上市公司自愿性信息披露水平影响因素实证研究
2011-11-29宜宾学院李文红
宜宾学院 李文红
上市公司自愿性信息披露水平影响因素实证研究
宜宾学院 李文红
本文采用多元回归分析方法对从深、沪两市筛选出的952家样本公司进行实证研究,结果发现,流通股比例、股权集中度、发行股票类型、独立董事人数、董事长与总经理二职合一、会计师事务所类型以及审计委员会的设置对自愿披露行为有显著影响。
一、研究设计
(一)自愿披露指数的设定 主要包括:
(1)信息条目的选取。本文设计的信息披露指数包括了36条自愿披露信息条目,具体条目如表1所示:
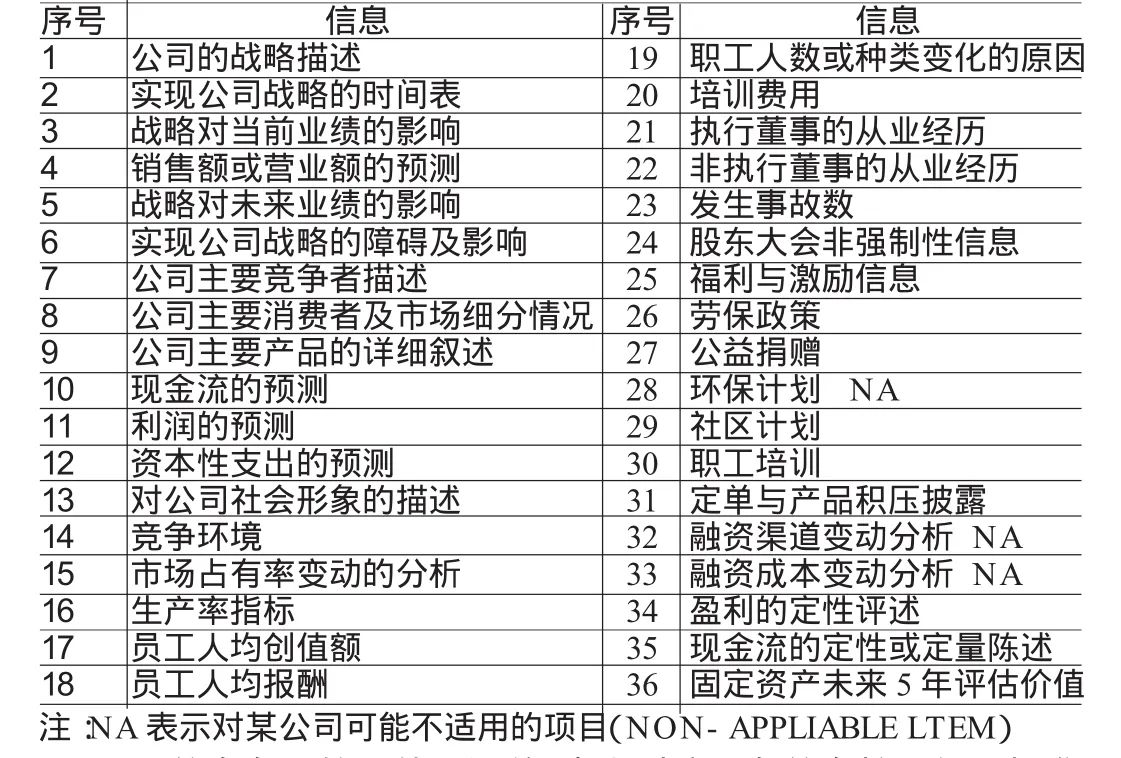
表1 上市公司自愿性信息披露信息条目表
(2)信息条目的取值及汇总。本文对这36条信息按照如下标准进行打分,这些取值标准是:第一,若该信息条目仅涉及定性披露,若详细描述给2分,一般性描述给1分,不披露则给0分。第二,若该信息条目涉及定性与定量披露,若仅作定性描述,则给1分,定性和定量相结合进行分析时给2分,既不作定性分析也不作定量分析时给0分,在通过信息条目的分值汇总成信息披露指数时,本文采用信息条目直接汇总的方法,避免人为分配权重。第三,信息披露指数形成。自愿性信息披露水平采用自愿披露指数VDI0来表示,第i家公司的自愿披露信息指数记为VDI0i,等于第i家公司各条信息条目得分之和除以按该公司有效信息条目计算的最佳得分之和。由于VDI0i的取值范围为0~1,为了满足多元回归对因变量取值范围的要求,本文采用与Mahmud Hossain一致的方式对VDI0进行如下替换,得到转化后的自愿信息披露指数VDIi,转化公式如下:VDIi=InVDI0i-In(1-VDI0i),经过转换后VDIi的取值范围为(-∞,+∞),而单调性没有改变。
