基于本体的局部文档分析查询扩展方法研究
2011-09-23周剑烽
周剑烽
中国人民银行杭州中心支行,浙江杭州 310001
基于本体的局部文档分析查询扩展方法研究
周剑烽
中国人民银行杭州中心支行,浙江杭州 310001
检索技术已经成为信息领域的重要技术之一,查询扩展技术是信息检索技术的一个关键技术,对提高检索结果的准确性和完整性有重要作用。为提高检索的查全率,本文在分析了传统查询扩展方法的基础上,结合语义检索技术的发展趋势,将语义模型中的本体概念融合到查询扩展技术中,提出了基于本体的局部文档分析查询扩展方法。实验结果显示,该方法的检索结果与人们的认识比较接近,达到了较好的语义检索效果。
本体 语义检索 查询扩展 局部文档分析
0 引言
目前的信息检索系统以关键词匹配为技术基础,检索结果的优劣依赖于用户给出的检索关键词。Furnas第一个发现了“词典问题”(dictionary problem)[1],即两个人使用同样关键词描述同一事物的几率小于20%。同时Xu Jx和Croft WB等人发现,49%的用户仅用一个关键词表达自己的查询请求,33%的用户使用两个单词进行查询,用户平均只使用1.4个单词描述他们的查询[2]。使用的查询词越少,结果命中率就越低,查询扩展技术由此产生,逐渐发展成了信息检索领域的一个重要研究方向,并已经向语义扩展方向发展。
本文将语义本体技术融合到基于局部文档分析的查询扩展方法中,得到了一种改进的基于本体的局部文档分析查询扩展方法,从语义角度扩展关键词,从而提高检索的质量。
1 相关理论
1.1 查询扩展定义
查询扩展就是指利用计算机语言学、信息学等多种技术,把与初始查询相关的词或概念以逻辑“或”的方式添加到初始查询中,得到比初始查询更长的新查询,然后再次检索文档,以改善信息检索的查全率和查准率,从而解决 “词不匹配”问题[3]。查询扩展技术大致可以分为3类:1)基于用户相关反馈的方法[4];2)基于全局文档集分析的方法[5];3)基于局部文档集分析的方法[3]。
1.2 基于局部文档集分析的方法
基于局部文档集分析的方法是在基于全局文档集分析的方法基础上提出来的,克服了全局分析方法构建全局叙词表计算量大的问题,同时也解决了基于用户相关反馈方法需要用户干预查询扩展的不足。但是该方法的效率取决于参与分析的文档数及文档的大小(词量),文档量大、文档体积大仍然会给局部文档分析带来巨大的计算量。同时由于难以保证待分析文档的相关性,造成扩展后查询表达式相关性的不确定,影响检索结果质量。
1.3 本体
本体是共享概念模型的明确的形式化规范说明[6]。从知识共享的角度来说,本体是通用意义上的概念定义集合,以分层次的形式化模式定义领域内术语间的相互关系,提供对这个领域知识的共同理解。实质上本体是一个领域的抽象知识化表示形式,具有良好的层次结构,以概念、实例以及各种关系表示领域中的信息。通过对本体中的关系进行推理,可以发掘隐含信息,实现语义上的关联。
