基于相似性保持和特征变换的高维数据聚类改进算法
2011-12-25王家耀谢明霞郭建忠
王家耀,谢明霞,2,郭建忠,陈 科
1.信息工程大学测绘学院,河南郑州450052;2.75719部队,湖北武汉430074
基于相似性保持和特征变换的高维数据聚类改进算法
王家耀1,谢明霞1,2,郭建忠1,陈 科1
1.信息工程大学测绘学院,河南郑州450052;2.75719部队,湖北武汉430074
提出一种基于相似性保持和特征变换的高维数据聚类改进算法。首先,通过相似性度量函数计算得到高维空间对象相似度矩阵,并利用近邻法、Floyd最短路径算法将相似度矩阵转换为最短路径距离矩阵;然后,将高维特征变换转化为遗传优化问题,利用特征变换降维后的二维数据进行k-均值聚类,并根据(高维坐标,降维后二维坐标)值进行RBF神经网络训练,当新对象输入时,利用训练好的神经网络对其进行二维映射,通过判断该对象与各聚类簇中心距离的远近获得其归属;最后,通过试验验证了改进相似性度量函数能够有效表达高维数据对象间的相似性,且基于特征变换的降维方法具有可操作性。
特征变换;高维数据聚类;相似度;降维
1 引 言
聚类分析是数据挖掘研究的一个重要方向。所有的聚类问题都是在对给定数据集进行划分的同时,根据同一簇中的对象尽可能相似、不同簇间的对象尽可能相异这一准则,设计优化函数,通过对所设计的优化问题的求解实现数据对象的聚类[1]。由于“维度困扰”的存在,目前绝大多数聚类算法在高维空间中无法得到理想的效果。为使现有聚类算法能够适用于高维空间,可以从两个方面进行改进:相似性度量和高维空间降维。
在高维数据相似性度量方面,就是否能获得高维数据聚类的成效而言,指定适当的相似性(相异性)度量比选择聚类算法更为重要。现有的高维数据相似性度量的改进方法可以概括为两种:一是基于传统距离度量的改进方法[2-4];二是相似性度量方法重构[5-7]。传统的相似性度量有距离度量和相似系数。文献[7-8]对Lk-范数和数据维数关系的研究结果说明在高维空间中用Lk-范数作距离函数时,随着维数的增加,点与点之间距离的对比性不复存在,基于传统Lk-范数的改进相似性度量方法本质上无法避免“维灾”的影响; Cosine度量和Pearson相关系数适于高维空间中数值型数据的相似性度量,而不能用于分类型数据相似度的计算;Jaccard系数可以较好地反映高维数据在属性上的相似程度,但不能反映其在高维空间距离上的相似程度。文献[7-8]重新设计高维空间中的相似性度量,文献[5]对其设计的相似性度量方法进行改进,提出度量函数 Hsim,该函数避免原低维空间中定义的距离函数在高维空间中的不适用问题,但不能用于对分类属性数据的相似性度量。文献[6]对函数 Hsim进行扩展使其能够对分类型数据进行度量,但该方法仍存在一些不足,文章将在下一节对其进行具体的分析和说明。如何设计适于高维数据对象间的相似性度量方法是提高高维数据聚类算法有效性的关键问题。
在高维空间降维方面,降维的方式有两种:特征(或属性)选择和特征(或属性)变换。特征(或属性)选择在降维中存在的最大弊端在于计算的复杂度,当数据维数比较高时,子空间数目将会急剧增长,导致对子空间中各簇的搜索过程漫长而又复杂,从而使算法失效;特征(或属性)变换方法包括PCA、LDA、KPCA、ISOMAP、LL E及其相应的改进方法等,如文献[9-11]。现有特征变换方法的主要缺陷在于其只能获得已知数据集的潜在低维结构,并不能给出高维空间中数据点到低维空间的确定性映射关系。
针对以上问题,主要对高维数据相似性度量的重构和基于特征变换的降维进行研究,将适于高维空间的相似性度量与降维过程中的距离保持方法相结合,使得在降维后的低维空间中,原数据集中各数据点之间在高维空间中的相似性得到有效保持。为确定原高维数据和降维后低维数据的映射关系,利用神经网络获取降维转换器,当新的高维数据点输入时,能够快速有效地获取其相应的低维坐标。
2 关键技术
2.1 相似性测度计算
高维数据对象间的相似性主要体现在属性相似性和几何相似性两个方面。
定义1:属性映射值
对于区间标度型、序数和比例标度型对象,属性映射值表示各维信息是否存在,即是否有取值,若存在,则对应维的属性映射值为1,反之为0;对于分类型对象,属性映射值表示各维的取值,若各维取值是概念性的,如{好,中,差},将其进行数值化映射,即{好,中,差}→{1,0,-1}。
定义2:几何相似度
几何相似度S(X,Y)表示对象X和Y空间距离的远近程度,S(X,Y)越大,表明 X和Y越相似,在空间上越接近;反之亦然。其表达式为
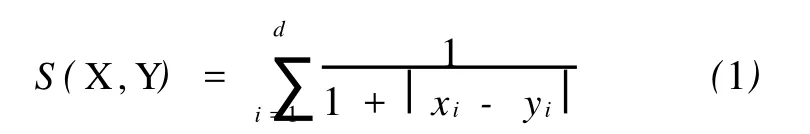
式中,xi、yi表示对象 X和 Y在第 i维上的属性值。
定义3:属性相似概率
属性相似概率 P(txi,tyi)表示属性 i上的几何相似度在d维对象X和Y的总体相似度中所占的比例,即

