烃类沸点的定量构效关系研究
2011-12-22陈利平谢传欣陈网桦
杨 惠,陈利平 ,谢传欣,石 宁,陈网桦
(1.化学品安全控制国家重点实验室,青岛 266071;2.南京理工大学化工学院安全工程系,南京 210094)
烃类沸点的定量构效关系研究
杨 惠1,2,陈利平2*,谢传欣1,石 宁1,陈网桦2
(1.化学品安全控制国家重点实验室,青岛 266071;2.南京理工大学化工学院安全工程系,南京 210094)
应用CODESSA软件计算296种烃类物质的分子结构描述符,分别用启发式回归(HM)和最佳多元线性回归(B-MLR)筛选计算出的所有分子描述符,并建立沸点的线性回归模型。用B-MLR方法筛选出的4个描述符作为支持向量机(SVM)的输入建立了非线性模型。预测结果表明:所建立的模型稳健,泛化能力强,预测误差小。非线性模型(R2=0.9905,RMSE=10.2295)的性能优于线性回归模型(HM:R2=0.9819,RMSE=14.0606;B-MLR:R2=0.9842,RMSE=13.1058),预测效果令人满意。
烃类物质;沸点;支持向量机(SVM);定量构效关系(QSPR)
0 引言
可燃性液体的闪点和燃点表明其发生爆炸或火灾可能性的大小,是很重要的安全参数。同样地,可燃性液体的沸点与其运输、储存和使用的安全也有着很大的关系。当外部环境的温度升高或内部反应热的作用使可燃液体的温度升高时,低沸点的可燃液体将大量汽化,当蒸汽压超过容器的承压极限时,容器将发生物理爆炸,大量可燃液体泄漏并与空气发生混合,从而形成大面积的易燃易爆云团,当存在适当的点火源时,就有可能导致严重的蒸气云爆炸。一般说来,沸点越低,在一定温度下承装可燃液体的容器内部压力越高,越易导致容器物理爆炸,同时液体抛撒后也越易气化形成易燃易爆云团。
