基于改进FP_Growth算法在中药提取信息中研究*
2011-11-07马健董辉
马健董辉
(亳州职业技术学院信息工程系,安徽 亳州 236800)
基于改进FP_Growth算法在中药提取信息中研究*
马健董辉
(亳州职业技术学院信息工程系,安徽 亳州 236800)
中药提取在中药生产中占有十分重要地位,企业在生产中药过程中,生产过程数据和质量数据存在一定的问题。数据挖掘技术的出现及利用k-means聚类算法和改进的FP_Growth算法对中药生产过程数据进行分析,既能为企业提高生产效率,降低成本,又保证产品的质量。因此对中药提取信息数据挖掘不仅是有必要的,更具有实际意义。
数据挖掘;关联规则;中药提取;FP-Growth算法
前言
亳州是全国著名的药材之乡,全市中药材种植面积约70万亩,约占全国种植面积的十分之一。亳州拥有全国规模最大、设备最先进的中药材专业市场。但是在中药生产企业中,中药企业对中药提取的生产过程还存在一些问题,企业在多年的生产过程中积累了大量的生产参数数据和产品质量数据,但是这些数据一直没有得到更好的利用,至今企业对生产和产品质量等参数的确定还在凭借操作人员的经验,缺乏科学的数据分析和指导,同时导致了产品质量的波动性。
数据挖掘技术旨在通过采用专业的数据挖掘算法进行分析,快速的从大量原始数据中提取隐含在数据之下的,人们无法直接获取的却又能对企业的生产决策和经营决策提供帮助的信息。关联规则挖掘是数据挖掘非常重要一种类型,FP-Growth算法是实现关联规则挖掘经典算法,本文在分析此算法的基础上,提出FP-Growth算法改进,并用这一算法对中药提起信息进行分析挖掘,希望为中药生产企业的发展和中药的发展提供一定帮助。
1.关联规则数据挖掘
1.1 关联规则挖掘
本文通过关联规则技术,分析过程数据和结果数据,探寻提取和浓缩过程与结果之间究竟存在怎样的关系,从而为企业的参数优化提供技术支持。
