汉语-维吾尔语机器翻译解码器研究
2011-10-15张亚军
张亚军
(昌吉学院计算机工程系 新疆 昌吉 831100)
1 引言
随着现代计算机科学技术的快速发展,人类渴望利用机器翻译而达到突破语言障碍的愿望已经初步实现了。在机器翻译的发展过程中,由于语料库的研究的兴起,尤其是对双语语料库(或称平行语料库)的研究,使得基于短语的统计机器翻译(statistical machine translation以下简称SMT)[1][2][3]得到越来越多专家的重视和研究。SMT以平行语料库(parallel corpora)为主要知识源,基于统计的方法来实现机器翻译过程。当输入待翻译的句子S后,主要处理顺序如下:对S分词,切分短语,短语对齐(即在平行语料库搜索相应语料),进行比较、适当取舍、调整排序,选取与S最接近的目标句子T。
快速准确地构建基于短语统计的汉语—维吾尔语机器翻译系统是目前领域内研究的主要方向,其中汉维解码器的研究工作已经成为构建机器翻译系统解决的首要问题。统计机器翻译最初采用的是基于词的逐词翻译方法[4],该方法对多个词语之间上下文关系反映较差。后来研究基于短语的方法,该方法将源句子切分为多个短语并进行短语间的相互翻译。本文主要研究汉维解码器的算法设计。
2 特征选取
信源信道模型是统计机器翻译研究中最初采用的主要模型之一,它是一种生成模型。语言模型和翻译模型的好坏对模型翻译质量的高低具有决定性的作用。经过不断地改进发展,逐渐演变为对数线性模型。对数线性模型与信源信道模型不同之处在于:对数线性模型属于判别模型,它比信道信源模型更具有一般性,信源信道模型可以作为对数线性模型的一个特例。在对数线性模型方法中,特征模型可以方便的加载到模型中来。
假设u、c是机器翻译的目标语言和源语言句子,h1(u,c), …, hM(u,c)分别是u和c上的M个特征,λ1, …,λM是与这些特征分别对应的M个参数(特征权重因子),那么直接翻译概率可以用以下公式模拟:
P(u|c)≈Pλ1…λm(u|c)
其中假设Z(c)是一个标准常量, 此时翻译过程转换如下:
翻译译文由解码算法通过搜索具有各个特征模型的最大加权评分值的目标语言句子而最终得出。性能较高的解码算法将得到翻译速度和质量都比较高的目标语言句子。
2.1 维吾尔语模型
目标语言模型主要用来评价翻译译文的质量。本文加入张亚军等人研究的基于N-gram的维吾尔n-gram语言模型(N=3)[5],则
2.2 扭曲模型
在对源语言句子进行短语翻译时,涉及到短语翻译的位置重排问题,在此选用扭曲模型考虑短语重排的代价(即扭曲度,用d表示)。
di表示翻译过程中源语言句子短语的位置扭曲幅度。di 的大小为翻译时第i个源短语的第一词语的位置与i-1个源短语最后一个词语位置的差值加1。
2.3 词语补偿(惩罚)模型
