供应链下Flow Shop调度问题的多目标混合算法研究
2011-09-03黄明达
黄明达, 刘 林
(合肥工业大学 管理学院,安徽 合肥 230009)
传统调度模型通常只研究企业内部生产阶段的问题,很少考虑到供应链上的其他因素,因此往往需要付出很高的代价;要突破过去的瓶颈,实现从生产能力、生产效率以及成本等方面的整体性飞跃,就必须将供应链的各个环节引入调度模型。目前,对于供应链环境下调度问题的研究多局限于生产计划层面,且考虑的目标过于单一和理想化,与实际情况相去甚远。例如文献[1]研究的是供应链下生产调度的管理机制;文献[2]讨论了一种扩展企业调度的计划方法;文献[3]虽然对多种产品情况下的分布式调度问题进行了分析,可实质上只是将生产车间的概念延伸至工厂。
供应链环境下的调度涉及的绝大部分为多目标问题,通常采取的方法有2种:
(1)将多目标转化为单目标求解。文献[4-6]采取的就是类似加权策略的求解办法,但这在现实中却往往不可行,因为除了权值难以确定外,量纲的统一也是一大障碍。
(2)寻找Pareto解。文献[7]就提出了一种基于Pareto排序的多目标遗传算法,文献[8]则针对多目标不等待Flow Shop问题,设计了一种基于生物免疫(IS)和细菌优化(BO)的混合Pare-to求解算法。
由于求解过程中多个目标在搜索方向上的差异以及它们之间的互相干扰,结果在分布的范围和解的优化程度等方面与期望有着不小的差距。
本文以供应链环境下单工厂多分销中心的调度问题为背景,选择了带有运输、库存、拖期惩罚等影响因素的Flow Shop调度问题为研究对象,以粒子群和SOM自组织神经网络算法为基础,构建了相关的模型与算法。仿真结果显示,该算法无论在解的优化程度、分布的范围还是分布的均匀程度上都达到了令人满意的效果。
1 问题描述
本文所针对的供应链下Flow Shop调度问题可描述为:1个加工系统,多个分销中心,有n个要加工的工件,每个工件都需要经过相同的m道加工工序,每道工序要求在不同的机器上完成。工件在加工完成后存放于工厂仓库,直至由运载工具运往分销中心。
问题假设一个生产周期内,工件的库存费用和拖期费用都远低于运输费用,当仓库中待发往某分销中心的工件数量达到运载工具的最大载货量时即起运货物;加工系统所生产工件的体积相似或相同,运载工具一次所能运送的工件种类可以不同但最大数量一致;加工系统与每个分销中心之间都有各自独立的运载工具与运输线路。问题的目标是确定工件的加工顺序,使所有工件的最大完工时间最短,库存与拖期的成本最小。问题的数学模型描述如下:
