一种基于加速度与表面肌电信息融合和统计语言模型的连续手语识别方法
2011-09-02田建勋杨基海
田建勋 陈 香 李 云 杨基海
(中国科技大学电子科学与技术系,合肥 230027)
引言
手语识别研究的目的是使计算机能自动理解手语执行者所表达的信息,一方面可为正常人与聋哑人的通信建立一种有效的途径,另一方面可提供一种利用手语手势动作和计算机进行自然交互的有效方法。
基于加速计[1](accelerometer,ACC)和基于表面肌电(surface electromyography,SEMG)传感器[2]的动作感知技术是手语手势识别研究领域的两个重要分支。加速计擅长检测手部或手臂运动轨迹和手所处姿态等较大尺度的动作,而表面肌电信号包含相关肌肉群的丰富运动信息,可用于手指、手腕等细微运动的识别。利用两类传感器信号的特点进行信息融合,可提高可识别手语手势动作的种类和准确率。作者实验室前期研究工作表明[3],将肌电传感器和加速计结合起来对23种手势动作进行检测和分类,比单独使用其中一种传感器可提高5%~10%的准确率。Kim等将两种传感器融合技术应用到德国手语7个手语词识别,取得了相似的研究结果[4]。
基于表面肌电和加速度信息融合的手语手势动作识别存在的问题是,动作表面肌电信号和加速度信号在采集时受外界影响较大,且存在较大的个体差异,不同对象做同样的动作时信号存在有差异,甚至同一对象在不同时间做同样的动作也会出现差异。这些信号差异对手语动作识别有着很大的影响,需要在识别过程中进行消除。为实现基于肌电和加速度信息融合的连续中国手语手势的可靠识别,一方面提出使用“词根”作为识别基元的识别方法,以消除手语词中词根动作之间的运动伪迹的影响,减小识别错误的可能性。另一方面,由于词根被识别出后,从词根到句子的转变与汉语中组词造句过程十分相似,在识别方法中引入统计语言模型,从语言概率方面来对词根识别结果进行错误检测和纠正,实现对连续句子的正确识别。
本研究工作与其他研究的显著不同在于:1)提出使用词根作为识别基元,采用多级决策树型结构和HMMs模型实现对词根动作的建模和识别,以提高手语手势动作识别的准确率。2)在识别过程中引入bigram统计模型,利用转移概率、互信息等参数对句子中的词根接续关系进行检测,从而进行错误检测与纠正。3)对中国手语120个常用词根动作和由此构建的200个中国手语例句开展了手语识别实验。
1 连续手语语句识别方法
基于加速计和多通道表面肌电信息融合的手语识别流程如图1所示,大致分为手语动作信号采集,词根分割与特征提取,词根识别和句子识别等4个主要步骤。
1.1 数据采集与预处理
由于手语动作中很多涉及到双手运动,在左右手前臂各自安放了4个SEMG传感器和1个3D加速计用于数据采集。考虑到传感器双手上的安放具有对称性,故具体安放位置以右手为例,如图2所示。三轴加速计安置在前臂背侧靠近腕部的位置,以捕获手部姿态和运动轨迹信息,4通道SEMG传感器分别放置在前臂小指伸肌、尺侧腕屈肌、伸指总肌和桡侧腕伸肌附近以检测手指和手腕的多种运动。
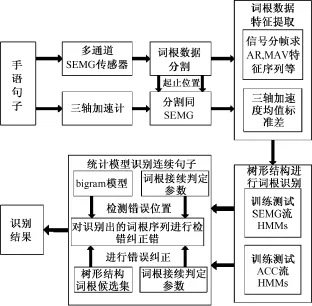
图1 连续手语语句识别流程Fig.1 The flow diagram of continuous sign language recognition
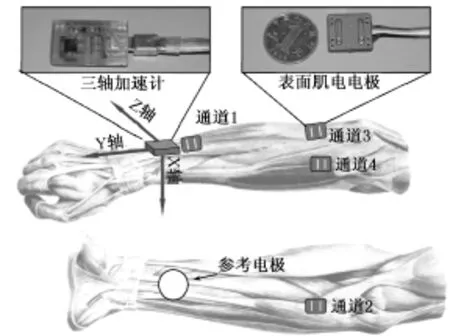
图2 右手传感器安放位置示意Fig.2 SEMG and ACC sensor placement on the right hand
当采集到原始的SEMG和ACC信号后,为了去除高频高斯噪声信号的干扰,需要对其进行滤波去噪,然后进行A/D转换,以得到无扰、离散的信号供使用。在预处理中,采用20~500Hz的带通滤波器对SEMG信号进行滤波,采用20Hz的低通滤波器对ACC信号进行滤波,然后以1 000Hz的采样频率进行A/D转换。