式中,txi、tyi为对象X和Y在第i维上的属性映射值;φ(txi,tyi)表示对象 X和Y在第i维上的属性映射值是否相同,若 txi≠tyi,则φ(txi,tyi)=0,若txi=tyi,则φ(txi,tyi)=1。
文献[5]所设计的高维数据相似性度量函数Hsim解决原有低维空间中定义的距离函数不适用于高维空间的问题,Hsim在高维空间中的有效性在文献中已进行论证,其具体设计如下

式中,d为两个对象X和Y中不全为空的维数,函数值范围为[0,1]。该函数在设计过程中未考虑属性之间的相似性,故不能用于分类型数据的相似性度量。为使其能够处理分类型数据,文献[6]对其进行扩展,具体扩展函数为

式中,若 xi=yi,则δ(xi,yi)=0;若 xi≠yi,则δ(xi,yi)=1。本文利用表1所列分类型数据来说明式(4)的不足。

表1 分类型数据Tab 1.Categorical data
根据公式(4)计算点 X和Y之间的相似性,其结果为 Hsimc(X,Y)=1/2,显然 Hsimc所反映出的相似性与实际情况是不相符的。本文融合高维数据的属性相似性和几何相似性,并将不同类型数据的相似性度量函数整合到统一的 HDsim函数中,具体定义如下
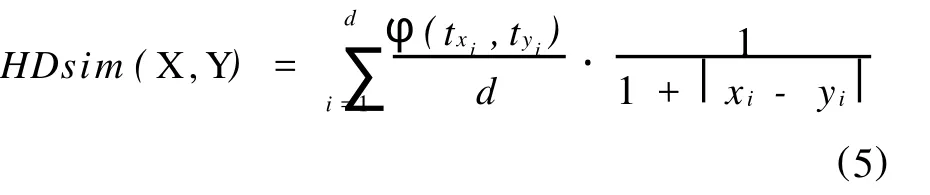
针对数值型数据,本文提出的相似性度量方法首先对数据集进行标准化处理,避免维间数值大小相差较大给相似性度量带来的不合理影响,并使其具有不依赖于幅值的特性;然后获取数据集相应的二元特征集,即对无取值的属性设置为0,对有取值的属性设置为1;最后根据式(5)计算对象间的相似度。在计算过程中,化简后的HDsim与原 Hsim相同。因此,本文设计的相似性度量函数 HDsim在处理数值型数据时能够充分利用Hsim函数的优越性;针对二元数据,函数Hsim与 HDsim计算得到的相似度量与Jaccard系数一致;针对分类型数据(分类型数据是二元数据的推广,它可以取多个状态值,即多元数据),函数 HDsim计算得到的相似度量与常用的分类型数据相似性度量方法(匹配率)一致,而 Hsim已无法求得对象间的相似性。
2.2 基于相似性保持的高维空间结构流形正确展开的降维方法
为了提高高维数据聚类的效率,本文采用特征变换的方式对原高维空间进行降维,并在降维后的低维空间中保持数据对象在高维空间的近邻关系。
根据公式

