SSAS聚类分析算法在顾客分组分析中的应用*
2011-11-07黄青松叶晓波
王 松 黄青松 叶晓波
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650093;2.楚雄师范学院计算机信息管理中心,云南 楚雄 675000)
SSAS聚类分析算法在顾客分组分析中的应用*
王 松1,2黄青松1叶晓波2
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650093;2.楚雄师范学院计算机信息管理中心,云南 楚雄 675000)
介绍一种利用数据挖掘技术建立顾客分类分析的挖掘模型。主要介绍了基于Microsoft SQL SERVER Analysis Services(SSAS)的聚类分析算法,以及SSAS聚类分析算法在对某销售信息进行顾客分组分析中的应用,通过分析聚类分析算法挖掘模型所发现的模式,得出了对顾客分类的结果,为销售公司管理层的营销决策提供有力的参考和辅助。
数据挖掘;SSAS聚类分析算法;顾客分组
1.引言
随着计算机应用技术的不断发展,销售信息管理系统在销售公司中得到广泛的应用。销售信息管理系统为各个销售公司的日常管理提高效率的同时积累了很多顾客的购买信息。那么,这些顾客的购买信息除了为商家的日常管理提供方便外,还能有什么用吗?促销酬宾活动是商家经常实施的提高销售利润的很好的方法。为了使商家在此类活动中有的放矢,针对潜在的顾客群来高效地完成促销活动,可以利用销售信息管理系统中顾客的历史购买信息来发现顾客的购买行为,从而确定最有可能购买商品的潜在顾客,为商家提供有利的决策支持。为了从这些海量数据中发现和获取对人们有价值的信息和知识,就需要通过新技术和强大的工具以智能的方式从这些庞大的数据信息中“挖掘”出有用的信息。