数据挖掘是近30年来逐步发展起来的一个新的研究领域,是多学科和技术相结合的产物,被广泛的应用于制造业、零售业、财务金融和医学研究等各个领域,为促进社会各方面的发展发挥重要的作用。关联规则挖掘作为数据挖掘的众多知识类型中最为典型的一种,在中药学领域有着广泛的应用。
关联规则用于表示OLTP数据库中诸多属性 (项集)之间的关联程度,是利用数据库中的大量数据通过关联算法寻找属性间的相关性。关联规则挖掘的问题描述如下:
设I= {i1,i2,i3,…,in}是数据项的集合,T={T1,T2,…,Tn}是一个事务数据库,其中每个事务T是数据项集I的子集即T⊆I,每个事务T有一个标识符TID与之相关。如果I的一个子集X满足X⊆T,则称事务T包含项目集X。一个关联规则就是形如X⇒Y的蕴涵式,X⊆I、Y⊆I、X∩Y=Φ。其意义在于一个事务中某些项的出现,可推导出另一些项在同一事务中也出现,此处,“⇒”称为“关联”操作,X称为关联规则的先决条件,Y称为关联规则的结果。例如:中药信息提取中,提取过程为A,固含量为B,则可用关联规则R表示为:R:A⇒B。支持度 (Support)和置信度 (Confidence)是关联规则中重要的概念,式 (1)和式 (2):
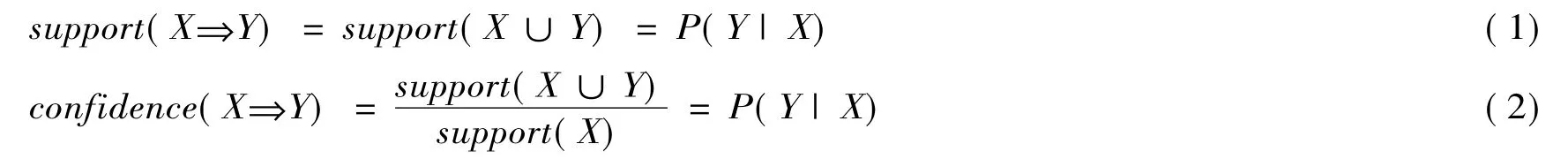
在实际应用中,支持度和置信度均较高的关联才可作为有用的关联规则,称之为最小支持度阈值 (min_sup)和最小置信度阈值 (min_conf),min_sup表示数据项在统计意义下的最低重要性,只有满足min_sup的数据项集才在关联规则中出现,称之为频繁项集;最小置信度则表示关联规则的最低可靠度。满足大于min_sup和min_conf的规则称为强规则,关联规则挖掘的任务就是发现所有频繁项集,挖掘出事务数据库D中所有的强规则。
1.2 FP-Growth算法改进
FP-Growth算法是韩家玮等人提出的基于FP-Tree增长树的著名算法,该算法在不产生候选集的情况下,提供了良好的频繁模式挖掘过程,性能比Apriori算法有所提高。但FP-Growth算法随着递归调用的深入,产生的条件FP-Tree越来越多,特别是在有共享前缀的情况下,FP-Growth算法非常耗时,为了解决这一问题,本文提出对FP-Growth算法的改进,命为FP-Growth*算法。
