Apriori关联规则算法的 C语言实现
2011-09-22宁燕子杨存志
李 楠,宁燕子,杨存志
(辽宁师范大学 a.计算机与信息技术学院;b.档案馆 ;c.教务处,辽宁 大连 116029)
Apriori关联规则算法的 C语言实现
李 楠a,宁燕子b,杨存志c
(辽宁师范大学 a.计算机与信息技术学院;b.档案馆 ;c.教务处,辽宁 大连 116029)
在分析 Apriori算法的基础上,介绍了该算法的 C语言实现,包括频繁集的发现和关联规则的生成,为进一步研究关联规则提供了基础。
数据挖掘;关联规则;Apriori算法;C语言
数据挖掘 (Data Mining,DM)是指从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们不知道的、但又是潜在有用的信息和知识的过程[1],是数据库知识发现(Know ledge Discovery in Database,KDD)过程中对数据真正应用算法抽取知识的一个步骤,是 KDD过程中的重要环节[2]。数据挖掘的方法主要包括:分类、回归分析、聚类、关联分析等。其中,关联规则挖掘是数据挖掘研究的一个重要分支,是众多知识类型中最为典型的一种。
关联规则挖掘最早是由 Agrawal等人于 1993年提出的[3],其形式化的描述如下:设 I={i1,i2,…,im}是 m个不同项的集合,事务 T为 I的子集,不同的事务的集合构成事务集D。关联规则就是形如X→Y的蕴涵式,其中 X⊃ I,Y⊃ I,且 X∩Y=Φ。
关联规则的实用性由支持度衡量,描述了 X和 Y两个项集同时出现的概率,定义为:Suppo rt(X→Y)=|{T:X∪Y⊆ T,T∈D}|/|D|。关联规则的准确性由可信度衡量,描述了出现 X的事务集 D同时也出现 Y的概率,定义为:Confidence(X→Y)=|{T:X∪Y⊆ T,T∈D}|/|{T:X⊆ T,T∈D}|。
关联规则挖掘就是在事务集D中找到满足最小支持度 m in-support和最小可信度 m in-confidence的关联规则。该问题一般分为两步骤完成:
(1)找出满足最小支持度 m in-support的所有频繁集;
(2)根据找到的频繁集,产生所有可信度大于m in-confidence的规则。其中,步骤 (1)是制约Apriori算法运行效率的关键所在,因为需要多次扫描数据集,需要消耗大量的时间和空间,众多文献中都对 Apriori算法的改进进行了多种研究[4-7]。
1 Apriori算法
在众多关联规则的算法中,Apriori是最有影响的挖掘布尔关联规则频繁项目集的算法,同时也是其他大部分关联规则算法的基础。Apriori算法的最主要的概念,就是从候选项目集合 Ck-1中通过扫描事务集 D,找出大于或者等于最小支持度的项目集,称为频繁项目集 Lk-1;再以频繁项目集Lk-1通过自连接和剪枝操作产生候选项目集Ck,候选项目集 Ck再通过扫描事务集找出频繁项目集 Lk,如此重复直到无法找到频繁项目集为止。
为了生成所有频集,使用了递推的方法。其核心思想简要描述如下:
第一步
输入:数据集 D;最小支持度 m in_sup
输出:频繁项目集 L


has_infrequent_subset(c,Lk-1)是为了判断 c是否需要加入到 k-候选集中。按 A graw al的项目集格空间理论,含有非频繁项目自己的元素不可能是频繁项目集,因此应该及时裁掉那些含有非频繁项目子集的项目集,以提高效率。例如 L2={AB,AD,AC,BD},对于新产生的元素 ABC不需要加入到 C3中,因为它的子集 BC不在 L2中,而 ABD应该加入到 C3中,因为它的所有的 2-项子集都在 L2中。
2 算法的实现流程和主要源代码
2.1 算法的实现流程
算法的流程如图 1。
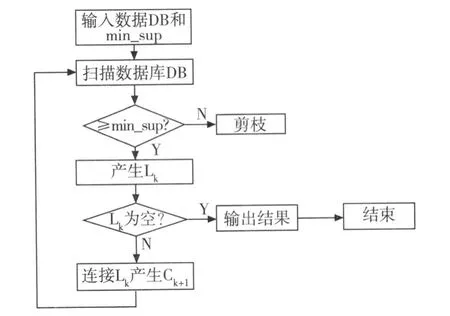
图1 Apriori算法实现流程图
2.2 数据库、数据项的结构体
下面用 C语言实现上述算法,首先要定义结构体,分别存放数据项。
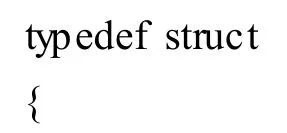