将相似度矩阵转化为距离矩阵 HD。聚类过程中数据对象间的相似关系需要满足两个一致性假设:局部一致性——邻近的数据点具有较高的相似度;全局一致性——同一流形上的数据点具有较高的相似度[12]。对于图l所示的情况,按照HDsim进行相似度度量时,数据点1和3的相似程度明显高于数据点1和2之间的相似度,因此不能反映图1所示数据的全局一致性。

图1 HDsim相似性度量的全局不一致Fig.1 Global inconsistency of similarity measureHDsim
为了解决上述问题,利用对象间的最短路径代替不能表达流形结构的欧氏距离,通过给定邻域大小,用近邻法创建与距离矩阵 HD相应的邻域图[13-15],并判断图的连通性,对连通图采用最短路径算法,得到 HDsim相似性度量基础上的最短路径距离矩阵D。对每一高维数据对象随机地赋一初始二维坐标值,通过使二维数据对象间欧氏距离趋近于高维空间对象间的最短路径距离,对二维坐标值进行迭代优化。该过程可以近似转化为使二维空间中各对象欧氏距离与对应原高维空间对象间最短路径距离测度之间的误差总和达到最小,使以下误差函数达到最小值

式中,d′ij表示降维后二维对象间的欧氏距离。利用遗传算法对此优化问题进行求解,误差函数值越小,则遗传过程中个体的适应度值越高[16]。定义个体的适应度函数为

2.3 降维转换器的生成及聚类簇更新
常用的基于特征变换的降维方法对原始数据进行降维后,当有新对象输入时,不仅要对新数据对象进行处理,而且需要对整个数据集进行重新降维,其结果是严重影响降维聚类算法的时效性。针对该问题,利用遗传降维所获得的数据值对二维映射后数据对象,进行RBF(径向基)神经网络训练,保存训练好的神经网络,从而获得对象高维坐标到低维坐标的转换器。当一新数据对象 pnew输入时,利用训练好的神经网络对其进行低维转换,获得相应的低维坐标值 p降维,并根据 p降维与原聚类簇中心的距离判断新数据对象的归属,即判断完新对象的归属后,重新计算各聚类均值,更新各聚类簇中心。由于新对象的低维坐标是通过原降维转换器获取,其精度无法判断,且降维转换器需要通过对外来数据值对(本身并不通过该降维转换器求取的数据值对)的学习进行更新,因此,本文在获取新对象的低维坐标后,不利用此数据值对更新降维转换器。
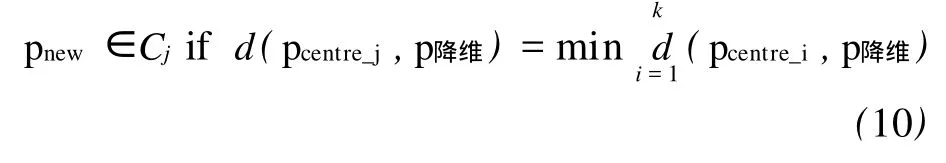
2.4 基于相似性保持和特征变换的高维数据聚类改进算法
本文提出的高维数据聚类改进算法,在降维过程中保持相似性度量在高维空间中的有效性,使数据对象在降维后的低维空间中能够正确展开高维数据对象间的相似性结构流形。算法的流程图如图2所示。