从商业角度来看,数据挖掘是一种新的商业信息处理技术,其主要特点是对商业数据库中的大量业务数据进行抽取、转换、分析和其他模型化处理,从中提取辅助商业决策的关键性数据。随着数据挖掘技术的日益成熟和广泛应用以及数据挖掘软件市场需求量的不断增大,许多具有成熟技术和应用价值很高的数据挖掘软件工具应运而生。在众多的数据挖掘工具中,Microsoft SQL SERVER Analysis Services(SSAS)以其容易上手、快速、便捷等特点得到广泛应用。本文主要介绍数据挖掘中的聚类分析算法在顾客分组分析中的应用,用一个实际案例说明用SSAS聚类分析算法建立的顾客分组预测分析模型。
2.SSAS聚类分析算法
SSAS聚类分析算法是一种分割算法。将数据划分为组或分类,这些组或分类的项具有相似属性。该算法使用迭代技术将数据集中的事例分组为包含类似特征的分类。
SSAS聚类分析算法首先标识数据集中的关系并根据这些关系生成一系列分类。
在最初定义分类后,算法将通过计算确定分类表示点分组情况的适合程度,然后尝试重新定义这些分组以创建可以更好地表示数据的分类。该算法将循环执行此过程,直到它不能再通过重新定义分类来改进结果为止。
SSAS聚类分析算法提供两种创建分类并为分类分配数据点的方法。第一种方法是K-means算法,这是一种较难的聚类分析方法。这意味着一个数据点只能属于一个分类,并会为该分类中的每个数据点的成员身份计算一个概率。第二种方法是“期望值最大化”(EM)方法,这是“软聚类分析”方法。这意味着一个数据点总是属于多个分类,并会为每个数据点和分类的组合计算一个概率。
(1)EM聚类分析