1.2 词根数据分割
词根被定义为手语中的最小单元,具有一定含义,并且可以用来区分不同的手势词,以词根为单位进行手语识别的优点在于:词根的数目是有限的,对其进行建模的工作量较小,而它可以组成的词的数目则是很大的[6],而且词根动作易于从手语动作信号流中分割出来。
由于SEMG信号的强度和手势运动时肌肉的收紧与放松密切相关,本研究根据两个词根动作间隔中,肌肉短暂放松时会出现SEMG信号强度变低的特点,采用多通道SEMG瞬时能量与阈值比较的方法自动检测词根动作的起点和终点,加速度信号流也按照相同的起点和终点进行分割。其主要步骤可见参考文献[7]。
图3所示为受试者连续执行例句“他想跑回去”所采集的信号中右手3轴ACC和4通道SEMG信号以及词根动作分割结果,图中最后一行(E_MA)为多通道SEMG均值信号的瞬时能量的移动平均序列。由图中信号可以看出,词根的动作信号与动作间隔信号相比SEMG能量非常显著,可以方便地通过合适的阈值检测方法确定起始点。手语单词“回去”由词根“回”和“去”组合而成,相比整段信号而言,两个词根各自的信号更能精确表现出手语动作的特点,也更利于特征提取和识别。

图3 例句“他想跑回去”词根信号分割示意Fig.3 Illustration of subword segmentation in 3-axis ACC and 4-channel EMG signal streams
1.3 词根数据段特征提取
当提取到显著的词根动作信号时,就需要用一组最有效的特征来对词根动作信号进行描述。对于词根动作中的加速度信号通过减采样抽取为32点和幅度归一化得到一组三维的特征向量序列作为主要特征[7],此外还提取出三轴的均值、标准差等简单特征用于决策树分类判断。对于多通道SEMG信号进行分帧提取每帧中各通道信号幅值的绝对值均值(mean absolute value,MAV)和4阶自回归(auto-regressive,AR)模型系数作为主要特征向量[7]。
1.4 采用多级决策树的词根识别
决策树是一种以拓扑结构为树型的多级决策系统,具有不同属性特征的样本数据从根节点输入,依据非叶子节点的一系列规则被分配到具有不同属性的分支,最终到达叶子节点确定样本所属类别[8]。图4为用于手语识别的多级决策树。其结构原理和建立过程分为以下几个部分。
静态与动态手语手势分类:在决策树结构的第一层中,通过ACC活动段三轴标准差的均方根值与指定阈值比较来判定手语手势动作的动静态。
手部姿态分类:在决策树结构的第二层中,对所有类别训练样本的ACC三轴均值特征用模糊K均值聚类算法,可以将相近手部姿态的动作划分在同一个聚类集中,供下一级进行识别分类。
动作时间长短分类:在树型结构第三层中,采用SEMG活动段时间长度与阈值比较的方法区分短时和长时执行手语手势动作。
多流HMM最终分类:经过上面三层树形分类之后,待识别的手语手势动作仅出现在一个较小规模的候选集合中。对该集合中的手语词,采用包含有ACC和EMG流的多流HMM实现两类传感器信息的决策级融合和手语词判决识别[8]。作者实验室以往的工作表明,在识别过程中出现的错误常见于此,即识别出的错误结果与正确结果一般来说存在于同一个候选集合中。因此,我们可以将此候选集合作为错误纠正部分中的纠错候选集。
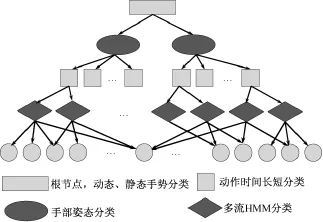
图4 多级决策树结构示意Fig.4 Diagram of herarchical decision tree
1.5 基于统计语言模型的连续语句识别