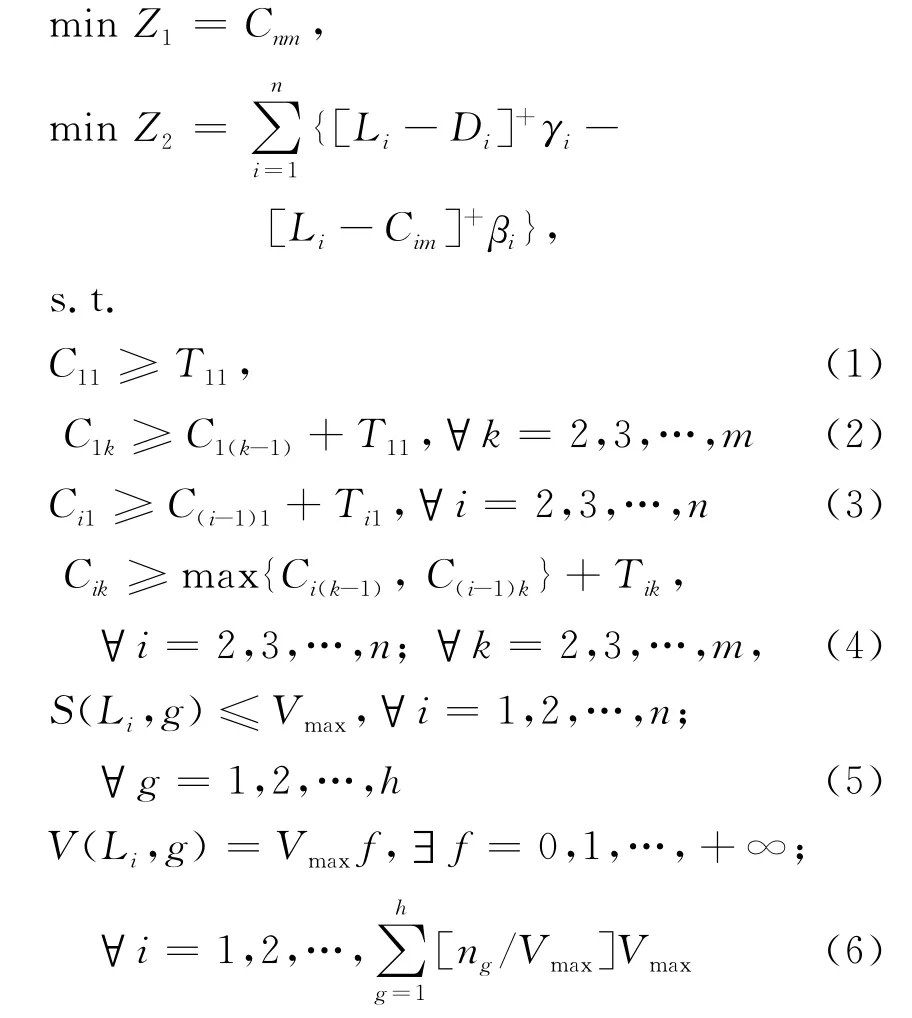
其中,n为工件数;m 为加工工序数(机器数);h为分销中心数量;ng为分销中心g订购的工件数量;Tik为工件i在第k道工序上的加工时间;Di为工件i的交货期;Cik为工件i在第k道工序上的完工时间;Li为工件i由加工系统运往分销中心的时刻;γi与βi分别为工件i的单位拖期和库存成本系数;Vmax为运载工具的最大单次载货数量;S(Li,g)为Li时刻仓库中待发往分销中心g的工件数;V(Li,g)为Li时刻发往分销中心g的工件数。
问题的约束条件(1)~(4)表示一个工件一次只能在一台机器上加工且一台机器一次只能加工一个工件,约束条件(5)表示运载工具一次的载货量不能大于其最大单次载货量,条件(6)则表示运载工具的起运条件为达到其最大载货量(除生产周期的最后一次运输外)。
2 算法思想与流程
关于多目标算法的优劣目前学界并无一个统一的评价标准,研究人员所使用的评判方法也多种多样[9-12],评价指标主要有解的分布范围、分布均匀程度以及单个解的质量。因此,要得到更优的解集就要将以上三者有机地综合起来。然而,由于各目标进化方向上的不统一,研究人员在追求单个解的质量的过程中往往不得不让前两者做出极大让步,导致解集的范围往往过于局限,无法给决策者提供更多不同的选择方案。
出于兼顾三者的目的,本文算法将首先凭借PSO粒子群算法在单目标问题求解上的优势,分别找到2个进化方向上的最优个体,再利用SOM自组织神经网络算法良好的学习能力,向先前得到的2个解序列学习并由此得到2个目标值都较为优秀的解,最后通过拟合Pareto曲线并找出均匀分布点的方法实现最终结果的优化。
用本文算法求解供应链下多目标Flow Shop调度问题的具体过程如下:
(1)随机生成初始种群。
(2)对生成的种群分别以目标值一和目标值二为评估标准,通过新的PSO算法进行处理,生成2个解集,如图1a所示。
(3)将得到的3个解集的解作为输入序列,运用SOM自组织神经网络算法进行处理,通过向输入序列的学习,生成一个原始的兼顾2个目标值的解前端,如图1b所示。
(4)执行VNS变邻域搜索算法,进一步优化各个所得解,如图1c所示。