定量构效关系(Quantitative structure-property relationship,QSPR)研究是目前国内外研究的一个热点,已成为近年来化学、环境科学、生命科学等学科研究中的一个前沿领域[1],其应用越来越受到重视。目前,国内外许多研究学者已做了大量研究,发展了许多根据分子结构预测化合物性能的方法和模型。其中,关于沸点的QSPR研究主要是利用拓扑指数、量子化学参数等与沸点进行关联[2-7],以建立线性的QSPR模型。这些方法相对来说比较复杂,而且不能揭示沸点与其结构间所存在的非线性关系,预测的精度也有待进一步提高。
本文根据QSPR研究的基本原理,尝试引入支持向量机(SVM)方法对易燃烃类物质沸点的QSPR关系进行研究,建立沸点与其分子结构之间的非线性模型,并与启发式回归(HM)和最佳多元线性回归(B-MLR)所建立的线性模型进行对比。
1 SVM简介
SVM是由Vapnik等人[8,9]基于统计学习理论基础上提出的一种新型机器学习方法,它能较好地解决小样本、非线性、高维数和局部极小等实际问题,具有精度高、速度快、自适应能力强、不受高维维数限制等优点。近年来,SVM在构效关系中有了一些较为成功的应用[10-12]。
概括地说,SVM就是通过某种事先选择的非线性映射,将输入向量映射到一个高维特征空间,并在这个空间中构造最优分类超平面的实现方法[13]。通过在高维空间中构建最优超平面,可以将问题转化为二次规划。SVM建立在结构风险最小化基础上,因此对于小样本观测数据,建立的模型不但训练误差小,而且具有良好的泛化推广性能。
2 研究方法
2.1 样本数据说明
样本集共包含296种烃类物质,为消除不同数据库中因数据差异可能给预测结果造成的影响,统一采用美国阿克伦大学化学品数据库“The Chemical Database”[14]中烃类物质的沸点作为样本数据集。其中,随机选择了236种物质作为训练集,剩下的60种作为测试集。训练集主要用于建立模型,测试集则用于评估模型的预测能力。
2.2 分析步骤
首先借助化学分子模拟软件 Hyperchem 8.0画出296种烃类物质的二维分子结构,用半经验方法PM3进行分子结构的初步优化。在此基础上获得分子坐标以及原子电荷矩阵,导入到CODESSA软件[15,16]中计算出组成描述符、拓扑描述符、几何描述符、静电描述符、量化描述符以及热力学描述符等六类374种分子结构描述符。