在多级决策树给出词根识别结果序列的基础上,采用统计语言模型对词根接续的合理性进行判断,纠正错误识别并给出连续语句识别结果。统计语言模型通常采用语料库语言学的方法,通过对语料库进行深层加工、统计和学习,可以客观地描述大规模真实文本中细微的语言现象。常见的统计语言模型指N-gram模型,它反映了元素的同现概率等信息,可以用来进行错误检测及纠正[5,9]。哈尔滨工业大学利用N-gram模型和依存分析,实现了对大规模句子文本中的错误进行有效检测[5]。高文等在手语识别的过程中也将bigram模型引入来进行句子的识别研究[6]。
1.5.1 N-gram统计模型的建立
假设一个句子由l个词根组成:W=w1,w2,w3,…,wl,若引入马尔科夫假设,即假设当前的这个词根只依赖于前面有限几个词根(例如n-1个),而不是依赖前面所有的词根[9],则
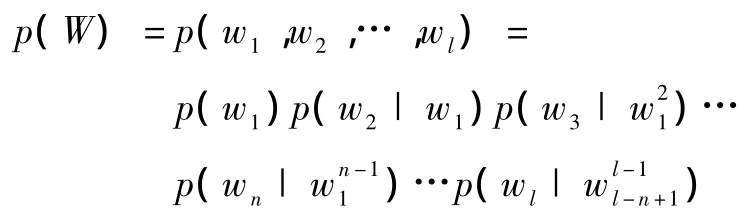
根据最大似然估计原则,元素wi的上下文条件概率p(wi|)的估计公式则为

1.5.2 词根接续错误检测与纠正方法
互信息表征的是两个统计量相互关联的程度,关联程度越高,互信息越大,反之则小。在基于词根容量为N的手语语料库建立的bigram模型中,可定义Xi-1,Xi之间的互信息为
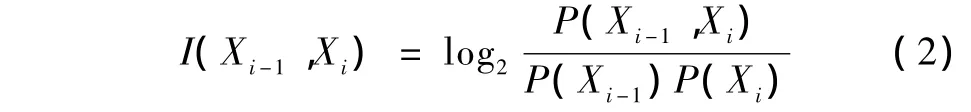
式中,r(Xi-1,Xi)为Xi-1,Xi邻接共同出现的次数,P(Xi-1,Xi)=r(Xi-1,Xi)/N为Xi-1,Xi的邻接共现概率,P(Xi-1)=r(Xi-1)/N,P(Xi)=r(Xi)/N为Xi-1,Xi出现的概率。
若I(Xi-1,Xi)>τ1,τ1为大于0的阈值,则有P(Xi-1,Xi)>>P(Xi-1)P(Xi),此时Xi-1,Xi接续,互信息量越大,接续强度越大。若I(Xi-1,Xi)≈0,则P(Xi-1,Xi)≈P(Xi-1)P(Xi),此时Xi-1,Xi之间的接续关系不明确。若I(Xi-1,Xi)<<0,则P(Xi-1,Xi)<<P(Xi-1)P(Xi),此时Xi-1,Xi之间基本没有接续关系。
统计理论Pearson的χ2统计量可以用来检验Xi-1和Xi的独立性,其也可以判断词根接续关系。假设二元组(X,Y)表示相邻的两个词根组合,X的取值范围是(S,-S),-S表示取值不为S。假设Xi-1和Xi独立,从二元组(X,Y)取得同现矩阵中的n个非零元为子样,用n11表示取值为(Xi-1,Xi)的子样个数,n12、n21、n22分别表示取值为(Xi-1,-Xi),(-Xi-1,Xi),(-Xi-1,-Xi)的子样的个数,记ni.=ni1+ni2,(i=1,2;j=1,2),有n=n11+n12+n21+n22。χ2(Xi-1,Xi)统计量可以定义为

由假设估计方法可知,当χ2(Xi-1,Xi)<τ2(τ2是由某个显著水平所得到的判断阈值)时假设成立,Xi-1和Xi独立,即Xi-1和Xi不接续,反之二者接续。
转移概率体现着前一个词根跳到后一个词根的概率,它也从一定程度上反映了两个词根前后接续的可能大小。结合二元语法F(Xi/Xi-1)和一元语法F(Xi),使用退步法计算从Xi-1到Xi的转移概率

λ为经验参数,一般取λ=0.8。
由上述公式可认为当P(Xi/Xi-1)>τ3的时候,Xi-1、Xi之间存在接续关系,并且P(Xi/Xi-1)越大,接续强度越强。
综合以上各式,可以设定合适的阈值,若I(Xi-1,Xi)>τ1,则判定系数K1=1,反之K1=0;若χ2(Xi-1,Xi)>τ2,则判定系数K2=1,反之K2=0;若P(Xi/Xi-1)>τ3,则判定系数K3=1,反之K3=0。定义词根接续判定函数CGJX(Xi-1,Xi)为
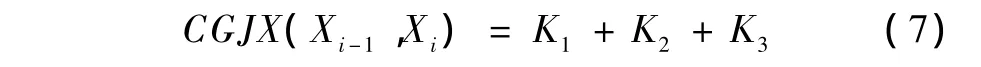