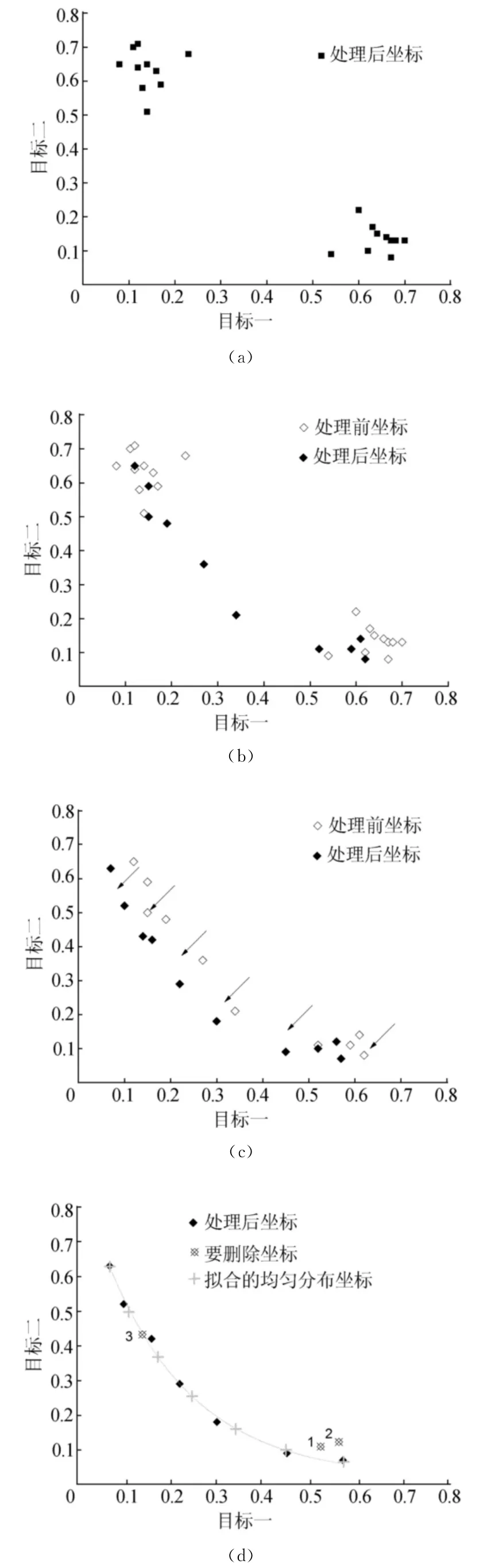
图1 概念演示图
(5)得到解集的Pareto前端,如图1d中的1、2所示。
(6)对Pareto解集进行曲线拟合,计算曲线长度并得到曲线的等长分割点,通过这些分割点对Pareto前端的集进行筛选,得到分布更均匀的多目标解集,方便决策者从不同解中找到所需的满意解,如图1d中的3所示。
3 PSO子算法
粒子群算法(Particle Swarm Optimizat-ion,简称PSO)[13],最早是由 Kennedy和Eberhart于1995年提出的,其基本思想是对鸟类捕食等社会群体行为的模拟。在该算法中,所有的粒子首先赋予位置X以及速度V,而后粒子就追随当前群体中的优秀粒子在解空间中进行搜索,其公式可描述为:
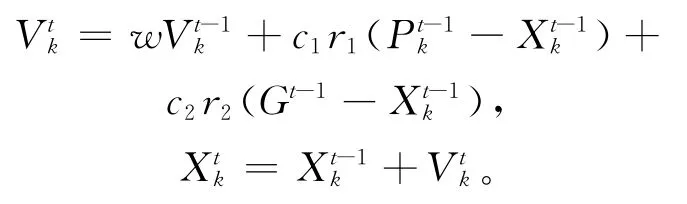
由于标准的PSO粒子群算法只能适用于连续性函数的优化,而无法实现对Flow Shop此类离散排序问题的求解,因此本文提出一种新的PSO改进算法来处理粒子的位置更新以及种群的优化。从原算法的公式可知,PSO粒子运动的实质[14]在于以当前位置为基点,按一定的概率不断向个体历史最优与全局最优的位置靠拢,故本文设计粒子位置的更新公式如下:
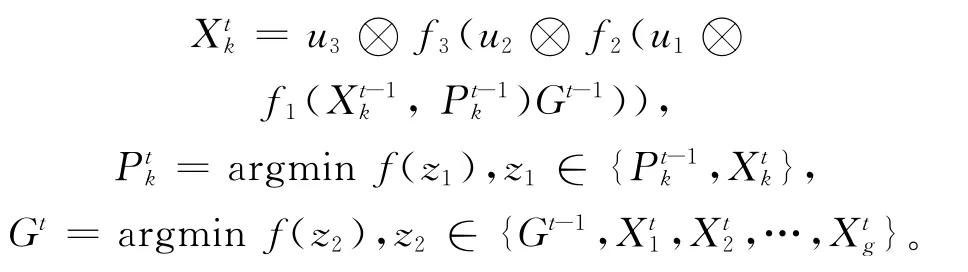
本文以加工序列作为种群的粒子,g为粒子个数;t为迭代次数;k为种群的个体序号;Ptk与Gt则表示个体历史最优和全局最优;f1、f2、f3分别表示执行与个体最优、全局最优的序列交叉(PMX方法)以及个体自身的单点变异;u1、u2、u3为执行的概率。粒子在迭代过程中首先执行与个体历史最优的杂交从自身吸取经验,再通过与全局最优的杂交向整个群体学习,最后执行一定概率的变异,以体现粒子进化过程中的部分不确定性。
为了保证粒子群进化过程中的个体多样性及收敛效果,本文将采取一种新的自适应参数获取方法,即粒子间的交叉概率以及变异概率由当前粒子的多样性决定。当多样性较差时提高变异概率并降低交叉概率以增强种群的全局搜索能力,反之则提高种群的交叉概率,降低变异概率以向最优解靠拢,该方法的公式表示如下:
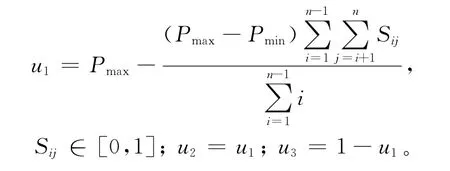
其中,Pmax与Pmin分别代表概率取值的上/下限;n为工件数;Sij则为粒子i与j的相似度。
