地震数据模型优化过程方法及初步应用
2011-12-06杜军辉闫丽莉屈春燕单新建
杜军辉 闫丽莉 屈春燕 刘 治 单新建
(中国地震局地质研究所,北京 100029)
地震数据模型优化过程方法及初步应用
杜军辉 闫丽莉*屈春燕 刘 治 单新建
(中国地震局地质研究所,北京 100029)
由于地震数据种类繁多且数量不断增大,使得地震数据共享和数据服务面临的困难越来越大。针对这个问题,提出了基于PowerDesigner建模工具对已有的地震数据模型进行优化的过程方法。并将此方法初步应用于现有的1/400万活动断层GIS数据库中,针对该库目前存在的问题,实现了对断层数据模型的优化,结合具体的实例,应用了优化后的断层数据库。同时,将优化前后的断层数据物理模型进行了对比分析,表明优化后的模型使用起来更加灵活、方便,数据描述更加准确,数据之间的关系更加清晰,数据约束更加规范、完善,能够满足地震工作者不同的需求,为今后的地震数据共享和数据服务奠定了良好的基础。
PowerDesigner 地震数据模型 数据模型优化 数据库
0 引言
目前国内地震数据建模工作较成熟的应属石油地质方面,围绕石油储层建模是近些年发展起来的高新技术,可以实现对油气储层的定量表征及对各种尺度的非均质性的刻画。在地质数据方面,通过研究地学数据的基础内容标准、专用标准和应用规则,形成几种较完整的地学数据建模的模式。例如地质界面建模、地质体建模、块段建模、实体建模法,从二维地质建模到三维建模研究,再到可视化的建模方法,并且建成了一批重要的地质数据库(马承杰,2005;轩兴涛,2008)。
地震数据模型是地震数据库的基础,而地震数据库已是地震业务、地震研究、地震信息网络等的基础。应用需求与数据模型具有一一对应的关系,即不同的需求对应着不同的数据模型。地震数据模型的建立需要依据应用需求和各个学科的数据特征来设计(李谊瑞等,1993;王秀英等,2004;姚运生等,2006;路鹏等,2007)。中国地震基础数据观测网络建立后,借助各种先进的观测手段,每天产生海量的动态数据和数据产品。故需要建立各类地震数据库,使得观测数据能够长期、系统、准确、全面地累积和保存。随着地震信息获取能力的不断增强,地震数据量和种类的不断增多,应用需求也在不断的变化,这时基于原有地震数据模型的地震数据库不再满足不断变化的应用需求,在这些情况下,对现有地震数据库的数据模型进行优化,建立健壮的数据库系统显得尤其重要。
本文针对目前地震行业地震数据模型的现状,提出一种针对地震数据模型优化的过程方法,并选取现有的全国1/400万活动断层GIS数据库(以下简称断层数据库)(屈春燕,2008)对象作为样本数据,来说明优化方案的具体实践过程。
1 数据建模及典型建模工具介绍
1.1 数据建模介绍
数据模型,就是描述数据的结构和性质、数据之间的联系以及施加在数据或数据联系上的一些限制。按不同的应用层次分为3种类型:分别是概念数据模型(CDM)、逻辑数据模型(LDM)、物理数据模型(PDM)。
数据建模指的是对现实世界各类数据的抽象组织,确定数据库需管辖的范围、数据的组织形式等,直至转化成现实的数据库。将经过系统分析后抽象出来的概念模型转化为物理模型后,在数据库建模工具基础上,建立数据库实体以及各实体之间关系的过程,就是数据建模的过程(萨师煊等,2000),如图1所示为数据建模的过程。

图1 数据建模过程Fig.1 Process of datamodeling.