FP-Growth*算法的思想是:减少搜索共享前缀的时间达到减少生成FP-Tree的时间,以提高挖掘效率,即在存在共享前缀的条件下,遍历节点的第一个子节点就发现共享前缀。其挖掘步骤如下:
(1)频繁1-项集排序:扫描事务数据库D一次,生成频繁1-项集及每个频繁项集的支持度,按支持度降序排序,结果为L;
(2)事务项重排序:按照频繁项表L的次序对事务数据库项排序,生成事务数据库D1;
(3)事务集再排序:按照L的次序对D1的整个数据集再排序,即先对事务集的首列按L的次序排序,之后在此基础上对事务集的次列再按L的次序排序,依次类推到数据集的终列得到排序数据集D2;
(4)构造FP-Tree条件:创建以“null”为标记的根节点,扫描D2,对其中每个事务调用insert_tree(P,T)过程,生成FP-Tree。
(5)挖掘FP-Tree:递归调用FP-Growth算法,挖掘FP-Tree,得到频繁项集。
1.3 FP-Growth*算法实验分析
在相同的计算机软硬件系统中,随着数据集数目的增加,改进后的算法生成FP-Tree时间明显的减少,效率较高。根据实验分析,当数据集数目较大时,采用FP-Growth*算法挖掘效率提高20%左右,如图1所示:
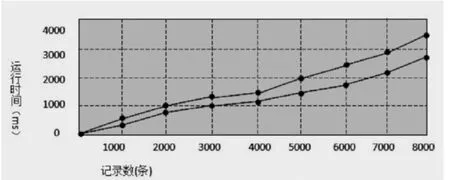
图1 FP-Growth*与FP-Growth算法生成FP-tree比较
2.用k-means算法对中药信息提取
2.1 K-means算法
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。[2]
该算法第一步中是随机的选取任意k个对象作为初始聚类的中心,初始地代表一个簇。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离将每个对象重新赋给最近的簇。当考察完所有数据对象后,一次迭代运算完成,新的聚类中心被计算出来。如果在一次迭代前后,J的值没有发生变化,说明算法已经收敛。[2]
