基于Web的智能信息检索方法研究*
2011-09-03李春生杨冬黎
高 玲, 李春生, 杨冬黎
(1.大庆油田图书馆,黑龙江大庆163300;2.东北石油大学,黑龙江大庆,163318)
Web为用户提供海量信息的同时,也带来了大量的噪声,用户对大量的无关信息淹没对自己有价值的信息已经无法忍受[1]。所以即时的处理大量信息,提高信息检索系统的准确率,使用户可以快速找到自己所需要的信息已经变得势在必行,Web信息检索受到越来越多的重视[2]。Web信息检索与传统信息检索有所不同:一是信息资源海量,用户对查全率的追求降低,查准率要求越来越高;二是文档之间的超链接结构是Web信息检索和传统信息检索的又一区别[3],链接描述文档对网页主题的概括有高度的精确性,由此产生了基于超链接结构的检索技术;三是Web上的文本数据大部分用HTML书写,使用HTML标签对网页的修饰作用进行信息检索。
本文以石油安全信息检索为例,应用分类算法和中文分词的关键技术,研究了信息检索模型及其实现。具体包括:⑴以石油安全生产方面的Web页为例,将大量分散无序的Web页信息集中起来,经过加工整理,使之形成有序化、系统化的语料库;⑵结合信息检索模型的相关理论、关键技术,选择在检索模型中应用概率的计算方法[4];⑶通过运用统计的学习方法,实现模型对检索结果的优化与完善。用已知的石油安全生产方面的文档,对模型的检索结果不断地进行训练,从而使模型在多次交互操作之后,得到的检索结果逐步接近用户提问的理想命中结果。
1 基于Web的信息检索模型设计
建立信息检索模型是实现检索系统的基础,基本设计要求如下:⑴语料库足够大,检索到的数据能满足一般用户需求;⑵用户操作界面简单,用户可以很方便地输入检索请求;⑶检索出的信息能够达到用户的要求,并能按照合理的顺序显式给用户,并且可以对显示的信息进行分类处理。
1.1 模型结构设计
信息检索是利用一定的检索算法,借助于特定的检索工具,针对用户的检索需求,从结构化或非结构化的数据中获取有用信息的过程。把整个信息检索过程刻画为三个方面:信息的存储与组织,信息的检索,信息的展示[5]。图1给出了信息检索过程的框架结构。

图1 基于Web的信息检索框架结构Fig.1 Web-based framework for information retrieval
根据图1的框架结构,可以设计基于Web的信息检索模型,对Web页的分类处理分两个阶段完成。第一阶段是利用自动搜索程序,通过输入一个短查询式的问题,进行初始检索,然后将检索出的Web页面经过页面清洗,去掉噪声,最后以文本文档的形式存入专门设计的后台数据库(包含检索出的题目、上传时间、内容等)。所谓Web页面清洗,是从Web页面中划分出精确的信息单位,并根据Web页面信息加工的后续应用的需求,将页面中不需要的部分去除,将需要的部分提取出来。噪声是指Web页中大量的诸如导航条、广告链接、版本信息、更新日期等。本文采用一种新的“HTML页面清洗压缩算法”,该方法是把页面对应的HTML文档,转化成对应的HTML树,然后再对树进行页面清洗。经过清洗后,Web页面在结构和语义上都被划分成细粒度的信息块,为后续的信息加工工作顺利进行提供了方便。由于在初始检索结果中会得到数目相当庞大的结果,包含的信息质量也会良莠不齐,大量的与用户意图不相关的文档也混杂在其中,这样就造成检索结果不够准确。因此需要对这些文档再进行第二次检索,即进入检索的第二阶段。第二阶段主要任务是对文本文档加以归类,利用文本分类方法来组织信息,最终实现按类显示用户查找信息的要求。