1.2 典型数据建模工具介绍
PowerDesigner是一个允许设计人员创建、管理数据结构及开发、利用数据结构,针对开发工具及环境快速生成应用对象和数据的组件。Powerdesigner支持.net,java,pb、delphi等各种语言。开发人员可以使用同样的物理数据模型查看数据库的结构和整理文档,以及生成应用对象和在开发过程中使用的组件。
此外,PowerDesigner还为我们提供了方便的逆向工程特性。可以将目前所有流行的后端数据库(包括SYBASE、DB2、Oracle等)的结构信息通过逆向工程加入到PowerDesigner的物理数据模型和概念数据模型中,包括表、索引、触发器、视图等,即从已有数据结构或数据库脚本文件生成PDM的过程。
地震数据库为地震研究提供了基础,数据模型的建立关系着数据库系统的好坏,PowerDesigner包括了数据库数据建模的各个方面,从而可以保证高效和高质量的数据库建设以及数据管理工作。
2 地震数据模型优化的过程方法
地震数据模型优化的整体过程较为复杂,既涉及到所选取的分析方法——面向对象的分析方法,又涉及到地震行业的专业知识以及对应数据的应用场景。
具体来说,对一个已有的地震数据模型进行分析优化的工作过程如下 (图2):

图2 地震数据模型优化过程Fig.2 The flow chart of earthquake datamodel optimization.
2.1.1 创建已有数据结构模型
创建已有数据结构模型,根据选取的建模工具(PowerDesigner)的特点,可以使用逆向工程或者手工重建数据结构的方式创建。其中,数据结构逆向工程是把数据库中的数据表映射到设计软件中,以图表显示,通过参数配置与添加,最终生成物理数据模型;手工重建数据结构,顾名思义,则是利用现有数据库表手工重新创建数据结构。
2.1.2 模型分析
数据分析决定系统开发的成败。在各类应用系统开发的初期,进行准确全面的数据分析是必不可少的,能够避免当问题不断出现时才不断修补,甚至系统构架需要不断调整或重新设计的情况。通常,我们借助图形化的模型来理解数据所描述的领域,使系统开发过程变为一种图形化的模型构建过程,这也叫做建模过程。可以说,数据分析也是一个建模过程,具体包括以下过程:
(1)模型对象提取,需要从地震专业的角度对整体的数据对象进行逻辑归纳,分类形成逻辑意义上的信息对象集合;
(2)参数化,需要通过对数据内容的分析,归纳出所需的支持性内容,即形成数据内容的参数表(业务字典表),如果出现多张表使用同一的参数表,建议考虑创建此业务字典表作为共有的数据对象;
(3)规范化,需要从地震专业的角度归纳数据本身的从属和冗余关系,应用数据库设计范式,拆分和理清关键的主从对象(表)关系;
(4)非规范化,非规范化过程本身是一个相对主观的过程,可能包含的数据结构调整有:为适应常用业务的需要,对常用作查询条件等内容的信息进行适度冗余,即将该信息字段重复存放于多张数据库表当中;为适应常用业务的需要对日常进行查询的结果要求进行适度派生,即将该查询结果要求字段与相关信息字段在数据库表中进行适度的耦合关联。
2.1.3 根据应用调整模型
在完成模型分析方法分析后,产生的数据模型可能还是不能很好地适应需求,那就需要在此基础上进一步考虑实际情况,对数据模型进行分析优化过程,这一阶段的工作相对更偏向于应用本身,而且本过程的优化可能导致上述第2阶段的工作需要重复进行,细分该工作过程如下:
(1)分析数据对象写入操作方式,采取对应的优化措施。包括:写入过程频繁的数据对象,尽量减少一次性写入的字段个数,减少在数据对象中的冗余字段,并且尽量使用字段表;批量写入的数据对象(地震相关数据中该类数据比较多),尽量考虑“一表化”写入,即批量写入只操作一个数据对象,避免主外键冲突,如“一表化”代价过高可以考虑取消父子数据表间的主外键关系。
(2)分析数据对象更新/删除操作方式(地震相关数据使用较少),采集对应的优化措施。包括:尽量使用无实际意义的ID作为表主外键,尽量避免使用联合主键;分析长期不使用的数据,创建对应的备份表脱机管理。