接下来对分子结构描述符进行筛选。在QSPR研究中,分子结构描述符的筛选至关重要,它直接影响预测结果的准确性。本文采用CODESSA软件中的HM和B-MLR方法来筛选描述符,同时对烃类物质沸点与所选出的分子描述符进行了线性拟合。SVM的研究则直接采用B-MLR方法所筛选出的分子描述符作为自变量来对物质的沸点进行训练,以建立非线性模型。
2.3 模型的评价与检验
模型验证是QSPR研究中非常重要的一个部分,通过结果的好坏可以判断模型的外部预测能力和真实有效性。
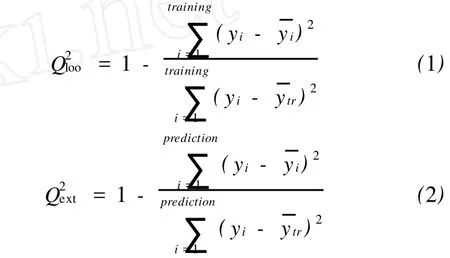
模型的检验主要分为内部检验和外部验证。相关系数R和复相关系数R2通常被用于检验模型的拟合能力,即用于模型建模能力的验证。R2越大,说明回归模型的相关性越好,能够解释的样本所占的比例越大,但并不一定保证模型具有更好的预测精度。交互检验的Q2是目前使用较为广泛的一种内部检验方法,其中的“留一法”(Q2loo)是最常用的交叉验证方法。好的交叉验证结果 Q2可以说明QSPR模型的稳健性和良好的内部预测性能,但是交叉验证的结果好并不保证模型的真实预测能力也好。Tropsha等的最新研究结果[17,18]表明,对模型预测能力的评价必须通过对那些未参与训练的物质进行预测,即采用测试集来进行检验,因为测试集样本不参与建模,因而对模型的真实预测能力更能做出客观的评价。
3 结果与讨论
3.1 HM分析
针对训练集样本,运用 HM方法对计算出的所有描述符进行广泛搜索,以复相关系数、交互验证系数以及F检验值作为选择模型的标准,最终确定了本研究中与烃类沸点最为密切相关的4个分子描述符,所得的沸点(BP)回归模型如下:
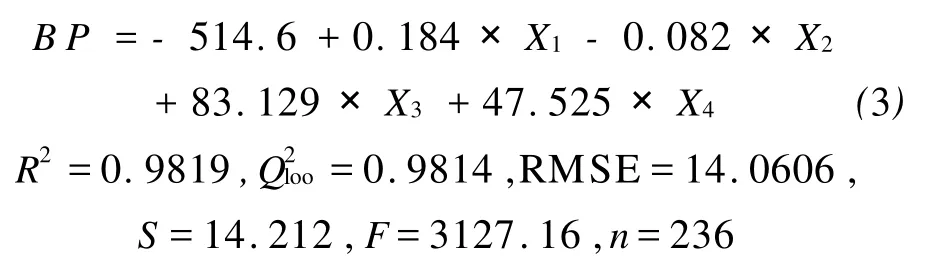
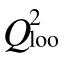