算法过程如下:
(1)从N个文档随机选取K个文档作为质心
(2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
(3)重新计算已经得到的各个类的质心
(4)迭代2~3步直至新的质心与原质心相等或小于指定阀值,算法结束
具体如下:
输入:k,data[n];
(1)选择k个初始中心点,例如c[0] =data[0],…c[k-1] =data[k-1];
(2)对于data[0],…,data[n],分别与c[0]…c[n-1]比较,假定与c[i]差值最少,就标记为i;
(3)对于所有标记为i点,重新计算c[i] ={所有标记为i的data[j]之和}/标记为i的个数;
(4)重复 (2)(3),直到所有c[i]值的变化小于给定阈值。
2.2 采用k-means对数据进行聚类
目前企业提取生产的检测指标如下:

表2.1 当前降压避风片提取生产的检测指标
设置参数聚类数目范围为2-4,系统运行后得到聚类分析的结果如下:
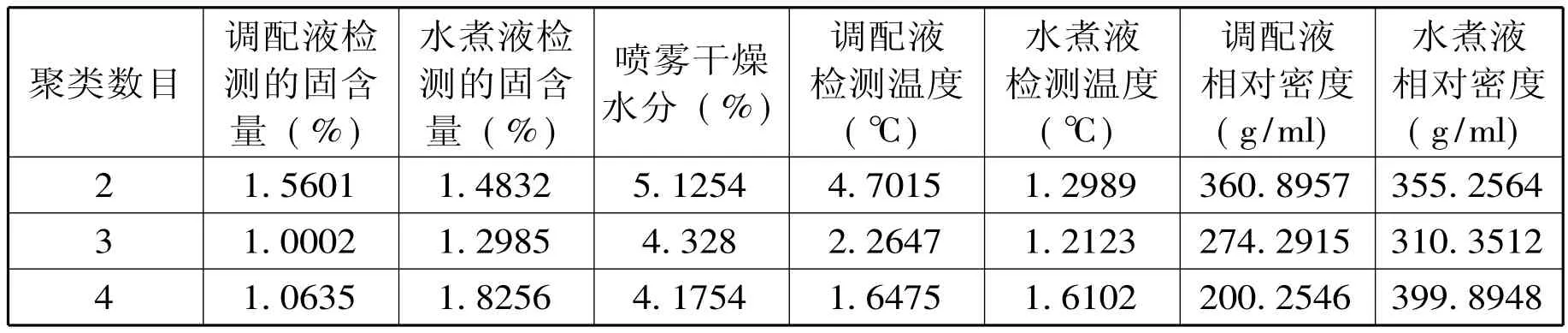
表2.2 k-means聚类参数G值比较分析
根据表2.2所提供的中药提取质检数据的七个属性,采用k-means聚类的初始参数进行优劣比较,聚类数目的参数范围2-4,选择G值最小值对应的参数作为k-means聚类算法的初始参数。通过计算,如要得到的聚类越精确,那么优质因子goodness Index值的划分要小,所以根据最佳聚类数据把参数代入相应的函数,就可以得到k-means聚类结果。
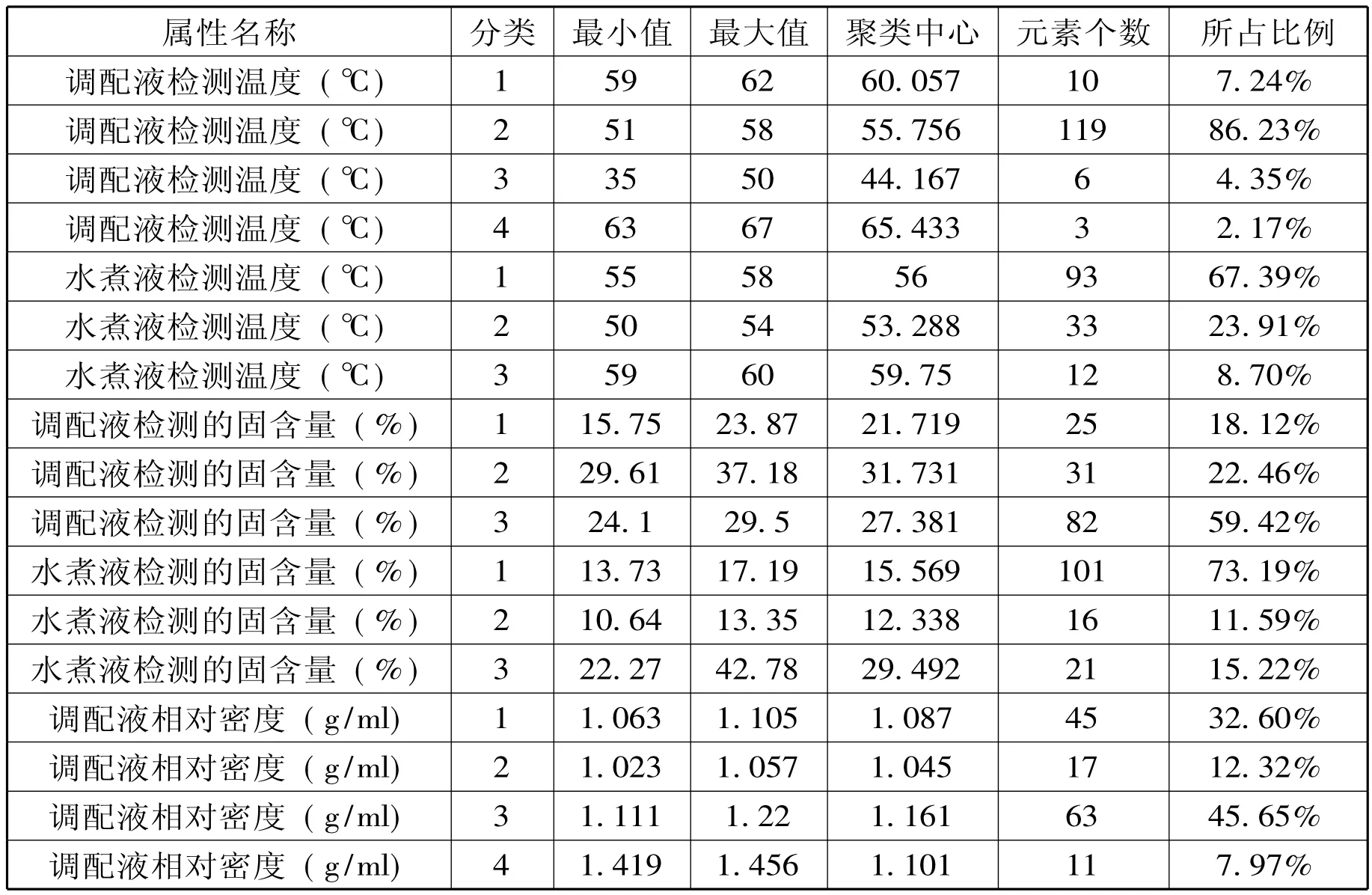
表2.3 质量检测数据k-means聚类结果
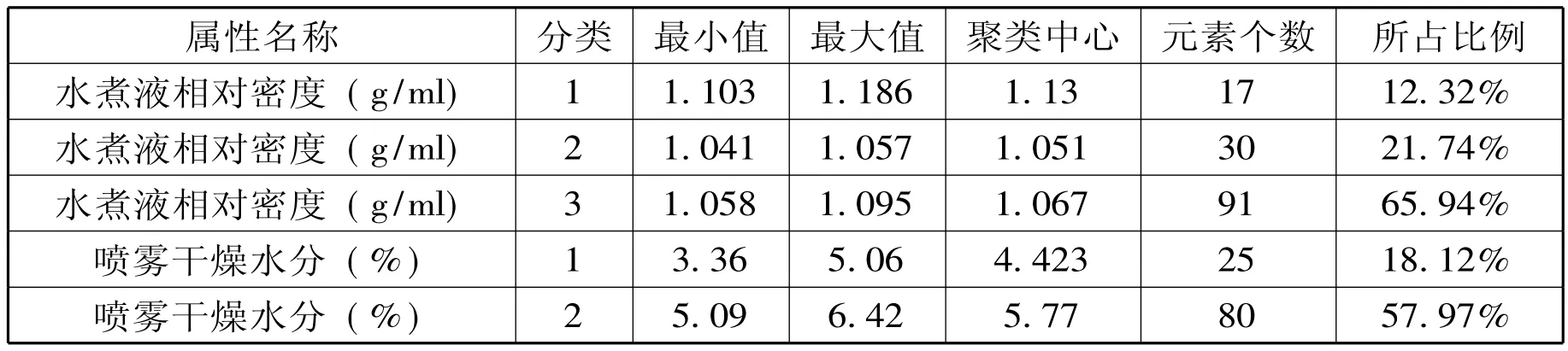