(3)分析数据对象读取操作方式,采集对应的优化措施。包括:读频率远大于写频率的数据表,尽量使用心型、雪花型模式创建;读写频率均很高的表,尽量针对操作方式分步建立数据结构;即“一表化”写入,异步加载至查询专用表;对于需要长期在线,数据量又非常大的数据表,使用分区表或者分割表进行处理。
2.1.4 创建结果数据结构
创建结果数据结构,根据分析结果使用PowerDesigner创建对应的数据结构模型。根据需要可以考虑建立与具体的数据管理系统无关的概念数据模型或者直接创建对应关系数据库的物理数据模型。
3 地震数据模型优化过程方法的初步应用
地震数据不仅系统庞大,而且多样化,范围从空间数据到非空间数据无所不包。因此,对所有的地震数据进行优化是非常巨大的工程。而GIS数据作为地震数据的一类,包括地理要素的属性数据和大量的空间数据,即描述地理要素空间分布位置的数据,具有自己的特殊性。所以本文选取地震断层GIS数据作为样本数据,针对其本身特有的属性,在现有GIS数据模型的基础上对其进行优化。
因此,我们选取现有的全国1/400万活动断层GIS数据库对象作为样本数据,来说明优化方案的具体实践过程,对比最后生成的数据模型与原数据库的数据模型的不同,体现这种优化方法的优点。最后将优化后生成的断层数据库应用于具体的实例。
3.1 断层数据现状分析
现有的1/400万中国活动构造空间数据库的地震活动断裂数据库 (表1)中,按照活动构造数据库中数据存储形式的不同,分为图形数据和属性数据两部分。其中,图形数据描述的是各类地质要素及现象在特定坐标系中的空间分布,概括为点、线、面3种空间特征要素,采用拓扑方式的矢量数据结构存储。属性数据是空间特征所具有的属性描述,采用关系数据模型即二维表的结构来记录和存储。
现有的1/400万中国活动构造空间数据库的地震活动断裂数据库,建库初期未经过系统建模阶段,数据结构只包含一张属性数据表,拥有26个属性域。所有的数据按照断层条目来存储,即一条数据存储一条断层信息。我们分析该地震断层数据库所存储的断层数据以及由表1分析数据的属性信息后,认为数据存在如下问题:
(1)该表为“一表化”表达,表内的数据关系表达不清楚,配合注释及地震业务知识能够简单理解数据含义;
(2)在数据中出现较多的惟一标识,但个别信息不同的情况(如断层的分段情况),这些数据需要进行对应的数据表拆分;
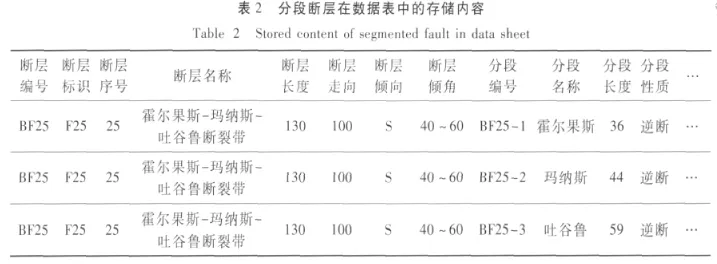
(3)分段断层的冗余存储。地震断层具有分段的特性,一条完整的断层由多段分段断层组成,因此在存储时将这些分段断层一一存储。若断层存在n个分段断层,那么数据库中就存储n条断层数据。例如,图3 a,b,c蓝色部分表示霍尔果斯-玛纳斯-吐谷鲁断裂带的3条分段断层,即该断裂带由3条分段断层组成。

表2是在该数据库中,霍尔果斯-玛纳斯-吐谷鲁断裂带的存储内容,显示该断裂带分为3条数据存储,其中对于该断裂带的基本信息,如断层编号、断层标识、断层名称等内容是相同的,分段断层的信息,如分段编号、分段名称、分段长度等是不同的。因此,对于相同的断层基本信息采用了重复存储,这样的存储方式造成了存储数据的冗余。
(4)主键无法确定。主键是惟一标识断层实体的属性或属性集,也是断层数据相互约束条件之一,一个表只有一个主键。主键应该有固定值(不能为Null或缺省值,要有相对稳定性),不含代码信息,易访问。在该地震活动断层数据库中,由于分段断层的冗余存储,使得断层编号、断层标识、断层序号以及断层名称重复存储,无法惟一的标识断层实体,而分段编号只能用来惟一约束分段信息,对于无分段性质的断层,分段编号又不能作为主键来对其进行约束。因此,无法找到一个合适的属性或属性集作为主键。
3.2 断层数据模型优化过程
针对上述现有的1/400万地震活动断裂数据库存在的问题,如不符合数据库建立的规范,无法确定主键等,给今后地震业务、地震研究、地震信息网络等大量不同需求的应用及数据的共享服务带来不便,为此应用前面提出的地震数据模型优化方法,对1/400万地震活动断裂数据库进行优化,具体过程如下。
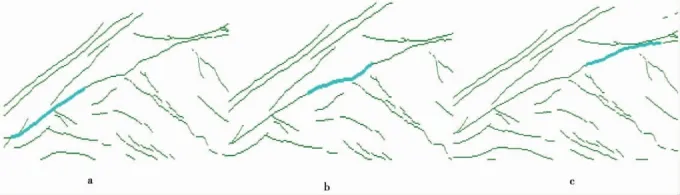
图3 霍尔果斯-玛纳斯-吐谷鲁断裂带的分段断层Fig.3 Fault segmentation of fault zone.