图2 基于相似性保持和特征变换的高维数据聚类改进算法流程图Fig.2 The flow of improved high dimensional data clustering algorithm based on similarity preserving and feature transformation
3 试验及有效性分析
3.1 仿真数据试验
利用MA TLAB分别随机生成7个包含50条10维、20维、50维、100维、200维、300维以及400维记录的数据集和5个包含10条、20条、30条、50条和100条50维记录的数据集。对仿真数据集进行遗传降维,图3和图4分别为遗传降维所用时间随数据维数和数据量变化的对比图。从图中可以看出,本文提出的遗传降维方法所用的时间与数据集的维数无关,而与数据集的数据量相关,当数据量增加时,降维所用的时间显著增加。因此,在实际降维过程中,当数据集的数据量非常大时,为提高遗传算法降维的效率,考虑在原始高维空间中随机抽取若干高维数据对象进行交叉变异,获得其相应的降维后坐标,根据所抽取对象的值对(原高维空间坐标值,降维后二维空间坐标值)进行神经网络映射,获得降维转换器,并利用转换器计算原始高维空间中未被抽取的数据对象的低维映射坐标值。
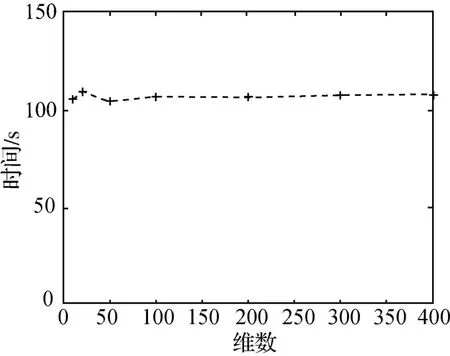
图3 遗传降维所用时间随维数变化曲线Fig.3 Change curve of consuming time with dimension

图4 遗传降维所用时间随数据量变化曲线Fig.4 Change curve of consuming time with data quantity
3.2 机器学习数据试验
为验证改进相似性保持和特征变换的高维数据聚类改进算法针对真实数据的有效性,以UCI提供的机器学习数据库中iris(数值型)和zoo(分类型)数据集为例,分别利用k-均值、基于 PCA降维的k-均值(PCA k-means)、基于欧氏距离保持的k-均值(Euclid k-means)以及本文提出的高维数据聚类算法(HDsim k-means)对其进行聚类对比分析。为提高遗传降维算法的效率,随机抽取数据集中的部分数据进行降维,生成降维转换器后对未被抽取的数据进行降维映射,获取相应的低维坐标。在聚类分析前,去掉iris和zoo数据集中的类标识属性,聚类后,利用聚类结果和类标识属性信息进行对比,即对各方法获得的聚类结果采用基于已知类标识分布的聚类质量度量方法——聚类簇纯净度PCC及聚类熵EIC进行质量评价,其定义参见文献[17]。
图5(a)、(b)、(c)分别为利用PCA k-means、Euclid k-means以及HDsim k-means对iris数据集的聚类可视化结果,表2和表3分别为各聚类方法所用时间和精度的对比。图6为zoo数据集的降维聚类可视化结果,表4和表5分别为利用二步聚类、Euclid k-means以及 HDsim k-means对zoo数据集的聚类所用时间和精度的对比。为便于可视化结果的对比,各方法降维结果均已进行归一化。针对zoo数据集,由于PCA方法仅适用于变量之间存在一定相关性的数值型数据集的降维,而不能用于处理非线性数据和分类型数据,因此,无法利用PCA k-means方法对zoo数据集进行降维聚类(降维结果无意义)。

图5 iris数据集降维聚类可视化Fig.5 Dimensionality reduction clustering visualization of data set iris
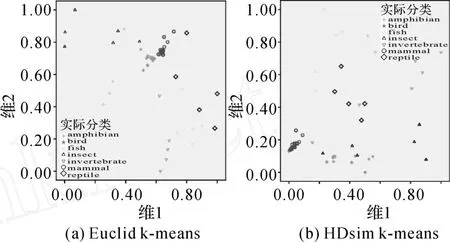
图6 zoo数据集降维聚类可视化Fig.6 Dimensionality reduction clustering visualization of zoo set iris

表2 iris数据集各算法聚类时间对比Tab.2 Consuming time of each clustering algorithm to data set iris s