在EM聚类分析中,此算法反复优化初始分类模型以适合数据,并确定数据点存在于某个分类中的概率。当概率模型适合于数据时,此算法终止这一过程。用于确定是否适合的函数是数据适合模型的对数可能性。
如果在此过程中生成空分类,或者一个或多个分类的成员身份低于给定的阈值,则具有低填充率的分类会以新数据点重设种子,并且EM算法重新运行。
EM聚类分析方法的结果是概率性的。这意味着每个数据点都属于所有分类,但数据点向分类的每次分配都有一个不同的概率。因为此方法允许分类重叠,所以所有分类中的项的总数可能超过定型集中的总项数。在挖掘模型结果中,指示支持的分数会相应地调整以说明这一情况。
EM算法可描述为:
①对参数向量作初始猜测:包括随机选择K个对象代表簇的均值或中心,以及猜测其他的参数。
②用下面两个步骤反复求精参数 (或簇):
Ⅰ.期望步:用以下概率将每个对象xi指派到簇Ck:
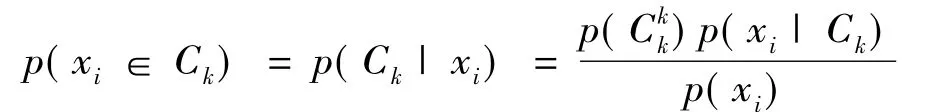
其中,p(xi|Ck)=N(mk,Ek(xi))服从均值为mk、期望为Ek的高斯分布。
Ⅱ.最大化步:利用前面得到的概率估计重新估计模型参数。例如:
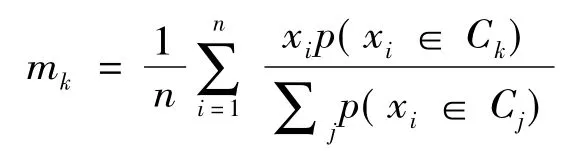
与k-means聚类分析算法相比,它有多个优点:①最多需要一次数据库扫描;②工作时不受内存(RAM)限制;③能够使用只进游标;④优于抽样方法。
(2)k-means聚类分析
k-means聚类分析是一种广为人知的方法,它通过尽量缩小一个分类中的项之间的差异,同时尽量拉大分类之间的距离,来分配分类成员身份。k-means中的“means”指的是分类的“中点”,它是任意选定的一个数据点,之后反复优化,直到真正代表该分类中的所有数据点的平均值。“k”指的是用于为聚类分析过程设种子的任意数目的点。k-means算法计算一个分类中的数据记录之间的欧几里得距离的平方,以及表示分类平均值的矢量,并在和达到最小值时在最后一组k分类上收敛。