3.2.1 创建已有断层数据结构模型
在分析地震活动断裂空间数据库的数据现状之前,我们先生成这个数据库的物理数据模型。利用PowerDesigner提供的一种逆向工程的方法,即通过已有数据库的数据结构或者数据库脚本文件,逆向生成物理数据模型。我们利用这种方法,对原有数据库的二维关系表逆向工程生成原始的物理数据模型(图4)。
3.2.2 模型分析
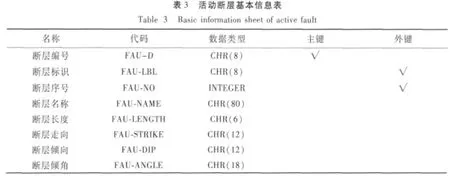
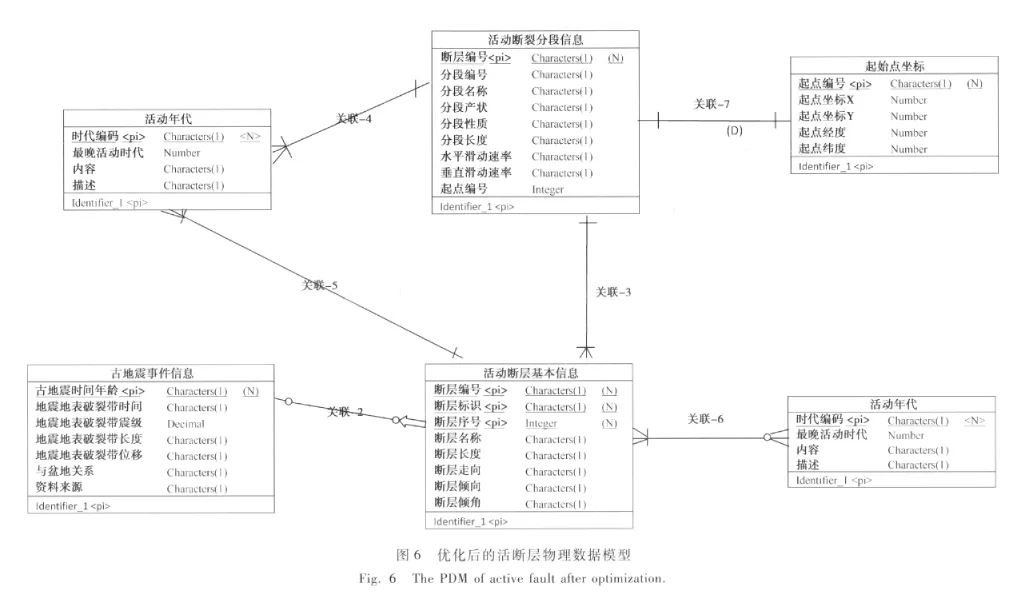
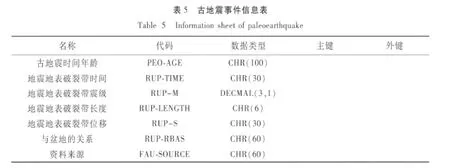
(1)模型对象提取。由以上分析得知:该断层数据库主要描述了3种数据:断层的基本信息(包括断层编号、断层名称等)、分段断层的信息(分段断层的编号、名称等)和与该断层有关的古地震事件的信息。其中,分段断层是断层的特殊性质,由断层运动而引起的地震信息存储在古地震信息里。由此,提取出3种地震断层数据对象:断层基本信息对象、分段断层信息对象和古地震信息对象,并对这3种对象重新定义其属性,这些属性只包括描述对象的如下信息:1)断层的基本信息(断层编号、断层标识、断层序号、断层名称、断层长度、断层走向、断层倾向、断层倾角);2)分段断层信息(分段编号、分段名称、分段产状、分段性质、分段长度、水平滑动速率、垂直滑动速率);3)古地震信息(古地震时间年龄、地震地表破裂带时间、地震地表破裂带震级、地震地表破裂带长度、地震地表破裂带位移、与盆地关系、资料来源)。
(2)参数化。在对数据属性的整理中,我们发现如断层的活动性质(包括正断、逆断等)、最晚活动时代(包括Q3p、Qh等)和分段年龄(包括Q3p、Qh等)这类数据,在数据上具有一定的范围,我们可以将这3种数据提取出来,作为描述数据对象的参数表,与对象具有一定的依赖关系。其中,最晚活动时代和分段年龄具有相同的数据内容,都表示的是时间概念,因此将它们合并为一个参数表,同属于断层基本信息对象和分段断层信息对象。
此外,在描述分段断层时,还需存储分段断层的起始点坐标,以确定分段断层的位置。在分段信息对象中增加起始点坐标的属性,并将起始点坐标作为一张表单独存储,函数依赖于分段信息对象。
(3)规范化和非规范化。在地震活动断裂数据库中,关系模式R的每一个分量都是不可再分的数据项,满足第1范式的要求,即R∈1NF,但是不满足第2范式的要求。下面举一个例子来说明R∈2NF,例如,对于关系模式:DC(断层编号、断层标识、断层序号、断层长度、分段编号、分段长度)。
从这个库表中我们可以看到:如果“断层编号”设置为主键,则“断层标识”、“断层序号”和“断层长度”与主键有一一对应的关系,但是“分段编号”、“分段长度”与主键并不是一一对应的关系,因此此表并不满足第2范式的要求。