词语惩罚模型主要是为了防止目标语言T的句子过长(短语数I限制在10≤I≤20),而对短的目标语言T所进行的补偿。词语惩罚模型可表示如下:
Pr(u)=exp(I) I代表目标语言的句子长度。
3 解码器算法的设计
在该汉维解码器的解码设计过程中,采用柱式搜索算法进行搜索,柱式搜索算法属于动态规划的一种算法。该算法主要策略是在有限的全局空间内有效进行搜索,使得解码速度在精度上都取得一个折中方案。
3.1 核心算法
柱搜索(Beam Search)算法思想:在一个搜索过程中尽可能的扩展出所有的翻译选项,直到翻译完成为止。柱搜索的思想实质上是动态规划思想的一种应用。这种翻译状态称作假设,每一个翻译结果即代表一种假设。表1中列出假设包含的主要信息说明。
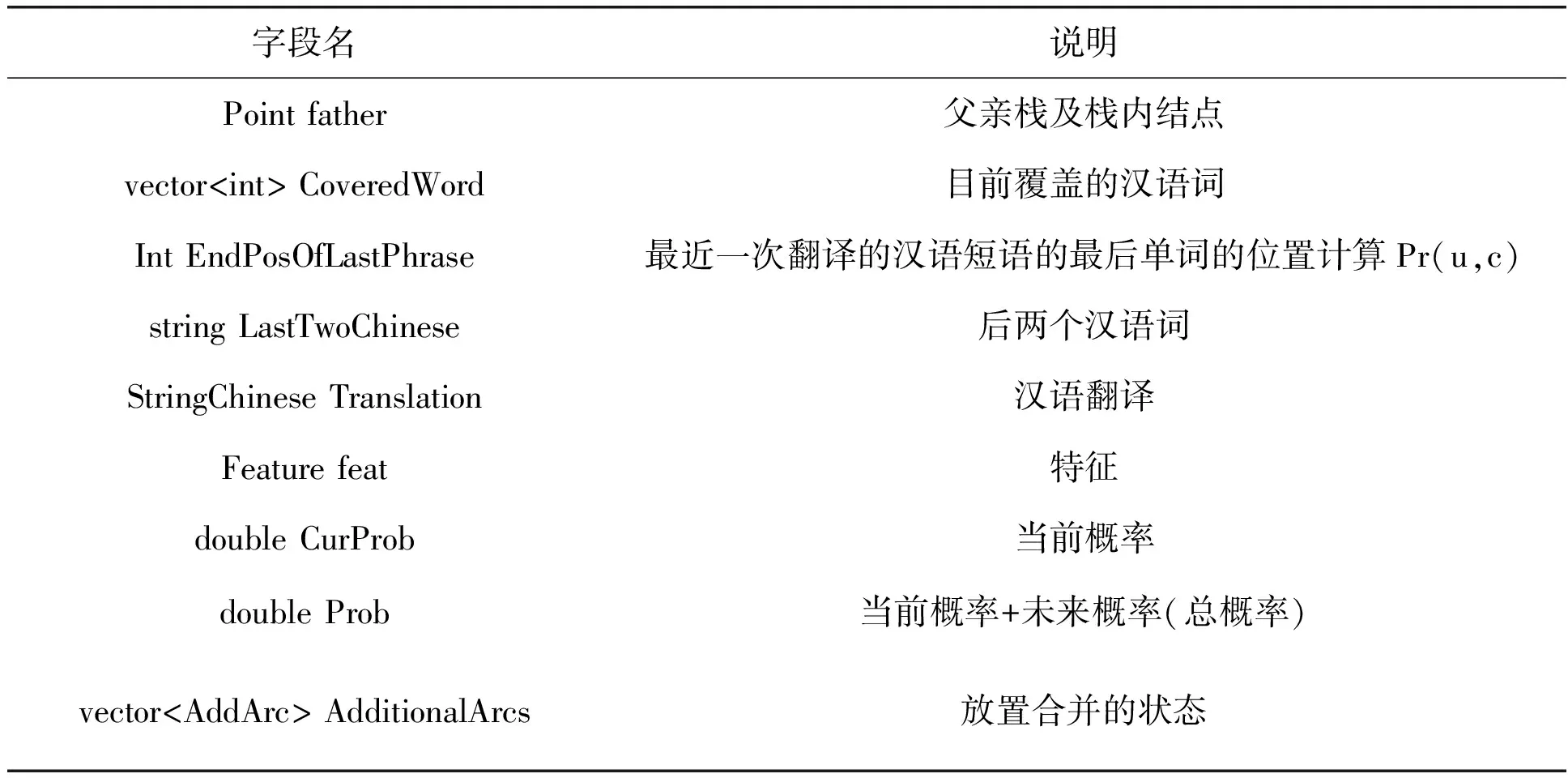
表1 翻译假设包含的主要信息说明
将需要翻译的汉语短语序列设置到相应的栈中,生成新的假设。翻译相同汉语短语个数存放到相应的假设站中。随后对假设栈依次扩展,到汉语短语翻译完成位置结束。对汉语句子中短语数为K的解码算法描述如下:
(1)对汉语句子S进行分析;
(2)翻译备选项列表的构建;
(3)未来评分表;
(4)初始化假设栈HpStack;
(5)生成初始假设加入到假设栈HpStack [0]中;
(6)遍历搜索假设栈HpStack[i](0≤i≤k-1,以下i相同),遍历假设栈中所有的Hp;
(7)在Hp中搜索(2)中构建的表,扩展一次即可生成一个NewHp;
(8)计算Prob值,newHp翻译的汉语短语依次加入到栈HpStack中;
(9)从HpStack[K]中的分值最高的假设作为出发点,依次回退,直至结束,即可得到一条路径,路径上的所有点组合得到一个译文。
在(1)中首先从译模型搜索出汉语句子的所有可能的翻译短语对,目的是为了避免在进行假设扩展的后的重复搜索。
(8)中计算假设的Prob值,要计算假设当前的各个加权值,另外还需要加上通过搜索(3)生成的未来评分表估计的假设未来评分[6],这样总概率就能很方便的反映出假设的质量如何。
3.2 构建翻译备选项列表
扩展次数是由翻译备选项列表的数目决定的(数目越多,次数越多)。因此减少假设扩展的次数提高翻译速度可以对翻译备选列表进行裁减。对翻译备选项列表的大小进行限制以及通过对翻译选项评分阀值的设定,即可达到对评分值较差的翻译备选项进行裁减的目的。
记录短语互译信息表是通过翻译备选项列表实现的,此表主要包括维吾尔/汉语短语、翻译评分值、维吾尔短语的N-gram模型评分值信息。备选项表的构建,不只需要收集到翻译模型中维吾尔语/汉语言句子或者短语之间对应的互译信息,而且要计算它们的模型评分值。
另外,在解码的过程中对栈中状态进行剪枝,搜索过程中栈中状态的个数是固定的(见表2),选择评分较好的状态进行下一步扩展,评分效果不理想的节点,作为评分效果较好节点的一个分支,并入该节点下。这种方法通常称为剪枝策略,优点就是可以降低节点数,同时有没有删除评分效果的不理想的节点,尽可能的保留原始信息。
