一种基于GPU的主动声纳宽带信号处理实时系统*
2011-10-19李晓敏侯朝焕鄢社锋
李晓敏,侯朝焕,鄢社锋
(中国科学院声学研究所声学智能制导实验室,北京 100190)
传统意义上的GPU主要针对图形图像处理和游戏加速,其功能受到一定限制。NVIDIA公司于2007年发布了CUDA以及相应的GPU版本。这类GPU内核有很多流处理器,每个流处理器内包含相当多数量的并行执行单元,可以高效执行各种模型的大规模科学计算,因此受到学术界和产业界的追捧,被广泛应用于金融、石油、天文学、流体力学、信号处理、电磁仿真、模式识别、图像处理和视频压缩等众多领域[1-7]。然而,目前国内外将GPU通用计算应用到声纳信号处理的案例还很少。
声纳信号处理的手段主要分为两类。一类为以CPU为代表的处理平台,另一类为基于FPGA和DSP等大规模集成电路芯片的阵列信号处理平台。前者耗时严重,实时性差;后者虽然能够完成实时信号处理,但也具有开发周期长、板卡众多和成本高等众多缺点。
基于以上因素,本文采用基于CUDA编程架构的GPU,实现了LFM及CW信号的几种经典波束形成和匹配滤波过程,该系统具有实时性、开发周期短、性价比高和使用灵活等众多优点。
1 基于CUDA的GPU通用编程
CUDA是一种将GPU作为数据并行计算设备的软硬件体系,采用了比较容易掌握的类C语言进行开发。它是一个SIMD(Single Instruction Multiple Data)系统,即一个程序编译一次以后,CUDA将计算任务映射为大量的可以并行执行的线程,并由拥有大量内核的硬件动态调度和执行这些线程,从而显著提高运算速度。如图1所示,将一个可以并行化执行的任务首先分配给若干个线程网格(Grid),其次将每个Grid内的任务分配给若干个线程块(Block),最后再将每个Block内的任务细分给若干个线程(Thread)。Grid中的所有Blocks并行执行,Block中的所有Threads并行执行,这种两层并行模型是 CUDA 最重要的创新之一[8-9]。