属性名称 分类 最小值 最大值 聚类中心 元素个数 所占比例水煮液相对密度 (g/ml)1 1.103 1.186 1.13 17 12.32%水煮液相对密度 (g/ml)2 1.041 1.057 1.051 30 21.74%水煮液相对密度 (g/ml)3 1.058 1.095 1.067 91 65.94%喷雾干燥水分 (%)1 3.36 5.06 4.423 25 18.12%喷雾干燥水分 (%)2 5.09 6.42 5.77 80 57.97%
上表以系统选择的最佳初始参数为初始参数,本文采用k-means聚类算法对七个质检指标进行聚类,得到聚类结果,用户根据这些结果来分析更符合生产工艺的质检要求,针对某区间参数数据量最多,可将此区间作为质检指标的参考值来分析数据。
3.FP-Growth算法在中药信息提取结果
3.1 整理数据
首先我们整理过程和结果数据,集成两个数据文件,使之成为一个数据集。本文整理的方式采用将同种批号数据每个属性取均值和方差代表该批数据的方式,各个属性的均值和方差与固含量数据结合起来。下面是部分结合数据表:
3.2 数据离散化
我们通过数据离散化对目前关联规则发现数据进行处理,本文采用用户自由拟定分组数目,对各个属性进行等宽度划分的方式对数据进行输入。
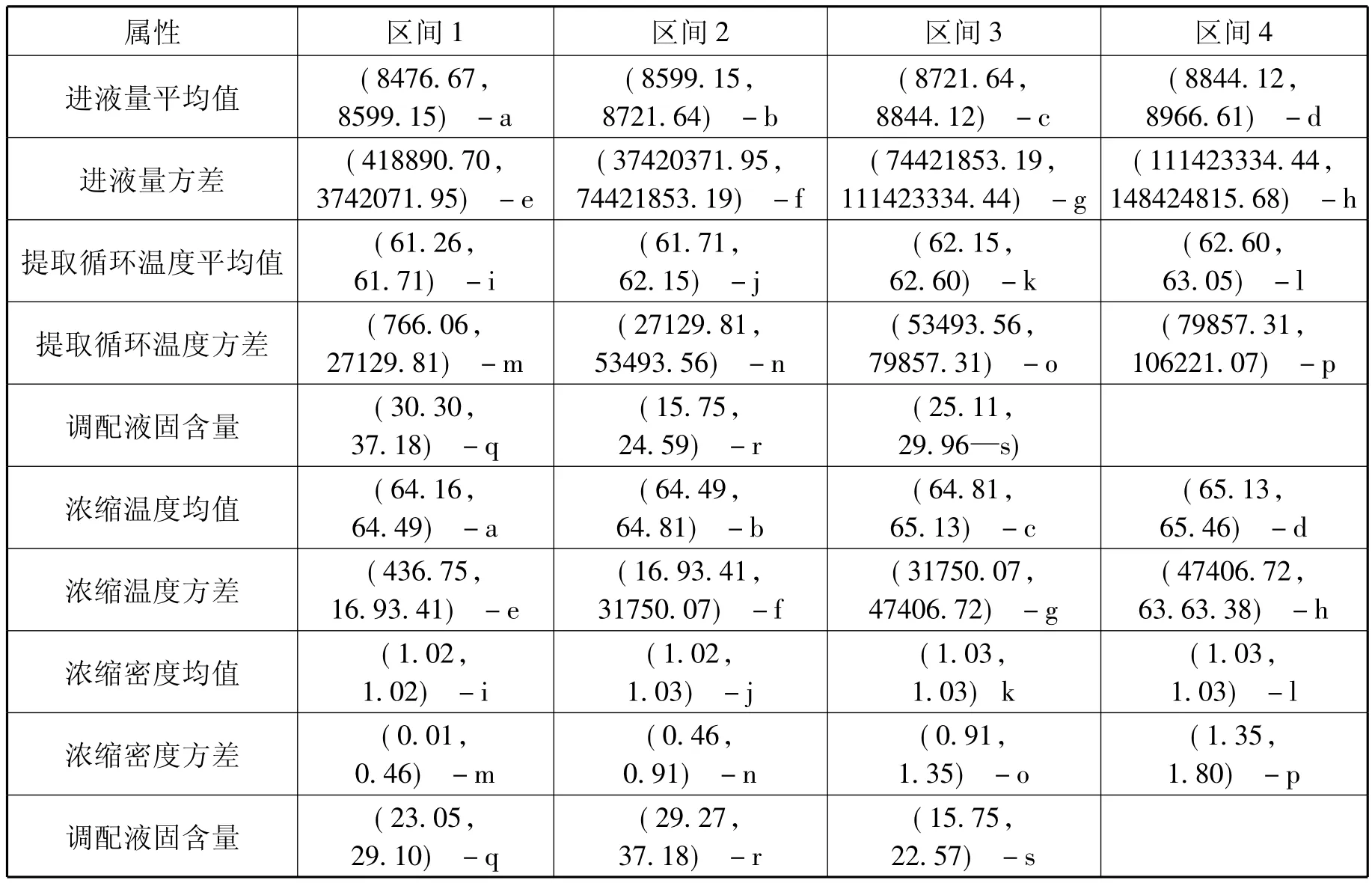
表3.1 离散化连续数据区间与符号对应关系
3.3 结果
本文根据改进的FP-Growth*算法,在离散化的数据表中发现在所有满足要求的频繁项集中得到最大频繁集。利用改进的FP-Growth*算法发现的最大频繁集中,在改进算法中无需生成频繁模式基和条件模式树,而是把事务的所有节点数据项直接存入到以HT表中各节点为头指针的相邻的单链表组中,不像FP_Tree树,需要在父子节点中有双向指针,节省了一半的指针域,减小的空间消耗,避免了内存压力,同时也仅需扫描事务数据库两次,且这种存储结构本身就直接蕴涵了全部频繁项目集,通过遍历操作,可以很容易的挖掘出所有的频繁项模式,挖掘效率有了显著的提高。使关联规则的时间减少,提高系统运行的速度。