(二)研究假设 结合国内外关于自愿披露影响因素的相关研究以及我国特有的研究背景,本文提出以下研究假设:
假设1:上市公司股权结构中流通股所占比例(TRADE)与自愿披露水平正相关;
假设2:上市公司股权集中度(HERF)与自愿披露水平负相关;
假设3:上市公司董事会中独立董事人数(RIND)与自愿披露水平正相关;
假设4:上市公司董事会构成中独立董事人数占董事会总人数的比例(RINDPR)与自愿披露水平正相关;
假设5:董事长与总经理二职合一(CEO)的上市公司具有较低的自愿披露水平;
假设6:设置了审计委员会(AC)的上市公司具有较高的自愿披露水平;
假设7:深圳上市的上市公司自愿披露水平要高于上海上市的公司(PLACE);
假设8:属于垄断行业(INDU)的上市公司具有较低的自愿披露水平;
假设9:发行两种及以上股票的上市公司具有较高的自愿披露水平(TYPE);
假设10:会计师事务所的规模(BIG4)与自愿披露水平正相关。
(三)模型构建 在确定研究中所用的上述变量之后,本文构建了用以检验我国上市公司自愿披露影响因素的多元回归模型:

式中,INSIZE表示公司的规模,ROE表示净资产收益率,DEBT表示负债程度,DIVI表示股利支付率,GROWTH表示公司成长性为控制变量。
(四)资料来源及样本选择 本文以深沪两地所有A股上市公司2009年年度报告全文为研究对象,选取了952家上市公司作为样本单位。这些样本公司行业分布为:制造业,562家;采掘业,17家;农、林、牧、渔业,27家;信息技术产业,68家;电气、煤气及水的生产和供应业,41家;建筑业,15家;交通运输、仓储业,42家;社会服务业,28家;传播与文化产业,9家;批发和零售业,75家;综合类,68家。