2 基于本体的局部文档分析查询扩展方法
为了更好的发挥基于局部文档分析的方法优势,同时实现语义支持,本文将本体技术应用到基于局部文档分析的方法中,提出了基于本体的局部文档分析查询扩展方法。改进后的方法充分利用了本体的优良特性,以本体指导整个查询扩展过程,实现了对语义的支持,基本原理为:1)初始查询请求提交;2)本体化初始查询请求的关键词,并利用本体对关键词进行同义、近义扩展;3)进行一次检索;4)从检索结果中取N(N取值可以节)个文档进行分析,利用文档矢量(由文档特征词权重构成,特征词权重根据出现频率计算得到)提取文档中的特征词。文档矢量在对文档进行预处理时形成,重复使用;5)一次扩展后的关键词集通过本体进行二次语义扩展。通过本体对关键词逐个进行相似度值查询,根据相似度值的高低来决定新扩展词的取舍。向一次扩展关键词集合中添加语义相关的概念、实例,提高了检索词的语义完备性;6)对步骤4)和5)得到的关键词集合进行交运算,得到最终的扩展结果。这一步操作得到的关键词,既满足了传统方法的共现频率统计,也满足了语义相关性的描述,丢弃了两种方法产生的不一致的词,保证了语义相关性。
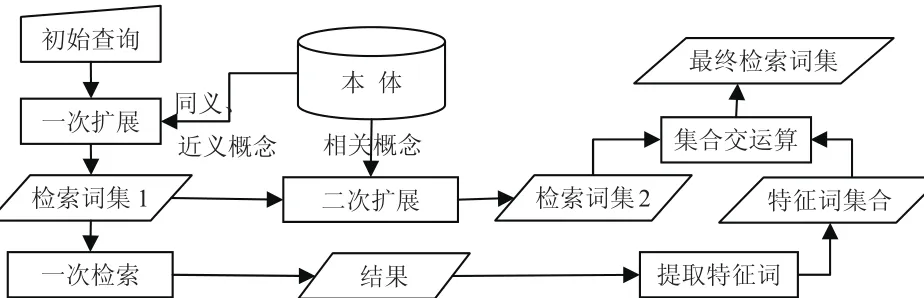
图1 基于本体的局部文档分析查询扩展方法
扩展过程由两条路,一条为本体扩展过程,即步骤5);一条是传统的文档分析过程,即步骤3)和4)。最终通过步骤6)合为一条路,产生最终的检索词集合。本体技术的使用,实现了对语义的支持,使扩展结果语义上更加明确,避免二义性。
3 实验及结果分析
本文以田径项目作为领域,构建了一个简单的实验本体。概念:田径项目,跳跃,径赛,投掷,接力,公路赛,障碍赛,短跑,长跑;实例:竞走,马拉松,女子100m栏,男子110m栏, 5000m,10 000m ,4×100m,4×400m,100m,400m,200m,标枪,铁饼,铅球,链球,跳高,跳远,三级跳远,撑杆跳高。
本文从网络上摘取了60个与田径项目相关的新闻作为实验文档,采用分层向量空间模型[7]进行文档的矢量化,得到对应的文档矢量。
以检索 “短跑”为例,使用传统方法和本文方法进行对比实验,使用查全率和查准率两个指标来衡量检索质量。60个样本文档中与“短跑”相关的文档总共是16个。
1)使用本文基于本体的局部文档分析查询扩展方法,最终检索结果如表1所示。
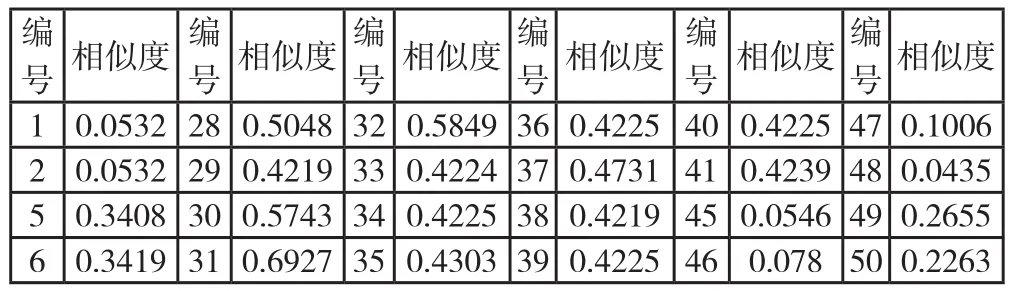
表1 检索文档相似度值(其余文档为零)
根据文档相似度值对结果进行相关性排序,以一定的阈值获取最终结果返回给用户。相似度阈值分别取0.3,0.4,0.5时,对应的查全率分别为:100%,87.5%,25%,查准率相同为:100%。