k-means算法仅仅将每个数据点分配给一个分类,并且不允许成员身份存在不确定性。分类中的成员身份表示为与中点的距离。
通常,k-means算法用于创建连续属性的分类,在这种情况下,计算与平均值的距离非常简单。但是,SSAS实现通过使用概率针对分类离散属性对k-means方法进行改编。对于离散属性,数据点与特定分类的距离按如下公式计算:
1-P(数据点,分类)
k-means算法的步骤:
输入:K(期望簇的数目)、n个对象的数据集
输出:K个簇的集合
①任意选取数据集中的K个对象作为初始簇的中心
②对于所有n个对象,一一找其最近似的簇中心 (一般是以距离最近者相似度较高),然后将该对象分配到最近似的簇
③根据第②步的结果,重新计算各个簇的中心 (各个簇的平均值)
重复以上两个步骤,直到所设计的准则函数收敛为止 (一般是以没有任何对象变换所属簇为收敛条件),也就是平方误差准则,其定义如下:
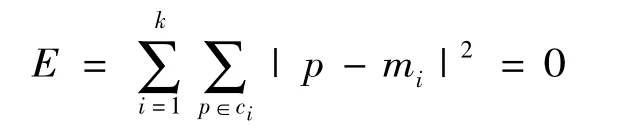
其中:mi是簇i的中心,p是簇i内的对象,ci代表簇i
3.实例分析
3.1 实例概述
本文以某销售公司的销售信息为数据依据,根据顾客的历史购买情况来详细了解该公司的顾客,然后使用这些历史数据进行可用于营销的预测。按照顾客历史信息中的“之前是否已购买”(顾客购买自行车的行为)这个属性和顾客的年龄、所在地区、随同居住的孩子数、拥有车数量、年收入、婚姻状况、上下班路程、拥有孩子数、是否有房等属性,将相似的顾客聚成簇,使得在一个簇中的顾客具有很高的相似性,而与其他簇中的顾客很不相似,从而发现未知的类别。所形成的每个簇可以当作一个类别,形成对每个类别的描述。本例采用的是k-means算法。