用来综合判定词根接续,若CGJX(Xi-1,Xi)≥2时,相邻两词根接续,反之认为相邻词根不接续。
当检测到某个词根与相邻词根不接续的时候,可以对纠错候选集中的候选结果计算相应的参数值,看它们是否满足与前后词根的接续关系,从而找出最符合接续关系的结果作为最终结果,以此纠正错误,识别出连续句子。
2 实验
本研究从中国手语词中选了120个常用词根,以这120个词根构建了260个左右的手语词汇,并以此为基础构建了200个实验例句,例句平均长度为4.6个词根。实验选取2名受试者,每名受试者分5次采集数据,每次实验采集40个例句,每个句子重复三遍。这样,用于实验分析的数据集包含了5 640个手语词根样本和1 200个句子样本。数据处理时将每个受试者5d的数据分为三组,每组数据包含全部200个句子且不重复,以其中2组作为训练样本,剩下的1组作为测试样本。
由于本工作的研究对象为手语词根和句子,与日常语言有着很大的不同,所以在本工作中建立统计语言模型需要先建立相应的手语语句语料库。本工作使用的语料库中包含有2 000个日常手语语句,并依据手语的构成规则进行了相应的词根标注。在此日常手语语料库中共含有9 344个手语词根样本,平均语句长度为4.7个词根。
以120个词根动作为对象进行统计建立模型,则可能出现的词根接续对为120×120=14 400个。由于语料库的规模大小是有限的,它并不能完全的反映出所有词根动作的出现规律,仍然会有大量的低频词出现,即有数据稀疏情况的出现。为了避免数据稀疏对实验的影响,使用了katz平滑方法对统计结果进行数据平滑,其在小训练集的bigram模型上有较大的优势。最终经数据平滑后获得120个词根的二元统计模型矩阵和一元统计结果。
当建立了bigram统计模型后,为了对词根接续关系进行判定,需要对相应的阈值参数进行设定,其中包括互信息,Pearson的χ2统计量和转移概率。由于语料库的规模有限,它不能完全的反映所有词根动作的接续关系,会引起在纠错的过程中有些错误可能漏检,而有些出现比较少的接续关系有可能被判错。为了对纠错模型进行定量分析,定义正确率(accuracy)Pa,误报率(false)Pf和漏报率(omission)Po。记待检测文本中实际的错误数(error)Me,检测出错误的位置数量为(check)Mc,其中正确检测出错误位置的数目为(right check)Mr,检测出错误而实际上原文位置正确的数量为(false check)Mf。则有
Pa=Mr/Me
Pf=Mf/Mc
Po=(Me-Mr)/Me
为了找到最佳的纠错模型参数,利用部分测试文本进行了相应的实验,在测试文本中,共有727个接续检测点,其中错误位置为109个,通过对不同的阈值进行设定检测,统计此时测试文本的检错相应结果,从而找到最佳的阈值。
在确定了合适的统计语言模型后,为验证所提出的基于加速度与表面肌电信息融合,和统计语言模型的手语识别方法的有效性和实用性,首先对所采集的融合表面肌电和加速度信息的手语词根动作进行数据分析处理,利用多级决策树模型进行识别统计,为每个句子识别出相应的词根序列,然后使用bigram模型进行词根的二元接续关系进行检测,从而进一步改正词根动作的误识别,对纠错后的句子中的词根识别结果进行统计。
3 结果与分析
表1以正确率、误报率和漏报率的形式给出了在不同的阈值选取下,bigram二元检错模型对测试文本中的错误检测的结果。
由表1可以看出,若阈值取得过低的话,可能有大量的错误会被漏检,而若阈值取得过高的话,则会有大量的误报情况出现。随着阈值取值的不断提高,误报率的升高趋势越来越明显。这是由于构建的语料库与真实的语言模型还有差距,尽管进行了数据平滑,但是某些正确存在的词根组合所存在的概率仍然很小,当取得较高的阈值来判定的时候,这些组合则会被判定为错误。一个较好的检错模型应该在正确率、误报率和漏报率中取得较好的平衡,即正确率尽量高,而误报率和漏报率尽量低。通过大量的不同阈值实验后选取τ1=0.4,τ2=0,τ3=0.01作为实验时的所使用的阈值参数。