表3 iris数据集聚类结果对比Tab.3 Clustering results of data set iris
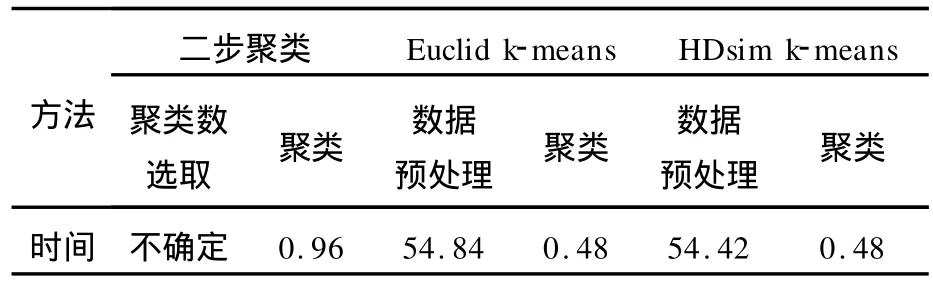
表4 zoo数据集各算法聚类时间对比Tab.4 Consuming time of each clustering algorithm to data set zoo
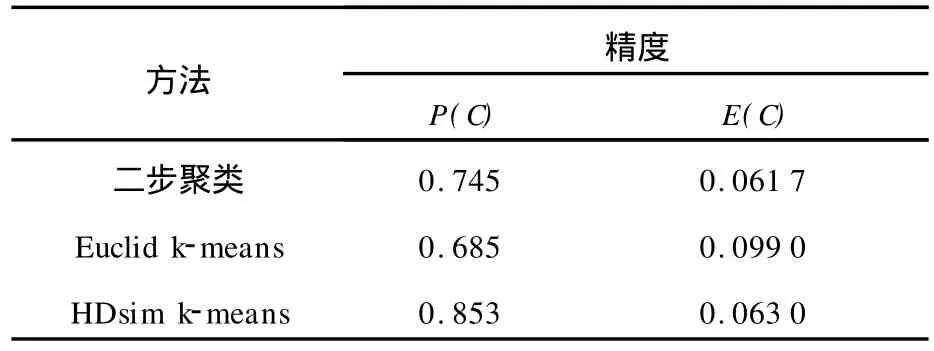
表5 zoo数据集聚类结果对比Tab.5 Clustering results of data set
3.3 试验分析
k-均值聚类的精度取决于聚类个数和初始中心确定的好坏,在处理高维数据时,由于不易确定其聚类个数和初始聚类簇中心,导致聚类结果和聚类时间无法确定,而降维可视化对k-均值聚类中聚类个数和初始中心的选取具有指导意义。在确定聚类数和初始聚类簇中心后,由于k-均值聚类是对原始高维数据进行处理,而 PCA kmeans、Euclid k-means以及 HDsim k-means是对降维后的数据进行处理,降维后的数据量明显少于原数据量,因此,仅就聚类时间(不包括数据预处理、聚类数和初始簇中心的确定所需时间)而言,PCA k-means、Euclid k-means以及 HDsim k-means的聚类时间要少于k-均值聚类。Euclid k-means和 HDsim k-means算法数据预处理阶段所需时间较长,而PCA k-means所用的时间要远远少于 Euclid k-means和 HDsim k-means算法,但PCA应用范围有限,主要表现在以下几个方面:①当随机生成的数据集维数达到170维左右时,传统的 PCA方法已无法对其进行降维;②PCA不能对数值型以外的数据进行降维;③PCA不能处理非线性数据。
文中涉及的各降维聚类方法中高维数据对象的降维坐标是通过不同性质的降维方法(PCA、基于Euclid距离保持的降维以及基于HDsim相似性保持的降维方法)获取的,因此,利用各方法求取的数据对象降维后的坐标之间并没有相关性,从而导致聚类可视化结果图5、6中各方法降维聚类结果在数据分布上不存在相似性。由可视化结果图5可知,算法 PCA k-means、Euclid kmeans和 HDsim k-means都较好地保留iris各聚类数据的内部局部结构,但PCA k-means所获得的聚类结果中Virginica和Versicolor两类之间无明显界线;由图6可以看出,算法 Euclid kmeans和 HDsim k-means较好地保留各聚类数据的内部局部结构,但 Euclid k-means的聚类可视化中类与类界限不清晰。
从iris和zoo数据集的聚类精度对比结果可以看出,本文提出的基于相似性保持和特征变换的高维数据聚类改进算法 HDsim k-means在聚类精度上要优于传统的经典聚类方法、PCA kmeans和 Euclid k-means。针对数值型数据集(iris),文中所提出的聚类方法的聚类纯净度及聚类熵远远好于 k-均值和 PCA k-means,略好于Euclid k-means;针对分类型数据(zoo),文中方法的聚类熵与二步聚类结果类似,但优于Euclid kmeans,且聚类纯度最高。改进算法不仅在聚类精度上优于其他算法,而且该方法只需获得对象间的相似度,利用遗传交叉变异可以方便地对数据进行相似性保持的数值化降维,后续的聚类过程可以采用统一的经典聚类算法(如k-均值)完成,而不需对聚类流程进行重新设计。
4 结 论
通过对本文聚类方法与传统聚类方法、PCA k-means以及Euclid k-means聚类结果的可视化和精度对比,证明本文提出的改进聚类算法在高维空间中的有效性和可行性。研究结果表明:①本文提出的相似性度量函数在形式上比原有公式复杂,但方法的实质只是增加了对各维属性类型的判断,其计算量并未增加;②在降维过程中对HDsim相似性的保持比对Euclid距离进行保持更好地保留了各聚类数据的内部局部结构;③改进聚类算法虽然在降维阶段所需时间较长,但通过降维结果的可视化较好地解决了传统k-均值不易确定聚类数和初始聚类中心的问题;④在降维后的低维空间中保持高维数据对象间相似性,即将高维数据对象间的相似程度转化为低维空间中对象间的相似程度,则对映射后的二维样本聚类就相当于对原始的高维样本聚类,因此,本文提出的改进聚类算法具有可行性。
[1] CECILIA M.Clustering Problems and Their Applications [R].Durham:Duke University,1997.
[2] XIE Lihong.The Research on Clustering for High Dimensional Data[D].Wuhan:Wuhan University,2002.(谢立宏.面向高维数据的聚类算法研究[D].武汉:武汉大学,2002.)
[3] LIU Jiping,WANG Hongbin,WANG Chengbo,et al.Fuzzy Nearest Neighbor Clustering of High-dimensional Data[J]. Journal of Chinese Computer Systems,2005,26(2):261-263.(刘纪平,汪宏斌,汪诚波,等.基于模糊最近邻的高维数据聚类[J].小型微型计算机系统,2005,26(2): 261-263.)