关于相似度Sij的计算,学界通常采用点对点的方法,笔者认为该方法忽略了Flow Shop调度强序列依赖这一重要特性,即序列的相似度应该取决于工件加工的先后顺序而非位置,例如以下2个序列,如果采用点对点比较,其相似度为0,但实际上两者却拥有十分相似的序列段。
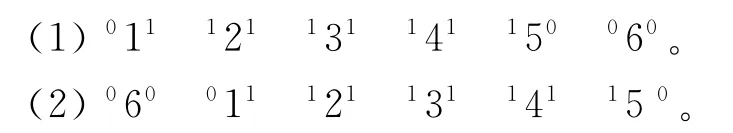
因而本文在计算Sij时,将以工件加工的先后顺序为依据,以上面2个序列为例,其相似度为8/12。
4 SOM子算法
自组织神经网络算法(Self Organizing Map,简称SOM)[15]同其他人工神经网络算法一样,通过模拟人类大脑的行为来解决诸如预测、聚类分析、数据挖掘等问题,不同的是它采用非监督式学习(unsupervised learning),即根据输入向量的特性对其进行处理。鉴于此,本文以PSO阶段得到的2个序列解作为输入,凭借网络对输入序列的自动聚类与反复学习,使权重向量在输出时具有前2个解集的优势,达到2个目标值的协调统一,其具体算法如下:
(1)初始化。从PSO算子的2个解集中根据目标值自小至大各选取g/2个不同序列作为输入向量{I1,I2,…,Ig};随机生成g 个不重复序列作为权重向量{W1,W2,…,Wg}。
(2)竞争。为每一个输入向量Ik找到一个与其最相似的权重向量W作为获胜神经元,其竞争规则如下:*Wk=arg max Sk(W),W ∈ {W1,W2,…,Wg},其中,Sk(W)为序列W 与Ik的相似度,其计算方法与PSO子算法中的相同。
(3)权重序列的更新。由于离散不重复序列的特殊性,权重序列在竞争获胜后将作如下的更新:

其中,f表示获胜神经元序列与输入序列执行交叉操作,学习其部分序列段;η为学习率,代表要学习的序列段长度,即交叉部分的长度。
(4)学习率的更新。在每一次迭代之后,需要对学习率进行一定的调整,调整规则如下:

5 VNS搜索策略
变邻域搜索方法(Variable Neighborhood Search:,简称 VNS)[16]属于一种局部搜索算法,与一般局部搜索算法的不同的是,它采用2种或者2种以上的邻域结构,当其中一个邻域陷入局部最优时即改用其他邻域生成方法。本文所使用的VNS算法选用插入邻域和交换邻域2种邻域结构,其应用规则如下:
(1)插入(邻域)操作。随机选取序列中一个工件,将该工件随机插入其他任何一工件之前;