断层编号(1)→断层标识(1);断层编号(1)→断层序号(1);断层编号(1)→断层长度(1);断层编号(1)→分段编号(n);断层编号(1)→分段长度(n)
经过模型对象提取和参数化后创建的断层基本信息表和分段断层信息表解决了不满足第2范式的问题。

图5 断层数据表字段的函数依赖关系Fig.5 An example of functional dependency of fault data sheet field.
(4)业务模型分析调整。1)分析数据对象写入操作方式,该表数据为一次性导入,导入频度很低,可以基本不考虑写入时的性能优化;2)分析数据对象更新/删除操作方式,该表数据可能会产生修正,但可能更新的数据项均为实体对象,本身不影响表的主外键结构。该表基本不产生删除操作,由此基本可以不考虑更新时的性能优化;3)分析数据对象读取操作方式,该表主要为其他查询提供参数支撑,甚至本身就是其他查询数据对象的维度表,另该表所包含的数据量不大,由此偏向使用雪花型模型进行数据结构分解。
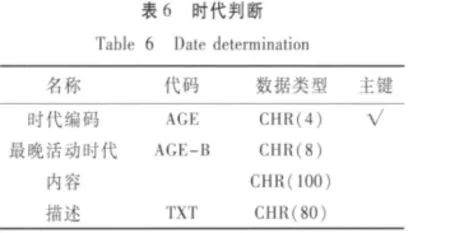
(5)创建结果数据结构。通过上述优化方法的应用,我们将地震断层数据库表按照最优结构,拆分成活动断层基本信息、活动断层分段信息、古地震事件信息、时代判断、起始点坐标、活动性质等6张表。通过各子表进行数据库关联,最终达到优化目的。
根据分析结构,创建较优的断层数据库模型(图6),优化后的表结构说明如下,其中数据对象表见表3~5,参数表见6~8。
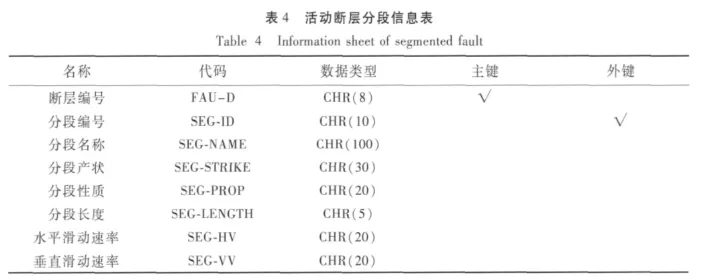
其中,活动断层基本信息表记录了描述断层的基本属性,即原数据库中重复存储的数据。由于一条分段断层只属于一条主断层,一条断层有多条分段断层,故创建活动断层分段信息表。而一个古地震事件可以由多条断层的运动引起;多条断层也可能引起多个古地震事件,故由断层运动而引起的地震的信息存储在古地震事件表里。
3.3 地震活动断层数据库物理数据模型优化前后对比
我们利用PowerDesigner逆向生成原来未经过优化的地震活动断裂数据库的物理数据模型(图4),现将它与使用全程建模方法得到的新物理数据模型(图6)进行比较,得到以下结论:
(1)过程优化方法提供了一个统一的地震数据结构分析和优化的表达过程,每个阶段的优化要素全面集成,生成实体关系图或对象图,然后可以直接将图转换为概念数据模型和物理数据模型。
(2)过程优化方法对数据进行标准化分析,使数据对象更准确,理清了数据之间的逻辑关系。
(3)提取对象后,明确了关键字和主键,使得数据之间的依赖关系得到整理,从数据模型三要素之一的数据约束方面优化了数据模型。
(4)优化后的数据模型改变了地震活断层数据库单一的二维表结构,丰富了数据信息,使整个数据流程一目了然。