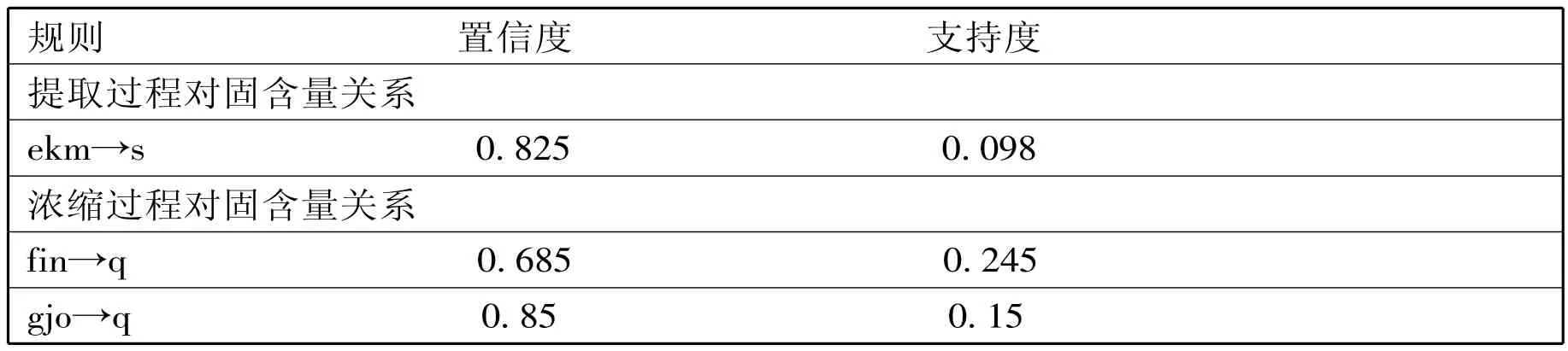
表3.2 关联规则结果
将符号对应实际属性区间得到下表:
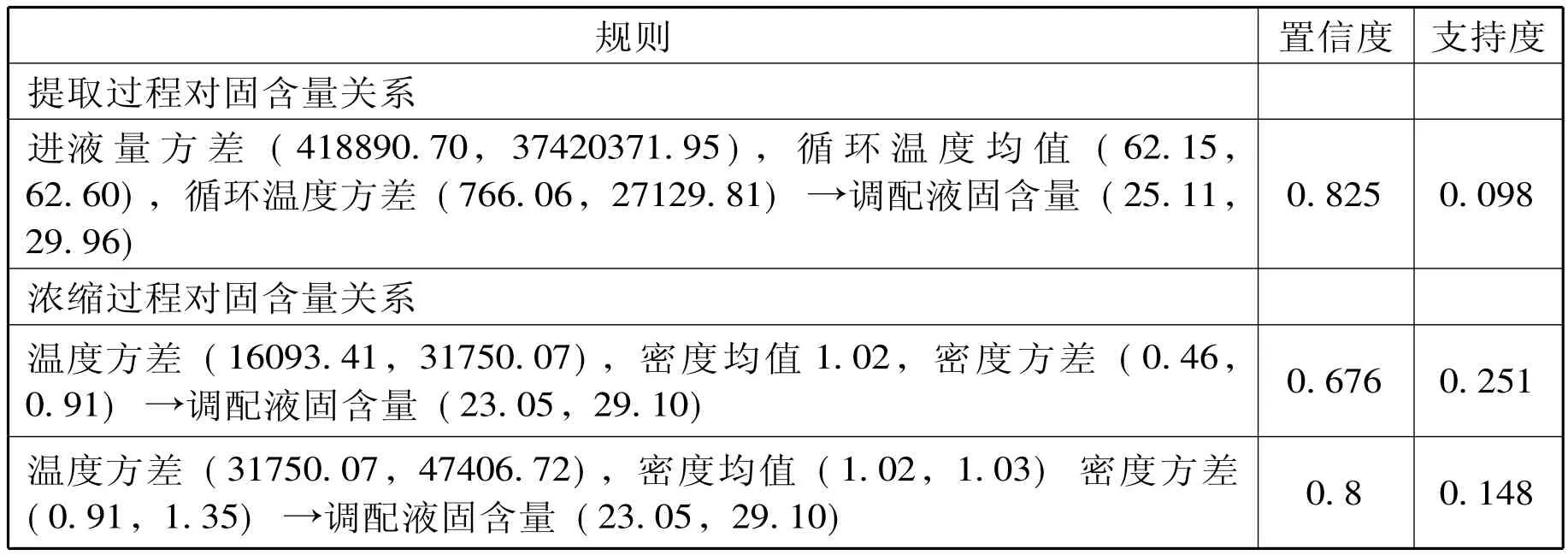
表3.3 联结果符号转化成实际属性结果
通过上表我们可以看出,比较提取过程与固含量的关系时,在生产的批次中进液量方差和循环温度方差均较小时,能够得到很好的固含量结果;比较浓缩过程对固含量关系,所有批次中浓缩液温度和方差适中的能够得到很好的固含量结果。
4.总结
本文回顾了关联规则挖掘知识,在分析FP-Growth关联算法的基础上提出改进算法,并用之于中药提取信息中数据挖掘,以求在中药生产过程中提取科学的数据,这仅是本人把数据挖掘在应用于中药提取信息挖掘的初步探索,希望能为为广大中药生产企业提供参考。
[1]Jiawei Han,Micheline Kamber著,范明,孟小峰 译.数据挖掘:概念与技术 (第二版)[M].北京:机械工业出版社,2007.
[2]张建辉,K-means聚类算法研究及应用 [D].武汉理工大学硕士论文,2007.
[3]朱明.数据挖掘 (第二版)[M].合肥:中国科技大学出版社,2008.
[4]Pang-Ning Tan,Michael Steinbach,Vipin Kumer著,范明,范宏建等译.数据挖掘导论 [M].北京:人民邮电出版社,2007.
[5]丛丹,王俊普等.基于FP-tree的模式分解算法 [J].计算机工程,2005,31(16):77—79.
[6]李云,蔡俊杰,刘宗田.基于量化规则格的关联规则渐进更新 [J].计算机应用研究,2007,24(5):27—30,34.
[7]谭建豪.数据挖掘技术 [M].北京:水利水电出版,2009.
Research of traditional Chinese medicine data mining based on improved FP-Growth algorithm
MA Jian;DONG Hui
(Department of Information Engineering,Bozhou Vocational and Technical College,Bozhou 236800,China)
Chinese medicine extraction plays a very important role in the production of traditional Chinese medicine.There are some problems in the process data and quality data from enterprises’Chinese medicine production.The emergence of data mining techniques and the use of k-means clustering algorithm and improved FP-Growth algorithm to analyze the data of traditional Chinese medicine production process,both improved enterprises productivity and reduced costs,and as well as ensure product quality.Therefore,data mining of Chinese medicine extraction is necessary and practical.
Data mining;association rules;Chinese medicine extraction;FP-Growth algorithm
TP391.1
A
1671-7406(2011)09-0017-07
2011-06-17
马 健 (1978—),男,安徽亳州人,主要研究方向:数据挖掘。
(责任编辑 刘洪基)