2.3 主要的程序源代码


2.4 实验结果及分析
采用如图 2的数据库。
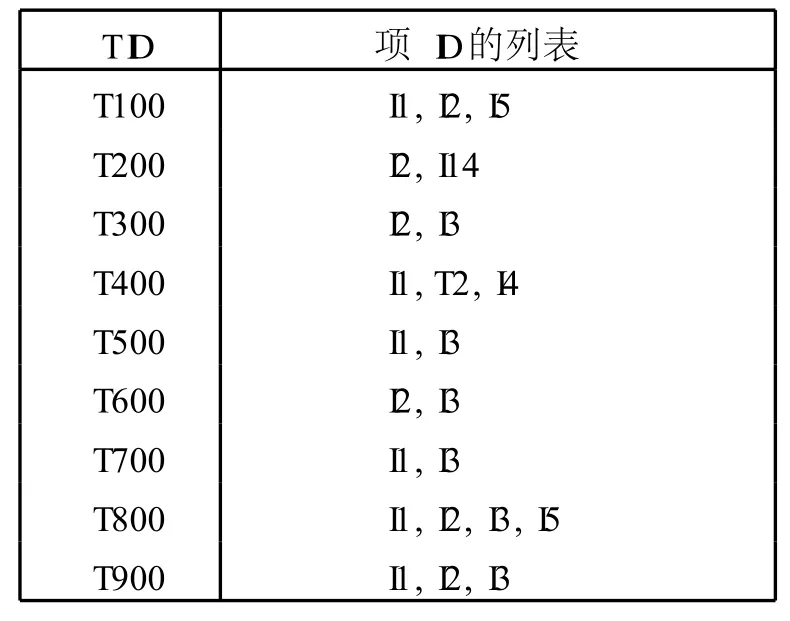
图2 数据库中的项目集
本程序执行以后,切实的可以自由设置最小支持度,并且在确定支持度的前提下,可以输入实际的交易集大小,以及交易集中项目的个数,并且选择实际的数据库,在以上 3项确定的情况下可以得到的运行结果如图 3。
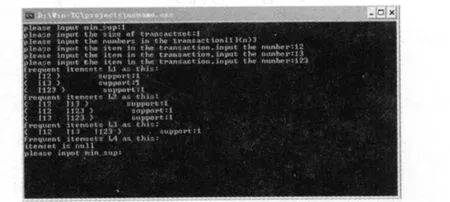
图3 连续输入 3条项目并且显示运行结果
Apriori算法作为经典的频繁项目集生成算法,在数据挖掘中具有里程碑作用。但是随着研究的深入,缺点也暴露出来。Apriori算法有两个致命的性能瓶颈:
(1)多次扫描事务数据库,需要很大的 I/O负载。
对每次 k循环,候选集 Ck中的每个元素都必须通过扫描数据库一次来验证其是否加入Lk。加入一个频繁大项目集包含 10个项,那么至少需要扫描事务数据库 10遍。
(2)可能产生庞大的候选集。由 Lk-1产生 k-候选集 Ck是指数增长的,如此大的候选集对时间和主存空间是一种挑战。
本文用 C语言实现之算法,对所输入数据库有严格的限制,循环语句太多,并且每一次扫描数据库都要进行多层循环,浪费了程序运行的时间和空间,因此有进一步研究改进的空间。
3 结 语
Apriori算法是关联规则中的经典算法,文中主要对 Apriori算法进行研究分析之后,采用 C语言对算法进行了实现,为进一步的关联规则改进等方面的实现都奠定了一个良好的基础。
[1]陈京民.数据仓库与数据挖掘技术[M].北京:电子工业出版社,2002.
[2]王丽珍,周丽华,陈红梅,等.数据仓库与数据挖掘原理及应用[M].北京:科学出版社,2005.
[3]AGRAWAL R,IM IL IENSK IT,SWAM IA.Mining association ru les between sets of item s in large datasets[C].GIGMOD,1993:207-216.
[4]柴华昕,王勇.Apriori挖掘频繁项目集的算法的改进[J].计算机工程与应用,2007(43):24.
[5]钱少华,蔡勇,钱雪忠.基于数组的 Apriori算法的改进[J].计算机应用与软件,2006,23(2):44-46.
[6]谢宗毅.关联规则挖掘 Apriori算法的研究与改进[J].杭州电子科技大学学报,2006,23(3):78-82.
[7]程玉胜,邓小光,江效尧.Apriori算法中频繁项集挖掘实现研究[J].计算机技术与发展,2006,16(3):58-60.
(责任编辑 刘敏)
Research and Implementation of Apriori Rules Algorithm Based on C
LI Nana,NING Yan-zib,YANG Cun-zhic
(a.College of Computer and Information Technology;b.Archives;c.Academic Affairs Division Liaoning Normal University,Dalian Liaoning 116029,China)
A ssociation rule is an effective way for know ledge discovery in datamining,where in algorithms.The Apriori is a classical algorithm.Based on the analysis of the algorithm Apriori,we introduced the algorithm’s realization of discovery of frequent item sets and generation of association rules by using C,and at last it perform s a validation to discover the frequent item sets from the traditional market basket,and also the rules satisfying with the minimum support and confidence.Which provide a so lid foundation for further research of association rules.
datamining;association rules;Apriorialgorithm;Clanuage
TP312 < class="emphasis_bold">文献标志码:A
A
1009-315X(2011)01-0052-04
2010-09- 07;
2010-09-17
国家自然科学基金项目 (20873055)。
李楠 (1977-),女,辽宁丹东人,讲师,主要从事分布式数据库、数据挖掘算法研究。