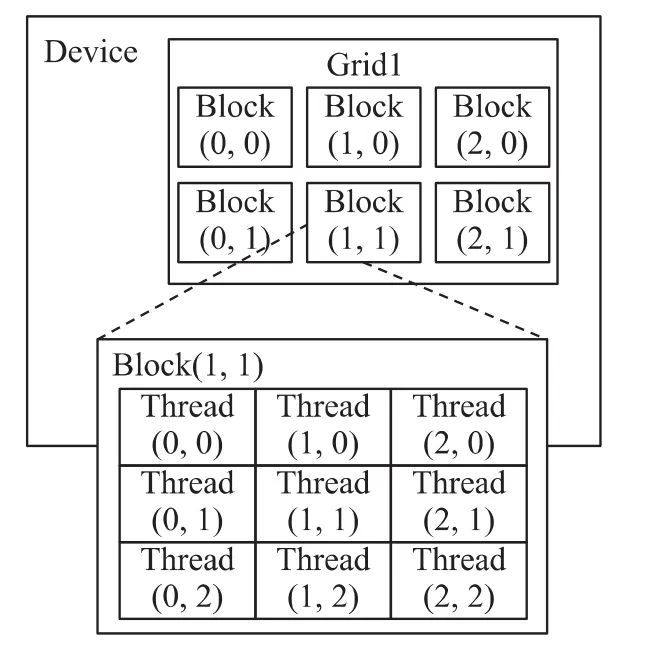
图1 GPU内线程结构
2 主动声纳宽带信号处理的GPU实现
图2是一个简单的主动声纳信号处理过程框图。

图2 主动声纳信号处理基本框图
接收基阵接收到M路回波信号,通过波束形成实现DOA估计,并将波束汇聚后送入匹配处理器,最终得到目标距离和速度。
2.1 经典窄带波束形成的实现
2.1.1 自适应 MVDR 波束形成器[10-11]
MVDR波束形成器的加权向量为

其中,as(θ)为θ方向上的导向向量。
方位谱为
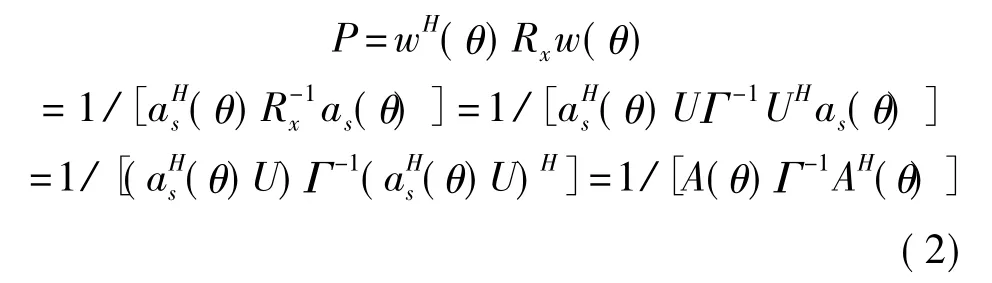
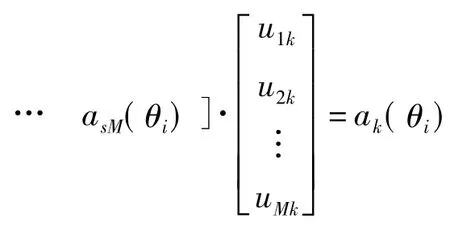
其中,对Rx进行特征分解为Rx=UΓUH,M为基阵阵元数
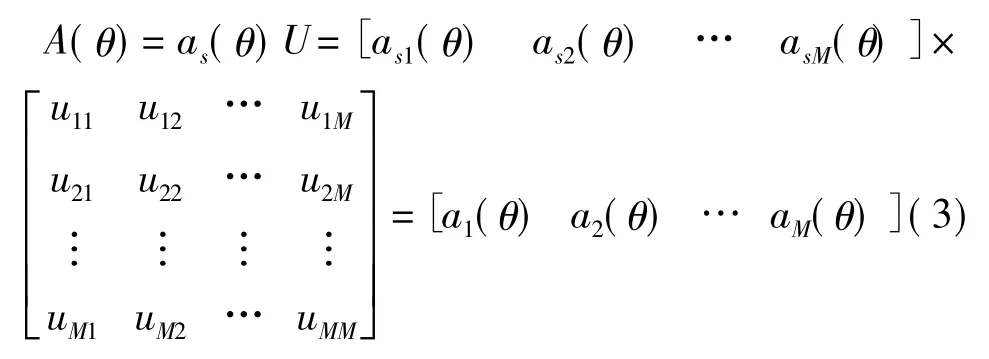
图3为在GPU上实现MVDR波束形成器的任务分配图。其中,s为扫描角度数目,一般取扫描范围为[0:1:180]°,则s=181。

图3 MVDR波束形成器GPU内部kernel任务分配图
2.1.2 LSMI波束形成器[10-11]
LSMI波束形成器的加权向量为
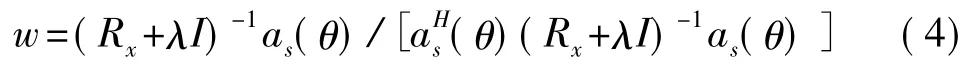
其中λ为对角加载量,经验值为10。
方位谱为
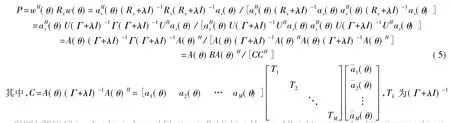
的第k个元素;B为对角阵,Bk为B的第k个元素。图4为在GPU上实现LSMI波束形成器的任务分配图。
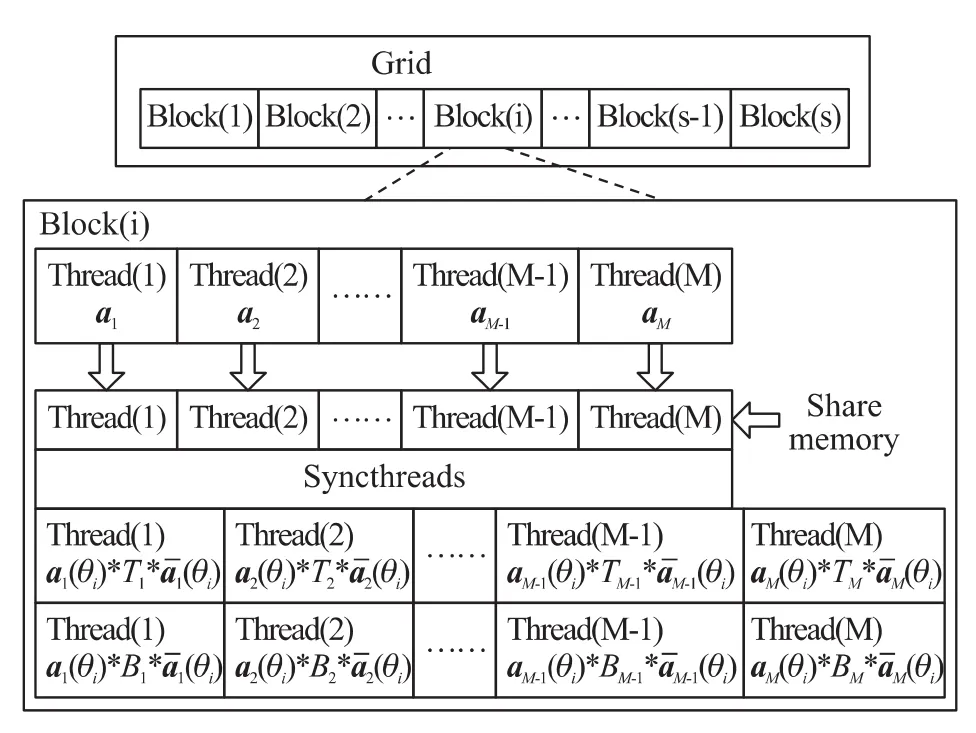
图4 LSMI波束形成器GPU内部kernel任务分配图

2.1.3 RCB 波束形成器[10-11]