3.2 分析聚类分析算法挖掘模型所发现的模式
3.2.1 所生成的分类特征
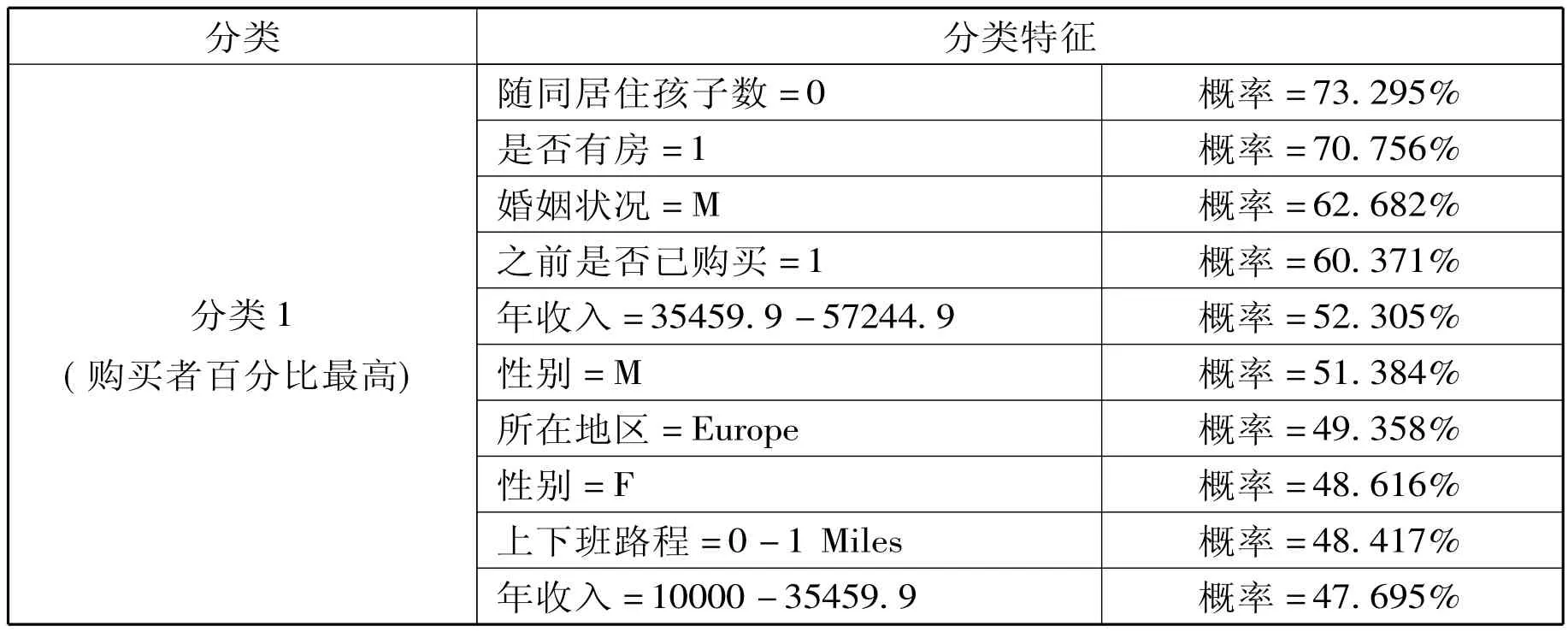
表1
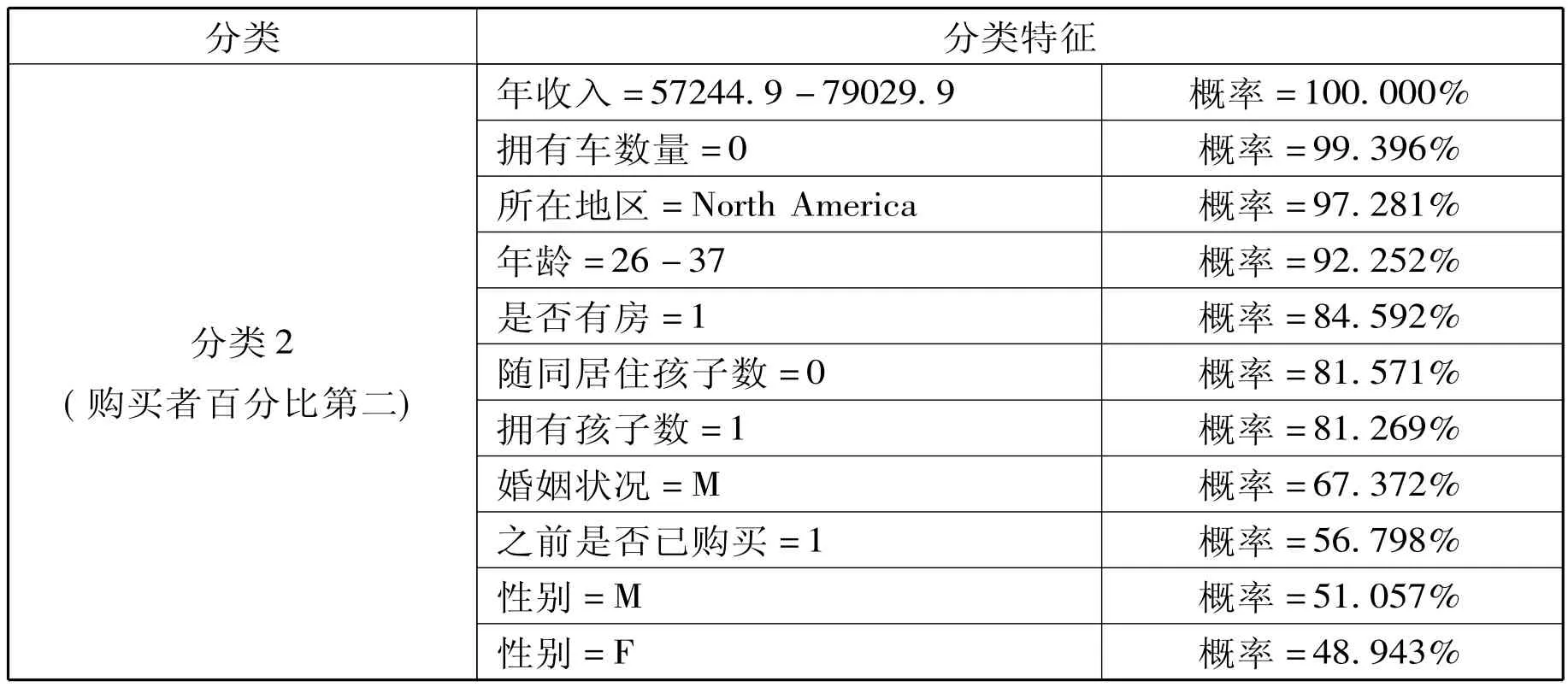
表2
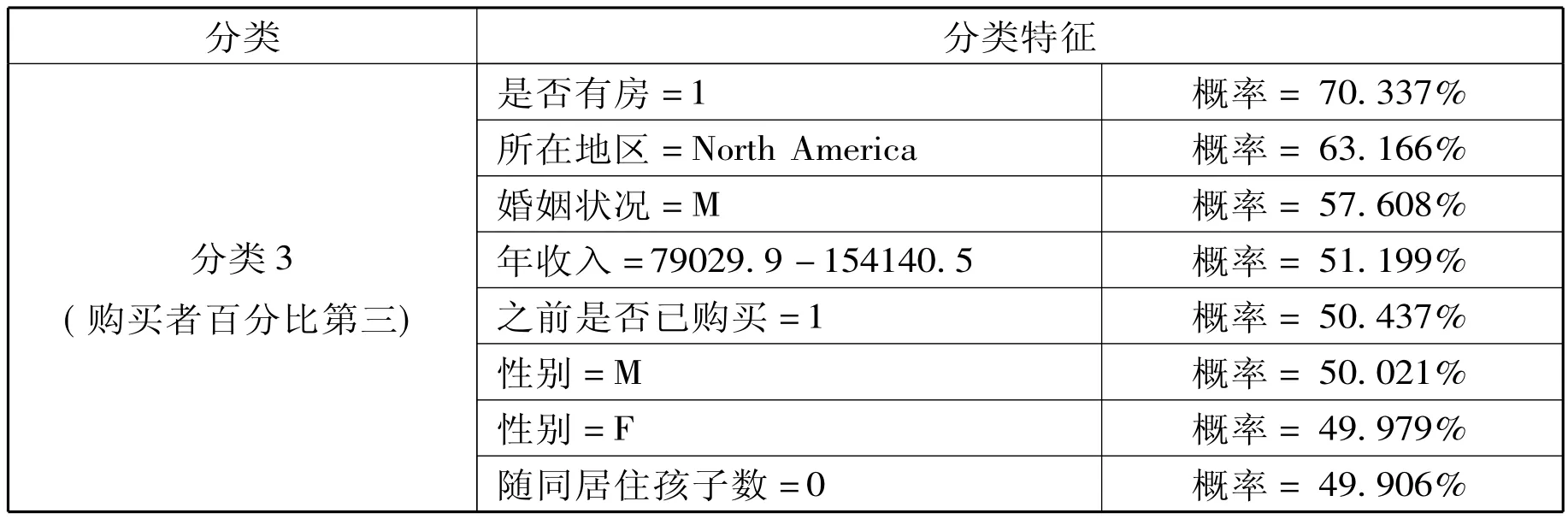
表3
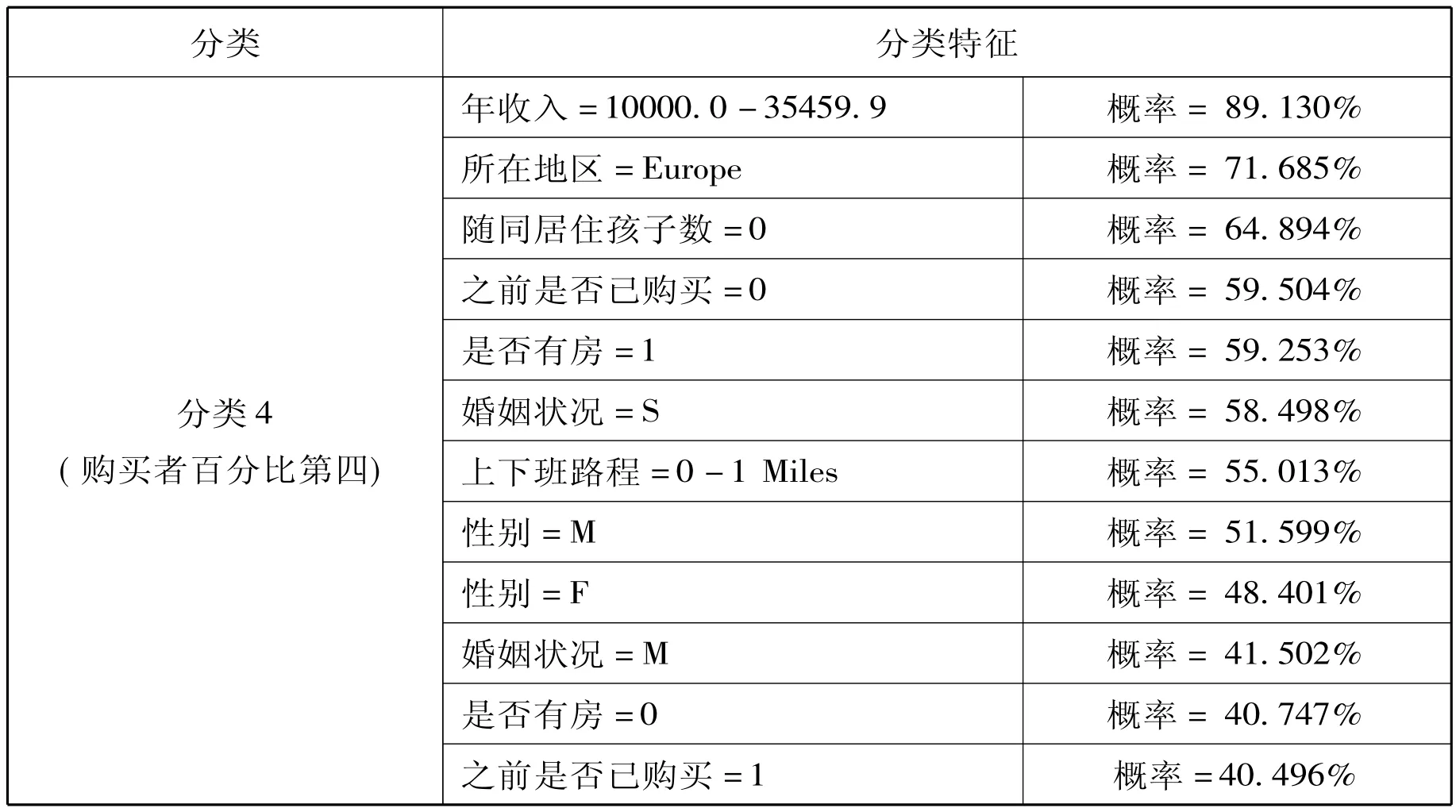
表4
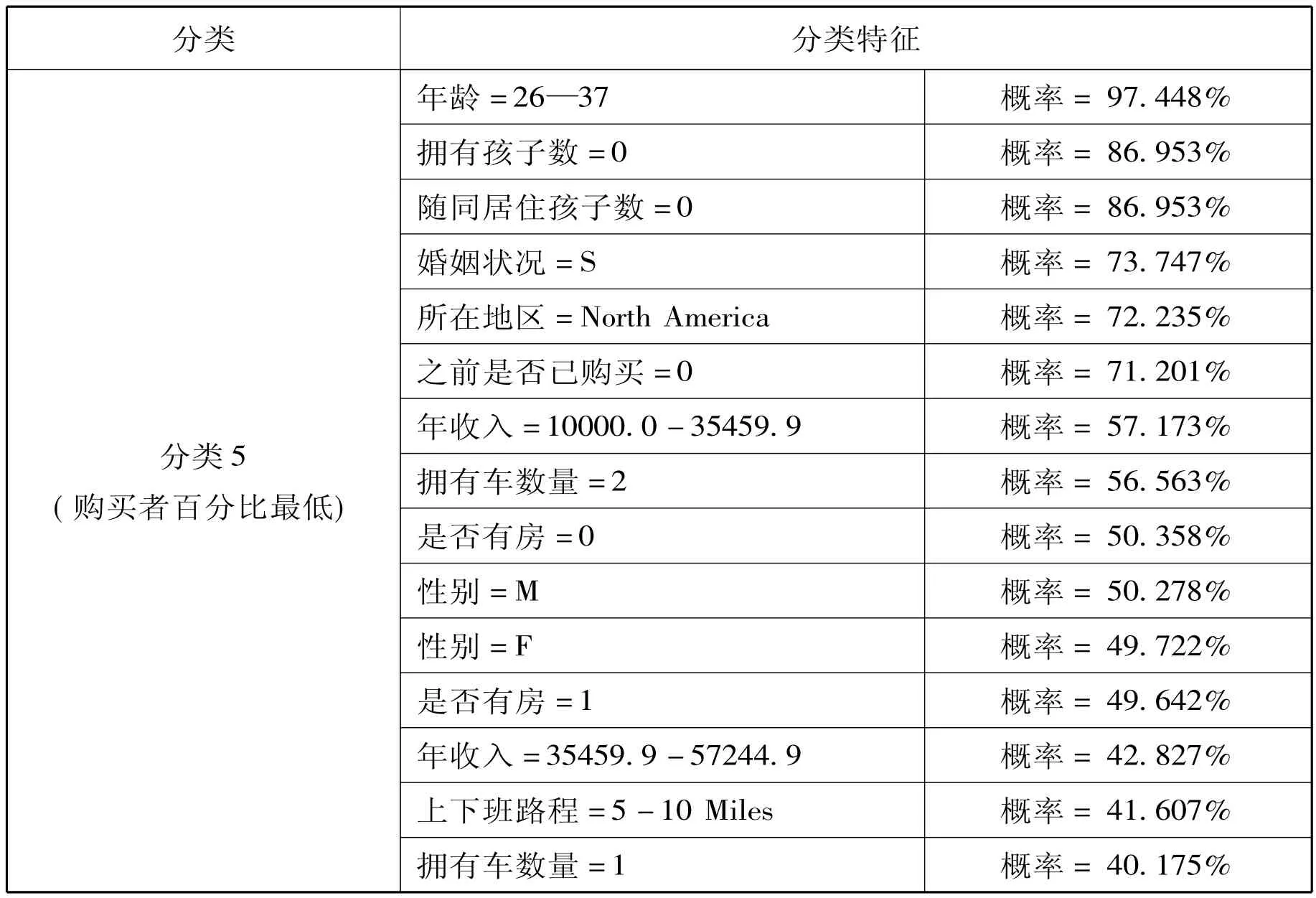
表5
3.2.2 聚类分析结果
通过对所生成的分类特征的分析,可对聚类结果作出如下的判断:
分类1(购买者百分比最高):性别分布很均匀,拥有一个孩子,没有车子,没有随同居住的孩子,上下班路程较短,有房的,已婚的,年龄较大,年收入在五类中居第二位。
分类2(购买者百分比第二):性别分布很均匀,拥有一个孩子,没有车子,没有随同居住的孩子,上下班路程较短,有房的,已婚的,较年青 (26—37),年收入在五类中居第三位。
分类3(购买者百分比第三):性别分布很均匀,没有孩子,拥有两辆车,没有随同居住的孩子,上下班路程较长,有房的,已婚的,年龄较大,年收入在五类中居首位。
分类4(购买者百分比第四):性别分布很均匀,没有孩子,拥有两辆车,没有随同居住的孩子,上下班路程较短,有房的,未婚的,年龄分布均匀,年收入在五类中居末位。
分类5(购买者百分比第五):性别分布很均匀,没有孩子,拥有两辆车,没有随同居住的孩子,上下班路程较长,有房的,未婚的,较年青,年收入在五类中居末位。
4.总结