第二阶段信息检索模型分成前台用户查询处理和后台文档信息处理两大部分,结构如图2所示。
前台部分:给用户提供查询界面,用户在该界面输入查询请求后,调用后台信息,界面中会显示查询结果。用户点击查询到的文档标题后,又弹出一个界面。界面的上方显示这篇文档属于第几类,界面的下方会显示这篇文章的详细内容。
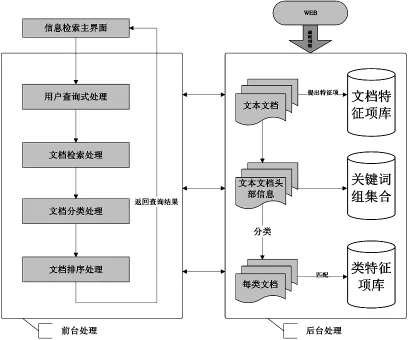
图2 模型的组织结构Fig.2 Structure of the model
后台部分:利用第一阶段从Web上收集来的用户初次查询请求资料,将其转化为统一格式的文本文档。然后对所有文档采用停用词处理,也就是删掉没有意义的代词、助词、副词。再采用信息检索模型对所有文档进行检索,先提取特征项。我们选取能正确反映文档重要内容的文档标题、摘要部分进行关键词及词组提取,然后这些词形成了文档的关键词组集合。再计算每篇文档中关键词出现的频数,将词频数高的关键词也存储到文档特征项库中去。将查询式词组、特征项及已知的数据字典中的类特征项进行匹配,使用分类算法公式计算概率值,依据数值进行归类处理。
1.2 分类算法设计
为了对模型进行训练,将文本集分为两个部分:训练集和测试集。所谓训练集是由一组已经分好类(即已给定类别标号)的文本组成,用于归纳出各个类别的特性以构造分类器。测试集是用于测试分类效果的文档的集合。其中每个文本都通过分类器分类,然后与正确决策的分类结果相对比,从而得到对分类器效果的评价,其中,测试集不参与分类器的训练。
本文采用贝叶斯分类方法对文档进行分类。由于真实文本的一个属性对给定类的影响独立于其他属性的假设并非总是成立,我们选取了贝叶斯网络分类器。这种模型考虑到了属性之间的依赖关系,更能反映文本的真实情况。但代价是计算复杂度比朴素贝叶斯高。贝叶斯分类算法的基本思路是计算文本属于类别的概率,文本属于类别的概率等于文本中每个特征项属于类别的概率的综合表达式。其具体算法步骤如下:输入训练集文本文档,每个文档都包含特定的特征的词。
第一步:先对训练集中的每个文本文档进行分词处理,提取关键词。依次计算出每个关键词在这个文档di中出现的次数ni和频度fi。频度:
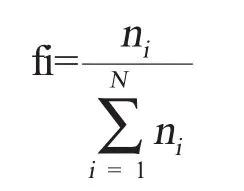
其中N为每个关键词在文档di中出现的次数的和。频度高的这些关键词放到文本特征项库中。
第二步:用下列公式计算特征项库中每个特征词属于每个类别的概率。
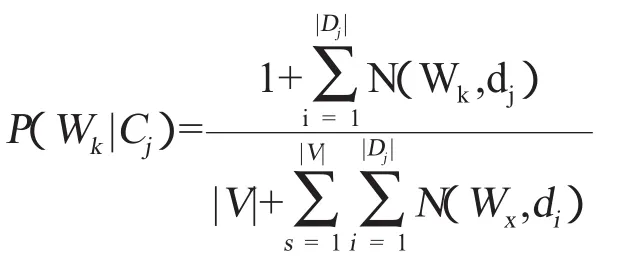
其中:
P(Wk|Cj)为特征词 Wk在类 Cj中出现的比重,|DJ|为该类的训练文本数,N(Wk,di)为特征词Wk在文档di中的词频,|V|为特征文档库中的总词数(Wx,di)为该类所有词的词频和。
第三步:文本到达时,根据特征词,按下面的公式计算该文本di属于类Cj的概率:

P为类的总数,N(Wk,di)为Wk在di中的词频,n为特征词总数。
第四步:比较测试文档属于所有类的概率,将文本分到概率最大的那个类中。
第五步:确定阈值。根据训练集中文档的概率和频率,算出每一类的阈值。
第六步:当有新文档出现时,只需要用它第二步计算出P(Wk|Cj)和每一类的阈值进行比较,大于阈值的认为是相关文档,把它归入该类中。省去第三步到第五步的计算过程,节约了时间也减少了计算工作量。
2 模型在石油安全领域的应用
在基于中文分词和文本分类算法相结合的信息检索模型的基础上,针对石油安全领域的Web信息检索设计了一个智能信息检索系统,该系统在查找准确率、文档分类方面均取得了较好的结果。
2.1 实验数据
本文利用网络蜘蛛自动搜索程序从百度网上采集了与石油相关的Web页400个。其中200个作为训练集,剩下的200个作为测试集。为了保证训练数据的正确性,训练集里的Web页是由人工提取的。
2.2 数据处理
数据处理基于语料库。语料库主要由文档特征项库、类特征项库、关键词组集合三大部分组成。文档特征项库是从由特征提取中词频高的关键词组成的(可以选择字、词或词组来作为特征项,但是根据做实验显示的结果来看,选取“词”作为特征项要优于字和词组,所以文档特征库是由词构成的);关键词组集合是从每篇文本文档的标题、摘要、关键词信息中获取的;类特征项库是利用数据字典中的数据获得的。
数据处理的目的是让系统最终实现智能分类,要分类就得先分词。对于一篇经过预处理后的文本文档,根据它出现的标点符号位置,先将它切分成句子。遇到逗号、问号、感叹号、分号、冒号、省略号和回车换行符,就认为是一个句子的结束标志。另外,如果句子中存在括号,被一对括号括起的部分认为是一个独立的句子。然后对句子再进行切分,得到词。这主要是因为考虑到自然语言处理技术的影响,选择词作为文本组成的特征,更符合人们的思维习惯。因此本文中文档特征项库中的关键词、关键词组集合中的特征项都是用文本分词的方法获得的。本文采用的中文分词算法是基于分词词典(常用词词典)的字符串匹配算法,其分词过程如3所示。
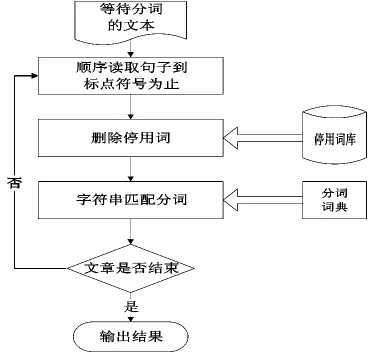
图3 中文分词流程Fig.3 Flow chart of Chinese Word Segmentation
现以石油安全生产领域的一篇名叫《石油库带掩体油罐防护安全距离的确定》的文档D1和《加油站与加气站安全距离要求》的文档D2为例,说明对文档的智能分类过程。
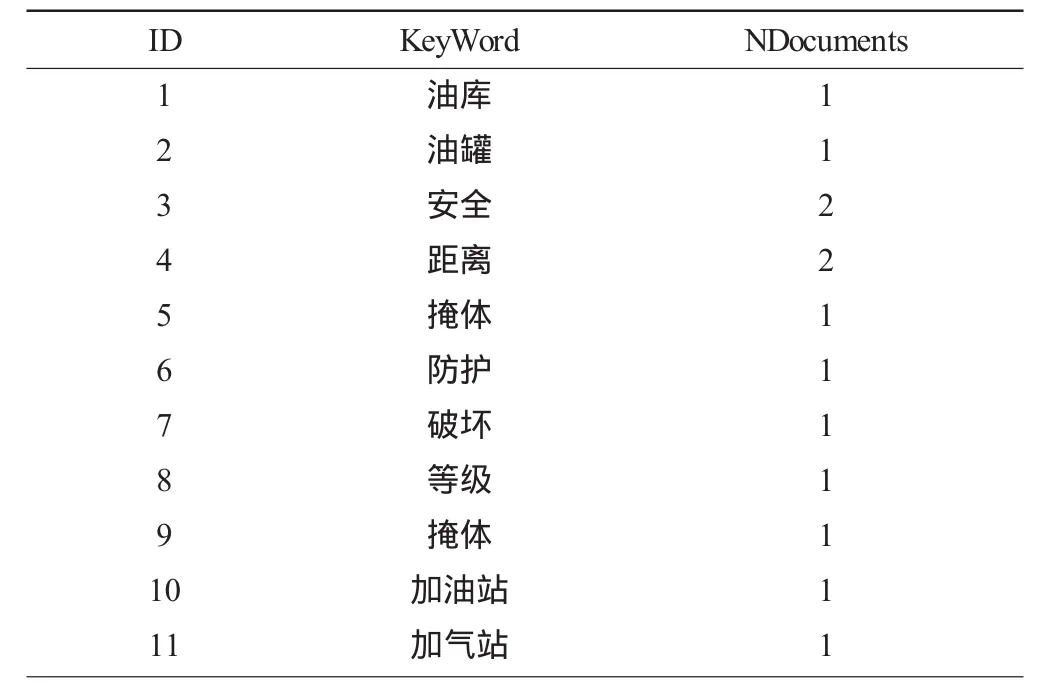
表1 D1和D2关键词统计Table 1 Keywords statistics of Documents D1 and D2
石油库带掩体油罐防护安全距离的确定。摘要:油库安全距离有两个不同的概念,一个是防火安全距离;另一个是防护安全距离。针对如何科学地确定油库防护安全距离这一问题,对炸弹的破坏因素和建筑物的破坏等级进行了分析与划分,从而根据建筑物的重要性和抗冲击波破坏能力,确定其允许破坏的等级,再由投弹的装药量计算出冲击波的设防安全距离。对于带有掩体的油罐,其防护安全距离的确定应根据允许破坏等级、爆炸位置以及有掩体的两油罐间防护安全距离的计算来确定。关键词:油库,油罐,安全,距离。