RCB波束形成器的加权向量为
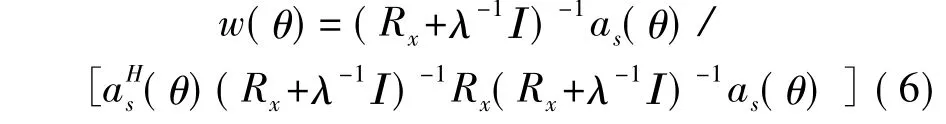
方位谱为

其中,B为对角阵,λλk为B的第k个元素。令ε0为一个趋近于0的正小数,则λ可通过(8)求解
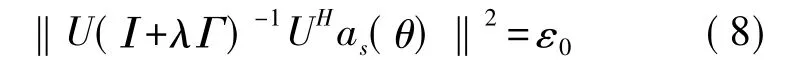
图5为在GPU上实现RCB波束形成器的任务分配图。
对于RCB波束形成器,仍然使用s个Blocks,每个Block内包含M个并行处理Threads。

图5 RCB波束形成器GPU内部kernel任务分配图

2.2 宽带波束形成的实现
宽带波束形成器的实现包括频域FFT实现和时域FIR实现两种方式。本文采用频域FFT实现方法,首先使用离散傅里叶变换将阵列数据分解为若干频带上的子窄带,然后针对每个子带进行[0:1:180]°扫描窄带波束形成,最后将各子带方位谱累加从而估计出目标方位[11],实现流程如图6所示。
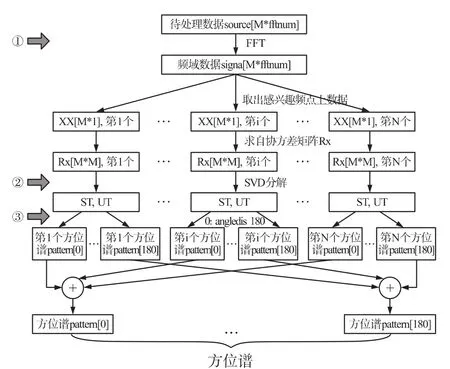
图6 宽带波束形成算法实现流程图
其中,M为阵元数,fftnum为采样数据长度,ST为分解后的特征值,UT为分解后的特征向量,angledis为波束扫描间隔角度。在宽带波束形成器的实现过程中,只需要针对每个子窄带使用2.1节介绍的过程即可。
2.3 匹配处理的实现
匹配滤波常用来检测淹没在加性高斯白噪声中的信号,它是一种使输出峰值信噪比最大的最优滤波技术。在主动声纳系统中,匹配滤波接收输出波束的时间序列,并将处理后的结果直接作为检测器的输入,与门限进行比较,进而判定目标是否存在[12]。
由于匹配滤波器对频移信号没有适应性,因此需要产生发射信号的多种频率版本,以匹配由多普勒频移造成的接收信号频率与发射信号频率不一致,这个过程通常被称为拷贝相关。图7展示了采用匹配滤波的过程。

图7 匹配滤波示意图