二、实证结果与分析
(一)整体回归结果及模型解释 参照表2,可以对回归方程的显著性及其解释能力作出分析。首先,由于F=56.518(p=0.000),因此,回归方程在显著性水平为0.1的假设上通过了检验;其次,表中的Adjusted R-square为0.467,说明回归模型对因变量的解释力为46.7%。此外,从表3所列示的残差分析结果也可以看出模型的拟合程度指标D-W值接近2,残差均值为0,方程整体效果明显。

表2 整体回归方程显著性检验表

表3 残差分析
(二)多元回归结果分析 在表4中,另外,对各个变量的方差膨胀因子(VIF)进行了计算,RIND所对应的膨胀因子最大,其值为1.706,小于10,证明了回归模型中变量间并不存在严重的多重共线性问题。
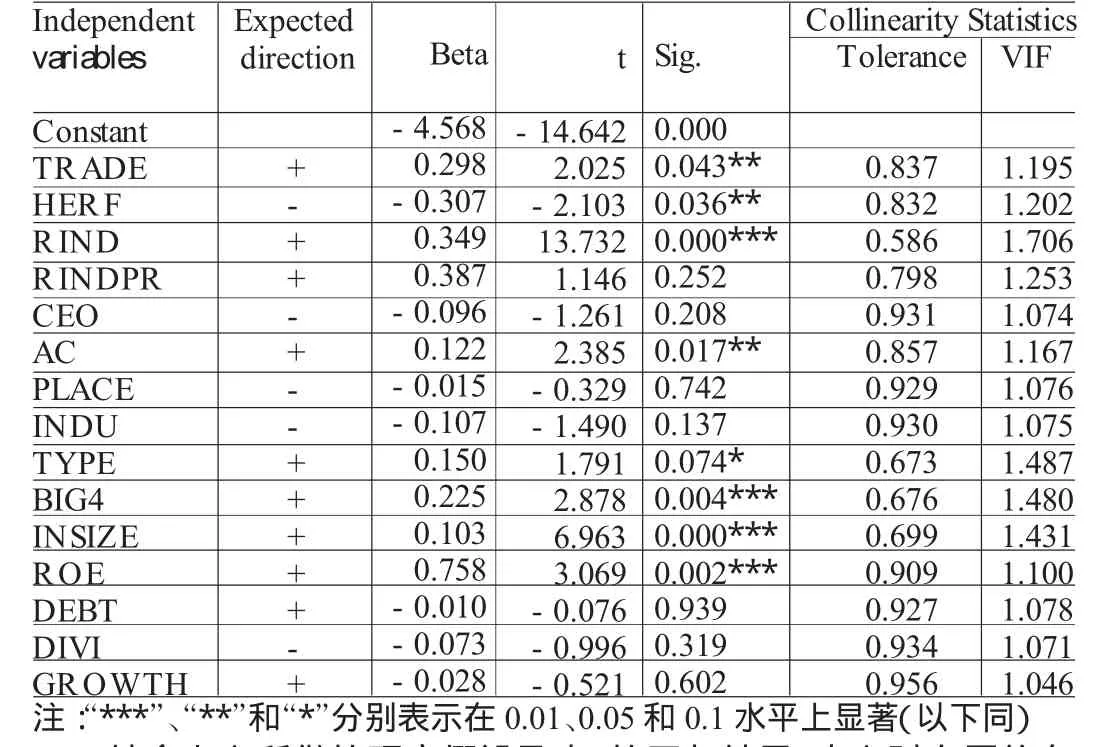
表4 回归系数及显著性检验表
结合上文所做的研究假设及表4的回归结果,本文对自愿信息披露水平的影响做出以下分析:
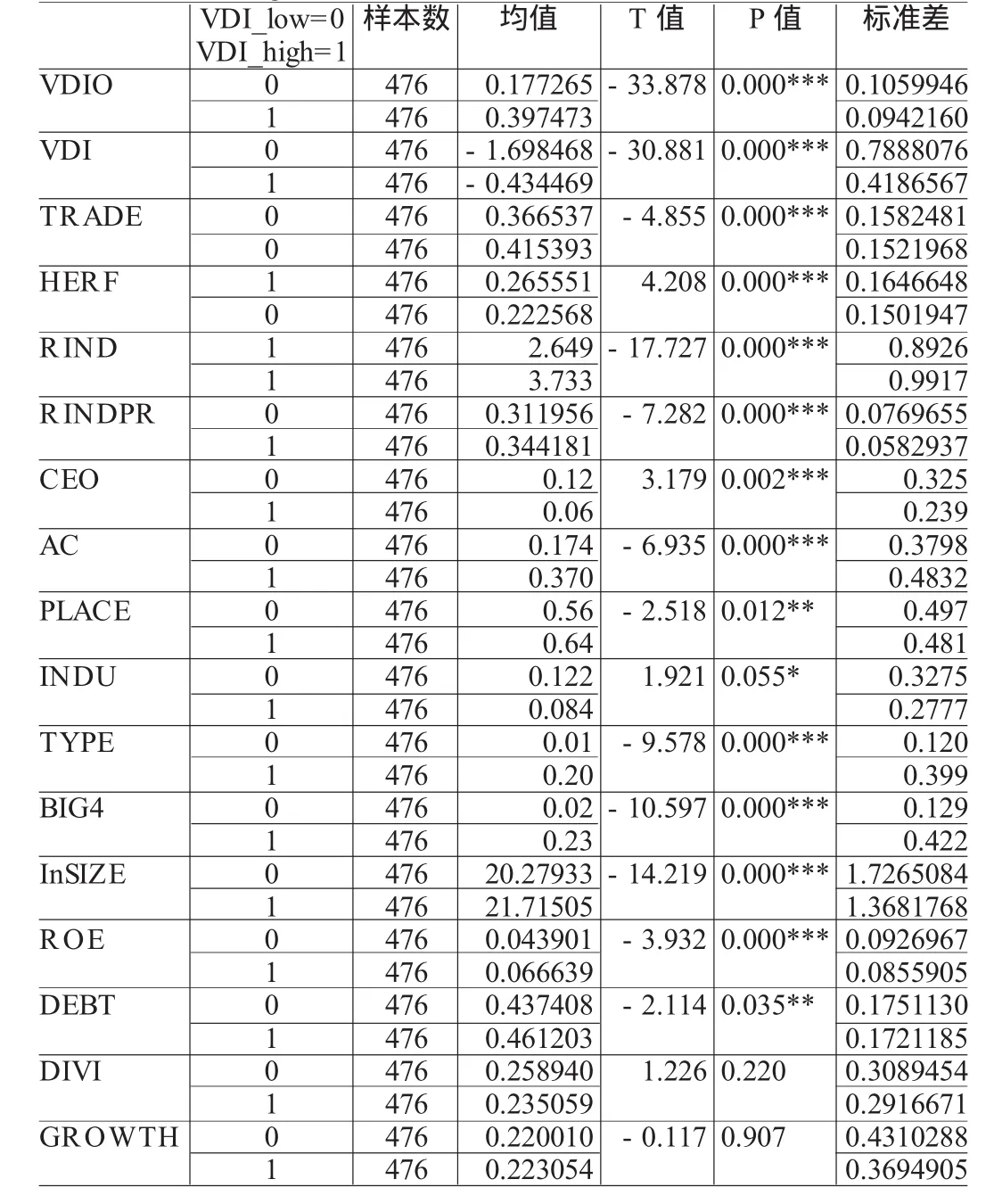
表5 VDI_high组和VDI_low组因变量与自变量的T检验
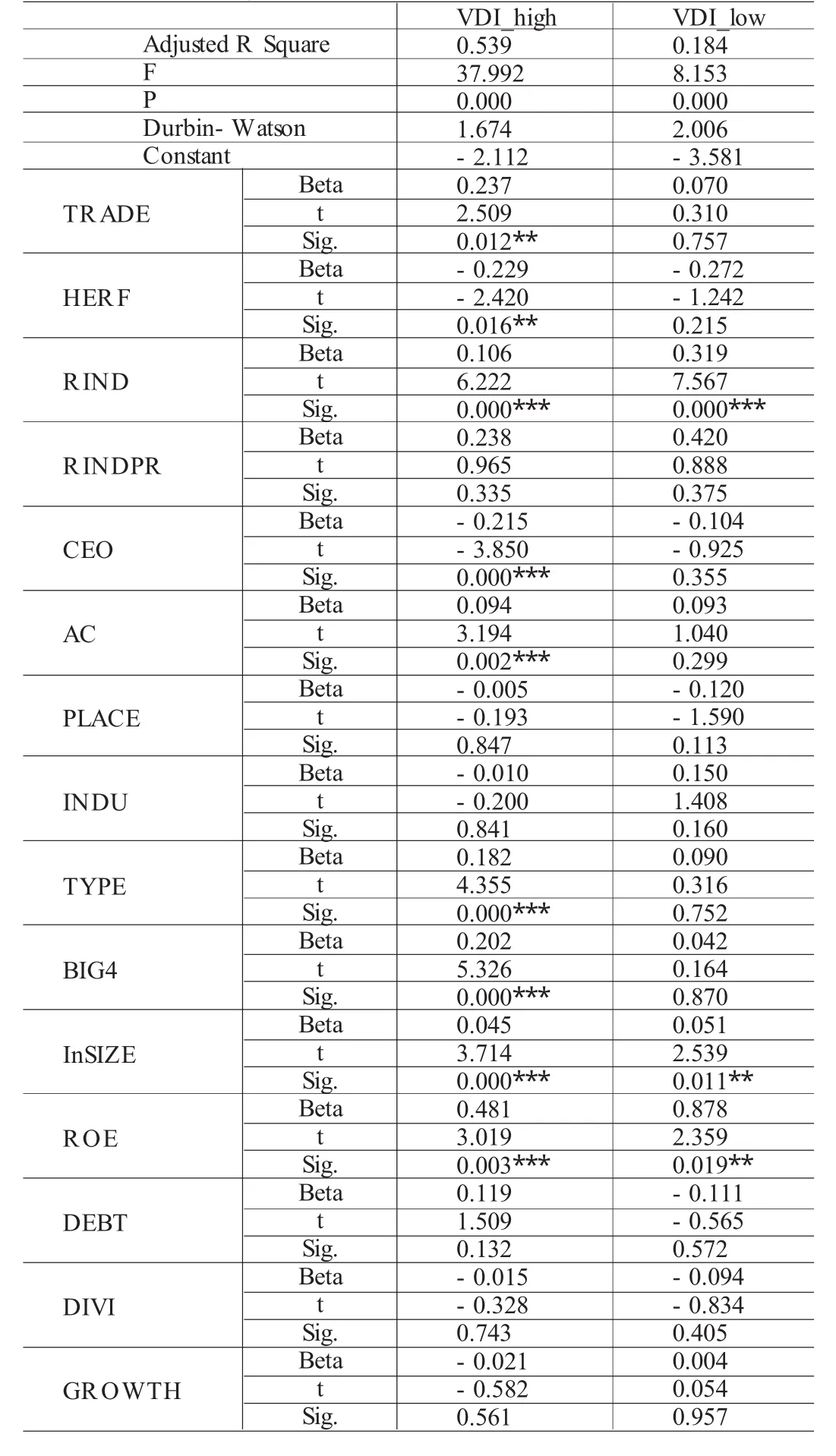
表6 VDI_high组和VDI_low组的多元回归结果
