P2P网络中基于本体驱动的网格资源发现的研究
2011-10-10李艳鹏钟军凯
李艳鹏 钟军凯 魏 慧
济宁职业技术学院 山东济宁 272037
P2P网络中基于本体驱动的网格资源发现的研究
李艳鹏 钟军凯 魏 慧
济宁职业技术学院 山东济宁 272037
提出了一种新的语义网格资源发现方法。P2P网络用来分发和查找资源目录,每个点能够提供资源描述和背景知识,能够查找网络中存在的资源信息。每个点都有自己的本体,该本体由网络上知识传播来完成,因此不需要一个中心本体来描述和匹配资源,具有很好的扩展性。
网格;资源管理;语义;本体;查找;分配
语义网格的目的是把语义本体和逻辑描述应用到网格中间设备中去。把本体应用到资源匹配中去,要求资源提供者和请求者必须具有相同的背景知识,且资源代理程序必须具有访问本体域的权利。
资源代理程序访问本体域需要相应的结构与之对应。笔者采用了基于本体的P2P网络查找网格资源,该网络利用传统语义知识来处理分布式网格中的资源请求,并利用P2P网络传播概念知识。除了具有一般P2P网络的分散化、易扩展、耐攻击、高容错及隐私性能好的优点外,该网络还具有智能性,因为把本体引入到网格中,使资源之间能够相互理解,从而能够根据用户的需求有效、动态、智能地聚合各种资源来满足用户的需要。
1 资源匹配算法
1.1 模型
文中采用的资源发现模型如图1所示。

图1 资源发现模型
该模型分为上下两层,上层是P2P层,由多个PS服务组成,每个PS服务对应一个虚拟组织(VO),主要实现2个方面的功能:跨VO的资源发现和覆盖网络。下层是网格层,由多个VO组成,实现的功能有:资源聚合、VO内的资源发现、建立在PKI基础上的身份认证和授权机制。
当用户有查询请求时,先向本地VO提出请求,本地VO根据用户请求在本地的索引服务中查找,若找到匹配的资源则对资源进行分配和预约。否则,由本地VO中作业应用代理把请求提交到P2P层对应的节点,在此节点保存着邻居节点的资源信息。在P2P层进行跨不同VO的资源查找,并把最终的结果返回到请求资源的应用代理处,根据情况做进一步处理。
1.2 模型中存在的问题及解决方法
上述模型需要解决如下两个方面的问题:
(1)不知道哪个节点有资源匹配请求。
(2)节点可能自己也不知道是否具有匹配的资源,因为它们缺少本体域中信息的重要部分。
我们构造了一个能够解决上述问题的P2P网络(如图2所示)。在该网络中,所有节点的概念和信息都将在网络中进行传播。PS和CS服务的功能和前面模型中的功能一致,我们主要对VO内的节点进行设置。第一个节点的IP地址为192.168.0.45,根据处理器厂家的不同进行分类(如图3所示);第二个节点根据字节长度进行分类(如图4所示);第三个节点根据AMD子类对CPU进行分类(如图5所示)。第一个节点包括一个资源且处理器的类型是赛扬ID8,这说明图3中IP地址为192.168.0.45[8]的赛扬框中资源ID8是这个概念的一个事例(其中ID指标识符)。
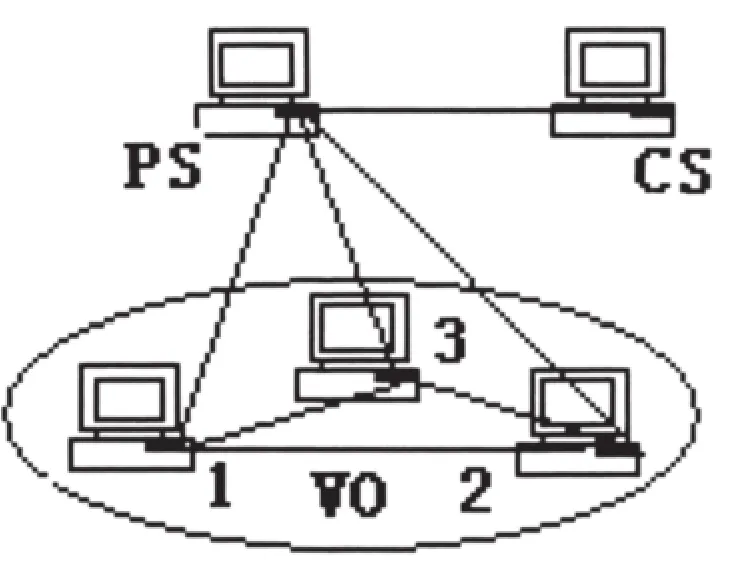
图2 P2P网络