上图中,每个阴影区域即代表某频移点上的拷贝相关。考虑到信号点数length(length=快拍数snapnum*FFT点数 fftnum)远大于 GPU内每个Block拥有的最大线程数512,无法将每个阴影区的执行单独分配给1个Block。因此,将各个阴影区域之间串行执行,而每个阴影区域内部并行执行。并行任务分配给snapnum个Blocks,每个Block内有fftnum个Threads,所有的Threads均完成一次点乘。
3 实验结果
3.1 硬件平台

表1 硬件平台
3.2 系统输入输出界面
本文采用诺基亚公司开发的跨平台C++图形用户界面应用程序框架Qt实现系统输入输出界面,图8所示为系统主界面。
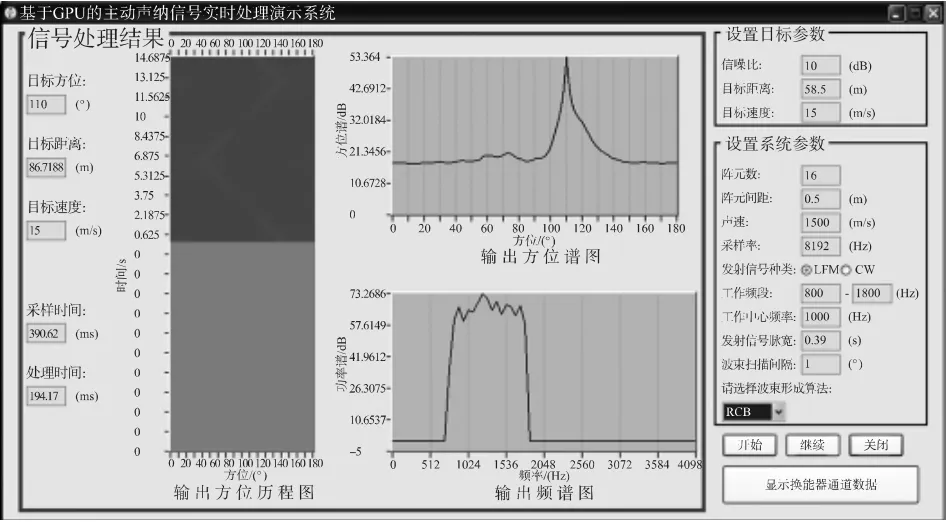
图8 系统主界面
右侧蓝色方框内为目标参数输入区和系统参数输入区,左侧紫色方框内为信号处理结果显示区。
假设目标在[40~140]°之间以5°间隔来回运动,设置完成各项参数后,点击“开始”按钮,输出方位谱图将会显示每个时刻的方位谱,输出方位历程图将会记录下所有时刻目标的方位情况,并一帧一帧刷新。点击方位历程图上任意一点,将会在输出频谱图上显示相应时间和方位上的输出信号频谱。
同时,每个时刻目标方位、目标距离和目标速度都以文字形式显示在主界面最左侧。由于该系统具备实时性,处理时间始终小于采样时间。
点击主界面上“显示换能器通道数据”按钮将弹出一个新界面,如图9所示。通过下拉框选择想查看的通道,点击“确定”按钮,该界面将与主界面同步显示当前时刻某换能器通道输入信号波形及其频谱。
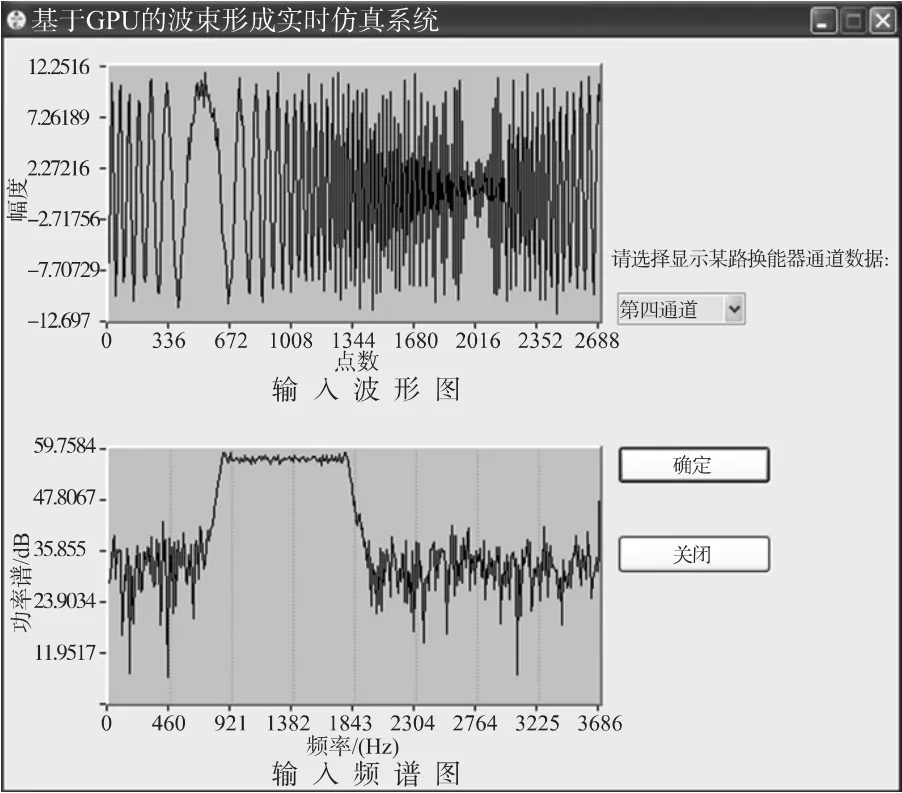
图9 显示换能器通道数据界面
3.3 运行时间及加速比
在图8中所示参数的基础上,增大阵元数为32,增大子带数为21,减小扫描间隔为1°,从而增大扫描角度次数。表2展示了Matlab、CPU和GPU三种平台在此参数条件下采用不同的算法执行处理过程的时间以及加速比。