表2以120个手语词根平均识别率(Mean)和标准差(Std),以及200个测试句子的整体识别率的形式,给出了使用统计纠错模型和未使用统计纠错模型两种方法进行对比的手语识别结果。由表2可知,120个手语词根全局平均识别率在90%以上,句子识别率在86%以上。验证了所提出的基于SEMG和ACC信息融合与结合统计纠错模型的手语识别方法的可行性和有效性。此外,通过对比实验结果不难发现,采用纠错模型的方法与未采用纠错模型相比,词根的平均识别率提高了近4%左右。对200个连续手语句子的句子识别结果进行统计(每个句子中有一个词根错误就算句子错误),可以看出句子的识别率比未使用纠错模型时有了10%左右的提高。这是由于在多级决策树的最后一级中,使用ACC和EMG流的多流HMM实现两类传感器信息的决策级融合和手语词判决,此时在同一集合中的动作具有相似的信号特征,但是它们在语言的含义上,比如词性,具有较大的差别,因此可以明显的用统计语言模型进行词根的接续判定来进行纠错。

表1 不同参数阈值对纠错结果的影响Tab.1 The correction results of different threshold

表2 两种方法的词根及句子识别结果Tab.2 The recognition results of the subwords and the sentences
表3是连续句子识别判断纠错的一个实例。正确例句为“他想跑回去”,识别结果为“他想跑他他”,即词根“回”和“去”识别错误。此时,结果中需要进行接续检测的词根组合为〈他,想〉,〈想,跑〉,〈跑,他〉,〈他,他〉四组。(选定的阈值为τ1=0.4,τ2=0,τ3=0.01,带下划线的值低于选定的阈值)

表3 词根接续错误检测结果示例Tab.3 The error detection results of the example sentence
在本例中,确定了词根“跑”和“他”以及词根“他”和“他”之间不接续,由此就确定了错误区间为句子的最后两个词根。然后对多层决策树所提供的纠错候选集里面的词根进行3-best结果判断,发现第一个错误词根“他”的HMMs识别结果中最好的三个词根为[他,我,回],第二个错误词根“他”的HMMs识别结果中最好的三个词根为[他,我,去],由此建立候选结果搭配集,通过再计算相应的参数值,可以得到“跑”和“回”的计算结果为[4.898 5,240.118 8,0.110 7],“回”和“去”的计算结果为[3.965 6,189.231 4,0.207 9],两者均满足接续关系,所以句子“他想跑回去”是合理的,作为纠错后的最终句子识别结果。
综上所述,将基于SEMG和ACC融合的手势识别方法与基于词根接续纠错模型结合起来,互相补充,可以有效地提高手语连续语句的识别率。此种方法主要应用于句子中局部错误的检测与纠正,如相邻词根之间的关系判断。
4 结语
本研究首先对基于SEMG和ACC融合的手语手语手势识别技术进行了分析,对其优缺点进行了总结,并针对其识别结果受动作信号影响较大的缺点,提出了一种基于SEMG与ACC信息融合与结合统计语言模型纠错的中国手语手势识别方法。该方法先通过基于SEMG与ACC信息融合的多级决策树得到手语词根识别的初步结果,然后再利用统计语言模型对识别结果中的相邻词根动作的接续关系进行检测,从而把结果中可能出现的错误限定在一个小窗口中,然后再利用多级决策树中所给出的纠错候选集进行错误纠正。实验结果表明:这种方法可明显提高手语手势动作的正确识别率。这种纠错方法比较依赖于所选取进行训练的语料库的完备程度,且擅长于检测局部范围内的错误,对一些语义级别的错误还不能做到纠错。今后准备进行更大规模的手语语句语料库的建设,并将句法结构进一步引入到识别过程中,以期望实现大词汇量、连续的中国手语识别系统。