图3 根据厂家对CPU进行分类

图4 根据单词长度对CPU进行分类

图5 根据AMD子类对CPU进行分类
通过网络来传播当地DAGS类型,具体的结果如图6所示,网络也传送有关资源消息。在192.168.0.45[8]显示的CELERON,INTEL,32位和PROC框都说明IP地址为192.168.0.45节点ID8是这些概念的一个事例。
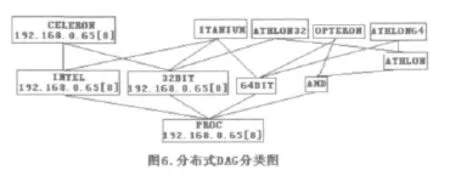
假设查询需要32位的处理器。尽管节点1有一个匹配的资源,由于它不知道自己的处理器是32位的,所以并不能满足自己的需要。通过查找网络,使用虚拟类DAG发现IP地址为192.168.0.45中的资源8能满足需要。
1.3 消息传播
消息传播是指在点到点网络中传播事例检查、T-Box和A-Box。DHT算法能够实现概念在网络中传播。对每一个概念来说,T-Box和A-Box都要被存储。T-Box是子概念目录,这些目录能够在网络中进行传播,形成虚拟的DAG。A-Box包含每个点的资源列表,这些资源是符合该概念的事例(把它叫做事例列表)。对每个资源来说,节点的IP地址和资源在节点上具有的ID都将被存储,具体表示为“IP1[Resources of IP1],IP2[Resources of IP2],...,IPn[Resources of IPn]”,这个列表越大所包括的资源就越多。
把事例列表存储在哈希表中,通过IP地址进行检索,以矢量形式存储资源ID。因此,要对每个节点的资源进行线性编号。采用这种数据结构,事例列表能够根据所需内存和所要求操作进行有效的存储。
1.4 网络中节点的加入和离开
从两个角度来分析节点的加入和离开:网格层和P2P层。其中网格层主要指VO内部节点的变化,P2P层主要是PS服务节点的变化。PS服务节点的变化由CS服务实现,当有新的PS节点加入时首先向CS注册,同时获得几个其他PS的GSH,这些PS成为其邻居节点,在网络中找到该位置完成加入;离开时要向已注册的CS发消息,使CS去掉该节点的地址信息。VO内部节点的变化可以通过服务数据的通知机制来实现,基本原理可参照文献[4,5]。
1.5 概念查询
概念查询分为简单概念查询和复杂概念查询两种。简单概念查询中最主要的问题是怎样找到请求者所需求的概念事例节点。首先,要看决定节点简单概念定义的主要因素。其次,使用基本函数功能(一般指并、交和差)来提供查询的定义。根据概念名称在哈希表中的值来选择查询所需要的节点,找到的节点具有该概念的事例。
复杂概念查询是在简单概念并、交和差的基础上根据概念定义形成的。在网络中连续访问复杂概念定义中包含的每个简单概念,并在此基础上从底向上构造复杂概念的事例列表。当概念进行联合或交操作时,可以对每个概念进行或和与操作。复杂概念查询中逻辑非的处理有两种不同的方式:如果非和与一起出现,例如A∩¬B,事例列表就可以被删除;如果非单独出现或和逻辑或一起连用,例如A∪¬B,B就将从Resource的事例列表中删除,因为Resource事例列表已包括了所有节点有关B的列表。非操作无效,无论资源的类型是什么,Resource事例列表中都会包括该资源的事例。根据复杂概念事例列表和上述规则可以实现复杂概念查询。
2 实验结果
通过模拟几种网络情况,得出了该方法的执行图,解决了下面的问题:
(1)一个查找请求需要多长时间才能找到满足需要的资源?
(2)新消息公布的过程中网络能传播多少信息?
模拟产生了一个随机的分类DAG,该图能够在节点中传播,因此每个节点都拥有DAG的子图和该图的一些事例。根据这种情况,通过改变节点个数、DAG大小和事例个数,模拟了网络中信息的传播情况,计算出不同大小的DAG下,随着节点个数的增加消息的迭代次数和消息传送量。在保持每个固定节点事例个数不变情况下,增加了总的事例个数,如图7和8所示。X轴表示节点的个数,它由相应事例的个数决定,Y轴分别表示的是迭代次数和消息传送量,需要注意的是节点个数不是线性变化的。每种情况运行10次,为了避免随机产生DAG所带来的特殊影响,图中的值是10次运行的平均值,因此迭代次数和消息传送量可能不是整数。

