数据挖掘在提高学生成绩中的应用
2011-09-25杨阳李明东西华师范大学计算机应用研究所四川南充637002
杨阳,李明东(西华师范大学计算机应用研究所,四川南充637002)
数据挖掘在提高学生成绩中的应用
杨阳,李明东
(西华师范大学计算机应用研究所,四川南充637002)
该文针对部分大学生对低年级课程不够重视这一现象,采用数据挖掘中的关联规则算法找出大学课程之间的内在联系,而后建立成绩预警模型,对相关的学生提出警告并指明努力的方向,从而能尽早使学生对相关的课程引起足够的重视.
数据挖掘;关联规则;课程成绩;解决方法
1 引言
大多数学生经过高中三年的学习,进入大学之后不能很快适应大学的学习环境,对自己的学习采取放任的态度,认为高中阶段太辛苦,应轻松了,即使不用那么刻苦也能考出好成绩,这种想法是完全错误的.随着大学课程难度的不断加大,有些学生因为前驱课程没有学好,从而加大了学好后继课程的难度.不管是教学管理部门还是学生自己都应该明确的知道大学课程中哪些课程之间是有联系,联系的紧密程度如何.从而对学生提出警告,使之加强基础课程与主业课程的学习.
2 数据挖掘与关联规则
2.1 数据挖掘的基本理论
近年来,随着科学技术的发展,社会与经济都取得了很大的进步,信息技术在各行各业都得到了广泛的应用,同时,各个领域也产生了大量的数据.如何从这些数据中得到有用的信息,成为分析人员的密切关注的问题.因此,数据挖掘技术得到了广泛的应用.
数据挖掘(Data Mining,简称DM),就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含的在数据中、人们事先不知道却是潜在的有用信息和知识的过程,是数据库中的知识发现的核心[1].图1是一个挖掘系统的原型[2].
2.2 关联规则的基本理论
支持度(Support)用于度量一个项集的出现频率.项集{A,B}的支持度由同时包含A和B的事务总个数组成.计算支持度的公式为[1]:Support({A,B})=Number of Transactions(A,B).
置信度(Probability)是关联规则的属性.规则A =>B的概率就是使用{A}的支持度除项集{A,B}的支持度来计算.计算置信度的公式为:Probability (A=>B)=Support(A,B)/Support(A).
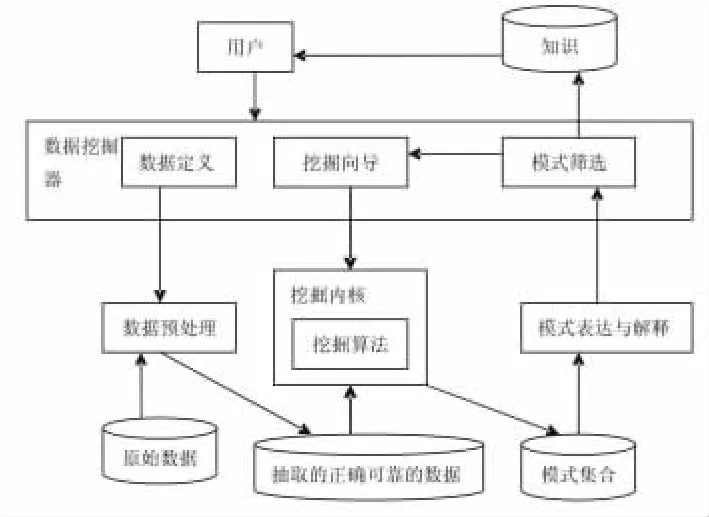
图1 挖掘系统的原型
2.3 Apriori算法
关联规则算法就是相关性计数引擎.在关联算法中有两个步骤,首先挖掘频繁项集,再基于频繁项集来生成关联规则[3].
挖掘频繁项集是使用关联规则算法的核心部分.首先必须使用最小支持度来指定频率阈值.该算法在第一次迭代中挖掘所有大小为1的频繁项集,其支持度大于最小支持度.第二次迭代挖掘大小为2的频繁项集,在进行第二次迭代之前该算法会基于第一次迭代的结果来生成一组大小为2的候选项集,同样的,这些项集的支持度不得小于最小支持度.该算法重复相同的过程来挖掘大小分别为3、4、5……的频繁项集,直到再没有项集满足最小支持度为止.以下是用来生成频繁项集重要过程的形式代码[3]:
F:result set of all frequent itemsets

3 关联规则用于提高学生成绩
近年来,由于高等教育的不断普及与发展,各个高校扩招,学生也不断增加,这就给高校的管理工作带来了很大的困难.教师需要科学的分析包括学生成绩在内的各个教学环节中的大量数据信息,才能很好的指导教学.并且能够使学生在了解课程联系的前提下,很好的学习这些课程.
3.1 模型的描述与建立
这个模型的作用是通过对现有的课程成绩的分析,找出课程间的关联规则以及联系的紧密程度.当输入某个学生的成绩时,能根据这些关联规则判断该生应该注意哪些后续课程的学习,并指明学习的方向[4].
模型的建立过程如下: A:课程A的成绩.B:课程B的成绩.Support(A,B)=包含A,B的项集个数/项集总个数.
若Support(A,B)>最小支持度,则项集(A,B)为频繁项集.
反之则不是频繁项集.
若项集(A,B)为频繁项集,则挖掘项集(A,B)的关联规则.
Probability(A=>B)=Support(A,B)/Support(A).
若Probability(A=>B)>最小置信度,则A,B之间存在联系.
C:某人课程C的成绩.
输入C,可预测此人与C相关的课程的成绩,从而提醒此人应该注意哪些后续课程的学习,以及可能会导致的后果.
图2为学生课程成绩关联规则模型图:

图2 学生课程成绩关联规则模型图
3.2 模型的求解
(1)数据的预处理.随机抽取本校计算机学院某个班一学期的成绩,首先对这些数据进行预处理,然后把数据经过数据库的导入及选择连接,将数据转化为规格化的形式,将其转化为事务数据库的存储形式,最后将成绩进行转化并将其离散化.[5]课程成绩按照成绩区间设置如下:60分以下的设置为“1”,60到70分的设置为“2”,70到80分的设置为“3”,80分以上的设置为“4”.
(2)挖掘关联规则.本文主要是想通过分析成绩从而得到课程之间的内在联系.通过数据挖掘找出各个课程之间的关系从而发现有联系课程.本文将利用关联规则中的Apriori算法来解决该问题.设置最小支持度为0.3,最小置信度为0.3.开始对数据进行分析.现选取部分实验结果进行解释说明.[4].

表1 学生的成绩示意图
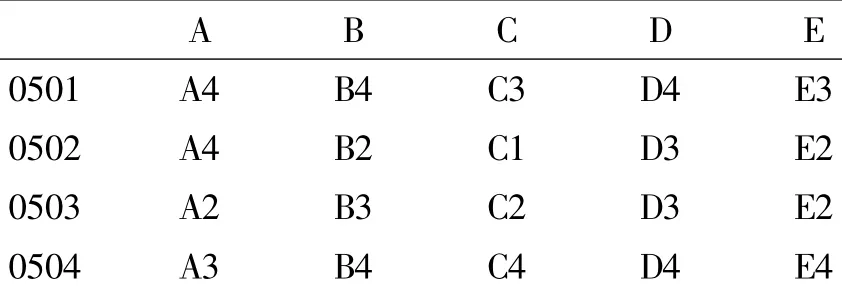
表2 预处理1后的成绩图

表3 预处理2后的成绩表

表4 生成频繁项集

表5 生成关联则
上述分析可知,B、D课程与K课程之间有着非常紧密的联系,如果B、D课程没有学好,将会导致后续K课程难以学好.课程G与课程H,课程F、C与课程E之间也存在联系.
4 解决方法
通过上面的数据分析可以知道:大学中的绝大多数课程之间是存在联系的,特别是前驱课程与后继课程之间的联系是非常紧密的,一旦前驱课程没有学好将会直接影响到后继课程的学习.既然我们已经知道了课程之间的联系就应该很好地利用起来.对于有相关问题的学生,老师应及时与学生进行交流,鼓励学生重拾学习的信心,把没有学好的前驱课程重新学习一遍,为后继课程的学习打下坚实的基础,同时老师从旁给予一定的帮助,以此达到提高学生成绩的目的.
5 结论
本文针对当今的部分大学生对大学中的低年级课程不够重视这一现象,简要地阐述了关联规则的Apriori算法,并用这一算法建立了成绩预警模型.这个模型通过分析数据库中大部分学生的成绩,得出课程之间的关联规则,然后输入某学生的当前成绩,可知他目前的学习状况,由此提醒该生应该注意哪些后续课程的学习.并在此基础上提出解决学生相关问题的方法,以达到提高学生成绩的目的.
[1]ZhaoHui Tang,Jame Maclennan.数据挖掘原理与应用[M].北京:清华大学出版社,2007.
[2]李雄飞,李军.数据挖掘与知识发现[M].北京:高等教育出版社,2003.
[3]胡吉明,鲜学丰.挖掘关联规则中Apriori算法的研究与改进[J].计算机技术与发展,2006(4).
[4]李军.数据挖掘系统实现的一般模型[J].大庆石油学院学报,2003(3).
[5]李瑞欣,张水平.数据仓库建设中的数据预处理[J].计算机系统应用,2002(5).
(责任编辑:王前)
Abstract:Some students not pay enough attention to the low-grade curriculum,in view to this phenomenon,the paper used association rules algorithm in datamining to find the inner relation between university courses,and then established achievements early warningmodel to warn the relevant students and indicate the direction,thus early enabled the students cause enough attention to the related curriculum.
Key words:datamining;association rule;course grade;solution
Applied Research of Data M ining in Im proving Students'Grades
YANG Yang,LIMing-dong
(Institute of Computer Application,China West Normal University,Nanchong,Sichuan 637002,China)
TP391
A
1008-7974(2011)04-0022-03
2010-10-20
杨阳(1986-),女,四川遂宁人,西华师范大学计算机应用研究所在读硕士研究生.李明东(1958-),男,四川广安人,教授,硕士研究生导师.