从回归结果中可以看出,流通股比例与自愿披露水平显著正相关,这说明流通股股东无法“用手投票”的前提下,他们可“用脚投票”,这种约束促使管理当局进行更多的自愿披露。股权集中度与自愿披露负相关,这说明了股权越集中,上市公司自愿披露的动机也就越少。独立董事人数通过显著性检验,但独立董事比例却没有通过显著性检验,表明我国独立董事在董事会中的比例不值得过分强调。审计委员会的设置与自愿信息披露正相关,这与中国证监会在2002年1月发布的《上市公司治理准则》中作出的设立审计等专门委员会等决议提供了一定的证据。上市地点变量没有通过显著检验,但系数符号与预计一致。这说明在深圳上市的上市公司信息披露水平略高于在上海上市的上市公司,市场效率越低的证券市场还更倾向于披露信息。究其原因,本文认为,这与目前我国上市公司自愿披露的意愿淡薄,普遍缺乏自愿披露的动力有很大的关系。行业类型变量也没有通过显著检验,但系数符号与预计一致。这说明垄断行业的上市公司更不愿披露更多的信息。这可能和我国目前垄断行业的上市公司国有股“一股独大”有关,存在事实上的内部人控制。发行股票类型变量通过显著性检验,即同时发行除A股以外的B股或H股的上市公司具有较高的自愿披露水平,这说明外部治理对于上市公司自愿披露行为能够产生极其明显的影响力。会计师事务所规模在回归模型中显示在1%水平上与自愿披露水平正相关,即经国际知名的前“四大”会计师事务所审计的上市公司具有较高的自愿披露水平。关于模型中的控制变量,公司规模和净资产收益率通过了验证,这说明信号理论对我国上市公司的自愿披露行为具有一定的解释力。
(三)分组回归结果及模型解释 为了对自愿性信息披露的影响因素做更深入的分析,本文按照自愿性信息披露的分值高低排序将样本分为两组,分别称作VDI_high组和VDI_low组,每组各有样本476家,分别做回归分析。这样做的目的在于试图挖掘对于自愿性披露状况好与差的公司,影响其披露的因素是否有不同。