表1 HM模型中的分子描述符及其统计学参数Table 1 Statistic parameters of molecular descriptors in HM model
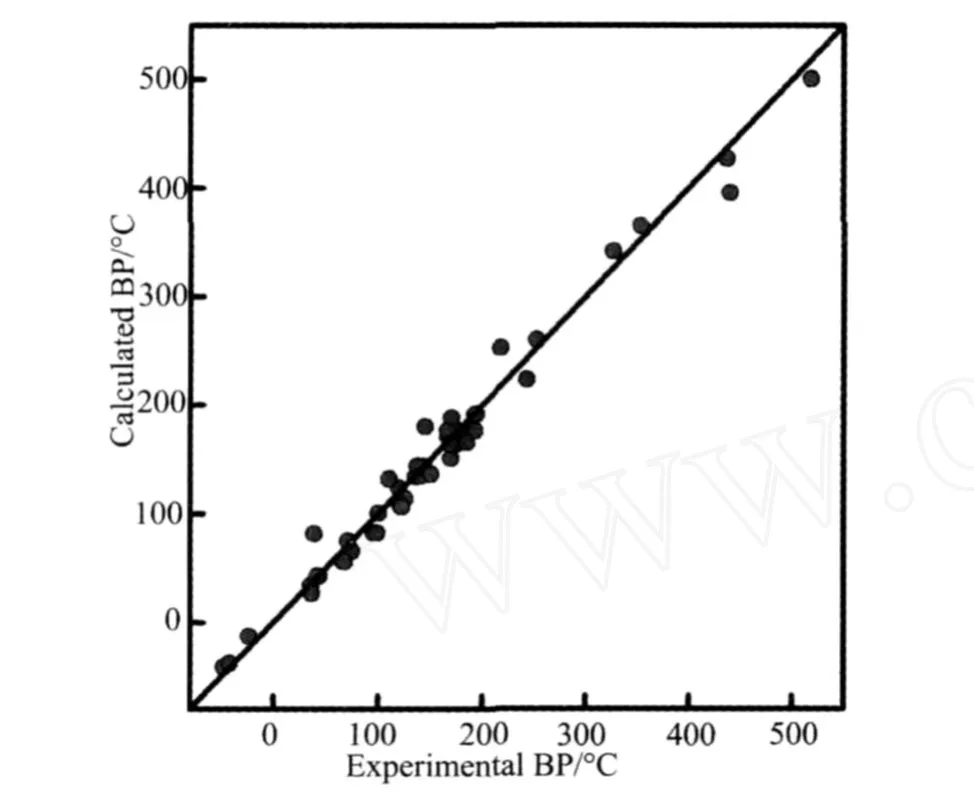
图1 HM对测试集所得沸点预测值与实验值的比较Fig.1 Comparison between the predicted and experimental BP by HM for test set
随后,对测试集中60个样本的沸点进行预测,以验证模型的外部预测能力。模型的主要性能参数见表3,所得的沸点预测值与实验值的比较见图1。
3.2 B-MLR分析
用B-MLR方法筛选出的4个分子描述符所建立的沸点(BP)回归模型如下:
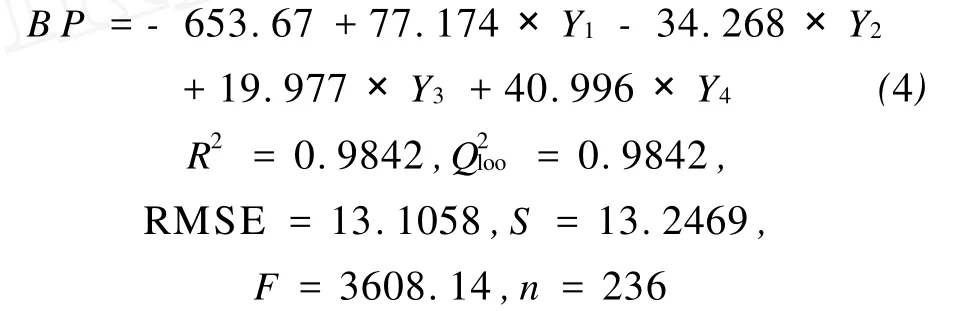
模型中各分子描述符的定义及其统计学参数见表2,主要性能参数见表3,所得的沸点预测值与实验值的比较见图2。

表2 B-MLR模型中的分子描述符及其统计学参数Table 2 Statistic parameters of molecular descriptors in B-MLR model
3.3 SVM分析
为了进一步对烃类物质沸点与其分子结构间可能存在的非线性关系进行研究,直接以B-MLR方法所筛选的4个分子描述符作为自变量,运用SVM方法进行建模。用SVM做预测时,相关参数(主要是惩罚参数 C和核函数参数γ)的选择是个难点,参数选择不好,将会严重影响预测的精度和准确率。
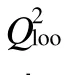
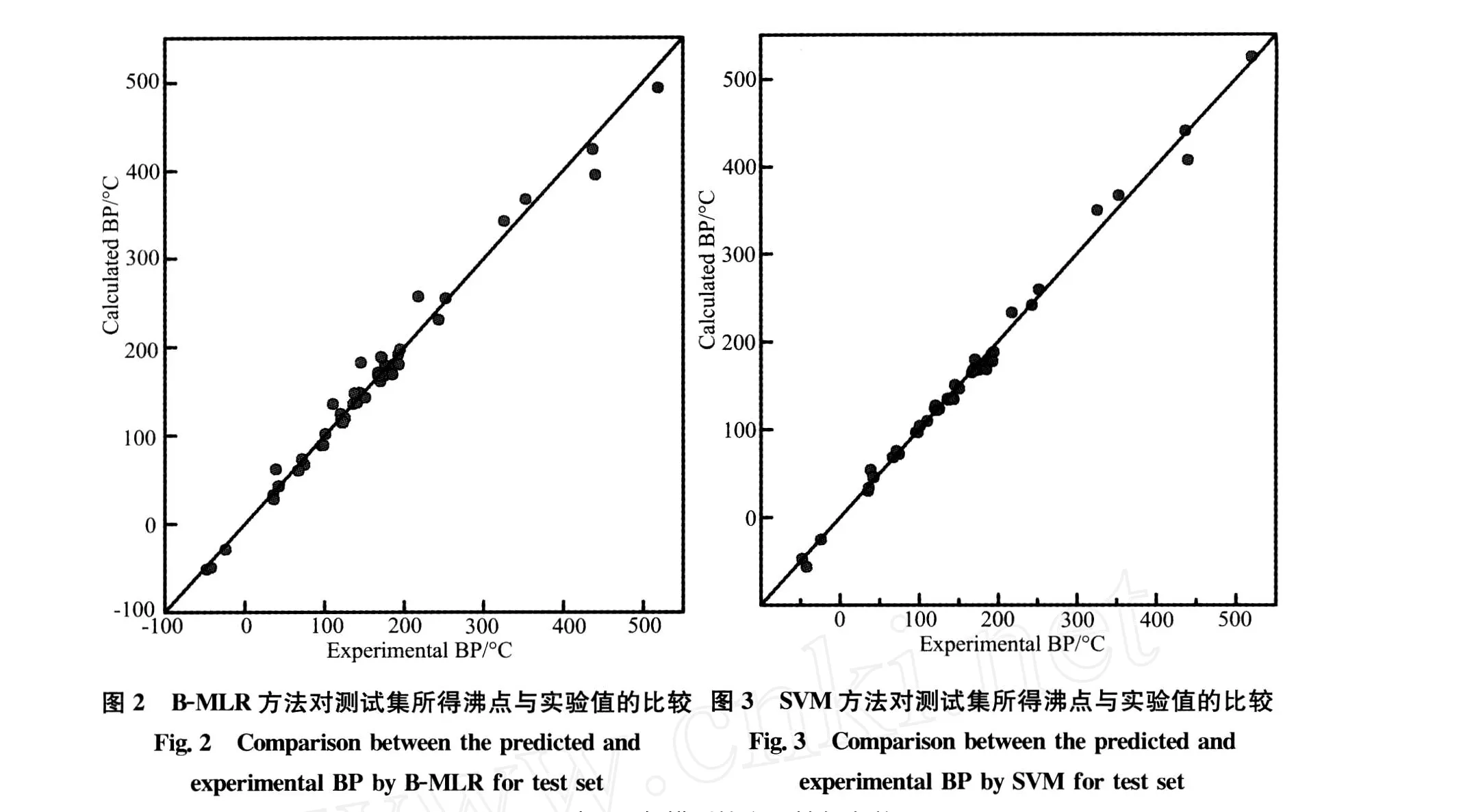
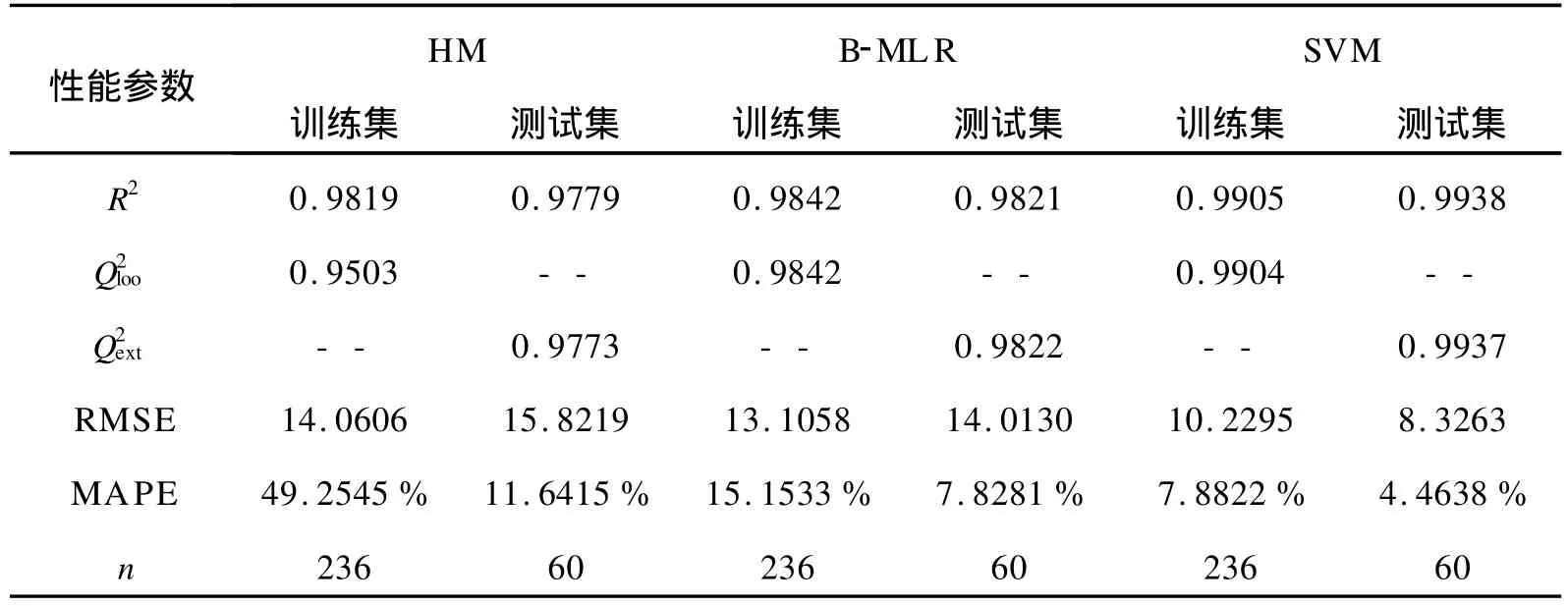
表3 各模型的主要性能参数Table 3 Performance comparison between these models
3.4 结果的比较与分析