(2)交换(邻域)操作。随机选取序列中2个工件,将这2个工件的位置互换。
算法首先以SOM算子所得的解为输入,重复下面操作步骤:
(1)对解进行插入操作并评估结果,如果2个目标值都较先前更优则更新序列并再次执行此操作,否则执行步骤(2)。
(2)执行交换操作并评估结果,如果2个目标值都较前更优则更新序列,否则不执行。在迭代次数达到要求后结束算法。
6 均匀度优化策略
对于一个多目标问题的解,如果其在Pareto前端分布较均匀,决策者就能更加容易地从不同的解中选择想要的解决方案[17]。为了实现解集的优化,减少差异性较小的解对决策者的影响,本文需要对前面所得Pareto解集进行一次筛选,即均匀度的优化。
由于要解决的是一个两目标问题,因此可以将得到的Pareto前端拟合成一条近似曲线。具体步骤如下:
(1)对得到的2个目标值通过如下公式进行归一化处理,即

其中,Omax和Omin分别代表该目标函数的最大与最小目标值。
(2)以函数y=1/(a+bx)(目标一值为x,目标二值为y,np为要拟合的点数)为基准拟合曲线,其公式如下:

(3)对该曲线使用积分求得其长度,即
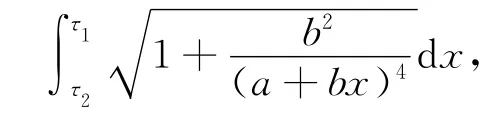
其中,τ1和τ2为目标一的最小与最大目标值。
(4)将曲线均匀等分得到S个点。
(5)依次选取与等分点(欧式距离)最接近的点作为保留点,删除其余Pareto解。
7 仿真实验及结果分析
7.1 算法评价准则
为了真实反映本算法在单个解的质量、分布的范围以及均匀度上的性能,本文采用以下3个评价准则。
(1)解的质量[18]。假定要评价的2个算法其非支配解集分别为A1与A2。将这2个解集叠加并去掉其中的支配解,从而得到一个新的Pareto解集A,记新的解集中属于原解集A1的解的数量为a1,其中属于原解集A2的解的数量为a2,则A1解的质量可描述为:Q(A1)=a1/(a1+a2)。
(2)分布范围[19]。设z0与z1为集合A中的任意解,fi(z0)和fi(z1)分别为该两者在目标i上的目标函数值,Fmaxi和Fmini为所有参与比较算法所得解的最大与最小目标值,则解集A分布情况的计算公式如下:

(3)均匀程度[20]。设d′1,d′2,…,dD′为归一化后相邻2个解之间的欧式距离,dideal为理想距离,则解集A的均匀度为:
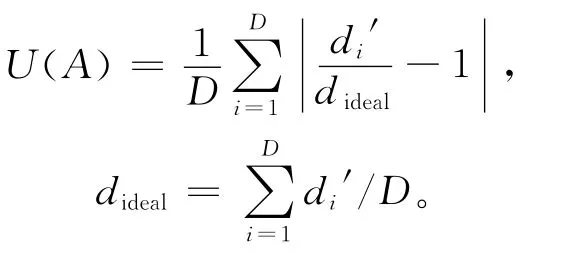