(5)降低了数据冗余。新PDM体现了活断层分段的特点,解决了分段断层冗余存储的问题。参数表描述了数据对象的参数属性,参数化的表达方式节省了数据存储的空间。
(6)当需求变化时,传统方法生成的地震数据模型往往会处于劣势,通过修改数据库底层的逻辑数据模型来满足变化,而这种过程优化方法只需在系统分析的阶段调整分析模型,便会自上而下得到新模型,而无须修改数据库的底层数据模型。

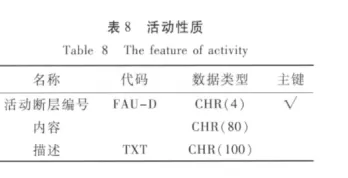
3.4 断层数据库优化应用
应用以上的数据模型优化过程方法,得到优化后的地震断层数据库。同时,对断层数据库进行实际应用。依据不同的研究目标设计程序,从前面优化后的数据库中提取相关的有效信息。如根据地震研究的需要,地震学者需要了解某条活动断层曾引发过多少次地震事件,为今后的地震研究工作提供准确、可信、快速的信息。如以鲜水河断裂为例进行查询,可以看到在距离断层50km的范围内,历史上共发生了17次6级以上的地震事件(图7)。

图7 优化后断层数据库应用实例Fig.7 Examples of application of the optimized fault database.
4 结论
通过分析地震数据模型目前存在的问题,应用典型、功能强大的数据建模工具——Power-Designer,提出了基于PowerDesigner建模工具对已有的地震数据模型进行优化的过程方法,并以活动构造数据库为例,进行了地震数据模型优化的初步应用,结果表明:
(1)随着地震信息获取能力的增强,地震观测数据量和种类不断增多,因此,对现有地震数据库的数据模型进行优化,建立合理的数据库系统显得尤其重要。
(2)地震数据模型优化步骤。利用PowerDesigner提供的一种逆向工程的方法,在数据优化过程中,需要采用以下步骤:创建已有的数据结构模型、模型分析、根据具体应用调整模型、创建数据结构模型。
(3)根据具体数据库结构存在的问题提出优化方案。以1/400万中国活动构造GIS数据库为例,由于建库初期未经过系统建模阶段,分析表明,数据结构为较单一的“一表化”表达,数据条目出现多个惟一标识,数据冗余较为严重。根据分析结果,依据所提出的地震数据模型优化过程方法对断层数据进行了优化。
(4)优化前后对比分析。将数据模型优化过程方法初步应用于断层GIS数据库中,实现了对断层数据模型的优化。研究结果表明,经过全程建模方法优化得到的物理数据模型,数据描述更加准确,数据之间的关系更加清晰,使用起来更加灵活、方便,数据约束更加规范、完善,数据冗余减小,能够满足地震工作者不同的需求,为地震数据的共享服务奠定了良好的基础。
李谊瑞,牟其铎.1993.中国地震数据库建设及其应用综述[J].国际地震动态,9:8—12.