[1]Mäntyjärvi J,Kela J,Korpipää P,et al.Enabling fast and effortless customisation in accelerometer based gesture interaction[C]//Proceedings of the 3rd International Conference on Mobile and Ubiquitous Multimedia.New York,NY:ACM,2004:25-31.
[2]Oskoei M,Hu Huosheng.Myoelectric control systems—A survey[J].Biomedical Signal Processing and Control,2007,2(4):275-294.
[3]Chen Xiang,Zhang Xu,Zhao Zhangyan,et al.Hand gesture recognition research based on surface EMG sensors and 2D-accelerometers[C]//Proceedings of the 11th International Symposium Wearable Computers.Boston,MA:IEEE,2007:11-14
[4]Kim J,Wagner J,Rehm M,et al.Bi-channel sensor fusion for automatic sign language recognition[C]//Proceedings of the 8th IEEE International Conference on Automatic Faceand Gesture Recognition.Amsterdam:IEEE,2008:647-652.
[5]马金山,张宇,刘 挺,等.利用三元模型及依存分析查找中文文本错误[J].情报学报,2004,23(06):723-728.
[6]王春立,高 文,马继勇,等.基于词根的中国手语识别方法[J].计算机研究与发展,2003,40(2):150-156.
[7]Zhang Xu,Chen Xiang,Wang Wenhui,et al.Hand gesture recognition and virtual game control based on 3D accelerometer and EMG sensors[C]//Proceedings of the 13th International Conference on Intelligent User Interfaces.New York:Association for Computing Machinery,2009:401-405.
[8]Fang Gaolin,Gao Wen,Zhao Debin.Large vocabulary sign language recognition based on hierarchical decision trees[C]//Proceedings of the 5th International Conference on Multimodal Interfaces.New York,NY:ACM,2003:125-131.
[9]邢永康,马小平.统计语言模型综述[J].计算机科学,2003,30(9):22-26.
