 吕英华.计算电磁学的数值方法[M].北京:清华大学出版社,2006:6-8.
[5] Valcarce A,De La Roche G,Jie Z.A GPU approach to FDTD for radio coverage prediction[C]//The 11th IEEE Singapore International Conference on Communication Systems,Guangzhou,2008:1585-1590.
[6] 沈 琛,王 璐,胡玉娟,等.基于CUDA平台的时域有限差分算法研究[J].合肥工业大学学报:自然科学版,2012,35(5):644-647.
[7] 沙 威.高阶辛算法的理论和应用研究[D].合肥:安徽大学,2008.
[8] NVIDIA Corporation Technical Staff.NVIDIA CUDA programming guide 2.0[EB/OL].[2011-12-05].http://www.nvidia.cn/object/cuda_home_new_cn.html.
[9] 濮元恺.改变翻天覆地史上最全Fermi架构解读[EB/OL].[2010-03-26].http://www.sina.com.cn/