通过上述对SSAS聚类分析算法的讨论,以及利用基于SSAS聚类分析算法建立的挖掘模型应用到一个具体实例,通过分析聚类分析算法挖掘模型所发现的模式,得出了对顾客分类的结果。这种对顾客特征描述的分类归纳能为销售公司管理层的营销决策提供有力的参考和辅助,对同一类型的顾客制定特定的营销管理策略,有针对性的提高管理顾客和提高销售量的效率。
[1] JIAWEIHAN MICHELINE KAMBER.Data Mining:Concepts and Techniques,2nd ed[M].China Machine Press,2006.
[2]郭丽.SQLServer2005构建数据挖掘解决方案 [J].计算机与现代化.2007(5):1.
[3](美)陈封能,(美)斯坦巴赫,(美)库玛尔著,范明等译.数据挖掘导论 (完整版)[M].北京:人民邮电出版社,2011.
[4]谢邦昌.商务智能与数据挖掘Microsoft SQL Server应用 [M].北京:机械工业出版社,2008.
[5](美)迈克伦南,(美)唐朝晖,(美)克里沃茨著,董艳,程文俊译.数据挖掘原理与应用 (第2版)—SQL Server 2008数据库[M].北京:清华大学出版社,2010.
Application of SSAS cluster parsing algorithm in customers partitioning analysis
WANG Song1.2;HUANG Qing-song1;YE Xiao-bo2
(1.School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650093,China;2.Computer Information Management Center,Chuxiong Normal University,Chuxiong 675000,China)
A model of customers partitioning analysis using data mining technology was described.This paper mainly recommends a cluster parsing algorithm based on Microsoft SQL SERVER Analysis Services(SSAS)and its application in customers partitioning of sales information.The results of customer partitioning obtained from the pattern excavated by analyze cluster parsing algorithm data mining model,and it provided sufficiently reference and supplement for management’s marketing decision-making of a sales company.
Data mining;SSAS cluster parsing algorithm;customers partitioning
TP391.1
A
1671-7406(2011)09-0011-06
2011-04-12
王 松 (1976—),男,云南楚雄人,昆明理工大学在读硕士,楚雄师范学院计算机信息管理中心实验师,主要研究方向:人工智能。
(责任编辑 刘洪基)