7.2 参数设置
为便于实验比较,本文设置各参数如下:
分销中心数量g=2;运载工具的最大单位载货量Vmax=n/5;工件i的单位拖期/库存成本系数γi=2,βi=1;工件i的加工时间Tik,交货时间都由计算机随机生成,其范围分别是[10,100]和[10,10+55n];PSO子算法的概率值上限Pmax=1.0,下限Pmin=0.6,迭代次数为100代;SOM子算法的学习率η=1/3,递减率δ=3/4,迭代次数为3代;VNS搜索策略的迭代次数为70代。
7.3 实验结果
图2所示为100×100问题规模下,本文所提混合算法(PSHA)、多目标粒子群算法(MOPSO,100代)和多目标遗传算法(MOGA,100代)的实际Pareto解分布情况(未作均匀度优化);表1所列为3种算法在解的质量、分布范围上的情况比较,以及本文算法在应用均匀度策略前后的情况比较;表2所列为各个算法在2个目标上的最小目标函数值。
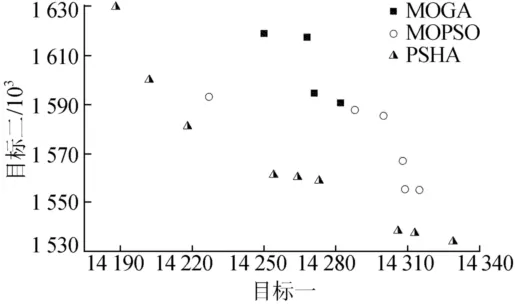
图2 100×100规模下实际解分布情况
从表2可以看出,本文算法在单目标方向的进化上明显优于其他2种算法,而从表1可以得知本文算法在单个解的质量以及分布范围方面也都远优于其他2种算法,均匀度策略的应用又使得算法所得的Pareto解剔除了部分目标值近似解,达到了更好的均匀效果。
除此之外,观察图1c的典型例子也不难发现,本文算法先向两边拓展再往中间优化的思想在实验中得到了预期的效果。

表1 解质量、分布范围及均匀度的数据对比
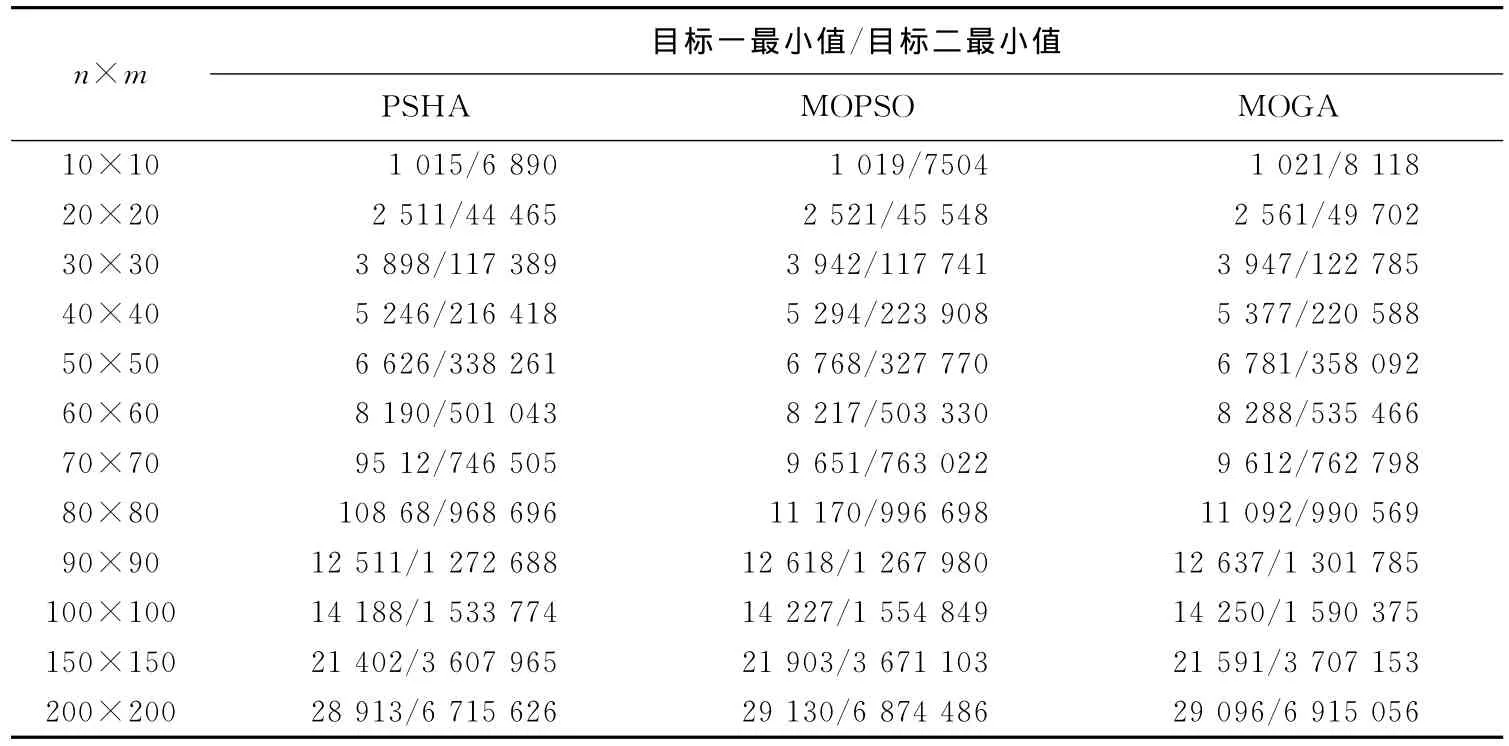
表2 各算法最小目标值的数据对比
8 结束语
本文对供应链环境下的一类单工厂多分销中心Flow Shop调度问题进行了分析,建立了相关模型并提出了一种新的解决多目标问题的混合算法。实验结果显示,该算法很好地解决了多目标进化中不同目标间进化方向不同所带来的相互干扰,从而在解的质量、分布的广度上都达到了预期的效果;除此之外,算法还对解的均匀度做了优化,避免了目标值函数近似的解对决策者的影响。
[1]Iyer A,Bergen M E.Quick response in manufacturer-retailer channels[J].Management Science,1997,43 (4):559-570.