4 试验结果
实验使用新疆大学多语种实验室提供的20000句对的汉维双语语料库为基础。以维吾尔语为目标语言训练3-gram的维吾尔语语言模型和汉维短语翻译模型。选用200句长度为10到20个词语的汉语句子作为测试输入数据的对比实验。

表2 试验结果对比
由表2可以看出,在固定栈设定为200时,解码处理速度比较慢且错误率比较大。固定栈设置的越大,则解码处理速度加快,并且解码算法的错误率也在随之下降。但并不是固定栈设置越多越好,随着栈的继续增加,搜索算法将会占用大量的时间,处理整体效果没有明显加强,并且对计算机的硬件性能要求较高。
5 总结
汉维解码器的研究是汉维机器翻译研究的关键。在汉维翻译解码过程将遇到庞大的搜索空间,评价汉维解码器的重要指标之一就是如何快速解码。本文讲述搜索解码算法设计与实现了汉维解码算法的实验。下一步主要研究汉维解码算法的全局优化问题,使得算法在效率上得以提升。
参考文献:
[1]OCH F J,NEY H.Discriminative training and maximum entropy models for statistical machine translation[C].Proceedings of the40th Annual Meeting of the Association for Computational Lingu istics(ACL).Philadelphia,PA:[s.n],2002:295—302.
[2]http://www.iccs.inf.ed.ac.uk/~pkoehn/publications/phrase2003.pdf.
[3] Wang Ye-yi,Warble.Decoding algorithm in statistical machine translation [C].Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics,Madrid,Spain,1997.
[4] 聂进. 一个基于JAVA的堆栈式自然语言翻译解码器[J]. 计算机工程与应用,2005,(4):105-108.
[5] 张亚军,吐尔根·依布拉音.汉语—维吾尔语句子级对齐系统分析及其实现[J].中国科技纵横,2010,(6).
[6] KOEHN P.Pharaoh:A beam search decoder for phrase—based statistical machine translation models[C].Proceedings of the Association of Machine Translation in the Americas(AMTA-2004).