加油站与加气站安全距离要求。根据《汽车加油站、加气站设计与施工规范》,加气机与加油站、加气站房的最小防火距离为5米。
从文档D1和D2的标题、摘要(或者主要叙述内容)、关键词信息中我们取出相对重要的词放到关键词组集合中,如表1所示。
由于“安全”和“距离”这两个词在文档D1和D2中全出现了,所以这连个词的NDocuments=2,其余词的NDocuments=1。如下图4所示。
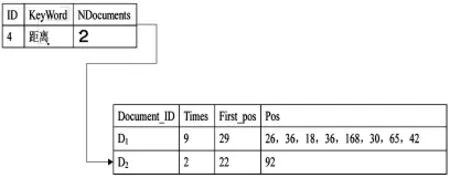
图4 “距离”关键词统计Fig.4 Statistics of the keyword“Distance”
从图4可知,关键词“距离”出现在D1与D2两篇文档中,“距离”在文档D1中一共出现了9次,第一次出现的位置为29,第二次出现的位置离第一次出现位置的相对的位移为26(这里采用的是一个汉字占2个字符的算法来计算词在文档中的位置的)。“距离”在文档D2中仅出现了2次。从图4显示的内容来看,关键词“距离”这个词在文档D1中的出现的频率是很高的,所以把它存入到文档特征项库中。类特征项库的数据是从已知的石油安全数据字典中获得的。
2.3 检索结果
在面向用户的信息检索系统的检索词提交框中,用户输入想查询的关键词,或者在下拉列表框中选择已知的类别中的某一类,点击“搜索”按钮提交给系统。经过计算处理后,查到的与用户输入相关的文档结果会按相关度展示给用户。通过对系统测试,文档对应分类的查准率稳定在62%到71%之间。如图5所示。
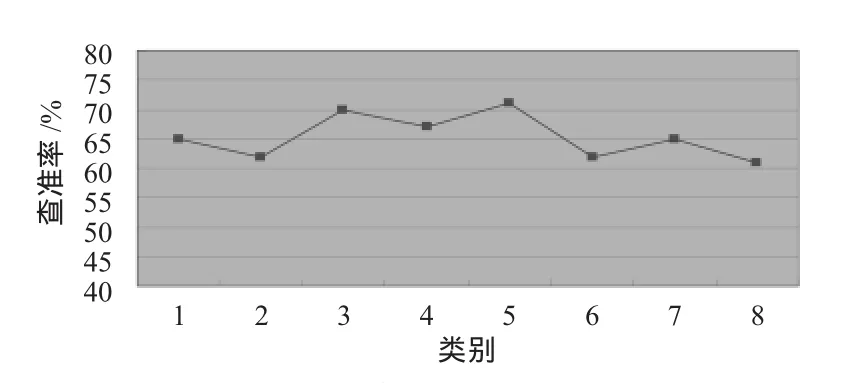
图5 不同类别查准率的比较Fig.5 Comparison of accuracy of different categories
3 结 论
提出了分阶段对Web页的检索方法。第一阶段,通过在Web站点上安装程序获取Web页,应用页面清洗技术,使之变成文本文档,实现了模型中数据导入前的预处理;第二阶段,把分类算法运用到信息检索模型中,在计算文档与用户需求相关度的同时,对文档进行了分类。通过概率模型实现了文档的分类,并且把这种方法应用到了石油安全生产领域,取得了良好的分类效果。
[1]WANGNENGBIN.Databasesystemtutorial[M].Beijing:Publishing houseof Electronics Industry,2004.
[2]张德海,沙月林.基于本体与工作流的知识服务系统[J].计算机工 程,2009,35(19):75~77,80.
[3]MENGXIAO-FENG,ZHOULONG-XIANG,WANGSHAN.Stateof theart and trends in databaseresearch[J].Journal of software,2004,15(12):1822~I836.
[4]杜小勇,李曼,王珊.本体学习研究综述[J].北京软件学报,2006,17(9):l837~1847.
[5]王珊,萨师煊.数据库系统概论[M].北京:高等教育出版社,2005.