图7 迭代次数
图7说明迭代次数随节点个数的增加变化不明显,由于实验中事例是随机传送的,所以当节点个数增加时,要重新计算迭代次数。迭代次数随着概念个数的增加,变化也不明显。从图中可以看出,552个概念下,计算迭代次数的平均值大约为9.3,而50733概念下迭代次数的平均值大约为15.3。把迭代次数为1.6所对应的节点个数和节点个数为90两种情况进行比较发现,当概念以DAG形式组织时,仅当最长路径和迭代次数相关时,结果才很明显。
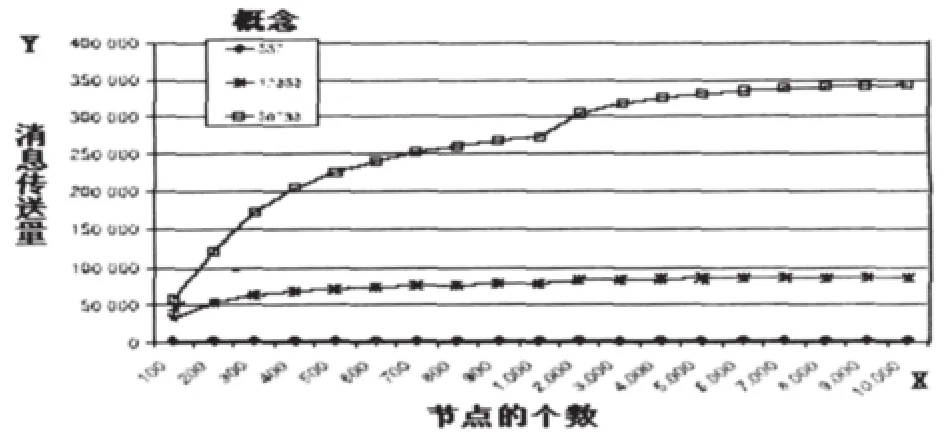
图8 消息量
图8表明消息传送量的增长和节点个数的增加很协调。从图中可以看出,552个概念时,随着节点个数的增加,消息传送量的变化很小;50733个概念时,消息传送量随节点个数的变化就很明显,而且基本上是成比例的,这说明概念个数越多,消息传送量的增长和节点个数的增加越协调。
3 结束语
本文提出一种动态网格环境中资源查找方法,通过本体来描述资源,在分布式哈希表的基础上实现节点之间信息传播。如果资源提供者不在网格范围内,可以结合可传输的DAG图内所有节点的知识来实现资源查找。通过模拟获得了网络传播新信息时系统的行为和当概念个数发生变化时系统数值的变化范围。但该方法的使用范围还受到以下因素的限制:完备性、查找的表示、容错情况、垃圾的收集和传递的优化,所以将进一步改进使它不再受这些条件的限制。
[1]A. Vidal, and S. Kofuji, “Semantics-Based Grid resource Management”[C]. In Procedings of5th International Workshop on Middleware for Grid Computing-MGC’07, Newport Beach, CA, USA, Nov26, 2007
[2]P. Wieder, W.Ziegler, “Bringing Knowledge to Midleware –Grid Scheduling Ontology”[C]. In Proceedings of the Workshop on Future Generation Grids, Nov. 1-5,2004, Dagstuhl, Germany, Springer, 2006:47~59
[3]Borja Sotomayor.The Globus Toolkit 4 Programmer’s Tutorial[EB/OL].http://www.casa-sotomayor.net/gt4- tutorial-wo-rking/, 2005
[4]Domenico Talia, Paolo Trunfio.Web Services for Peer-to-Peer Resource Discovery on the Grid[C].DEIS,University of Calabria’s, Rende, Italy
[5]Professional Open Source Middleware for Parallel,Distributed, Multithreaded Programming[EB/OL].http://proactive.inr- ia.fr
[6]孙帅,董小社,杨凡,等.基于三层P2P结构的网格资源发现模型[J].微电子学与计算机,2005,8:127~129
Abstract: We present a new approach to semantic resource discovery in the grid in this paper. A peer-to-peer network is used to distribute and query the resource catalogue. Each peer can provide resource descriptions and background knowledge, and each peer can query the network for existing resources. We do not require a central ontology for resource description and matching. Each peer may have its own ontology, which will be completed by the knowledge distributed over the network. And it can be argued that this network has excellent scalability.
Key words: grid; resource management; semantic; ontology; query; location
Research for grid resource discovery in P2P network based on ontology-driven
Li Yanpeng, Zhong Junkai, Wei Hui
Jining vocational technology college, Jining, 272037, China
2010-08-16
李艳鹏,硕士,助教。钟军凯,硕士,助教。魏慧,本科,助教。