首先,对两个组的因变量及自变量做了描述性统计和T检验,结果如表5所示。从表5中可以看出,描述VDI_high组和VDI_low组的自愿信息披露水平的VDI值有明显差别,前者大于后者。同时,描述型变量中除了股利支付率(DIVI)和公司成长性指标(GROWTH)外,其余变量在两个组之间均有显著差别。
然后对两个组分别做多元回归分析,其结果见表6。从表6可以看出,对于自愿披露水平较高的一组而言,其回归效果是比较好的,调整后的R2达到0.539,F值为37.992,在0.001的水平上具有显著性。对于自变量的回归结果,除了二职合一(CEO)变量外,其余自变量的回归结果与总体回归结果基本相同。二职合一(CEO)变量在总体回归结果中不显著,而在自愿披露水平高组却高度显著,其原因可能是自愿披露水平高组的董事长与总经理职位分离得较为彻底。
但对于自愿性信息披露状况较差的一组,其回归结果不尽人意,模型的模拟程度仅为0.184,仅有独立董事人数、公司规模和盈利水平三个变量进入回归方程。
为何在总体回归结果与自愿信息披露水平高组回归结果里显著的变量在这里却不能进入方程,笔者认为出现这一现象的原因可能是由于这个组的信息披露程度太低,其均值仅为0.177,也就是说在大约36个的自愿性披露项目中,这个组的上市公司平均只披露6个。而且其标准差为约10%,说明各个公司披露的分值与均值的差异不大。上市公司自愿披露信息的意愿淡薄,即使主动地、有意识地进行较多的自愿性披露也可能是出于某种目的。
[1]乔旭东:《上市公司年度报告自愿披露行为的实证研究》,《当代经济科学》2003年第2期。
(编辑 刘 姗)