[4] JOSHUA Z H,MICHAEL K,RONG H Q,et al.Automated Variable Weighting in k-Means Type Clustering[J].IEEE Transactions on Pattern Analysis and MachineIntelligence,2005,27(5):657-668.
[5] YANG Fengzhao,ZHU Yangyong.An Efficient Method for Similarity Search on Quantitative Transaction Data[J]. Journal of Computer Research and Development,2004,41 (2):361-368.(杨风召,朱扬勇.一种有效的量化交易数据相似性搜索方法[J].计算机研究与发展,2004,41(2): 361-368.)
[6] ZHAO Heng.Study on Some Issues of Data Clustering in Data Mining[D].Xi’an:Xidian University,2005.(赵恒.数据挖掘中聚类若干问题研究[D].西安:西安电子科技大学,2005.)
[7] AGGARWAL C C.Re-designing Distance Functions and Distance-based Applications forHigh Dimensional Data [J].ACM SIGMOD Record,2001,30(1):13-18.
[8] AGGARW AL C C.On the Effects of Dimensionality Reduction on High Dimensional Similarity Search[C]∥Proceedings of the 20th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems.New York:ACM,2001: 256-266.
[9] LIU Xiaoming,YIN Jianwei,FENG Zhilin,et al.Orthogonal Neighborhood Preserving EmbeddingBased Dimension Reduction and Classification Method[J].Journal of Image and Graphics,2009,14(7):1319-1326.(刘小明,尹建伟,冯志林,等.正交化近邻关系保持的降维及分类算法[J].中国图象图形学报,2009,14(7):1319-1326.)
[10] L I Yang.Distance-preserving Projection ofHighdimensional Data for Nonlinear Dimensionality Reduction [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(9):1243-1246.
[11] LIU Zhonghua,ZHOU Jingbo,CHEN Yi,et al.Non-linear Dimensionality Reduction Techniques of Distance-preserving Projection for Visualization and Classification[J].Acta Electronica Sinica,2009(8):1820-1825.(刘中华,周静波,陈燚,等.距离保持投影非线性降维技术的可视化与分类[J].电子学报,2009(8):1820-1825.)
[12] WANG Na,DU Haifeng,WANG Sunan.Iterative Optimization Clustering Algorithm Based on Manifold Distance [J].Journal of Xi’an Jiaotong University,2009,43(5): 76-79.(王娜,杜海峰,王孙安.一种基于流形距离的迭代优化聚类算法[J].西安交通大学学报,2009,43(5): 76-79.)
[13] TENENBAUM J B,SILVA V,UNGFORD J C.A Global Geometric Framework for NonlinearDimensionality Reduction[J].Science,2000,290(12):2319-2323.
[14] GENG Xiepeng,DU Xiaochu,HU Peng.Spatial Clustering Method Based on Raster Distance Transform for Extended Objects[J].Acta Geodaetica et Cartographica Sinica, 2009,38(2):162-167,174.(耿协鹏,杜晓初,胡鹏.基于栅格距离变换的扩展对象空间聚类方法[J].测绘学报, 2009,38(2):162-167,174.)