LIYi-rui,MU Qi-duo.1993.Overview of the establishmentof earthquake databases in China and their application[J].Recent Developments in World Seismology,9:8—12(in Chinese).
路鹏,苗良田,李志雄,等.2007.中国科学数据共享现状的调查与分析[J].地震,27(3):125—130.
LU Peng,MIAO Liang-tian,LIZhi-xiong,et al.2007.Investigation on scientific data sharing situation and its analysis[J].Earthquake,27(3):125—130(in Chinese).
马承杰.2005.地震数据访问技术研究[J].石油工业计算机应用,13(4):5—7.
MA Cheng-jie.2005.A study of seismic data access technology[J].Computer Applications of Petroleum,13(4):5—7(in Chinese).
屈春燕.2008.最新1/400万中国活动构造空间数据库的建立[J].地震地质,30(1):298—304.
QU Chun-yan.2008.Building to the active tectonic database of China[J].Seismology and Geology,30(1):298—304(in Chinese).
萨师煊,王珊.2000.数据库系统概论[M].北京:高等教育出版社.
SA Shi-xuan,WANG Shan.2000.Introduction of Database Systems[M].Higher Education Press,Beijing(in Chinese).
王秀英,牛从达.2004.台网中心地震前兆数据库的结构及其管理维护[J].华北地震科学,22(3):28—32.
WANG Xiu-ying,NIU Cong-da.2004.The structure of precursor database in network center and itsmanagement[J].North China Earthquake Sciences,22(3):28—32(in Chinese).
轩兴涛.2008.基于PowerDesigner模型驱动机制下的全程建模研究[J].西安石油大学学报:自然科学版,23(6):104—106.
XUAN Xing-tao.2008.Full processmodeling technique based on the model drive mechanism of PowerDesigner[J].Journal of Xi'an Shiyou University(Natural Science Edition),23(6):104—106(in Chinese).
姚运生,李井冈,李胜乐.2006.提高地震前兆数据库存取效率的新表结构[J].大地测量与地球动力学,26(3):122—126.
YAO Yun-sheng,LI Jing-gang,LISheng-le.2006.A new table structure to improve earthquake precursor database access efficiency[J].Journal of Geodesy and Geodynamics,26(3):122—126(in Chinese).
THE SEISM IC DATA MODEL OPTIM IZATION METHOD AND PRELIM INARY APPLICATION
DU Jun-hui YAN Li-li QU Chun-yan LIU Zhi SHAN Xin-jian
(Institute of Geology,China Earthquake Administration,Beijing 100029,China)
Because the seismic data is so various and is continuously increasing in number,sharing seismic data and providing data service ismore difficult.This paper proposes amethod to optimize the existing seismic datamodel based on themodeling tool of PowerDesigner.Themethod was initially applied to the exiting 1/4000000 active fault GIS database.Aimed at the actual problem of active fault GIS database,themethod realizes the optimization of fault data model.And the optimized fault database was applied to specific example cases.Meanwhile,comparative analysis was done between the optimized PDM with the old one.The result shows that the optimized model ismore flexible and convenient to use,the data description ismore accurate,the relationship between data is clearer,and the data constraint ismore standard and complete.It can meet the different needs of seismologists.The proposed optimization method for earthquake datamodel has a certain value of popularization and application,and it lays a good foundation for seismic data sharing and data service in the future.
PowerDesigner,seismic datamodel,datamodel optimization,database
P315.61
A
0253-4967(2011)03-0706-13
10.3969/j.issn.0253 - 4967.2011.03.019
2009-06-02收稿,2011-01-15改回。
地震行业科研专项“地震数据模型优化技术研究”(200708049)资助。
闫丽莉,E -mail:yanlili_2003@163.com。
杜军辉,女,1981生,中国地震局地质研究所硕士研究生,主要从事计算机技术在地震科学研究中的应用,E-mail:dujunhui810224@163.com。