从图1、图 2、图 3可以看出,不论是 HM、BMLR还是SVM方法,对测试集中60个样本的预测值均与实验值有较好的一致性,预测精度令人满意。比较模型中训练集和测试集的预测结果发现,各子集的复相关系数均比较高,预测误差较低,而且比较接近,这说明所建立的模型不但具备较强的预测能力,而且具有较强的泛化推广性能。
由表3的数据可以看出,SVM方法不论在建模还是预测效果上都比 HM和B-MLR方法更好,性能更优越。另外,SVM的模型中,测试集比训练集的复相关系数更高,说明模型具有更高的预测性能。其测试集的平均绝对误差百分率 MAPE为4.4638%,与线性模型(11.6415%和 7.8281%)相比减小了许多,说明SVM模型的预测误差有所减小,预测更准确。因为SVM是一种基于结构风险最小化原则的机器学习方法,对于小样本的研究体系具有较强的非线性拟合能力和较好的泛化推广性能,这说明烃类物质的沸点与其分子结构间可能存在较强的非线性关系。
因此,将SVM用于烃类物质沸点的QSPR研究是成功的,所建立的模型具有一定的稳健能力和较强的预测性能。
4 结论
分别采用 HM、B-MLR和SVM方法对296种烃类物质的沸点进行QSPR研究,建立了沸点的预测模型,其中以SVM方法所建立的模型性能最好,揭示了烃类物质沸点与其分子结构间可能存在的强烈的非线性关系,也说明了将 SVM方法应用于QSPR研究的优越性,它有效地解决了小样本、非线性、过拟合、维数灾难和局部极小等问题,具有较强的泛化推广性能。
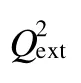
[1]Jyrki Taskinen,Jouko Yliruusi.Prediction of physicochemical properties based on neural network modeling[J].Adv Drug Delivery Rev,2003,55:1163-1183.
[2]冯长君,沐来龙.边支化度指数与环烷烃沸点的相关性[J].化学工业与工程,2005,22(5):338-341.