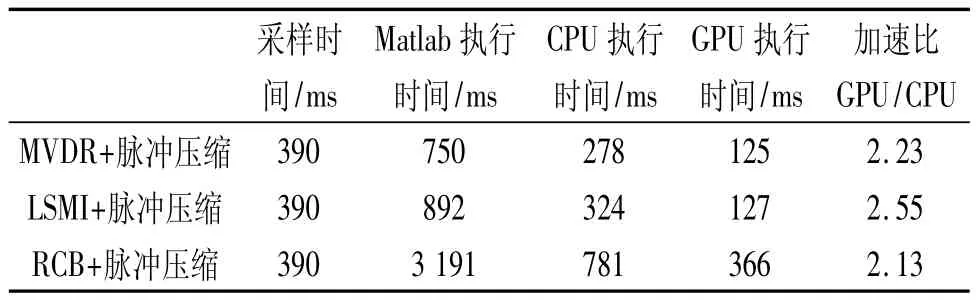
表2 各种平台执行时间及加速比
表2中所示的4种处理算法,从上到下运算量依次增大。从表2可以看出,处理同样的数据,GPU相比于CPU要快两倍多。当数据量增大到一定程度时,Matlab和CPU已经无法在采样一帧数据的时间内完成对上一帧数据的处理,而GPU却仍然可以满足处理的实时性。
在不考虑实时性的前提下,继续增大运算量,上面四个表格中的加速比会越来越大,GPU的加速优势会越来越明显。图10和图11分别展示了在表2所示参数基础上,CPU和GPU这两种平台执行“LSMI+匹配处理”的时间随着阵元数和子带数增加的变化趋势。
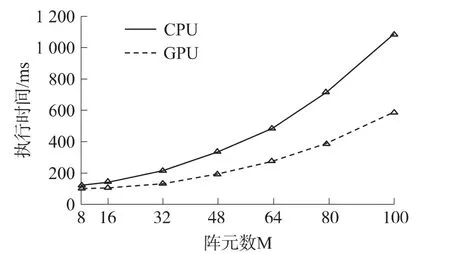
图10 各平台执行时间随阵元数M的变化
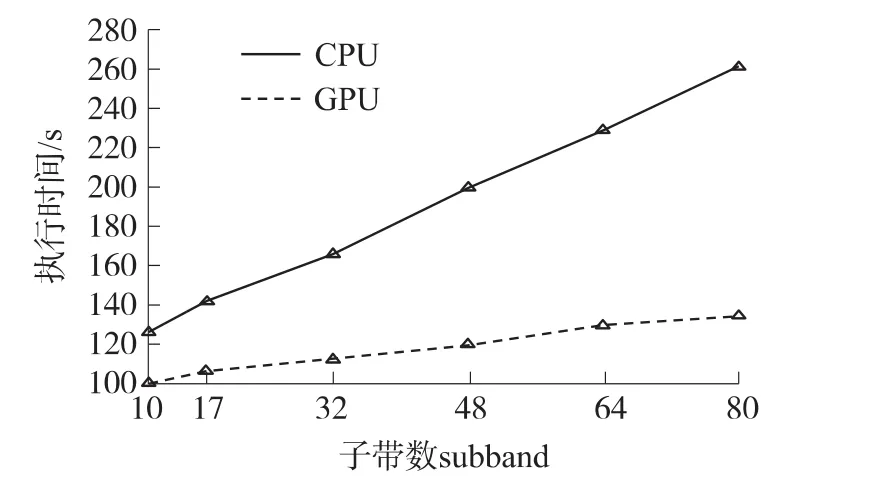
图11 个平台执行时间随子带数subband的变化
可以看出,当数据量增大时,GPU相较于CPU的执行速度优势更加明显,这正应证了GPU处理大数据量的优良性能。
4 结论
本文设计了一种主动声纳信号处理系统,采用具有众多并行内核的GPU实现其实时性。该系统相较于CPU有约一个数量级的加速,相较于同样处理速度的DSP平台,则体现了开发周期短、成本低和操作简单等优点。随着声纳信号处理数据量的日益增大,将GPU强大的通用计算能力应用到声纳领域的各个环节,是一个值得继续深入研究的课题。
[1]杜歆,颜瑞,刘加海.监控摄像机视频去隔行和CUDA加速[J].传感技术学报,2010,23(3):393-398.
[2]赵欣,李凤霞,战守义,等.基于粒子系统实现船舶航迹仿真的加速方法[J].大连海事大学学报,2008,34(1):54-57.