2)使用传统局部文档分析查询扩展方法,最终检索结果如表2所示。取同样的阈值0.3,0.4,0.5,对应的查全率分别为:62.5%,37.5%,37.5%,查准率相同为100%。
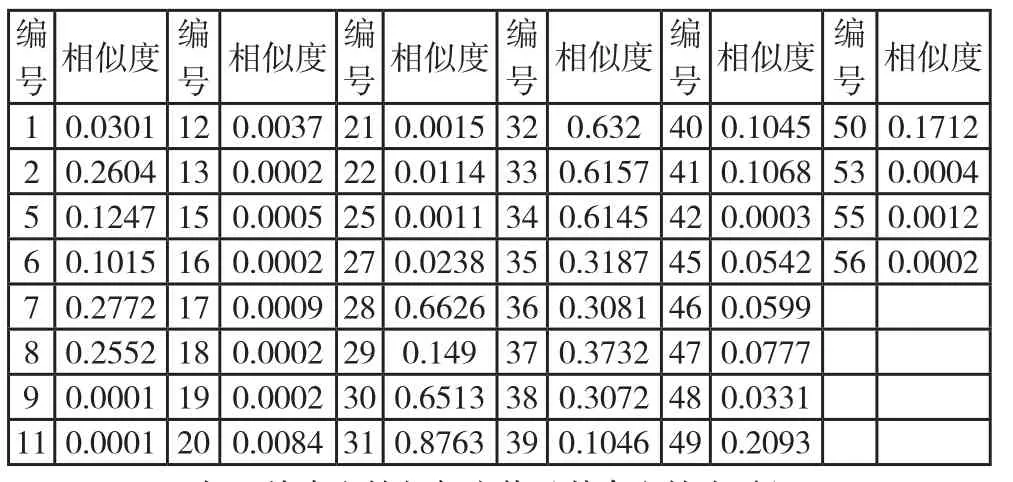
表2 检索文档相似度值(其余文档为零)

图2 本文方法与传统方法检索查全率对比
两种方法的查全率对比如图2所示。对文档相似度的要求也提高,符合的文档数量减少,查全率自然降低,阈值为0.3、0.4的时候,本文的方法对用户检索词的扩展效果更好,相关性更大,查全率高于原方法。为了使最终结果文档数在一个合适的范围内,需要在查全率和查准率之间选择一个平衡点,也就是选择一个合适的阈值来进行控制,实验中阈值取0.3和0.4都可以,在这个前提下,本文提出的方法能保证检索词的有效性和相关性,大大提高查全率,并保证查准率。
4 结论
对比结果,两种方法查准率一样,但查全率差别较大。阈值为0.3、0.4时,本文方法的查全率远高于原方法;阈值为0.5时,两种方法查全率差不多,但都比较低。原因为:随着阈值的提高,
本文针对基于局部分析的查询扩展不支持语义的弱点,通过融合本体技术于其中,得到了一个改进的方法。通过实验结果数据的对比分析,验证了本文提出的方法的有效性。
[1]Furnas GW,Landauer TK,Gomez LM,Dumais ST. The vocabulary problem in human-system communication. Communication of ACM,1987,30(11):964-971.
[2]崔航,文继荣,李敏.基于用户日志的查询扩展统计模型[J].软件学报,2003,14(9):1593-1599.
[3]黄名选,严小卫,张师超.查询扩展技术进展与展望[J].计算机应用与软件,2007,24(11):1-4.
[4]宋玲丽,成颖,单启成.信息检索系统中的相关反馈技术[J].情报学报,2005,24(1):34-41.
[5]TA Runkler, JC Bezdek. Automatic keyword extraction with relational clustering and Levenshtein distances,9th IEEE International Conference on Fuzzy Systems,IEEE,2000:636-640.
[6]陈泳,林世平.基于本体的语义检索技术[J].计算机工程与应用,2006(S1):78-80.
[7]高珊.信息检索中的查询扩展及相关技术研究[D].湖北:华中师范大学,2008:20-21.
G252.7
A
1674-6708(2011)36-0054-02