[3]孙海霞,周莲.链烃的沸点与分子拓扑指数 SZ[J].海南大学学报(自然科学版),2008,26(4):312-315.
[4]唐自强,冯长君.Randic边支化度指数与环烷烃沸点的相关性[J].辽宁工程技术大学学报(自然科学版),2008,27(5):795-797.
[5]刘凤萍,梁逸曾,曹晨忠.拓扑-量子指数醛酮气相色谱保留指数及沸点的定量构效关系[J].分析化学,2007,35(2):227-232.
[6]齐玉华,许禄,王淑云.量化参数在黄酮类化合物构效关系研究中的应用[J].计算机与应用化学,2000,17(1):29-31.
[7]禹新良,王学业,高进伟,等.用量子化学参数研究烯烃聚合物定量构效关系[J].化学学报,2006,64(7):629-636.
[8]Vapnik V.Statistical Learning Theory[M].New York:Wiley,1998.
[9]Cortes C,Vapnik V.Support–Vector network[J].Machine Learning,1995,20:273-297.
[10]潘勇,蒋军成,曹洪印,等.基于支持向量机方法的烃类物质自燃点预测[J].石油学报,2009,25(2):222-227.
[11]Wang Jie,Du Hongying,Liu Huanxiang,et al.Prediction of surface tension for common compounds based on novel methods using heuristic method and support vector machine[J].Talanta,2007,73(1):147-156.
[12]马喜波,阎爱侠.支持向量机算法用于烷基苯的热容和标准焓值的预测[J].北京化工大学学报(自然科学版),2008,35(2):33-37.
[13]Vapnik.The Nature of Statistical Learning Theory[M].Springer-Verlag,New York,NY,1995.
[14]Department of chemistry of university of akron.The Chemical Database[OB/OL].[2010-01-16].http://ull.chemistry.uakron.edu/erd/.
[15]Katritzky A R,Perumal S,Petrukhin R.CODESSABase theoretical QSPR model for hydantoin HPLC-RT[J],J.Chem.Inf.Comput.Sci.,2001,41:569-574.
[16]Katritzky A R,Lobanov V S,Karelson M.CODESSA Version 2.0 Reference Manual[R].Florida:University of Florida,1997.
[17]Tropsha A,Gramatica P,Gombar V K.The importance of beingeamest Validation is the absolute essential for successful application and interpretation of QSPR models[J].QSAR Comb Sci,2003,22(1):69-77.
[18]Gramatica P,Pilutti P,Papa E.Validated QSAR prediction of OH tropospheric degradation of VOCs Splitting into training-test sets and consensus modeling[J].J Chem Inf Comput Sci,2004,44(5):1794-1802.
Quantitative structure-property relationships for boiling points of hydrocarbon compounds based on SVM
YANG Hui1,2,CHEN Li-ping2,XIE Chuan-xin1,SHI Ning1,CHEN Wang-hua2
(1,State Key Laboratory of Chemical Safety and Control,Qingdao 266071,China;2,Department of Safety Engineering,School of Chemical Engineering,Nanjing University of Science&Technology,Nanjing,210094,China)
296 molecular descriptors of hydrocarbon compounds were calculated by the CODESSA program,and these descriptors were pre-selected by heuristic method(HM)and best multi-linear regression method(B-MLR).Four-descriptor linear models were developed by the two methods to describe the relationship between the molecular structures and the boiling points.Using the four descriptors which were selected by B-MLR,the non-linear regression model was established based on the support vector machine(SVM).The predicted results indicated that the models had robustness,strong generative ability and small prediction error.The performance of the non-linear model(R2=0.9905,RMSE=10.2295)was better than that of the linear model(HM:R2=0.9819,RMSE=14.0606;B-MLR:R2=0.9842,RMSE=13.1058).
Hydrocarbon compounds;Boiling point;Support vector machine(SVM);Quantitative structure-property relationship(QSPR)
O622.1
A
1004-5309(2011)-0062-06
2010-11-12;修改日期:2010-12-16
化学品安全控制国家重点实验室开放研究基金。
杨惠(1986-),女,湖北人,硕士研究生,安全技术及工程专业,研究方向为化学品危险性定量构效关系研究。
陈利平,讲师,E-mail:clp2005@hotmail.com.