[3]程广斌,马承华,郝立巍.基于图形处理器加速的医学图像分割算法研究[J].医疗卫生装备,2008,29(2):6-8.
[4]李蔚清,吴慧中.一种基于GPU的雷达探测区域快速可视化方法[J].系统仿真学报,2008,(20):323-327.
[5]Balz T,Stilla U.Hybrid GPU-Based Single-and Double-Bounce SAR Simulation[J].IEEE Transactions on Geoscience and Remote Sensing,2009,47(10):3519-3529.
[6]柳彬,王开志,刘兴钊,等.利用CUDA实现的基于GPU的SAR成像算法[J].信息技术,2009,11:62-67.
[7]Yubo Tao,Hai Lin,Hujun Bao.GPU-Based Shooting and Bouncing Ray Method for Fast RCS Prediction[J].IEEE Transactions on Antennas and Propagation,2010,58(2):494-502.
[8]Garland M,Le Grand S,Nickolls J,et al.Parallel Computing Experiences with CUDA[J].Micro,IEEE,2008,28(4):13-27.
[9]张舒,诸艳丽,赵开勇,等.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009:1-100.
[10]朱埜.主动声纳检测信息原理[M].北京:海洋出版社,1990:32-50.
[11]鄢社锋,马远良.传感器阵列波束优化设计及应用[M].北京:科学出版社,2009:48-93.
[12]丰平.基于VPX规范的新型阵列信号处理机系统设计[D].北京:中科院,2010:18-19.