[2]Frederix F.An extended enterprise planning methodology for the discrete manufacturing industry[J].European Journal of Operational Research,2001,129:317-325.
[3]Chan F T S,Chung S H,Chan P L Y.An adaptive genetic algorithm with dominated genes for distributed scheduling problems[J].Expert Systems with Applications,2005,29(2):364-371.
[4]Eren T,Guner E.A bacteria scheduling with sequence dependent setup times[J].Applied Mathematics and Computation,2006,179:378-385.
[5]Huang R H,Yang Changlin.Solving a multi-objective overlapping flow-shop scheduling [J].International Journal of Advanced Manufacturing Technology,2009,42:955-962.
[6]王海瑶,蒋增强,葛茂根.基于规则组合的Job Shop多目标柔性调度方法[J].合肥工业大学学报:自然科学版,2010,33(1):14-18.
[7]Pasupathy T,Rajendran C,Suresh R K.A multi-objective genetic algorithm for scheduling in flow shop to minimize the makespan and total flow time of jobs[J].International Journal of Advanced Manufacturing Technology,2006,27:804-815.
[8]Reza T M,Alireza R V,Ali H M.A hybrid multi-objective immune algorithm for a flow shop scheduling problem with bi-objectives:weighted mean completion time and weighted mean tardiness [J].Information Sciences,2007,177:5072-5090.
[9]Yangmahan B,Yenisey M M.A multi-objective ant colony system algorithm for flow shop scheduling problem [J].Expert Systems with Applications,2010,37(2):1361-1368.
[10]Schaffer J D.Multiple objective optimization with vector evaluated genetic algorithms[C]//Proceedings of the First ICGA,1985:93-100.
[11]Dugardin F,Yalaoui F,Amodeo L.New multi-objective method to solve reentrant hybrid flow shop scheduling problem[J].European Journal of Operational Research,2010,203(1):22-31.
[12]Lacomme P,Prins C,Sevaux M.A genetic algorithm for a bi-objective capacitated arc routing problem [J].Computers and Operations Research,2006,33(12):3473-3493.
[13]Kennedy J,Eberhart R C.Particle swarm optimization[C]//Proceedings of IEEE International Conference on Neural Networks,1995:1942-1948.
[14]Kennedy J.The particle swarm:social adaptation of knowledge[C]//Proc IEEE Int Conf on Evolutionary Computation,Indianapolis,1997:303-308.
[15]Kohonen T.The self-organizing map [J].Proceedings of the IEEE,1990,78:1464-1480.
[16]Liao C J,Cheng C C.A variable neighborhood search for minimizing single machine weighted earliness and tardiness with common due date[J].Computers &Industrial Engineering,2007,52:404—413.
[17]Leung Y W,Wang Yuping.U-masure:aquality measure for multi-objective programming [J].IEEE Transactions on Systems,Man,and Cybernetics,Part A:Systems and Humans,2003,33(3):337-343.
[18]Mansouri S A.A multi-objective genetic algorithm for mixed-model sequencing on JIT assembly lines[J].European Journal of Operational Research,2005,167(3):696-716.
[19]Veldhuizen D A V,Lamont G B.On measuring multiobjective evolutionary algorithm performance[C]//Proceedings of the 2000Congress on Evolutionary Computation,2000:204-211.
[20]Bosman P A N,Thierens D.The balance between proximity and diversity in multiobjective evolutionary algorithms[J].IEEE Transactions on Evolutionary Computation,2003,7(2):174-188.