[15] GUO Qingsheng,Zheng Chunyan,HU Huake.Hierarchical Clustering Method ofGroup of Points Based on the Neighborhood Graph[J].Acta Geodaetica et Cartographica Sinica,2008,37(2):256-261.(郭庆胜,郑春燕,胡华科.基于近邻图的点群层次聚类方法的研究[J].测绘学报, 2008,37(2):256-261.)
[16] WANG Baowen,YAN Junmei,LIU Wenyuan,et al.High Dimensional Datas Fuzzy Clustering Based on Genetic Algorithm[J].Computer Engineering and Application, 2007,43(16):191-192,221.(王宝文,阎俊梅,刘文远,等.基于遗传算法的高维数据模糊聚类[J].计算机工程与应用,2007,43(16):191-192,221.)
[17] ZHANG Weijiao,LIU Chunhuang,LI Fangyu.Method of Quality Evaluation for Clustering [J].Computer Engineering,2005,31(20):10-12.(张惟皎,刘春煌,李芳玉.聚类质量的评价方法[J].计算机工程,2005,31(20): 10-12.)
Improved High Dimensional Data Clustering Algorithm Based on Similarity Preserving and Feature Transformation
WANGJiayao1,XIE Mingxia1,2,GUO Jianzhong1,CHEN Ke1
1.Institute of Surveying and Mapping,Information Engineering University,Zhengzhou 450052,China;2.75719 Troup,Wuhan 430074,China
Improved high dimensional data clustering algorithm based on similarity preserving and feature transformation is proposed.Firstly,gain the similarity matrix of high dimensional data with the designed similarity measure function,and translate it into distance matrix of the shortest path through the nearest neighbor searching method and the algorithm Floyd.Then,translate high dimensional feature transformation into the optimization and resolve this optimization problem with genetic algorithm.The reduced data is used for clustering analysis via k-means and the value pairs between the coordinates of high dimensional data and their reduced 2D coordinates are used for RBF neural network training.Determine the belongingness of new object based on the distance from the new object to each current clustering center through the trained neural network.Finally,the experimental results prove the validity of the improved similarity measure and the operability of the dimensionality reduction method based on feature transformation.
feature transformation;high dimensional data clustering;similarity measure;dimensionality reduction
WANGJiayao(1936—),male,professor, academician ofChineseAcademicofEngineering, majors in teaching and scientific research of cartography and geographic information engineering.
1001-1595(2011)03-0269-07
TP181
A
国家863计划(2009AA12Z228);国家科技支撑计划课题(2007BAH16B03)
(责任编辑:宋启凡)
2010-03-10
2010-09-27
王家耀(1936—),男,教授,中国工程院院士,从事地图制图学与地理信息工程学科的教学与科研。
E-mail:wangjy@cae.cn
